






1.切换到普通户来操作
2.进入软件的目录

3.解压到指定目录
tar -zxvf hadoop-3.4.0-aarch64.tar.gz -C /bigdata/server
cd /bigdata/server
![]()
4.hadoop配置文件修改
进入目录
cd /bigdata/server
创建软链接
ln -s hadoop-3.4.0/ hadoop
进入软链接的etc目录下的hadoop目录
cd /bigdata/server/hadoop/etc/hadoop
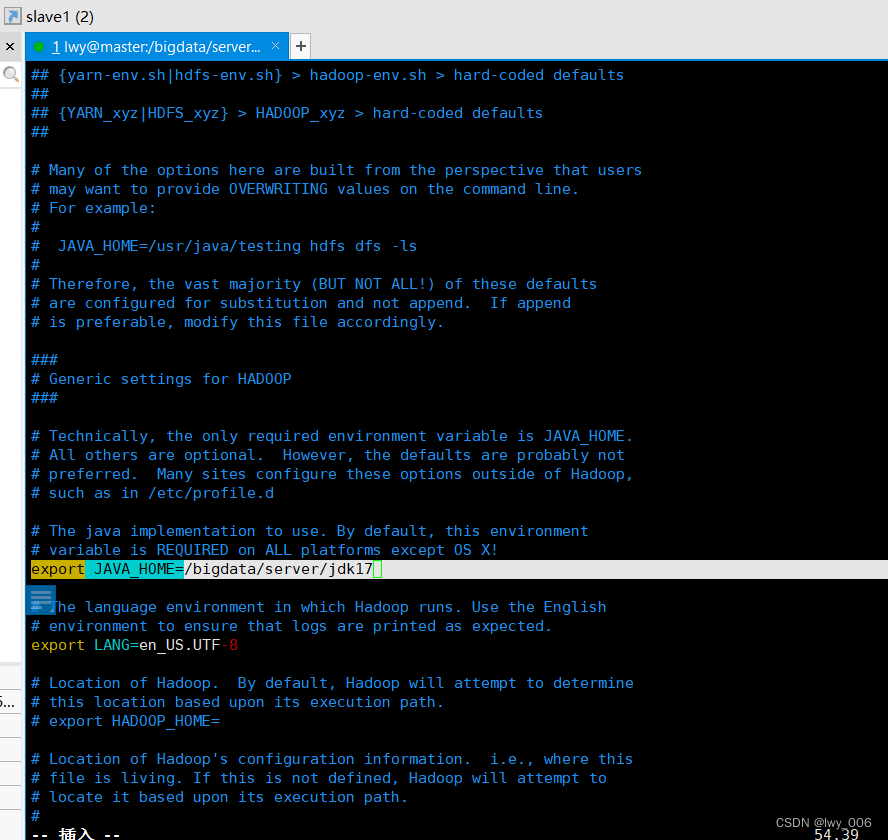
修改hadoop-env.sh文件vim hadoop-env.sh
添加内容
export JAVA_HOME=/bigdata/server/jdk17
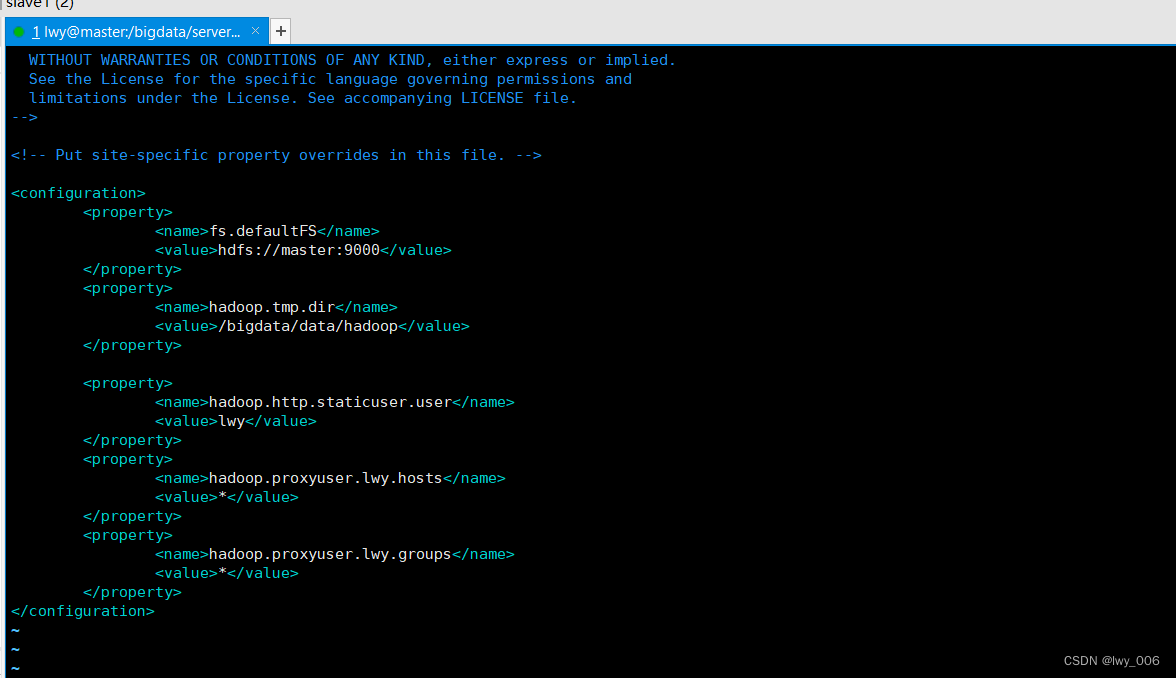
编辑vim core-site.xml文件
内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/data/hadoop</value>
</property><property>
<name>hadoop.http.staticuser.user</name>
<value>lwy</value>
</property>
<property>
<name>hadoop.proxyuser.lwy.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.lwy.groups</name>
<value>*</value>
</property>
</configuration>编辑vim hdfs-site.xml文件
添加内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property><property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
</configuration>编辑 vim mapred-site.xml文件
添加内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>编辑 vim yarn-site.xml文件
添加内容如下:
<!-- 设置主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<!-- reducer获取数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property><!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://slave2:19888/jobhistory/logs</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 环境变量的白名单 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
</value>
</property>
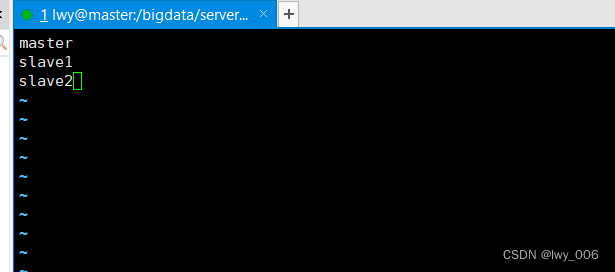
修改vim workers
先进入cd /bigdata/server/hadoop/etc/hadoop目录,然后在 vim workers
添加内容如下所示
master
slave1
slave2
3.同步到其他的服务器
xsync hadoop-3.4.0/
xsync hadoop
4.为所有节点配置环境变量
sudo vim /etc/profile.d/custom_env.sh
添加内容如下所示:
export HADOOP_HOME=/bigdata/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
![]()
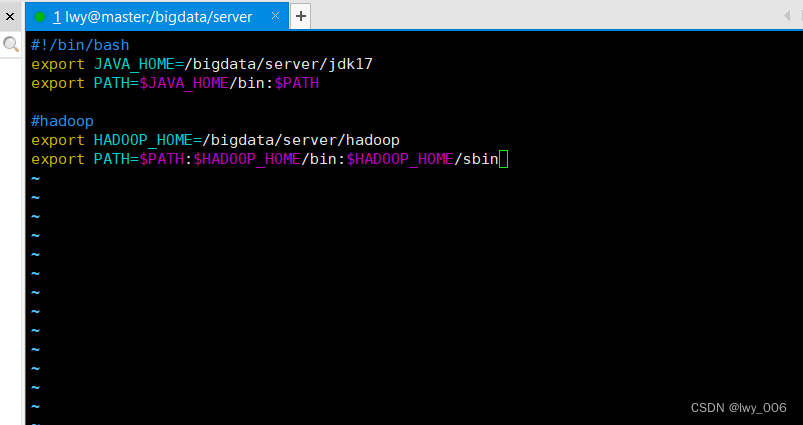 5.最后所有节点执行 source /etc/profile
5.最后所有节点执行 source /etc/profile

6.hadoop集群 启动
首次启动,首先在主节点master进行格式化操作,因此此时的HDFS在物理上还是不存在的
执行此命令:hadoop namenode -format
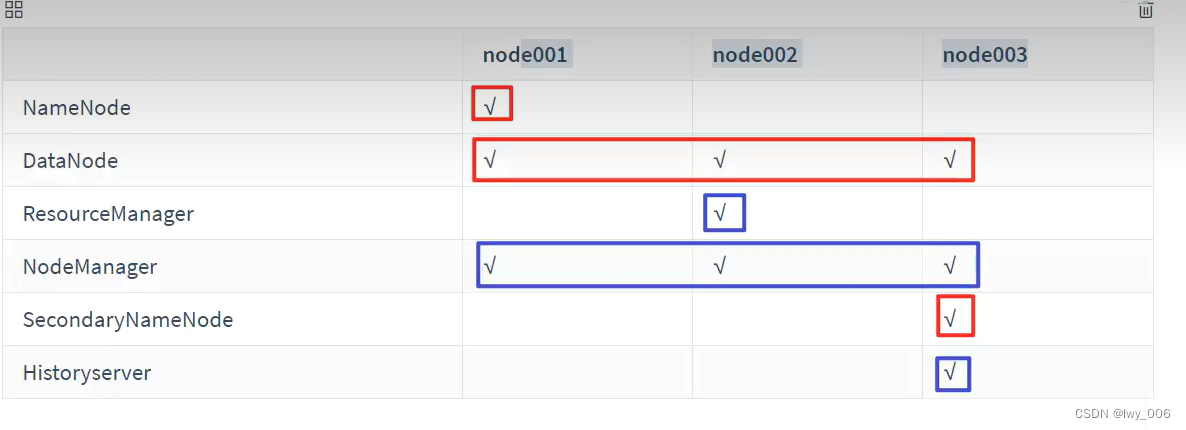
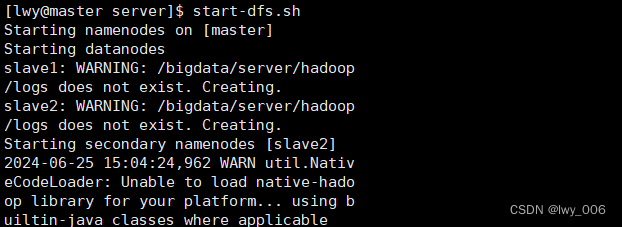
所有节点启动
start-dfs.sh
输入jps查看集群
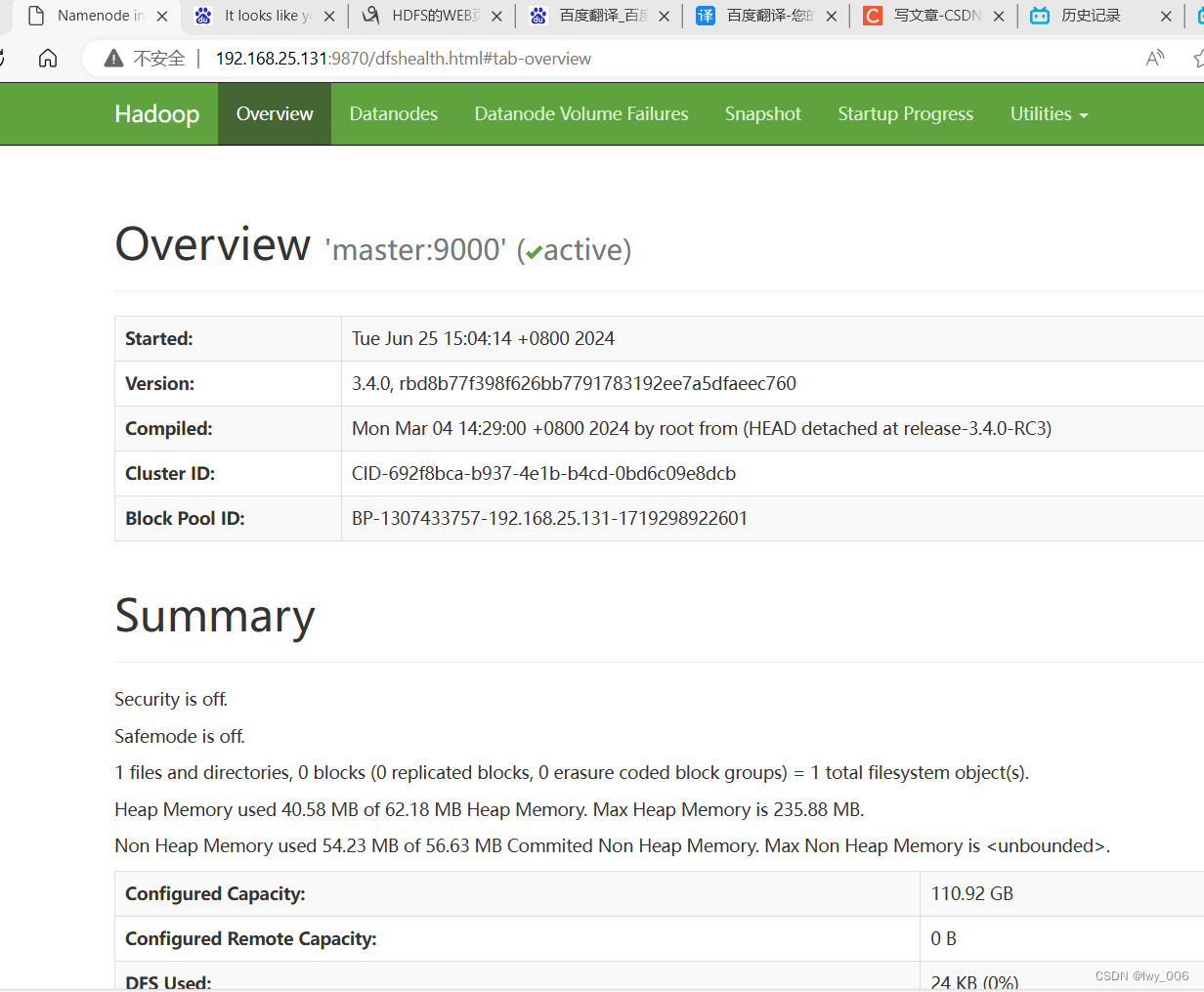
输入ip地址加端口http://192.168.25.131:9870/,端口是9870
启动yarn命令是在第二个主机启动: start-yarn.sh 端口是8088
















 3002
3002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









