







一、Hive的基础函数
1、如何查看自带的函数
show functions; --查看所有的函数
desc function functionName; -查看某个具体的函数如何使用
hive (yhdb)> desc function abs;
OK
tab_name
abs(x) - returns the absolute value of x
Time taken: 0.047 seconds, Fetched: 1 row(s)2、日期函数
当前系统时间函数:current_date()、current_timestamp()、unix_timestamp()
-- 函数1:current_date();
当前系统日期 格式:"yyyy-MM-dd"
-- 函数2:current_timestamp();
当前系统时间戳: 格式:"yyyy-MM-dd HH:mm:ss.ms"
-- 函数3:unix_timestamp();
当前系统时间戳 格式:距离1970年1月1日0点的秒数。
select unix_timestamp(); //获取当前的时间戳
select unix_timestamp('2017/1/21','yyyy/MM/dd') ;
hive (yhdb)> select current_date();
OK
_c0
2023-08-26
Time taken: 1.032 seconds, Fetched: 1 row(s)
hive (yhdb)> select current_timestamp();
OK
_c0
2023-08-26 18:38:02.304
Time taken: 0.404 seconds, Fetched: 1 row(s)
日期转时间戳函数:unix_timestamp()
获取当前时间的时间戳
select unix_timestamp();
select unix_timestamp(current_timestamp());
hive (yhdb)> select unix_timestamp();
unix_timestamp(void) is deprecated. Use current_timestamp instead.
unix_timestamp(void) is deprecated. Use current_timestamp instead.
OK
_c0
1693046302
Time taken: 0.448 seconds, Fetched: 1 row(s)
hive (yhdb)> select unix_timestamp('2022-10-01 00:00:00');
OK
_c0
1664582400
Time taken: 0.322 seconds, Fetched: 1 row(s)
hive (yhdb)> select unix_timestamp('2022/10/01');
OK
_c0
NULL
Time taken: 0.473 seconds, Fetched: 1 row(s)
hive (yhdb)> select unix_timestamp('2022/10/01','yyyy/MM/dd');
OK
_c0
1664582400
Time taken: 0.336 seconds, Fetched: 1 row(s)时间戳转日期函数:from_unixtime
菜鸟工具:时间戳转换器 | 菜鸟工具
根据时间戳,指定输出日期的格式:
hive (yhdb)> select from_unixtime(1693046606);
OK
_c0
2023-08-26 10:43:26
Time taken: 0.39 seconds, Fetched: 1 row(s)
hive (yhdb)> select from_unixtime(1693046606,'yyyy/MM/dd HH~mm~ss');
OK
_c0
2023/08/26 10~43~26
Time taken: 1.367 seconds, Fetched: 1 row(s)unix_timestamp 函数是将一个字符串,变为了一个时间戳
from_unixtime 函数是将时间戳变为了一个字符串计算时间差函数:datediff()、months_between()
select datediff('2023-01-01','2023-02-01');
hive (yhdb)> select datediff('2023-01-01','2023-02-01');
OK
_c0
-31
出现负数,说明数据是前面的时间减去后面的时间,相差的天数。
hive (yhdb)> select months_between('2019-12-20','2019-11-01');
OK
_c0
1.61290323
Time taken: 0.3 seconds, Fetched: 1 row(s)
前面的时间减去后面时间的月数 ,可以精确到小数。
日期相加:
select date_add('2023-12-31',3); -- 日期相加 2024-01-03
日期相减
select date_sub('2023-12-31',3);
select add_months('2023-12-31',3); --月份相加 2024-03-31日期时间分量函数:year()、month()、day()、hour()、minute()、second()
select month(current_date());
hive (yhdb)> select month(current_date());
OK
_c0
8
Time taken: 0.395 seconds, Fetched: 1 row(s)
hive (yhdb)> select year(current_date());
OK
_c0
2023
Time taken: 0.374 seconds, Fetched: 1 row(s)
hive (yhdb)> select year('2012-12-12');
OK
_c0
2012
Time taken: 0.395 seconds, Fetched: 1 row(s)日期定位函数:last_day()、next_day()
--月末:
select last_day(current_date());
--可以求出当前日期的下个星期几
select next_day(current_date(),'thursday');日期加减函数:date_add()、date_sub()、add_months()
select date_add(current_date,1);
select date_sub(current_date,90);
select add_months(current_date,1);综合练习:
--当月第1天
当前月往前推一个月,7月,7月的最后一天,+1
select date_add(last_day(add_months(current_date,-1)),1);
select add_months(date_add(last_day(`current_date`()),1),-1);
--下个月第1天:
select date_add(last_day(current_date),1);
dayofmonth(日期): 当前时间是这个月的第几天
select add_months(date_sub(current_date,dayofmonth(current_date)-1),1);字符串转日期:to_date()
select to_date('2023-07-01');将日期转为字符串:date_format()
select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss');
select date_format(current_timestamp(),'yyyy/MM/dd');
select date_format('2017-01-01','yyyy-MM-dd HH:mm:ss');
需求:假如需要将'2024-12-31' --> '2024/12/31'
-- 第一种方案
select date_format('2024-12-31','yyyy~MM~dd');
-- from_unixtime 将一个时间戳转换为某种字符串类型
-- 方案二
select from_unixtime(unix_timestamp('2024-12-31','yyyy-MM-dd'),'yyyy/MM/dd');3、字符串函数
-- lower(转小写)
select lower('ABC');
--upper(转大写)
select upper('abc');
--length(字符串长度,字符数)
select length('abc');
-- concat(字符串拼接)
select concat("A", 'B');
-- concat_ws(指定分隔符)
select concat_ws('-','a' ,'b','c');
-- substr(求子串)
select substr('abcde',3);
-- split(str,regex) 切分字符串,返回数组
select split("a-b-c-d-e-f","-");
select concat_ws('&',split('a,b,c,d,f',','));
select replace('a,b,c,d,f',',','&');
以下这个函数不是字符串函数:
select explode(split('h-e-l-l-o','-'));4、类型转换函数
select cast('123' as int)+1;
select cast(sal as string) from emp ;
select cast(1.5 as int);5、数学函数
--round 四舍五入((42.3 =>42))
select round(42.3);
--ceil 向上取整(42.3 =>43)
select ceil(42.3);
--floor 向下取整(42.3 =>42)
select floor(42.3);
-- 求绝对值
select abs(-1);
-- 取模函数6、hive的其他函数
1)nvl 判断一个数值是否为null,如果为null,给一个默认值
select nvl(null,100);
select nvl(200,100);
select nvl(comm,0)+sal from emp;2) 函数case when then ....when ...then.. else... end
举例说明:
数据如下:
张三 A 男
李四 A 男
王五 B 男
赵六 A 女
琪琪 B 女
巴巴 B 女
求男女数量。
建表:
create table emp_sex(
name string,
dept_id string,
sex string)
row format delimited fields terminated by "\t";
导入数据:
load data local inpath '/home/hivedata/test_a.txt' into table emp_sex;
sql 编写:
select sex,count(1) from emp_sex group by sex;
还有其他写法:
select
sum(case when sex='男' then 1 else 0 end) as `男`,
sum(case when sex='女' then 1 else 0 end) as `女`
from emp_sex;
还可以使用类似于switch的写法:
select
sum(case sex when '男' then 1 else 0 end) as man ,
sum(case sex when '女' then 1 else 0 end) as women
from emp_sex;hive中的字段的别名,英文别名不要使用单引号或者双引号,直接写就行,如果是中文的别名需要添加反引号``
3)get_json_object 从json数据中获取值
select get_json_object('{"name":"jack","age":19}','$.age');4) parse_url 解析一个字符串中的url参数
举例: 获取url中的HOST
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','HOST');
OK
www.baidu.com
Time taken: 0.437 seconds, Fetched: 1 row(s)
-- 获取PROTOCOL中的协议
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','PROTOCOL');
-- 获取Path
OK
http
Time taken: 0.194 seconds, Fetched: 1 row(s)
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','PATH');
OK
/path1/path2
Time taken: 0.183 seconds, Fetched: 1 row(s)
// 区分大小写
hive (yhdb)> select parse_url('http://www.baidu.com/path1/path2?k1=v1&k2=v2','path');
OK
_c0
NULL
获取url后面的参数以及参数的值
select parse_url('http://www.baidu.com/path1/parth2?name=zhangsan&age=18','QUERY');
select parse_url('http://www.baidu.com/path1/parth2?name=zhangsan&age=18','QUERY','name');5)if(p1,p2,p3)
语法格式:
if和case差不多,都是处理单个列的查询结果
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值: T
e.g.
select if(1==1,1,2) ;
select if(name!='a',name,'aaa') from user01;
select source,if(source='猎聘',1,2) as flag from t_cal_dowell_resume;
拓展:以下三个一个效果
select sal,if(comm is null,0,comm) from emp;
select sal,nvl(comm,0) from emp;
select sal,case when comm is null then 0 else comm end from emp;6) coalesce(col1,col2,col3...)返回第一个不为空的数据
select coalesce(null,1,23,4);
返回结果为17)取模函数
select pmod(3,2); -- 1
select pmod(5,3); -- 2
-- b + am == -5+ m * 3 ==m=2 1 / 3
-- -7 + a * 3= 正数 a=3 2/3= 2
-- 假如第一个值是负数,一般采用公式 a + bm = xxx
-- a= 被除数 m 等于除数 b等于多少取决于 这个公式什么时候是正数,最后将正数 除以 除数 获得的余数就是结果
select pmod(-5,3); -- 1
select pmod(-7,3);8) arry_contains
arry_contains()作用:判断数组是否包含某元素
语法:array_contains(数组,值),返回布尔类型
第五题:
有如下数据,表示1、2、3三名学生选修了a、b、c、d、e、f中的若干课程
id course
1 a
1 b
1 c
1 e
2 a
2 c
2 d
2 f
3 a
3 b
3 c
3 e
根据如上数据,查询出如下结果,其中1表示选修,0表示未选修
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
SQL:
--第一种方法
select id,
sum(case when course='a' then 1 else 0 end ) a,
sum(case when course='b' then 1 else 0 end ) b,
sum(case when course='c' then 1 else 0 end ) c,
sum(case when course='d' then 1 else 0 end ) d,
sum(case when course='e' then 1 else 0 end ) e,
sum(case when course='f' then 1 else 0 end ) f
from zhoukao03 group by id;
--第二种方法
select id,
if(array_contains(collect_set(course),'a'),1,0) a,
if(array_contains(collect_set(course),'b'),1,0) b,
if(array_contains(collect_set(course),'c'),1,0) c,
if(array_contains(collect_set(course),'d'),1,0) d,
if(array_contains(collect_set(course),'e'),1,0) e,
if(array_contains(collect_set(course),'f'),1,0) f
from courses group by id;
-- 第三种写法
select id,
sum(if(course=='a',1,0)) `a`,
sum(if(course=='b',1,0)) `b`,
sum(if(course=='c',1,0)) `c`,
sum(if(course=='d',1,0)) `d`,
sum(if(course=='e',1,0)) `e`,
sum(if(course=='f',1,0)) `f`
from courses group by id;
假如查询出如下结果
id a b c d e f
1 选修 选修 选修 未选修 选修 未选修
2 选修 未选修 选修 选修 未选修 选修
3 选修 选修 选修 未选修 选修 未选修
create table courses (
id int,
course string
)
row format delimited
fields terminated by '\t';
load data local inpath '/home/hivedata/zuoye5.txt' into table courses;
select id,
if(array_contains(collect_set(course),'a'),'选修','未选修') a,
if(array_contains(collect_set(course),'b'),'选修','未选修') b,
if(array_contains(collect_set(course),'c'),'选修','未选修') c,
if(array_contains(collect_set(course),'d'),'选修','未选修') d,
if(array_contains(collect_set(course),'e'),'选修','未选修') e,
if(array_contains(collect_set(course),'f'),'选修','未选修') f
from courses group by id;二、Hive的高级函数
1、窗口函数Over
来一个需求:求每个部门的员工信息以及部门的平均工资。在mysql中如何实现呢。
-- 第一种写法
SELECT emp.*, avg_sal
FROM emp
JOIN (
SELECT deptno
, round(AVG(ifnull(sal, 0))) AS avg_sal
FROM emp
GROUP BY deptno
) t
ON emp.deptno = t.deptno
ORDER BY deptno;
-- 第二种写法
select A.*,(select avg(ifnull(sal,0)) from emp B where B.deptno = A.deptno ) from emp A;以后看见这种既要明细信息,也要聚合信息的题目,直接开窗!
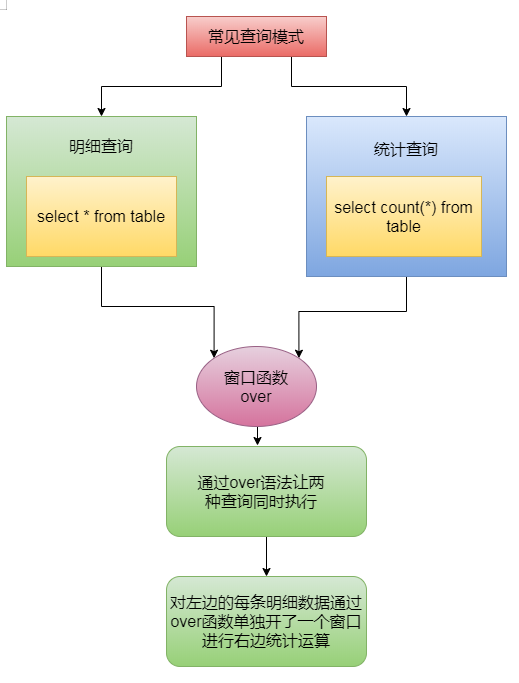
上案例:
数据order.txt
姓名,购买日期,购买数量
saml,2018-01-01,10
saml,2018-01-08,55
tony,2018-01-07,50
saml,2018-01-05,46
tony,2018-01-04,29
tony,2018-01-02,15
saml,2018-02-03,23
mart,2018-04-13,94
saml,2018-04-06,42
mart,2018-04-11,75
mart,2018-04-09,68
mart,2018-04-08,62
neil,2018-05-10,12
neil,2018-06-12,80
-1. 创建order表:
create table if not exists t_order
(
name string,
orderdate string,
cost int
) row format delimited fields terminated by ',';
-2. 加载数据:
load data local inpath "/home/hivedata/order.txt" into table t_order;指标一:需求:查询每个订单的信息,以及订单的总数
不使用开窗函数的写法
select *,(select count(1) from t_order) as `订单总数` from t_order ;
使用开窗函数的写法:
select *, count(*) over() from t_order;
开窗函数一般不单独使用,而是跟另外一些函数一起使用,比如 count, over() 这个的窗口是多大呢?over() 是整个数据集。
窗口其实就是范围,比如统计男女比例?必须知道窗口,是统计整个班级还是统计整个学校,班级和学校就是窗口。
窗口函数是针对每一行数据的.
如果over中没有指定参数,默认窗口大小为全部结果集指标二:查询在2018年1月份购买过的顾客购买明细及总次数。
select *,count(*) over()
from t_order
where substr(orderdate,1,7) = '2018-01';指标三:查询在2018年1月份购买过的顾客购买明细及总人数。
select *,count(distinct name) over()
from t_order
where substr(orderdate,1,7) = '2018-01';
还有没有其他的写法:
错误的写法:group by 语句,select 后面只能跟分组字段和聚合函数
select *,count(distinct name) over()
from t_order
where substr(orderdate,1,7) = '2018-01' group by name;
正确写法:
-- 假如使用group by
select *,(select count(1) from (
select name from t_order where substr(orderdate,1,7) ='2018-01' group by name
) t) from t_order where substr(orderdate,1,7) ='2018-01';
结论是:太麻烦了distribute by子句:
在over窗口中进行分组,对某一字段进行分组统计,窗口大小就是同一个组的所有记录
语法:
over(distribute by colname[,colname.....])指标四:查看顾客的购买明细及月购买总额
错误写法:明细信息是不能跟聚合函数一起使用的,聚合多个信息变一个。
select *,sum(cost) from t_order ;
可以这么写:
select *,(select sum(cost) from t_order) from t_order ;
如果非要按照第一个写法,需要开窗
select *,sum(cost) over() from t_order ;
底层原理:先查询到第一条数据,saml,2018-01-01,10,然后进行 sum统计,统计的窗口是整个数据集。
接着查询第二条数据 xxxxx,然后进行 sum统计,统计的窗口是整个数据集,依次类推。
saml 2018-01-01 10 661
saml 2018-01-08 55 661
tony 2018-01-07 50 661
saml 2018-01-05 46 661
tony 2018-01-04 29 661
tony 2018-01-02 15 661
saml 2018-02-03 23 661
mart 2018-04-13 94 661
saml 2018-04-06 42 661
mart 2018-04-11 75 661
mart 2018-04-09 68 661
mart 2018-04-08 62 661
neil 2018-05-10 12 661
neil 2018-06-12 80 661
接着继续编写咱们的需求:
select *,sum(cost) over(distribute by substr(orderdate,1,7) ) from t_order ;
t_order.name t_order.orderdate t_order.cost sum_window_0
saml 2018-01-01 10 205
saml 2018-01-08 55 205
tony 2018-01-07 50 205
saml 2018-01-05 46 205
tony 2018-01-04 29 205
tony 2018-01-02 15 205
saml 2018-02-03 23 23
mart 2018-04-13 94 341
saml 2018-04-06 42 341
mart 2018-04-11 75 341
mart 2018-04-09 68 341
mart 2018-04-08 62 341
neil 2018-05-10 12 12
neil 2018-06-12 80 80
Time taken: 2.128 seconds, Fetched: 14 row(s)
指标5:需求:查看顾客的购买明细及每个顾客的月购买总额
select *,sum(cost) over(distribute by name,month(orderdate) ) from t_order ;
mart 2018-04-13 94 299
mart 2018-04-08 62 299
mart 2018-04-09 68 299
mart 2018-04-11 75 299
neil 2018-05-10 12 12
neil 2018-06-12 80 80
saml 2018-01-01 10 111
saml 2018-01-05 46 111
saml 2018-01-08 55 111
saml 2018-02-03 23 23
saml 2018-04-06 42 42
tony 2018-01-04 29 94
tony 2018-01-07 50 94
tony 2018-01-02 15 94窗口期:这个词我们经常听到,比如:穷人的孩子,上升渠道的窗口期马上就过去了。
sort by子句
sort by子句会让输入的数据强制排序 (强调:当使用排序时,窗口会在组内逐行变大)
语法:
语法: over([distribute by colname] [sort by colname [desc|asc]])需求6:查看顾客的购买明细及每个顾客的月购买总额,并且按照日期降序排序
select *,sum(cost) over(distribute by name,month(orderdate) sort by orderdate desc ) from t_order ;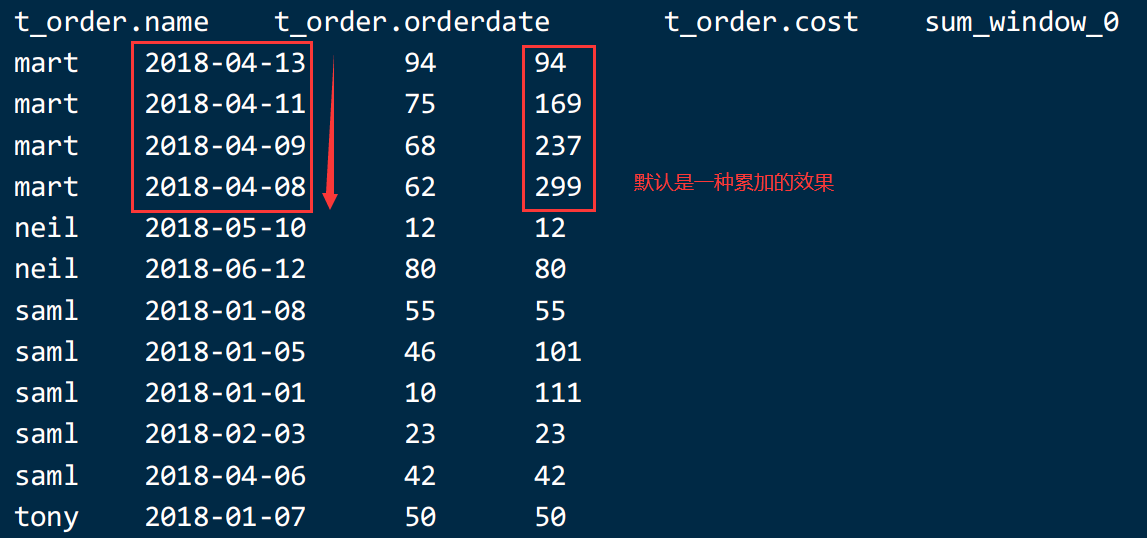
注意:可以使用partition by + order by 组合来代替distribute by+sort by组合
select *,sum(cost) over(partition by name,month(orderdate) order by orderdate desc ) from t_order ;注意:也可以在窗口函数中,只写排序,窗口大小是全表记录
select *,sum(cost) over(order by orderdate desc ) from t_order ;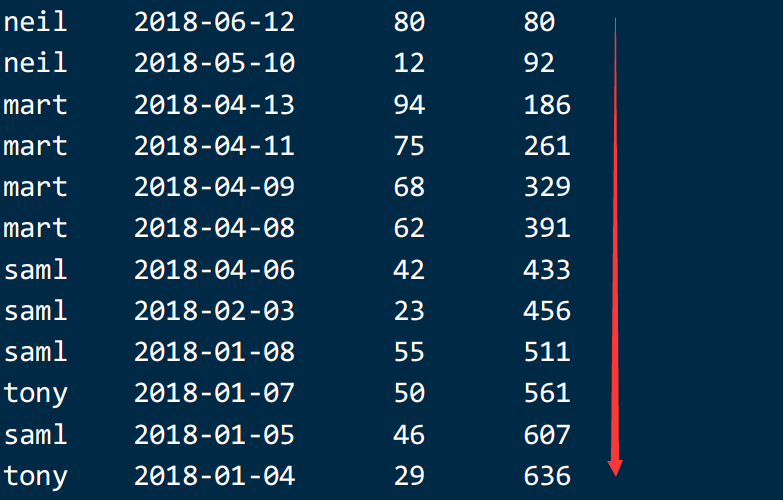
window 子句
如果要对窗口的结果做更细粒度的划分,那么就使用window子句,常见的有下面几个
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING:表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点 
解析这句话:
select name,orderdate,cost,
sum(cost) over() as sample1, -- 所有行相加
sum(cost) over(partition by name) as sample2,-- 按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,-- 按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,-- 与sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, -- 当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,-- 当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 -- 当前行及后面所有行
from t_order;运行结果:
name orderdate cost sample1 sample2 sample3 sample4 sample5 sample6 sample7
mart 2018-04-08 62 661 299 62 62 62 130 299
mart 2018-04-09 68 661 299 130 130 130 205 237
mart 2018-04-11 75 661 299 205 205 143 237 169
mart 2018-04-13 94 661 299 299 299 169 169 94
.....需求7:查看顾客到目前为止的购买总额
select *,sum(cost) over(rows between UNBOUNDED PRECEDING and current row)
from t_order;需求8:求每个顾客最近三次的消费总额
select *,sum(cost) over(partition by name order by orderdate rows between 2 PRECEDING and current row) from t_order;
t_order.name t_order.orderdate t_order.cost sum_window_0
mart 2018-04-08 62 62
mart 2018-04-09 68 130
mart 2018-04-11 75 205
mart 2018-04-13 94 237
neil 2018-05-10 12 12
neil 2018-06-12 80 92
saml 2018-01-01 10 10
saml 2018-01-05 46 56
saml 2018-01-08 55 111
saml 2018-02-03 23 124
saml 2018-04-06 42 120
tony 2018-01-02 15 15
tony 2018-01-04 29 44
tony 2018-01-07 50 94回过头来看以前的需求:求每个部门的员工信息以及部门的平均工资
select *,avg(sal) over(partition by deptno) from emp;注意:默认mysql老版本没有支持,在最新的8.0版本中支持, Oracle和Hive中都支持窗口函数。
2、序列函数
1)NTILE
ntile 是Hive很强大的一个分析函数。可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1
-- SQL语句:
select name,orderdate,cost,
ntile(3) over(partition by name) -- 按照name进行分组,在分组内将数据切成3份
from t_order;
-- 运行结果如下:
mart 2018-04-13 94 1
mart 2018-04-08 62 1
mart 2018-04-09 68 2
mart 2018-04-11 75 3
neil 2018-06-12 80 1
neil 2018-05-10 12 2
saml 2018-02-03 23 1
saml 2018-04-06 42 1
saml 2018-01-05 46 2
saml 2018-01-08 55 2
saml 2018-01-01 10 3
tony 2018-01-02 15 1
tony 2018-01-04 29 2
tony 2018-01-07 50 3
Time taken: 2.192 seconds, Fetched: 14 row(s)需求:获取一个表中,所有消费记录中,每一个人,最后50%的消费记录。
select name,orderdate,cost,
ntile(2) over(partition by name order by orderdate ) as xuhao
from t_order where xuhao = 2;
错误:where子句后面不能使用别名,当不能使用的时候要么复制一份,要么包一层
select name,orderdate,cost from (
select name,orderdate,cost,
ntile(2) over(partition by name order by orderdate ) as xuhao
from t_order ) t where t.xuhao=2;2)LAG和LEAD函数
lag返回当前数据行的前第n行的数据
语法:lag(colName,n[,default value]): 取字段的前第n个值。如果为null,显示默认值
lead返回当前数据行的后第n行的数据
需求:查询顾客上次购买的时间
select * ,lag(orderdate,1) over( partition by name order by orderdate ) from t_order;
mart 2018-04-08 62 NULL
mart 2018-04-09 68 2018-04-08
mart 2018-04-11 75 2018-04-09
mart 2018-04-13 94 2018-04-11
neil 2018-05-10 12 NULL
neil 2018-06-12 80 2018-05-10
saml 2018-01-01 10 NULL
saml 2018-01-05 46 2018-01-01
saml 2018-01-08 55 2018-01-05
saml 2018-02-03 23 2018-01-08
saml 2018-04-06 42 2018-02-03
tony 2018-01-02 15 NULL
tony 2018-01-04 29 2018-01-02
tony 2018-01-07 50 2018-01-04
select * ,lag(orderdate,1,'1990-01-01') over( partition by name order by orderdate ) from t_order;
mart 2018-04-08 62 1990-01-01
mart 2018-04-09 68 2018-04-08
mart 2018-04-11 75 2018-04-09
mart 2018-04-13 94 2018-04-11
neil 2018-05-10 12 1990-01-01
neil 2018-06-12 80 2018-05-10
saml 2018-01-01 10 1990-01-01
saml 2018-01-05 46 2018-01-01
saml 2018-01-08 55 2018-01-05
saml 2018-02-03 23 2018-01-08
saml 2018-04-06 42 2018-02-03
tony 2018-01-02 15 1990-01-01
tony 2018-01-04 29 2018-01-02
tony 2018-01-07 50 2018-01-04需求:求5分钟内点击100次的用户
dt id url
2019-08-22 19:00:01,1,www.baidu.com
2019-08-22 19:01:01,1,www.baidu.com
2019-08-22 19:02:01,1,www.baidu.com
2019-08-22 19:03:01,1,www.baidu.com
编写一个伪SQL:
select id,dt,lag(dt,100) over(partition by id order by dt)
from tablename where dt-lag(dt,100) over(partition by id order by dt)<5分钟
思路:先按照id分组,按照点击时间排序,获取从当前时间算起,前100次以前的时间,让当前时间-100次以前的时间,如果差值大于5分钟,说明该用户的数据是必须查出来的。3)FIRST_VALUE和LAST_VALUE
first_value 取分组内排序后,截止到当前行,第一个值
last_value 分组内排序后,截止到当前行,最后一个值
sql练习:
select name,orderdate,cost,
first_value(orderdate) over(partition by name order by orderdate) as time1,
last_value(orderdate) over(partition by name order by orderdate) as time2
from t_order;
name orderdate cost time1 time2
mart 2018-04-08 62 2018-04-08 2018-04-08
mart 2018-04-09 68 2018-04-08 2018-04-09
mart 2018-04-11 75 2018-04-08 2018-04-11
mart 2018-04-13 94 2018-04-08 2018-04-13
neil 2018-05-10 12 2018-05-10 2018-05-10
neil 2018-06-12 80 2018-05-10 2018-06-12
saml 2018-01-01 10 2018-01-01 2018-01-01
saml 2018-01-05 46 2018-01-01 2018-01-05
saml 2018-01-08 55 2018-01-01 2018-01-08
saml 2018-02-03 23 2018-01-01 2018-02-03
saml 2018-04-06 42 2018-01-01 2018-04-06
tony 2018-01-02 15 2018-01-02 2018-01-02
tony 2018-01-04 29 2018-01-02 2018-01-04
tony 2018-01-07 50 2018-01-02 2018-01-07
Time taken: 2.053 seconds, Fetched: 14 row(s)3、排名函数 -大名鼎鼎
row_number() rank() dense_rank()
1、row_number()
row_number从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列
效果如下:
98 1
97 2
97 3
96 4
95 5
95 6
没有并列名次情况,顺序递增2、rank()
生成数据项在分组中的排名,排名相等会在名次中留下空位
效果如下:
98 1
97 2
97 2
96 4
95 5
95 5
94 7
有并列名次情况,顺序跳跃递增3、dense_rank()
生成数据项在分组中的排名,排名相等会在名次中不会留下空位
效果如下:
98 1
97 2
97 2
96 3
95 4
95 4
94 5
有并列名次情况,顺序递增4、案例演示
1 gp1808 80
2 gp1808 92
3 gp1808 84
4 gp1808 86
5 gp1808 88
6 gp1808 70
7 gp1808 98
8 gp1808 84
9 gp1808 86
10 gp1807 90
11 gp1807 92
12 gp1807 84
13 gp1807 86
14 gp1807 88
15 gp1807 80
16 gp1807 92
17 gp1807 84
18 gp1807 86
19 gp1805 80
20 gp1805 92
21 gp1805 94
22 gp1805 86
23 gp1805 88
24 gp1805 80
25 gp1805 92
26 gp1805 94
27 gp1805 86建表,加载数据:
create table if not exists stu_score(
userid int,
classno string,
score int
)
row format delimited
fields terminated by ' ';
load data local inpath '/home/hivedata/stu_score.txt' overwrite into table stu_score;需求一:对每个班级的每次考试按照考试成绩倒序
select *,dense_rank() over(partition by classno order by score desc) from stu_score;
select *,dense_rank() over(order by score desc) `全年级排名` from stu_score;需求二:获取每次考试的排名情况
select *,
-- 没有并列,相同名次依顺序排
row_number() over(distribute by classno sort by score desc) rn1,
-- rank():有并列,相同名次空位
rank() over(distribute by classno sort by score desc) rn2,
-- dense_rank():有并列,相同名次不空位
dense_rank() over(distribute by classno sort by score desc) rn3
from stu_score;
运行结果:
26 gp1805 94 1 1 1
21 gp1805 94 2 1 1
25 gp1805 92 3 3 2
20 gp1805 92 4 3 2
23 gp1805 88 5 5 3
27 gp1805 86 6 6 4
22 gp1805 86 7 6 4
24 gp1805 80 8 8 5
19 gp1805 80 9 8 5
11 gp1807 92 1 1 1
16 gp1807 92 2 1 1
10 gp1807 90 3 3 2
14 gp1807 88 4 4 3
13 gp1807 86 5 5 4
18 gp1807 86 6 5 4
12 gp1807 84 7 7 5
17 gp1807 84 8 7 5
15 gp1807 80 9 9 6
7 gp1808 98 1 1 1
2 gp1808 92 2 2 2
5 gp1808 88 3 3 3
9 gp1808 86 4 4 4
4 gp1808 86 5 4 4
8 gp1808 84 6 6 5
3 gp1808 84 7 6 5
1 gp1808 80 8 8 6
6 gp1808 70 9 9 7需求三:求每个班级的前三名
select * from (
select * ,dense_rank() over(partition by classno order by score desc) as paiming from stu_score) t where paiming <=3;4、练习
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/home/hivedata/test_e.txt' into table score;1、计算每门学科成绩排名
select *,dense_rank() over (partition by subject order by score desc) from score;2、求出每门学科前三名的学生
select * from (
select *,dense_rank() over (partition by subject order by score desc) paiming from score
) t where paiming <=3;5、自定义函数
hive的内置函数满足不了所有的业务需求。hive提供很多的模块可以自定义功能,比如:自定义函数、serde、输入输出格式等。而自定义函数可以分为以下三类:
1)UDF: user defined function:用户自定义函数,一对一的输入输出 (最常用的)。比如abs()
2)UDAF: user defined aggregation function:用户自定义聚合函数,多对一的输入输出,比如:count sum max avg。
3) UDTF: user defined table-generate function :用户自定义表生产函数 一对多的输入输出,比如:lateral view explode大数据需要学习哪些编程语言?
sql、python、java、scala(java 的升级版)
1、将字母变大写案例
创建Maven项目:MyFunction
在pom.xml,加入以下maven的依赖包
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>需要继承一个类:继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF,并重写抽象方法。
需求:编写一个自定义函数,让其字母大写变小写
package com.bigdata;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class LowerString extends GenericUDF {
// 初始化操作
// 假如传递的参数个数不是1个,就抛异常
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length != 1) {
// 说明参数的数量不对
throw new UDFArgumentException("参数数量错误");
}
// 返回值类型检查
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
// 编写具体代码的地方
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 获取到传入进来的参数
String inputString = deferredObjects[0].get().toString();
// 逻辑处理
if (inputString == null || inputString.length() == 0) {
return "";
}
// abc
return inputString.toUpperCase();
}
// 返回自定义函数的描述
@Override
public String getDisplayString(String[] strings) {
return "该函数可以将大写的字母变为小写";
}
}
编写好之后,打包 package,变为一个jar包。
将该jar包放入 hive的lib文件夹下。
函数的加载方式:
第一种:命令加载 (只针对当前session有效)
1、将MyFunction-1.0-SNAPSHOT.jar 放入/opt/installs/hive/lib/目录下:
2. 将编写好的UDF打包并上传到服务器,将jar包添加到hive的classpath中
hive> add jar /opt/installs/hive/lib/MyFunction-1.0-SNAPSHOT.jar;
3. 创建一个自定义的临时函数名
hive> create temporary function myUpper as 'com.bigdata.LowerString';
4. 查看我们创建的自定义函数,
hive> show functions;
5.在hive中使用函数进行功能测试
select myUpper('yunhe');
6. 如何删除自定义函数?在删除一个自定义函数的时候一定要确定该函数没有调用
hive> drop temporary function if exists myupper;第二种方式:
1. 将编写好的自定函数上传到服务器
2. 写一个配置文件,将添加函数的语句写入配置文件中,hive在启动的时候加载这个配置文件
[root@yunhe01 ~]# vi $HIVE_HOME/conf/hive-init
文件中的内容如下
add jar /opt/installs/hive/lib/MyFunction-1.0-SNAPSHOT.jar;
create temporary function myUpper as 'com.bigdata.LowerString';
3. 启动hive时
[root@yunhe01 ~]# hive -i $HIVE_HOME/conf/hive-init第三种方式:
在.hiverc 文件中,添加
add jar /opt/installs/hive/lib/MyFunction-1.0-SNAPSHOT.jar;
create temporary function myUpper as 'com.bigdata.LowerString';
每次hive启动即可使用。2、输入 出生年月日求年龄 函数
1. age=当前年-生日的年份 2001-2-1 2024-2001 = 23
2. 判断月份,当前月份小于生日月份,age-1 2001-3-10 22
3. 月份相等,判断当前的日期,如果日期小于生日日期,age-1 2001-2-23 22代码演示:
package com.bigdata.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import java.time.Duration;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
/**
*/
public class BirthdayToAgeUDF extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// 1、检查参数的数量是否正确
if (objectInspectors.length != 1) {
throw new UDFArgumentException("参数的数量错误");
}
// 2、检查参数的类型是否正确
ObjectInspector inspector = objectInspectors[0];
if (!(inspector instanceof StringObjectInspector)) {
throw new UDFArgumentException("参数的类型错误");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 1、获取参数
String birthdayStr = deferredObjects[0].get().toString();
// 2、判断参数的有效性
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
try {
LocalDate birthday = LocalDate.parse(birthdayStr, formatter);
int birthYear = birthday.getYear();
int birthMonth = birthday.getMonthValue();
int birthDay = birthday.getDayOfMonth();
int nowYear = LocalDate.now().getYear();
int nowMonth = LocalDate.now().getMonthValue();
int nowDay = LocalDate.now().getDayOfMonth();
// 年龄计算
int age = nowYear - birthYear;
if (nowMonth < birthMonth) {
--age;
} else if (nowMonth == birthMonth && nowDay < birthDay) {
--age;
}
return age;
} catch (Exception ignore) {
return -1;
}
}
@Override
public String getDisplayString(String[] strings) {
return null;
}
}
hive (yhdb)> add jar /usr/local/hive-3.1.2/lib/MyFunction-1.0-SNAPSHOT.jar;
Added [/usr/local/hive-3.1.2/lib/MyFunction-1.0-SNAPSHOT.jar] to class path
Added resources: [/usr/local/hive-3.1.2/lib/MyFunction-1.0-SNAPSHOT.jar]
hive (yhdb)> create temporary function myAge as 'com.bigdata.udf.BirthdayToAgeUDF';
OK
Time taken: 0.048 seconds
hive (yhdb)> select myAge('1987-02-06');
OK
35
Time taken: 0.187 seconds, Fetched: 1 row(s)另外一种写法:
package com.bigdata;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
public class BirthdayToAgeUDF extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length != 1) {
// 说明参数的数量不对
throw new UDFArgumentException("参数数量错误");
}
// 返回值类型检查
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 获取参数
String birthday = deferredObjects[0].get().toString();
// 获取用户输入的年月日
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd");
int age = -1;
try {
Date date = format.parse(birthday);
// 想要年月日
Calendar c = Calendar.getInstance();
c.setTime(date);
int year = c.get(Calendar.YEAR);
int month = c.get(Calendar.MONTH);
int day = c.get(Calendar.DAY_OF_MONTH);
// 获取当前时间的年月日
Calendar c1 = Calendar.getInstance();
int year2 = c1.get(Calendar.YEAR);
int month2 = c1.get(Calendar.MONTH);
int day2 = c1.get(Calendar.DAY_OF_MONTH);
// 根据规则比较
age = year2 - year;
if(month2 < month){
age--;
}else if(month2 == month && day2 < day){
age--;
}
} catch (ParseException e) {
throw new RuntimeException(e);
}
return age;
}
@Override
public String getDisplayString(String[] strings) {
return "将出生年月变为年龄";
}
}
面试过程中经常问这两个问题:
1、你自定义过函数吗?定义过哪些函数?
2、你写过脚本吗?你编写过什么脚本?
开始积攒这些问题的答案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









