







数据结构
数据结构是计算机存储、组织数据的方式。
在现实世界中,不同数据元素之间不是独立的,而是存在特定关系的,我们将这些关系称为结构。
同样在计算机中,数据元素也不是孤立、杂乱无序的,而是具有内在联系的数据集合。
按照不同的角度,数据结构可分为逻辑结构和物理结构。
其中逻辑结构是面向问题的,
而物理结构是面向计算机的,
它们的基本目标都是将数据及其逻辑关系存储到计算机内存中。
逻辑结构
逻辑结构:是指数据对象中数据元素之间的相互关系。分为四种:集合结构、线性结构、树形结构和图形结构。

物理结构
物理(存储)结构:是指数据的逻辑结构在计算机中的存储形式。数据的存储结构应正确反映数据元素之间的逻辑关系,这是关键。
数据元素的存储结构可分为两种:顺序存储结构 和 链式存储结构。
顺序存储结构:
把数据元素放在地址连续的存储单元中,数据间的逻辑关系和物理关系一致。如,数组。
链式存储结构:把数据元素放在任意的存储单元中,数据间使用指针关联。
数据元素的存储关系不能反映其逻辑关系。如,链表。
算法
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
算法的基本特性:
- 输入,算法具有零个或多个输入,
- 输出,至少有一个或多个输出。
- 有穷性,算法在执行有限步后能够自动结束,不会出现无限循环。
- 确定性,算法的每一步都具有确定的含义,不会出现二义性。
- 可行性,算法的每一步都能够通过执行有限次操作完成。
算法的复杂度
算法复杂度分为时间复杂度和空间复杂度。
时间复杂度是指执行算法所需要的计算工作量(时间)
空间复杂度是指执行这个算法所需要的内存空间
时间复杂度
算法的时间复杂度反映了算法执行的时间长短,它是度量一个算法好坏的重要指标。
度量一个算法的时间复杂度通常采用“大O表示法”
时间复杂度的几条基本计算规则:
- 基本操作,即只有常数项,认为其时间复杂度为O(1)
- 顺序结构,时间复杂度按加法进行计算
- 循环结构,时间复杂度按乘法进行计算
- 分支结构,时间复杂度取最大值
- 判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
- 在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度

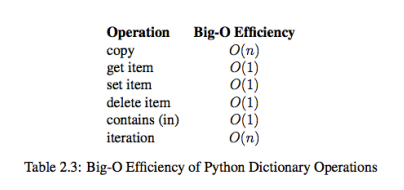
list类型时间复杂度

dict类型时间复杂度
举个例子:
for i in range(1):
print(i) # 时间复杂度是O(1)
for i in range(n):
print(i) # 时间复杂度是O(n)
for i in range(n):
for j in range(n):
print(i,j) # 时间复杂度是O(n2)
线性表
线性表是具有零个或多个数据元素的有限序列。线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。
线性表的基本特征:
第一个数据元素没有前驱元素;
最后一个数据元素没有后继元素;
其余每个数据元素只有一个前驱元素和一个后继元素。
抽象数据类型:
线性表一般包括插入、删除、查找等基本操作。
线性表按物理存储结构的不同可分为顺序表(顺序存储)和链表(链式存储):
顺序表(存储结构连续)
链表(存储结构上不连续,逻辑上连续)
顺序表
顺序表是在计算机内存中以一组地址连续的存储单元依次存储数据元素的线性结构。

顺序表效率分析:
顺序表插入和删除一个元素,最好情况下其时间复杂度(这个元素在最后一个位置)为O(1),最坏情况下其时间复杂度为O(n)。
顺序表支持随机访问,读取一个元素的时间复杂度为O(1)。
顺序表的优缺点:
优点:支持随机访问
缺点:插入和删除操作需要移动大量的元素,造成存储空间的碎片。
顺序表适合元素个数变化不大,且更多是读取数据的场合。Python中的list和tuple两种类型采用了顺序表的实现技术
链表
为什么需要链表?
顺序表的构建需要预先知道数据大小来申请连续的存储空间,而在进行扩充时又需要进行数据的搬迁,所以使用起来并不是很灵活。
链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
那什么是链表呢?
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是不像顺序表一样连续存储数据,而是在每一个节点(数据存储单元)里存放下一个节点的位置信息(即地址)。
链表可分为单向链表、单向循环链表和双向链表

这里分别做解释:
单向链表
单向链表也叫单链表,是链表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域。这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。

单向循环链表
单链表的一个变形是单向循环链表,链表中最后一个节点的next域不再为None,而是指向链表的头节点。
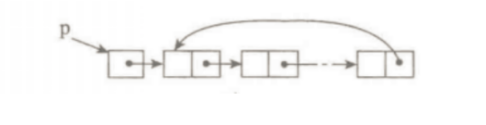
双向链表
一种更复杂的链表是“双向链表”或“双面链表”。每个节点有两个链接:一个指向前一个节点,当此节点为第一个节点时,指向空值;而另一个指向下一个节点,当此节点为最后一个节点时,指向空值。
链表与顺序表的对比
链表失去了顺序表随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大,但对存储空间的使用要相对灵活。
链表与顺序表的各种操作复杂度如下所示:
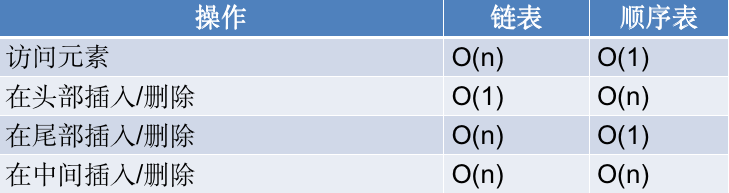
注意虽然“在中间插入/删除”表面看起来复杂度都是 O(n),但是链表和顺序表在插入和删除时进行的是完全不同的操作。链表的主要耗时操作是遍历查找,删除和插入操作本身的复杂度是O(1)。顺序表查找很快,主要耗时的操作是拷贝覆盖。因为除了目标元素在尾部的特殊情况,顺序表进行插入和删除时需要对操作点之后的所有元素进行前后移位操作,只能通过拷贝和覆盖的方法进行。
栈与队列
栈
栈(也称下压栈,堆栈)是仅允许在表尾进行插入和删除操作的线性表。
我们把允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom)。
栈是一种后进先出(Last In First Out)的线性表,简称(LIFO)结构。

具体代码操作
Stack() 创建一个新的空栈
push(item) 添加一个新的元素item到栈顶
pop() 弹出栈顶元素
peek() 返回栈顶元素
is_empty() 判断栈是否为空
size() 返回栈的元素个数
队列
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。

具体代码操作
Queue() 创建一个空的队列
enqueue(item) 往队列中添加一个item元素
dequeue() 从队列头部删除一个元素
is_empty() 判断一个队列是否为空
size() 返回队列的大小
栈和队列的区别
栈与队列,它们都是特殊的线性表,只是对插入和删除操作做了限制。
栈限定仅能在栈顶进行插入和删除操作,而队列限定只能在队尾插入,在队头删除。
栈:后进先出
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列:先进先出
它们都可以使用顺序存储结构和链式存储结构两种方式来实现。
树
树(英语:tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:
每个节点有零个或多个子节点;
没有父节点的节点称为根节点;
每一个非根节点有且只有一个父节点;
除了根节点外,每个子节点可以分为多个不相交的子树;
术语
节点的度:一个节点含有的子树的个数称为该节点的度;
树的度:一棵树中,最大的节点的度称为树的度;
叶节点或终端节点:度为零的节点;
父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:父节点在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>0)棵互不相交的树的集合称为森林;
种类
无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
二叉树:每个节点最多含有两个子树的树称为二叉树;
完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
霍夫曼树(用于信息编码):带权路径最短的二叉树称为霍夫曼树或最优二叉树;
B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
应用场景
- xml,html等,编写这些东西的解析器的时候,不可避免用到树
- 路由协议就是使用了树的算法
- mysql数据库索引(B+树)
- 文件系统的目录结构
- 很多经典的AI算法其实都是树搜索















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









