






01
模块化数字人对话系统
OpenAvatarChat 是一个由 HumanAIGC-Engineering 团队开发的模块化数字人对话系统,通过简单配置,在单台电脑上实现与虚拟数字人的实时交互。它结合了语音识别、语言模型、语音合成和数字人动画技术,提供低延迟、高流畅度的对话体验。
① 实时语音对话
用户说话结束后,数字人平均 2.2秒内 即可开始回答(测试环境:i9-13900KF + RTX 4090)。支持 本地或云端语言模型,用户可根据硬件条件灵活选择。
② 模块化设计
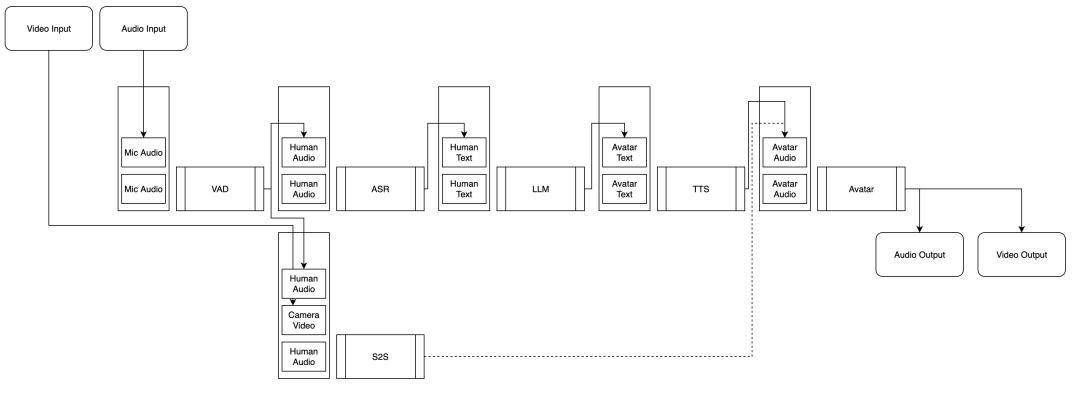
各功能模块可独立替换(如语音识别、语言模型、语音合成等),方便定制和扩展。关键模块如下:
• 语音检测(VAD):判断用户何时开始/结束说话(基于 silero-vad)。
• 语音识别(ASR):将语音转为文字(支持 SenseVoice 模型)。
• 语言模型(LLM):生成回答文本(默认用 MiniCPM-o,也支持阿里云“通义千问”等云端API)。
• 语音合成(TTS):将文本转为语音(基于 CosyVoice,支持自定义音色)。
• 数字人动画:根据语音生成面部表情和动作(lite-avatar,CPU推理可达30帧/秒)。
③多模态支持(实验性)
语言模型 MiniCPM-o 可处理文本和图像输入,但需较高显存(20GB以上),开启后可能影响性能。最低配置:
• GPU:支持CUDA,若使用量化版语言模型(int4),显存需 ≥10GB。
• CPU:推荐高性能CPU(如i9-13980HX)以保证数字人动画流畅。
• Python 3.10+,需安装 git-lfs 下载大模型文件。
云端替代方案:若本地配置不足,可改用云端LLM API(如阿里云“百炼”),大幅降低显存需求。
开源地址:https://github.com/HumanAIGC-Engineering/OpenAvatarChat02
让静态肖像“活起来”
LivePortrait 是一个开源工具,能够将照片或视频中的人物/动物肖像变成生动的动画。比如,你可以让一张证件照里的人像根据视频中的动作眨眼、微笑,甚至让宠物图片模仿真实动物的表情。

开源地址:https://github.com/KwaiVGI/LivePortrait① 灵活驱动方式
• 图像/视频驱动:用一张图片+动作视频,生成动态肖像。

• 视频到视频编辑(v2v):直接修改原视频中人物的表情动作。
• 区域控制:精细调整面部特定区域(如嘴巴、眼睛)的动画效果。
② 支持多类型对象
人类肖像(主推功能)和动物模型(如猫狗)均可动画化。

③ 高效与隐私保护
• 预提取动作模板:将驱动视频转换为轻量的 .pkl 文件,加快处理速度,同时避免直接使用他人视频泄露隐私。
• 自动裁剪优化:自动截取视频中的头部区域,减少无效背景干扰。
④ 易用性设计
• 提供 Gradio 网页界面,无需代码操作即可体验;支持 Windows、Linux 和 macOS(苹果芯片)系统。
⑤ 技术亮点
• 缝合控制(Stitching):确保生成动画时面部特征自然过渡,减少扭曲。
• 重定向控制(Retargeting):将驱动视频中的动作精准映射到不同人物/动物肖像上。
• 多尺度形变注意力机制:提升关键点检测精度,使动画更逼真。
03
实时高质量唇形同步模型
MuseTalk 是由腾讯音乐娱乐集团(TME)Lyra 实验室开发的一款实时高质量唇形同步模型。它能将任意输入视频或图片中的人物嘴唇动作,精准匹配到输入的音频上(如说话、唱歌),生成口型自然的视频。
开源地址:https://github.com/TMElyralab/MuseTalk其核心优势在于:
• 实时性:在 NVIDIA Tesla V100 显卡上可达 30 帧/秒以上。
• 多语言支持:中文、英文、日文等音频均可处理。
• 高分辨率:唇部区域处理分辨率为 256x256,优于多数开源方案。
• 灵活调整:通过参数控制唇部张合程度,适配不同场景需求。
模型在图像压缩后的“潜在空间”中直接修复唇部区域(非逐像素处理),提升效率。
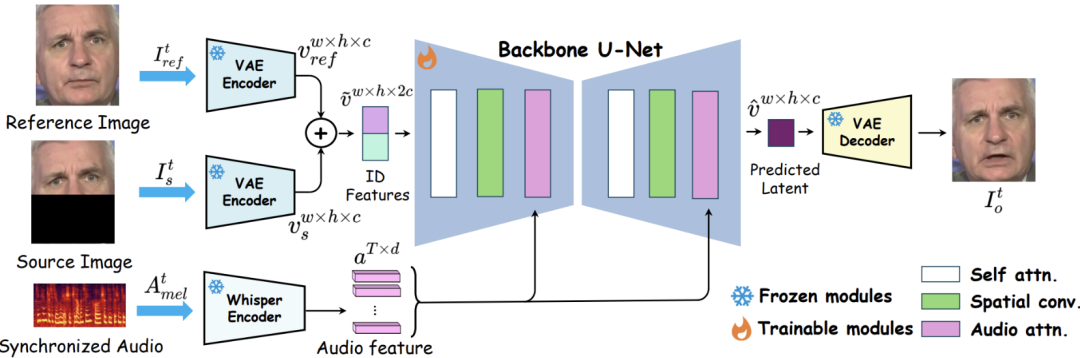
• 音频编码:使用 Whisper-tiny 模型提取语音特征。
• 图像编码:采用预训练的 ft-mse-vae 模型压缩图像。
• 融合生成:借鉴 Stable Diffusion 的 UNet 结构,通过交叉注意力机制融合音频与图像特征,单步完成修复(非扩散模型)。
• 训练数据:基于 HDTF 数据集(多人种、多场景视频)。
04
点击下方卡片,关注我
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









