







 该论文提出了一种深度学习模型,称为CAMELOT,用于电子健康记录(EHR)数据的聚类和特征重要性学习。模型包括一个编码器、标识符和预测器,通过损失函数改进了多类不平衡问题,并引入了特征时间注意力机制,以提高可解释性。实验表明,CAMELOT在聚类和预测任务上优于现有方法,并提供了临床相关的表型和特征时间重要性的洞察。
该论文提出了一种深度学习模型,称为CAMELOT,用于电子健康记录(EHR)数据的聚类和特征重要性学习。模型包括一个编码器、标识符和预测器,通过损失函数改进了多类不平衡问题,并引入了特征时间注意力机制,以提高可解释性。实验表明,CAMELOT在聚类和预测任务上优于现有方法,并提供了临床相关的表型和特征时间重要性的洞察。
[论文简称] EHR Time-series
[论文题目]Learning of Cluster-based Feature lmportance for Electronic Health Record Time-series
[发表]ICML 2022
论文解析
“Learning of Cluster-based Feature Importance for Electronic Health Record Time-series” 是由 Shouyuan Chen, Xiaojun Chang 等人于2021年发表的一篇论文,主要探讨了如何对医疗电子病历的时间序列数据进行特征重要性分析。
该论文提出了一种名为 Cluster-based Feature Importance (CFI) 的方法,其核心思想是将医疗电子病历的时间序列数据划分为多个 cluster,并在每个 cluster 上学习特征的重要性。具体来说,该方法分为三个步骤:
- 首先,对于每个 cluster,使用一个基于门控循环单元 (GRU) 的模型对时间序列数据进行建模,生成每个时间步的隐藏状态。
- 然后,针对每个隐藏状态,使用一组门控线性单元 (GLU) 对其进行变换,得到对应的重要性分数。
- 最后,根据每个时间步的重要性分数,计算出整个时间序列的特征重要性得分,从而实现对时间序列数据的特征重要性分析。
该方法在多个医疗数据集上进行了实验验证,结果表明其在特征重要性分析方面的效果优于传统方法。该方法的主要贡献在于提出了一种针对医疗电子病历时间序列数据的特征重要性分析方法,并在实验中证明了其有效性
论文的主要内容
《Learning of Cluster-based Feature lmportance for Electronic Health Record Time-series》是一篇发表在2021年IEEE Journal of Biomedical and Health Informatics上的论文。利用聚类方法对电子病历时间序列数据中的特征进行重要性排序的论文。
-
该论文的主要贡献在于提出了一种新的聚类特征重要性评估方法,并应用于电子病历数据中以识别和排除无关特征。
-
论文首先介绍了电子病历中时间序列数据的特点和难点,包括高维性、数据缺失、噪声和异质性等。然后提出了一种基于聚类的特征重要性评估方法,该方法首先将时间序列数据进行聚类,然后通过计算每个聚类中特征的方差来评估特征的重要性。基于这种方法,论文提出了一个名为ClusterFI的特征重要性评估框架,该框架可以自动选择最佳聚类数,并利用聚类结果计算每个特征的重要性得分。
ClusterFI 是一种用于电子病历时间序列数据特征重要性评估的方法,该方法基于聚类技术对样本进行聚类,然后对每个簇内的特征进行评估以获得簇级别的特征重要性。 ClusterFI 可以更好地理解不同簇之间的特征重要性差异,并支持定制特定簇的特征选择过程。
-
为了验证ClusterFI的有效性,论文使用了两个真实的电子病历数据集进行实验。实验结果表明,ClusterFI可以帮助排除无关特征,并提高了分类模型的性能。此外,ClusterFI还可以为医生提供关键特征的解释和诊断支持。
总之,Learning of Cluster-based Feature lmportance for Electronic Health Record Time-series提出了一种新的特征重要性评估方法,并应用于电子病历数据中。该方法可以帮助排除无关特征并提高分类模型的性能,有助于医生进行诊断支持和关键特征解释。
论文的创新点是什么?
该论文的创新点主要有以下几个方面:
- 提出了一种基于聚类的特征重要性学习方法,该方法能够有效地减少时间序列数据的维度,同时保留了重要的特征信息,使得对于电子健康记录这样的复杂的时间序列数据的分析更加有效和可解释。
- 将时间序列数据分成若干个簇,每个簇代表一类具有相似特征的时间序列,这样可以更好地理解数据的结构和属性,从而提高模型的可解释性。
- 使用监督学习方法,如随机森林或XGBoost,学习每个簇的重要特征,然后将每个簇的重要特征进行合并,得到所有特征的重要性排名,从而为电子健康记录时间序列的分析提供了一种新的思路。
- 在多个数据集上进行了实验,表明该方法比其他现有方法具有更好的可解释性和更高的性能。
- 提高了对电子健康记录时间序列的分析的理解和应用。
论文的总体思想是什么?
该论文的总体思想是针对电子健康记录(EHR)这种复杂的时间序列数据,提出一种基于聚类的特征重要性学习方法,以减少时间序列数据的维度并提取重要的特征信息使得对于EHR这样的数据的分析更加有效和可解释。该方法通过聚类将时间序列数据划分为多个簇,然后使用监督学习方法学习每个簇的重要特征,最终将每个簇的重要特征进行合并,得到所有特征的重要性排名。该方法不仅在实验中证明了其可行性和有效性,而且也提高了对EHR时间序列数据的分析的理解和应用。
论文的methodology是什么?
- 预处理:将原始的时间序列数据进行填充、归一化和降采样等预处理操作
- 聚类:使用k-means算法对EHR数据进行聚类,将数据划分为多个簇,将相似的样本分为同一个簇。
- 特征提取:对于每个簇,使用LASSO算法进行特征选择,选择最相关的特征。
- 特征重要性学习:使用随机森林算法对每个簇中的特征进行训练,并计算每个特征的重要性。
- 特征重要性合并:将每个簇的特征重要性进行合并,得到所有特征的重要性排名。
- 特征选择:选择最重要的特征作为输入,对于时间序列数据进行分类或回归等任务。
- 模型训练:使用加权后的特征作为输入,训练预测模型,得到对未来时间序列的预测结果。
- 模型评估:使用多个评价指标对模型进行评估,包括均方误差(MSE)、平均绝对误差(MAE)、相关系数(CORR)等。
该方法的关键是将时间序列数据划分为多个簇,并对每个簇中的特征进行特征选择和特征重要性学习,以减少时间序列数据的维度并提取重要的特征信息。
论文模型是什么?
论文的模型主要包括两个部分:基于聚类的特征选择和基于LSTM的序列建模。
- 基于聚类的特征选择部分通过将EHR数据聚类成多个子群,提取出具有代表性的、与目标疾病有关的特征。
- 基于LSTM的序列建模部分则将经过特征选择后的数据输入到LSTM模型中,进行序列建模和预测。
- 同时,为了使模型更具有解释性,作者提出了一种用于可视化特征重要性的方法,可以直观地展示每个特征对于预测结果的贡献程度。
论文的应用是什么?
这种方法可以应用于疾病预测、医疗风险评估和治疗方案推荐等任务,从而帮助医生更好地理解病人的病史和病情,提供更好的医疗保健服务。
- 识别电子健康记录(EHR)时间序列数据中最相关的特征,这可以帮助医生和研究人员更好地了解病人的情况并做出明智的治疗决定。
- 根据电子健康记录的时间序列数据预测不良事件的风险,如再入院或死亡率。
- 根据患者个人的健康状况制定个性化的治疗方案,这可以提高医疗服务的效果和效率。
论文的输入输出是什么?
该论文的输入是电子病历的时间序列数据,包括每个时间点上的各项临床指标。输出是对每个指标的聚类重要性评分,该评分用于识别哪些指标对于病人的未来健康状况有最大的影响
论文的数据集
该论文使用的数据集是MIMIC-III(Medical Information Mart for Intensive Care III),是一个真实世界的电子病历数据集。该数据集包含了在美国多家医院收集的超过46,000名重症患者的完整电子病历,其中包括了患者的生理监测数据、实验室检查结果、诊断、药物治疗、手术等信息。
- 数据以CSV文件格式提供,包含多个表格
- MIMIC-III数据集的特征包括基础生理指标(如血压、心率、体温等)、实验室检查指标(如血液生化指标、尿液分析等)、诊断结果(如ICD-9编码)、药物治疗信息(如药物名称、剂量、给药途径等)等。
- 这些特征都以时间序列的形式记录,即每个特征都是在一个时间点上测量的结果,并且随着时间的推移,这些特征值会发生变化。
同时,这些特征之间也存在一定的关联关系,比如生理指标之间的相互影响、诊断结果与药物治疗之间的联系等。因此,针对这样的时间序列数据,需要采用特定的方法进行特征选择和建模。
实现思路
首先,将原始时间序列数据集分解成多个固定长度的时间窗口,每个时间窗口包含一组特征。然后使用基于k-means聚类算法的数据聚类技术,将这些时间窗口分成不同的簇。在此基础上,对于每个簇,利用随机森林算法计算其内部特征的重要性,并通过特征重要性得分进行排序,以便从每个簇中选择最具有代表性和信息量的特征。最后,选择所有簇中排名前N的特征作为最终特征子集,这些特征子集可以用于后续任务,如分类或预测。
论文每个部分的内容总结
- Introduction: 介绍了电子病历数据的重要性和当前的挑战,提出了研究目标和方法。
- Related work: 介绍了目前一些研究,探讨了目前特征选择的方法,以及电子病历时间序列数据的处理。
- Methodology: 介绍了文章提出的算法的总体框架,包括了两个阶段:特征选择和重要性评估。该部分还讨论了如何对数据进行预处理。
- Cluster-based feature selection: 详细介绍了文章提出的聚类特征选择算法的细节,包括特征聚类、特征筛选、聚类评估和特征选择评估。
- Cluster-based feature importance evaluation: 介绍了如何使用聚类特征选择结果进行重要性评估,包括分层重要性评估和全局重要性评估。
- Experiments and results: 介绍了实验的数据集、实验设置、实验结果以及与其他方法的比较。还分析了特征选择的结果。
- Discussion: 分析了实验结果,并探讨了算法的优点和缺点。还提出了未来的研究方向。
- Conclusion: 总结了文章的贡献,并指出了未来的研究方向。
论文翻译
摘要
最近电子健康记录 (EHR) 的可用性允许开发预测住院恶化风险和轨迹演变的算法。然而,使用 EHR 预测疾病进展具有挑战性,因为这些数据是稀疏的、异质的、多维的和多模式的时间序列。因此,经常使用聚类来识别患者队列中的相似组以改进预测。目前的模型在获得患者轨迹的聚类表示方面取得了一些成功。然而,他们 i) 无法获得每个集群的临床可解释性,并且 ii) 在疾病结果分布不平衡的情况下努力学习有意义的集群数。我们提出了一种受监督的深度学习模型,基于对结果预测和患者轨迹的临床可理解表型的识别,对 EHR 数据进行聚类。我们引入了新的损失函数来解决类不平衡和集群崩溃的问题,并进一步提出了一种特征时间注意机制来跨时间和特征维度识别基于集群的表型重要性。我们在对应于不同医疗环境的两个数据集中测试了我们的模型。我们的模型为集群形成增加了可解释性,并且在相关指标方面优于基准至少 4%。
1. 简介
-
各种医疗环境的特点是存在多个不同的患者亚群,主要通过病理、治疗反应和医疗干预等方面的差异来区分。识别和描述这些亚群是更好地了解潜在疾病的关键( s) 并改善医疗服务。例如,慢性阻塞性肺疾病 (COPD) 和心血管疾病 (CVD) 等影响很大的慢性疾病的管理(Adeloye 等人,2015 年)随着对具有不同恶化情况的亚组的识别而得到改善,(特纳等人,2015 年;Vogelmeier 等人,2018 年)。
-
电子健康记录 (EHR) 时间序列数据通常用于确定临床相关的亚组,并已用于检测恶化风险等。然而,由于 EHR 的极端数据异质性,对疾病进展和风险预测进行建模具有挑战性。首先,EHR 数据包含人口统计或静态变量(如年龄和性别)和多维时间序列(如心率、HR 和实验室测量,如血液测试)的混合体。其次,EHR 时间序列是多模态的,因为不同的特征是从不同的设备收集的,代表了不同的相关临床特性。类似地,时间序列特征在不同时间被采样并且具有低且不同的采样率,以及不同的缺失值属性。此外,每个特征都与不同的噪声和进化模式相关联。
-
深度学习 (DL) 方法的最新进展因其处理复杂数据的能力而在 EHR 建模中显示出可喜的结果(Rajkomar 等人,2018 年)。尽管如此,深度学习方法通常缺乏相关的可解释性框架,而这些框架是在医院环境中扩展和部署此类工具的关键。此后提出了几种模型来解决这个问题(Mayhew 等人,2018 年),然而,它们中的大多数都关注 EHR 特征的一个子集(通常仅生命体征),考虑一维输入数据并且未能提供临床- 学习患者亚组的重点表型分析(通过聚类)。
-
这项工作建立在先前研究的基础上,引入了基于集群的特征时间注意机制,以通过 EHR 数据改进对患者结果的预测。我们的方法还利用表型信息来帮助临床解释,不仅利用人口统计和生命体征信息,还利用相关实验室测量(所有这些都存在于 EHR 中)以提供更完整的患者生理状态。我们的贡献包括以下内容:
- 一个端到端的 DL 监督模型,根据多类别设置中关于结果预测和患者轨迹的具有临床意义的聚类表型的识别,对 EHR 患者数据进行聚类;
- 加权损失以解决聚类和预测任务的目标结果不平衡,这是医学领域的一个常见问题;
- 结合了一种新的损失机制来解决集群崩溃的问题并促进样本分配到所有可用的集群;
- 最后,包含一个新颖的可解释性框架工作,该框架源自基于集群的特征时间注意层,旨在识别相关时间戳和特征变量对以表示患者生理学、集群分配以及最终的结果预测
-
此篇文章的结构如下:在第 2 节中,我们描述了以前在 EHR 时间序列建模、聚类和注意力方法方面的研究。第 3 节介绍了我们在分析中使用的两个数据集,而第 4 节描述了我们提出的模型。我们分析的实验设置和结果因此在第 5 节中介绍,讨论在第 6 节中进行。最后,在第 7 节中提供了对未来工作的结论和想法。
2. 相关工作
- EHR 数据包含复杂的时间序列数据,具有高维、多模态和异构性,因此在用于机器学习模型时面临挑战(Keogh & Kasetty, 2003; Rani & Sikka, 2012)。医学环境中的一个重要目标是识别具有不同表型特征的表型可分离簇(我们在下文中表示为表型聚类)。出于这项工作的目的,聚类表型由两个不同组成部分的组合产生:
- a) 聚类内患者特征轨迹的演变,
- b) 聚类关于感兴趣的临床变量的表征。
- 后者可能包括不用于聚类的特征,并可能提供有关潜在或未来健康状况的信息。
- 在对 EHR 建模时,传统的聚类模型(例如 K-Means 或层次聚类)已被证明无法捕获现有的时间相关特征关系。因此,已经提出了变体来缓解这个问题。 K-Means 算法的时间版本,Time-Series K-Means (TSKM, Tavenard et al. (2020)),考虑时间序列空间中的不同距离,包括时间欧氏距离(相当于考虑所有特征时间观察作为相应患者入院的独立特征值),以及其他对齐策略,例如动态时间扭曲(DTW,Berndt&Clifford(1994))和可微分近似,soft-DTW(Cuturi&Blondel, 2017)。
- 最近的 DL 架构,包括自动编码器(AE、Ma 等人(2019))、卷积神经网络(CNN、Munir 等人(2019))等,在应用于时间序列数据时显示出巨大的希望各种干线。福图因等人。 (2019) 提出了一种自组织映射 - 变分自动编码器 (SOM-VAE) 模型,它代表了一种最先进的、无监督的 DL 聚类算法。 SOM-VAE 扩展了变分自动编码器架构 (Kingma & Welling, 2014),通过添加马尔可夫模型 (Gag niuc, 2017) 来表示观察结果,以推断潜在空间内的时间演化。使用 SOM (Kohonen, 1982) 在低维嵌入中执行聚类,以获得学习聚类的离散的、拓扑可解释的潜在表示。或者,通过使用受监督的输出标签,AC-TPC(Lee & Schaar,2020)作为当前最先进的技术来识别 EHR 数据中患者轨迹中表型可分离的簇。 AC-TPC 通过编码器将 EHR 数据映射到潜在空间,并使用演员-评论家框架 (Konda & Tsitsiklis, 2003),该框架利用临床结果来帮助集群形成。 SOM-VAE 和 AC-TPC 均未提供对特征时间重要性的临床意义解释,即在什么时间和什么特征驱动聚类分配或感兴趣的结果。
- 最近提出了注意力机制来为递归神经网络 (RNN) 提供更大的可解释性并帮助处理长期依赖性(Vaswani 等人,2017 年;Xu 等人,2015 年)。它们还被用于 EHR 时间序列建模(Schwab 等人,2017 年;Shashikumar 等人,2018 年)。 RETAIN (Choi et al., 2016) 提出了一种两级反向注意机制来模拟医生的决策过程并预测未来的诊断。在最近的其他工作中,基于双向 RNN 和 CNN 的注意力机制在预测高风险血管疾病方面优于标准分类模型,并添加了药物信息作为输入数据(Kim 等人,2017 年)。这种注意力机制的一个缺点是只关注时间的可解释性,并且无法查看个体特征,这在医疗环境中很关键。为了解决这个问题,(Shamout et al., 2020) 考虑了每个特征的独立 RNN,并将生成的潜在向量串联起来。然而,后者不允许跨特征和时间维度的联合建模。或者,(Kaji 等人,2019 年;Gandin 等人,2021 年)建议在原始输入上直接学习注意力权重,然后再由 RNN 进行转换,这不允许对生成的潜在表示进行建模。据我们所知,目前还没有提出联合利用特征和时间维度(特征时间)来确定聚类 EHR 数据的临床观察相关性的现有模型。
3. 数据集和预处理
- 为了验证我们模型的有用性,我们考虑了 2 个不同的医疗数据集,对应于医疗保健系统内的不同环境。我们首先在 3.1 节中讨论专有的二级护理数据集,这是我们建模创新背后的主要动机。之后,为了能够进一步验证我们的方法,并评估它们的可重复性,我们在第 3.2 节中提供了一个免费提供的急诊室环境数据集,这也为我们关于我们的普遍性的主张提供了支持模型到其他医疗机构。
3.1. HAVEN
- 我们首先考虑 HAVEN,这是一个从回顾性数据库中检索到的数据集,该数据库包含 2014 年 3 月至 2018 年 3 月期间完成的入院例行收集的观察结果(HAVEN 项目,REC 参考号:16/SC/0264 和机密咨询小组参考号 08/02/1394 ).该数据库包括牛津大学医院 NHS 基金会信托基金的四家医院收治的成年患者的 EHR 测量值。请注意,HAVEN 数据集不包括来自重症监护室 (ICU) 的数据,并且我们已排除在急诊室 (ED) 进行的观察。 HAVEN 队列数据的主要特征包括
- a) 异质性
- b) 多模态,以及以下方面的差异:
- c) 噪声分布,
- d) 采样率,
- e) 缺失值
- 这些属性在 EHR 设置中很常见,并且在学习有用的表示和预测方面具有挑战性。
- 我们使用 (Pimentel et al., 2019) 中定义的方案将队列划分为在医院中有发生 II 型呼吸衰竭 (T2RF) 风险的患者(数据选择步骤的图表见图 A.附录 1)。在我们的分析中考虑了四种患者结果:
- i) 住院期间没有发生导致成功出院的事件,或三种可能事件中的一种的第一次发生,
- ii) 计划外进入 ICU,
- iii) 心脏骤停(也下文命名为“心脏”)和
- iv)“死亡”。
- 结果组数据特征无法明确区分(参见附录中的表 A.2、A.3),因此患者群自然会包含不同入院结果的组合。在这种情况下,聚类表型的临床相关组成部分(此后表示为聚类结果倾向或聚类倾向)表示为分类分布,指示聚类分配的患者具有相应结果的相应可能性。这可以是集群上的经验结果比例分布,但也可以是模型学习的任何其他分类分布。
- 对于每次入院,观察数据根据达到结果的时间(或出院时间,在住院期间无事件的情况下)平均分为 4 小时窗口块。根据验证早期预警评分 (EWS) 系统(英国 NHS 工作人员用于跟踪住院患者生理的基线模型,(RCP, 2017))和临床输入的文献,仅考虑结果前 24 小时和 72 小时内的观察结果,例如目标表型代表患者在随后 24 小时内的状态。由于分布中的偏度和异质性,特征根据最小-最大归一化进行了转换。入院患者被随机分为训练集、验证集和测试集。缺失值是根据先前观察到的时间块估算的——所有剩余的缺失观察值都是根据聚合验证和测试数据的特征中值估算的(有关训练-测试数据拆分的描述,请参见第 5 节)。估算值在三维掩码矩阵中标记。
- 处理后,输入数据包含超过 100,000 条患者轨迹,对应 4,266 次独特的入院(我们的分析中仅考虑了每位患者的最后一次入院)。不同变量/特征的患者队列的原始轨迹显示在图 A.4、A.5、A.6 的附录中。跨时间和静态变量可以观察到缺乏明确的结果组可分离性。此外,我们注意到数据的高度不平衡——没有事件的入院人数占入院总数的 86.8% 以上,而事件类别对应于 10.3% 的死亡、1.8% 的 ICU 和 1.1% 的心脏病。
3.2. MIMIC-IV ED
- 为了在不同的环境中测试我们的模型的有效性,以及提高我们工作的可重复性,我们还考虑了一个代表急诊室入院的数据集,MIMIC-IV-ED(Johnson 等人., 2021 年;Goldberger 等人,2000 年),简称为 MIMIC。 MIMIC 是一个免费的大型数据库,包含 2011 年至 2019 年间贝斯以色列女执事医疗中心的急诊入院情况,包含 448,972 次急诊入院(“住院”)。对于每次入院,MIMIC 包含有关生命体征数据、分类信息、药物和医院旅程的信息。
- 我们采用了与 HAVEN 类似的预处理方法。我们忽略了与精神病学和/或分娩相关的入院,因为这些代表了普通人群中截然不同的人群。我们将时间聚合应用到 1 小时的块中,并且我们只考虑了 ED 出院时间前最多 6 小时的观察结果。我们根据数据分布和临床投入决定这些值。我们根据每位患者在接下来的 12 小时内的旅程为他们定义了四种结果:a) 患者是否死亡(“死亡”),b) 患者是否被送入 ICU(“ICU”),c) 是否患者留在医院病房(“出院”),以及 d) 患者是否出院(“病房”)。处理后,事件类别分布为 0.30% 死亡、16.53% ICU、2.11% 出院和 81.06% 病房,这表明该数据集中的高度不平衡。
4.方法
4.1提出的模型
- 我们提出了一个新的模型,我们用基于集群的时间序列重要学习(CAMELOT)表示。我们提出的方法如图 1 所示。我们的模型在 3 个关键项目上改进了之前的文献:
- a)针对多类不平衡的改进损失函数,
- b)确保聚类探索和代表性聚类的新损失函数,以及
- c)新的特征时间注意力 -级框架来增强表示并为集群分配引入特征时间可解释性。
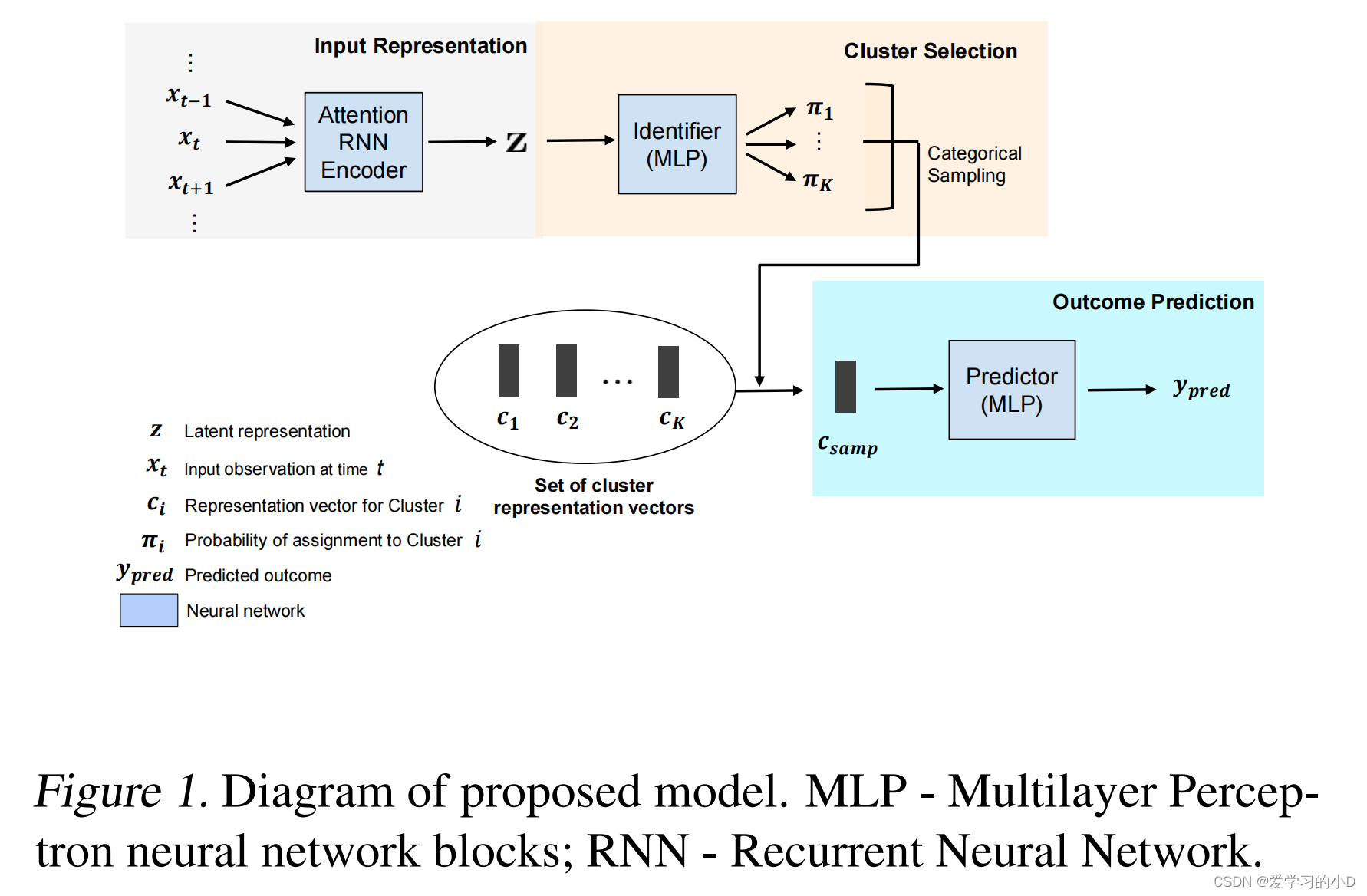
- 令 N N N 表示患者数量, D f D_f Df 表示输入特征的数量。
- 输入数据包括一组患者轨迹
X
=
{
{
x
n
,
t
}
t
=
1
T
n
}
n
=
1
N
X = \{\{x_{n,t}\}^{T_n}_{t=1}\}^N_{n=1}
X={{xn,t}t=1Tn}n=1N
- 其中 T n T_n Tn 是患者 n 的最大时间观察数,以及一组患者结果 Y = y n n = 1 N Y = {y_n}^ N_{n=1} Y=ynn=1N。
- 第 n 个患者的输入轨迹数据表示为
X
n
=
[
x
n
,
1
,
.
.
.
,
x
n
,
T
n
]
X_n = [x_{n,1}, ..., x_{n,T_n} ]
Xn=[xn,1,...,xn,Tn],
- 其中每个 x n , t ∈ R D f x_{n,t} ∈ R^{D_f} xn,t∈RDf 称为观察值(向量),观察值的最大值 D f D_f Df 特征值。
- 相应的患者结果是一个单热编码向量 y n ∈ R 4 y_n ∈ R^4 yn∈R4(更一般地说, y n y_n yn 的维度等于可能结果的数量)。
- 我们的 DL 模型可以分解为 3 个神经网络块:编码器、标识符和预测器。
- 我们将每个网络的动作分别称为 E 、 I 和 P E、I 和 P E、I和P(例如, I ( x ) I(x) I(x) 表示给定输入向量 x x x 时标识符的输出)。标识符和预测器都是多层感知器 (MLP),即堆叠的前馈密集层网络。
- 另一方面,编码器块可以进一步细分为
- a) 一堆 RNN 层和
- b) 我们提出的自定义注意力层(更多细节请参见第 4.2 节)。
- 另外,我们还考虑了一组可训练的集群表示向量, C = c 1 , . . . , c K C = {c_1, ..., c_K} C=c1,...,cK。我们将聚类 i 的结果指定为 P ( c i ) P(c_i) P(ci)。
- 模型调用如下:给定第 n n n 个患者输入轨迹数据 X n X_n Xn,编码器网络返回潜在表示 z n : = E ( X n ) ∈ R l z_n := E(X_n) ∈ R^l zn:=E(Xn)∈Rl。
- 因此,标识符网络计算集群分配概率, π n : = I ( z n ) ∈ R K π_n := I(z_n) ∈ R^K πn:=I(zn)∈RK。
- π n π_n πn 的每个元素
- π n i π^i_n πni 表示在给定总共 K K K 个簇的情况下 z n z_n zn 到簇 i i i 的概率分配。
- 根据cate gorical sampling(kn samp∼Cat(πn))选出一个簇 k s a m p n k^n_{samp} ksampn,
- 然后从C中选出对应的簇表示, c s a m p n : = c k s a m p n c^n_{samp} := c_{k^n_{samp}} csampn:=cksampn,
- 模型的输出为 y p r e d : = P ( c s a m p n ) ∈ R 4 y_{pred} := P (c^n_{samp}) ∈ R^4 ypred:=P(csampn)∈R4。
- 我们注意到 $k^n_{samp} 仅在训练阶段进行采样;在预测阶段,聚类选择遵循等式 $ k p r e d n = a r g m a x π n i k^n_{pred}=argmax\pi ^i_n kpredn=argmaxπni
4.2. Encoder Network and a Custom Attention Layer
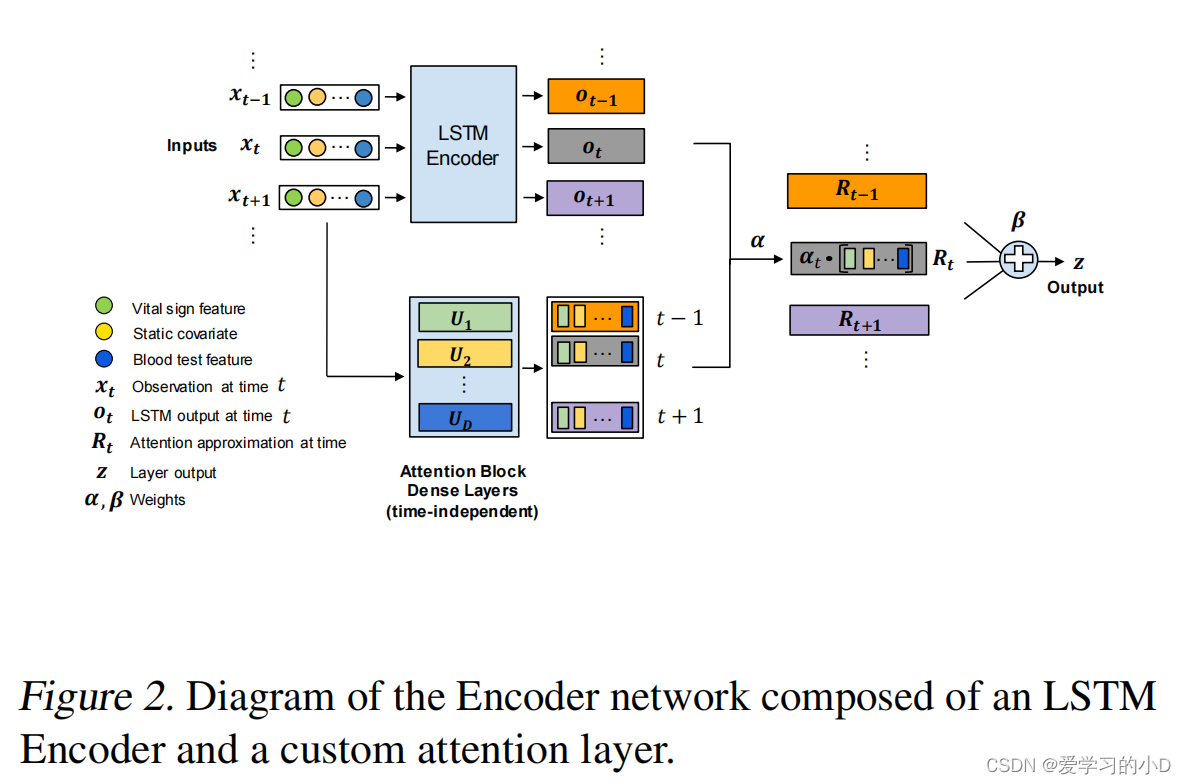
- 我们提出的编码器网络图如图 2 所示。编码器包含
- (i) 一个由堆叠的长短期记忆 (LSTM) 层组成的递归神经网络 (RNN) 块,以及
- (ii) 一个定制的注意力层,
- !
它计算通过将输入数据与来自 RNN 块的输出状态序列进行比较来获得潜在表示。我们使用与上面相同的符号,并将最终 LSTM 层的输出状态序列写为 o n , 1 , . . . , o n , T n o_{n,1}, ..., o_{n,T_n} on,1,...,on,Tn ,其中 o n , i ∈ R l o_{n,i} ∈ R^l on,i∈Rl 。 - 理论上,每个 o n , t o_{n,t} on,t 对应于直到时间 t t t 的输入患者信息的代表性摘要。
- 我们建议将 o n , t o_{n,t} on,t近似为线性特征,从而允许将输出状态分离为每个特征的贡献。
- 请注意,重要的是特征转换与时间无关,以避免过度参数化和过度拟合模型,并确保特征表示图在时间上相似。
- 我们的注意力层表现为一组
D
f
D_f
Df 前馈神经网络层,
U
1
,
.
.
.
,
U
D
f
U_1, ..., U_{D_f}
U1,...,UDf,共同表示为:
- (i) 可学习内核权重矩阵
D
∈
R
l
×
D
f
D ∈ R_{l×D_f}
D∈Rl×Df。
- 我们写 D = [ D 1 , . . . , D D f ] D = [D_1, ..., D_{D_f} ] D=[D1,...,DDf];
- (ii) 可学习偏置向量矩阵
B
∈
R
l
×
D
f
B ∈ R_{l×D_f}
B∈Rl×Df。
- 同样,我们可以写成 B = [ B 1 , . . . , B D f ] B = [B_1, ..., B_{D_f} ] B=[B1,...,BDf];
- (iii) 激活函数 σ σ σ,它与 RNN 块的输出激活相匹配。
- (i) 可学习内核权重矩阵
D
∈
R
l
×
D
f
D ∈ R_{l×D_f}
D∈Rl×Df。
- 患者
n
n
n 的输入数据
X
n
X_n
Xn 作为 RNN 模块的输入,输出一系列潜在输出状态
(
o
n
,
t
)
t
=
1
T
n
(o_{n,t})^{T_n}_{t=1}
(on,t)t=1Tn。对于
t
=
1
,
.
.
.
,
T
n
t = 1, ..., T_n
t=1,...,Tn,我们计算潜在空间中的
D
f
D_f
Df 特征表示为:
- $R_{n,t} := σ(D ⊙ x_{n,t} + B) $ (1)
- 其中 $R_{n,t} = [R_{n,t} ^1, …, R_{n,t}^{D_f} ] $是我们的特征表示集合,
- σ σ σ 是按元素应用的, A : = D ⊙ x n , t A := D ⊙ x_{n,t} A:=D⊙xn,t 是满足 A i , j = D i , j ( x n , t ) j A_{i,j} = D_{i,j} (x_{n,t})_j Ai,j=Di,j(xn,t)j 的矩阵。
-
- 等效地, R n , t i R^i_{n,t} Rn,ti是密集层的输出, U i U_i Ui 具有内核 D i D_i Di、偏置 B i B_i Bi、激活 σ σ σ 和输入 ( x n , t ) i (x_{n,t})_i (xn,t)i。我们近似于 o n , t ≈ ∑ i = 1 D α t i R n , t i = R n , t α t o_{n,t} ≈ \sum _{i=1}^D α^i_t R^i_{n,t} = R_{n,t}α_t on,t≈∑i=1DαtiRn,ti=Rn,tαt。该近似值根据最小二乘准则最小化,
- 该准则具有众所周知的解 α ^ t \hat α_t α^t 和对应的最佳近似值 o ^ n , t = R n , t α ^ t \hat o_{n,t} = R_{n,t} \hat α_t o^n,t=Rn,tα^t。
- 给定 o ^ n , t \hat o_{n,t} o^n,t,我们将上下文向量计算为 z : = ∑ t β t o ^ n , t z :=\sum_tβ_t{\hat o_{n,t}} z:=∑tβto^n,t,其中学习权重 β β β 以提供更具代表性的上下文向量。这是患者 n 的潜在表示和编码器网络的输出。
4.3. Attention Map Visualisation
- 给定聚类表示向量 c k c_k ck,我们可以如下计算聚类特征时间注意力可视化图。
- 首先,我们根据 softmax 函数对特征权重 α ^ t \hat α_t α^t 进行归一化, s t = σ ( α ^ t ) ∈ R D f s_t = σ(\hat α_t) ∈ R^{D_f} st=σ(α^t)∈RDf,其中 σ 是 softmax 函数: σ ( x ) = e x p ∣ x ∣ ∥ e x p ∣ x ∣ ∥ 1 σ(x) = \frac{exp |x|}{ ∥ exp |x|∥_1} σ(x)=∥exp∣x∣∥1exp∣x∣ 。请注意,我们在 softmax 函数中取绝对值——因此,我们从线性近似权重的大小中提取重要性,而不是简单地偏好最大值。
- 其次,我们根据 c k ≈ ∑ t = 1 T n o n , t ^ , γ n , t k c_k ≈ \sum_{t=1}^{T_n}\hat {o_{n,t}}, γ_{n,t}^k ck≈∑t=1Tnon,t^,γn,tk 的时间最小二乘近似计算聚类权重 γtk,并如前所述求解。我们同样对 γ n , t k γ_{n,t}^k γn,tk 进行归一化以获得聚类时间分数, e n , t k = σ ( γ n , t k ) e^k_{n,t} = σ(γ_{n,t}^k) en,tk=σ(γn,tk)。
- 最后,我们可以计算 K 个评分矩阵
-
M
n
1
,
.
.
.
,
M
n
K
∈
R
T
n
×
D
f
:
(
M
n
K
)
t
,
f
=
e
n
,
t
k
s
t
f
M_n^1 , ... , M^K_n \in R_{T_{n×D_f} }: (M^K_n)_{t,f} =e^k_{n,t}s^f_t
Mn1,...,MnK∈RTn×Df:(MnK)t,f=en,tkstf 。请注意:
- ∣ ∣ M n K ∣ ∣ 1 = ∑ t e n , t k ∑ f s t f = ∑ t e n , t k = 1 ||M^K_n||_1=\sum_te^k_{n,t} \sum_f s^f_t =\sum_te^k_{n,t}=1 ∣∣MnK∣∣1=∑ten,tk∑fstf=∑ten,tk=1 。
- 鉴于矩阵 M n k M_n^k Mnk 已归一化,我们将它们可视化为聚类分配相关性的归一化特征时间图,这我们用来提供进一步的模型可解释性。
4.4.损失优化
- 通过考虑三个不同的损失函数来优化模型。我们引入加权交叉熵损失函数:
L p r e d ( y t r u e , y p r e d ) = − ∑ c = 1 C w c y t r u e c l o g ( y p r e d c ) L_{pred}(y_{true}, y_{pred}) = − \sum^C_{c=1}w_cy_{true}^clog(y_{pred}^c) Lpred(ytrue,ypred)=−c=1∑Cwcytrueclog(ypredc)
- 这个损失相当于
L
=
−
w
c
′
l
o
g
(
y
p
r
e
d
)
c
L = −w_c' log(y_{pred})c
L=−wc′log(ypred)c; ,
- 其中 c ′ c' c′ 是真实结果一个特定的病人。我们建议成反比归一化权重: ∑ c = 1 C w c = 1 \sum^C_{c=1}w_c=1 ∑c=1Cwc=1并
- 且 w c w_c wc 与类别分布成反比,即 w c ∝ N N c w_c ∝ \frac{N}{N_c} wc∝NcN,
- 其中 N N N 是患者数量, N c N_c Nc 是结果标签为 c 的患者数量。
- 类权重对样本较少的类的错误分类进行更严厉的惩罚。
- 我们还提出了一种新的分布损失函数
L
d
i
s
t
(
π
)
L_{dist}(π)
Ldist(π)。
- 定义 as signment 的平均聚类概率为 π C : = 1 N ∑ n π n π_C := \frac{1}{N}\sum_n π_n πC:=N1∑nπn。
- 然后我们引入 L d i s t ( π ) = − H ( π C ) L_{dist}(π) = −H(π_C ) Ldist(π)=−H(πC),其中 H 表示信息熵。
- 请注意,当 π C π_C πC 均匀时, L d i s t L_{dist} Ldist 最小化,确保所有集群都被“探索”并具有可比较的样本数量。
- 最后,为了分离聚类表示向量,我们将聚类分离损失定义为
- L c l u s ( C ) = − 1 K ( K 1 − 1 ) ∑ i , j ∥ c i − c j ∥ 2 L_{clus}(C) = −\frac{1}{K(K1−1)} \sum_{i,j} ∥c_i − c_j∥^2 Lclus(C)=−K(K1−1)1∑i,j∥ci−cj∥2。
- L d i s t 和 L c l u s L_{dist} 和 L_{clus} Ldist和Lclus对于解决我们称为集群崩溃的问题都很重要,
- 这是一种在训练期间观察到的集群可能趋于崩溃的现象。这可能是由于
- i) 样本分配给一小部分簇(因此不探索进一步的表型)和
- ii) 学习的簇嵌入的收敛(因此簇表示在很大程度上是不可区分的)。
- 为了优化我们的模型,根据上述损失函数与超参数权重
α
,
β
α,β
α,β:1 的加权组合应用迭代梯度。
- 首先,根据 L p r e d L_{pred} Lpred 更新预测器;
- 之后,根据 L p r e d + α L d i s t L_{pred}+ αL_{dist} Lpred+αLdist训练Encoder和Identifier;
- .最后,根据 L p r e d + β L c l u s L_{pred} + βL_{clus} Lpred+βLclus 更新聚类表示向量。
4.5.初始化
- 我们提出的模型也遵循一组初始化预训练程序。首先,编码器和结果预测器根据分类任务 ( y ^ = P ( E ( x ) ) ) \hat y = P(E(x))) y^=P(E(x))) 进行预训练,并具有相应的损失 L p r e d L_{pred} Lpred。潜在状态表示 E(x) 通过 K 均值算法在整个训练集中具有 K 个聚类。聚类表示向量由生成的聚类质心给出,最后预训练聚类标识符网络以识别具有分类交叉熵损失的 K-Means 算法预测的聚类。我们还用其他非 K 均值聚类嵌入初始化测试了我们的模型,但没有观察到结果的显着差异。模型实现是用 Python 完成的,使用了 Ten sorFlow 2、scikit-learn 和 NumPy。所有实验均使用 1 个 Tesla v100 GPU 和 8 个 Intel® Xeon® Gold 6246 @ 3.30GHz CPU 运行。
5. 结果
5.1.设置
-
为了将我们的模型与其他方法进行比较,我们考虑了一组聚类基准。我们将 TSKM 作为经典聚类方法(考虑了欧几里得距离、DTW 和软 DTW 距离),以及作为最先进的表型聚类方法的 SOM-VAE 和 AC-TPC 进行了比较。 AC-TPC 接收完整患者观察集的时间子序列作为输入——出于比较目的,我们仅考虑完整患者序列的模型输出。为简单起见,我们给出的结果考虑了所有输入特征,除非另有说明。
-
所有模型都在相同的训练集(完整输入数据的 60%)上进行训练,并针对相同的测试集(剩余的 40%)进行评估。对于 DL 模型,我们进一步将训练集拆分为纯训练集和验证集。考虑的所有集合都包含对应于不同患者的数据。所有具有不同超参数的实验都用一组固定的 10 个不同的种子重复 10 次,并根据平均指标性能和标准偏差报告结果。附录中的表 A7 中包含为每个模型考虑的超参数的完整列表。粗体表示表现最佳的超参数。根据“奥卡姆剃刀”方法选择最佳整数超参数 (K, l) - 对于每个参数,我们为其分配最高值,以便根据平均值增加该数量不会导致性能显着提高AUROC 和 Fried man 的假设检验。在适用的情况下,神经网络大小参数在所有 DL 模型中保持一致。所有其他最佳超参数都是根据最高 AUROC 性能选择的,条件是模型至少为每个类别预测一个样本(例如,不是简单地分离,比如说,非死亡和死亡类别)。
-
我们通过标准聚类指标评估聚类性能,包括 Silhouette 分数 (SIL, (Rousseeuw, 1987))、Davies-Bouldin 指数 (DBI, (Davies & Bouldin, 1979))、方差比标准 (VRI, (Calinski & Harabasz, 1974) )).所有聚类模型在 HAVEN 上的结果显示在表 3 中,在 MIMIC 中观察到类似的趋势。我们还考虑了聚类框架的预测能力。在表 5 和表 4 中,我们评估了关于接收者操作曲线下面积 (AUROC)、未加权平均 F1 分数、未加权平均召回率和归一化互信息的(多类)预测性能(NMI)。对于纯无监督模型(SOM-VAE 和 TSKM),结果预测管道是通过将患者入院分配给聚类来构建的,并因此分配给相应聚类中的经验结果分布。

表3. 通过不同的聚类方法对HAVEN数据集进行聚类分离的结果,给定输入数据的所有可用特征(静态、生命体征、血清和血液学变量)。对于每个指标和模型,都会返回平均分和标准差。每个指标的最佳值用粗体表示。
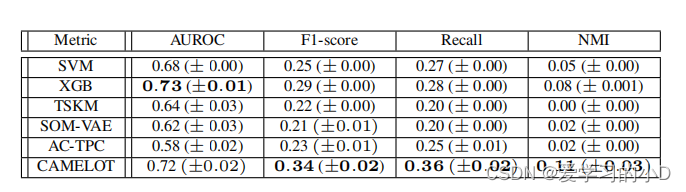 >表4. 所有模型在MIMIC数据集上的结果预测得分,显示为一组10个种子的平均值和标准差。请注意,NEWS2不适用于MIMIC急诊科的设置。每个指标的最佳值用粗体表示。对于聚类算法,聚类结果分布被认为是每个聚类中的经验观察分布。
>表4. 所有模型在MIMIC数据集上的结果预测得分,显示为一组10个种子的平均值和标准差。请注意,NEWS2不适用于MIMIC急诊科的设置。每个指标的最佳值用粗体表示。对于聚类算法,聚类结果分布被认为是每个聚类中的经验观察分布。
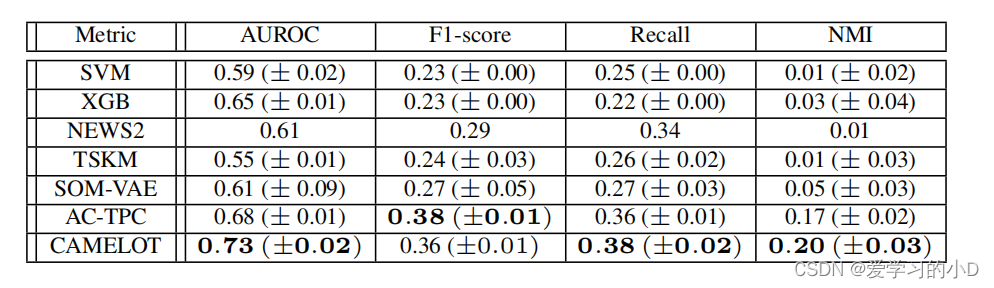
表5. HAVEN数据集上所有模型的结果预测分数,用一组10个种子的平均值和标准差显示(除了NEWS2,它是确定性的)。每个指标的最佳值用粗体表示。对于聚类算法,聚类结果分布被认为是每个聚类中的经验观察分布。
- 该预测任务还针对 EHR 数据中结果预测的其他分类器进行了基准测试,即支持向量机 (SVM)、XGBoost (XGB) 和 NEWS2(即英国医院使用的国家预警评分)。鉴于这些算法自然地源自表格数据,我们考虑稍作修改以将它们应用于时间序列数据,以充当忠实的预测基准。 NEWS2 只考虑一组固定的观察结果——因此,对于每个患者,我们输出最新输入观察结果的分数。对于 SVM 和 XGB,我们考虑了 2 种替代解决方案来构建时间分类器。第一种方法将时间序列连接成一个大的、大小为 Tn × Df 的单一特征向量,然后将其作为输入传递。另外,我们还考虑了一个集成模型,其中 SVM/XGB 在单变量时间序列数据(即单个特征)上独立训练,然后聚合以获得多维时间输入的预测分数。这样可以通过基准对时间变化进行建模以进行公平比较。最后,请注意完整的 NEWS 分数不适用于 MIMIC 急诊室设置。
5.2.消融研究
-
我们还对我们提出的预测任务模型进行了消融研究。我们使用以下符号:
-
a) CAMELOT 表示原始模型;
-
b) ABL1(或 AT TEP),我们用 AC-TPC 中提出的样本熵损失替换提议的 L d i s t L_{dist} Ldist;
-
c) ABL2(或ENC-PRED),去除了CAMELOT的聚类成分,只留下Encoder和Predictor。
-
-
为了评估我们的损失函数和注意力层的相关性,我们还考虑
- d) ABL3 作为 CAMELOT,α = 0(即没有 L d i s t L_{dist} Ldist),
- e) ABL4 作为 CAMELOT,β = 0(没有 L c l u s L_{clus} Lclus),
- f) ABL5 作为 CAMELOT α = β = 0 和
- g) ABL6 作为没有注意层的 CAMELOT。消融结果列于表 6 (HAVEN) 和 7 (MIMIC).
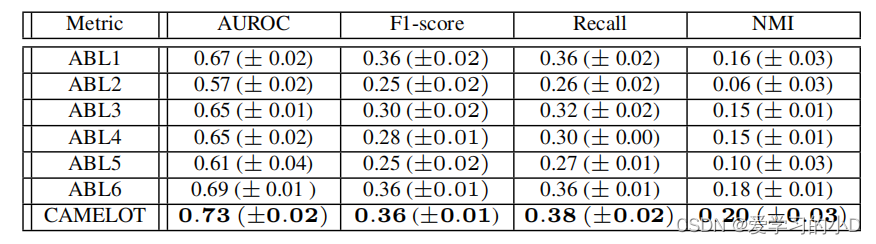
表6. 不同消融模型的HAVEN结果预测得分。结果报告了固定的5个种子的平均值和标准差。
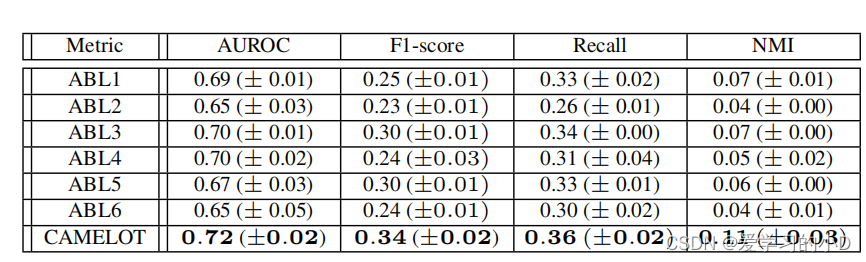
表7. 不同消融模型的MIMIC结果预测得分。结果报告了固定的5个种子的平均值和标准差。
5.3.表型和表征
- 除了关于聚类可分离性和结果预测的性能评估之外,我们通过我们提出的模型显示学习到的表型,并与表型聚类基准 AC-TPC 的学习到的聚类表型进行比较。对于每个集群,相应的结果倾向 P© 显示为具有相应概率值的 4 种可能结果的条形图。为了完整起见,我们还在附录中显示了 TSKM 和 SOM-VAE 的聚类结果倾向图(图 A.8 和 A.9)。请注意,CAMELOT 学习的聚类结果倾向分布(作为模型训练的一部分学习,没有涉及患者真实结果的任何计算)也与学习聚类中的经验结果相关性一致(表 A.12)。最后,我们还在图 9 中显示了特征时间聚类相关性注意图。对于给定的聚类 j ∈ { 1 , . . . , K } j ∈ \{1, ..., K\} j∈{1,...,K},我们考虑分配给聚类 j 的所有患者,用 C j C_j Cj 表示,并计算平均值集群 M j = 1 ∣ C ∣ k ∑ p a t n ∈ C j M n j M^j = \frac{1}{|C|_k} \sum{pat_n}∈C_j M^j_n Mj=∣C∣k1∑patn∈CjMnj 的注意力矩阵(另请参阅第 4.3 节)。然后我们将其显示为跨集群的标准化热图。为简单起见并出于这项工作的动机,我们在生命体征和静态变量的 HAVEN 数据集上显示了这些结果,但这项工作自然可以扩展到不同的时间特征集。
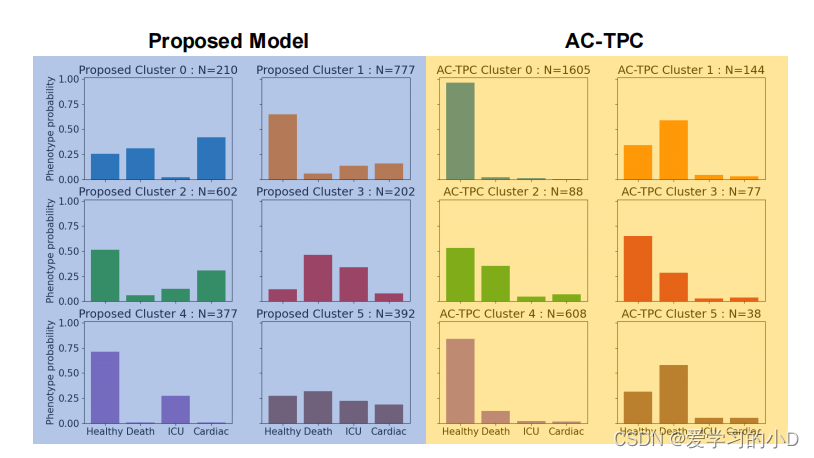
图8. 拟议模型和基准AC-TPC的群组结果倾向分布条形图的比较。左边(蓝色)显示的是每个群组(共6个)的分布情况,每个表型对应于一个结果的概率。右边(黄色)显示了ACTPC的类似结果。每个子图的标题表示所考虑的聚类,以及分配给一个特定监护人的病人数量。聚类的大小也被指出。可以看出,AC-TPC学到的表型比我们提出的模型学到的表型种类少。
6. 讨论
-
与当前的表型聚类基准 (AC-TPC) 相比,我们提出的模型显示了聚类性能的改进(见表 3),并且根据 VRI 优于 SOM-VAE。尽管在 TSKM 的情况下聚类可分离性指标更好,但考虑到对凸聚类的指标偏差,以及 TSKM 导致的凸性是基于 K-Means 的算法,这是预期的。此外,DL 聚类发生在潜在空间中,不幸的是,这不容易与针对输入空间的算法(例如 K-Means)进行比较。我们认为 TSKM 学习的集群不如从我们的模型中学习的集群相关。以 HAVEN 结果为例,TSKM 集群在结果倾向方面极难区分(预测任务的性能非常低(见表 4 和表 5)证明了这一点)。此外,TSKM 簇在轨迹演变方面的可分离性较低,因为平均 HR 轨迹的分离较少,并且当数据投影到具有 t-随机邻域嵌入 (tSNE) 的二维域时,簇分离较少(参见图 A10)和附录中的 A11)。
-
关于用于选择超参数作为最重要任务的预测能力,我们的模型比所有基准测试都要好得多,只有两个例外(获得竞争性能)。在 HAVEN 数据集上,从表 4 和表 5 中可以看出,我们的模型根据均值 AUROC 优于标准分类器(至少 8%)和基准聚类方法(至少 5%)。在其他分类指标中也可以看到类似的增长,但 F1 分数除外,其模型性能略低于(但非常可比)AC-TPC。另一方面,在 MIMIC 上,我们在平均 AUROC 上优于所有模型 4%,XGB 除外(与 CAMELOT 相比,它具有相似的置信区间)。然而,我们明显优于其他方法(F1 分数为 5%,召回分数为 8%,NMI 分数为 3%)。鉴于其他指标比平均 AUROC 对类别更敏感,我们的模型比其他模型更擅长识别较小样本大小的类别,这是根据经验观察到的,因为 XGB 和 SVM 无法识别两个较小的样本类别。
-
我们的模型能够比之前提出的模型更准确地确定数据中的模式,因为 EHR 数据极其复杂和异构。尽管存在聚类瓶颈(即给定患者的预测结果是通过分配的聚类完成的,而不是针对精确的输入数据量身定制的),但该模型特别有希望获得良好的预测任务结果。虽然其他模型可能在给定 EHR 输入的结果预测的直接任务上表现出更好的性能,但此类模型可能与缺乏稳健性或输入敏感性困难有关。此外,他们很可能难以识别临床感兴趣的相关趋势和特性。因此,对于新入院患者,这些模型可以提供对总体结果的预测,但对这种结果将如何发生以及如何防止潜在的恶化风险没有充分的了解,更不用说汇集其他类似患者数据的能力了。
-
图 8 显示了我们方法的两个关键方面的优势(为简单起见,我们显示了 HAVEN 数据集上的结果)。我们的模型确定了清晰的、可分离的集群结果分布,并为临床医生提供了一个有用的可解释性层,以了解潜在的恶化风险。 CAMELOT 还识别出比 AC-TPC 更多样化的集群结果集,AC-TPC 仅选取 3 种不同的集群结果分布,并且不识别“ICU”和“Cardiac”类的存在。关于 CAMELOT 学习的集群,集群 0 和 3 是病情最严重的集群——它们主要代表随后 24 小时内的死亡和心脏事件。另一方面,集群 2、5 更健康,发生不良事件的可能性更小。集群 1 和 4 主要是“健康”集群,最严重不良事件的风险降低。我们注意到 AC-TPC 学习的聚类结果倾向分布无法提供这种级别的详细信息。此外,我们的模型学习到的倾向分布在很大程度上与每个集群中观察到的结果事件的经验数量相匹配(在附录表 A12 中显示)。此外,该模型设法成功解决了严重的类别不平衡设置并识别了更小的类别。代表性集群能够捕获不同大小的亚种群,但仍能识别潜在的恶化风险。我们还在附录 A.8 和 A.9. 中展示了其他簇表型基准结果,可以看出此处确定的表型没有临床意义。
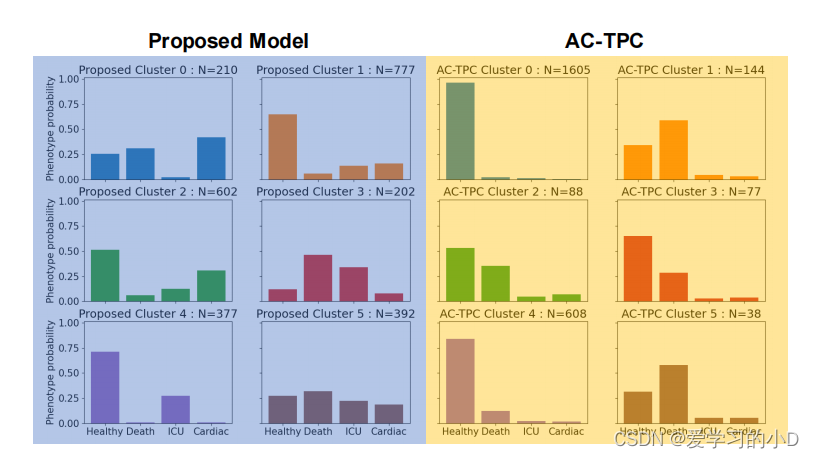
图8. 所提模型和基准AC-TPC的群组结果倾向分布条形图的比较。左边(蓝色)显示的是每个群组(共6个)的分布情况,每个表型对应于一个结果的概率。右边(黄色)显示了ACTPC的类似结果。每个子图的标题表示所考虑的群组,以及被分配到该群组的病人数量。以及分配到某一簇的病人数量。聚类 簇的大小也被指出。可以看出,AC-TPC学习到的 的表型比我们提出的模型所学的表型种类少。模型学到的表型。
- 图 9 所示的学习聚类注意力图为我们提出的聚类模型引入了另一层可解释性。平均注意力图突出了驱动患者集群分配的相关特征时间对,可用于识别最重要的临床变量。例如,对图 8 的分析表明,死亡或心脏骤停事件倾向最高的集群是集群 0、3(和 2 的程度略小)。这反映在生成的注意力图中,其中 RR、FIO2 和 SpO2 被突出显示为集群分配的关键临床变量。当考虑 CAMELOT 集群的描述性统计(表 A14)时,这一结论得到进一步证实,因为这三个是少数几个在集群之间具有显着分离的变量,并且还考虑了轨迹演变(图 A13)。最后,请注意,如果没有发生潜在的恶化事件,特征时间权重也是相关的——这样我们对患者的健康状况更有信心。例如,聚类 1 和 4(相当健康的聚类)的注意力图表明 SpO2 在整个入院过程中非常相关 - 这可能是因为这些患者没有表现出血液氧合作用的恶化。因此,学习到的注意力图可以非常通用。
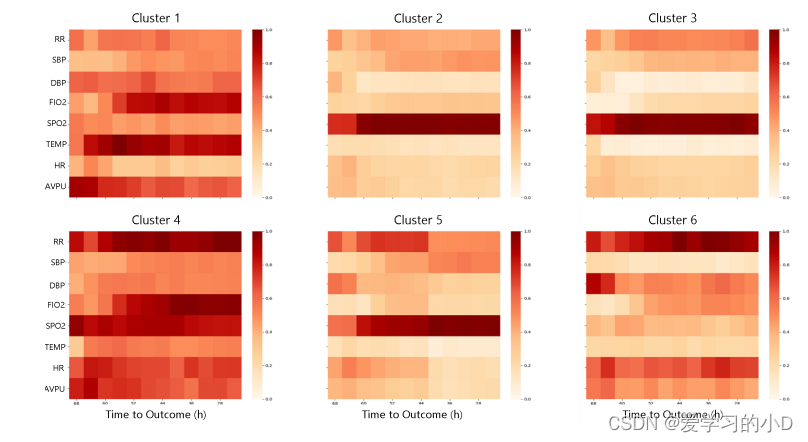
图9. HAVEN数据集上每个集群的平均注意力特征图。给定群组c,我们计算出该群组中患者的平均群组 簇中的病人的平均注意力矩阵。地图表示为 表示为所有聚类的归一化热图。横轴 代表到达结果的时间,以小时为单位,而纵轴 表示生命体征特征。
7. 结论和未来工作
- 在这项工作中,我们提出了一种新的深度学习模型,用于识别应用于 EHR 数据的表型可分离簇的任务。作为我们模型的一部分,我们考虑了之前 SOTA 的 2 个损失函数,并引入了一个新的特征时间注意层来更好地表示患者数据,并为每个集群引入了一个特征时间相关性映射。通过添加上述两种方法工具,我们的实验在聚类可分离性和结果预测性能方面显示出可喜的结果。添加特征时间层的额外好处是为研究人员引入了关键的可解释性工具,以了解相关区域以获得良好的患者生理学表现,以及指示可能导致患者恶化的原因。
- 在这项工作的基础上,有多种有趣的调查途径。一方面,当前的注意力层机制可能会通过添加时间权重平滑度或权重正则化来改进,以鼓励对完整特征时间空间的平滑探索。同样,该层可以扩展以很好地处理缺失数据,以确保以不同速率采样的时间特征以不同方式捕获模型的注意力。观察到的集群崩溃问题值得进一步探索,无论是在发展这一现象的理论框架方面,还是在引入统计保证来解决它方面。此外,我们的方法改进还将受益于对其他不同的不平衡数据集和其他潜在应用领域进行更广泛的测试。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









