







 论文提出了ModelCoder框架,基于数据驱动的故障模型和深度学习技术,用于微服务系统中的故障根本原因定位。通过对历史故障数据和运行时数据的分析,构建故障模型,使用深度神经网络进行训练,以自动定位导致故障的节点。实验表明,ModelCoder在准确性和效率上优于其他方法,能在80秒内定位故障根因,提高定位精度至93%。
论文提出了ModelCoder框架,基于数据驱动的故障模型和深度学习技术,用于微服务系统中的故障根本原因定位。通过对历史故障数据和运行时数据的分析,构建故障模型,使用深度神经网络进行训练,以自动定位导致故障的节点。实验表明,ModelCoder在准确性和效率上优于其他方法,能在80秒内定位故障根因,提高定位精度至93%。
ModelCoder: A Fault Model based Automatic Root Cause Localization Framework for Microservice Systems
ModelCoder: 基于故障模型的微服务系统自动根源定位框架
论文标题 | ModelCoder: A Fault Model based Automatic Root Cause Localization Framework for Microservice Systems
论文来源 | IWQoS(B) 2021
论文链接 | 未公布
源码链接 | 未公布
论文解析
主要内容
论文的主要内容是介绍了一种名为"ModelCoder"的自动故障根本原因定位框架,用于微服务系统中的故障诊断和定位。该框架基于故障模型和深度学习技术,旨在帮助开发人员快速、准确地找到导致微服务系统中故障的根本原因。
论文的主要创新点和关键内容包括:
- 故障模型构建:论文提出了一种基于数据驱动的故障模型构建方法,该方法能够从微服务系统的运行数据中自动学习故障模式。通过分析历史故障数据和正常运行数据,构建了一个描述不同故障模式的故障模型。
- 根本原因定位:使用深度学习技术,论文提出了一种根本原因定位方法,通过对故障模型和运行时数据进行联合分析,自动定位导致故障的根本原因。该方法利用深度神经网络对大规模的运行数据进行训练,并通过推理和特征重要性分析来确定导致故障的关键因素。
- 实验评估:论文在真实的微服务系统上进行了广泛的实验评估。通过使用真实的故障数据集和运行数据集,比较了ModelCoder与其他故障定位方法的性能。实验结果表明,ModelCoder在准确性和效率方面均取得了显著的改进。
总的来说,"ModelCoder: A Fault Model based Automatic Root Cause Localization Framework for Microservice Systems"论文介绍了一种创新的故障定位框架,利用故障模型和深度学习技术实现了自动化的故障根本原因定位。该框架在微服务系统中具有潜在的应用价值,可以帮助开发人员快速定位和解决微服务系统中的故障问题。
名词解析
-
「Node feature group」:节点特征组,包括目标节点本身,父节点,子节点和双向节点。
-
「Node feature」:节点特征,节点特征组中 「explicit nodes」 和 「implicit nodes」 分布。
-
「Fault model」:故障模型,故障根因节点的特征为故障模型。
对于挑战赛的数据集,论文中定义了四种故障模型: -
- docker network fault
- CPU fault
- docker deployed host network fault
- user oriented host network fault
-
「Node feature code」:节点特征的形式化表示,包含四种故障模型特征。
核心Model/Algorithm
- Data preprocessing:3-sigma 响应时间异常检测、依赖图构建和节点分类等。
- Known faults analysis:已知故障根因节点特征构建并存储在标准编码库中。
- Unknown fault analysis:候选根因节点判定并根据节点特征去匹配标准编码库进行根因定位。
「节点特征编码格式」
节点特征 使用 8 位编码表示,按照下文的意思应该只用了 7 位。
按照论文的意思故障模型应该用的是根因节点。
- 第一位:表示节点自身类型。如果节点是 explicit node 那么为 1,否则为 0。
- 第二位:表示节点的子节点中 explicit nodes 分布。包含三种值 1,0,-1,分别对应所有子节点都是 explicit nodes,部分是 explicit nodes 和全部都不是 explicit nodes。
- 第三位:表示节点的子节点中 implicit nodes 分布。
- 第四位和第五位:表示节点的父节点类型。
- 第六位和第七位:表示节点的双向节点类型。
第四五六七位含义模糊。
「特征存储格式」
三元组包含故障根因节点,故障类型,故障模型编码:「(cmdb_id, fault_type, code)」,然后存储在**「标准编码库」**中。
概念解析
论文中定义了非常多的概念,在阐述方法前先进行解释:
- 「Deployment graph」:部署图
G
D
=
<
V
,
E
>
G_D = <V,E>
GD=<V,E>定义为表示服务节点在物理主机上的部署状态。
- V V V 包括服务节点和物理主机, E E E 是一组有向边 < v i , v j > <v_i,v_j> <vi,vj>,表示服务节点 v i v_i vi 部署在物理主机 v j v_j vj 上,其中 $v_i , v_j \in V $。
- 「Service dependency graph」:服务依赖图
G
S
=
<
N
,
L
>
G_S=<N,L>
GS=<N,L>表示用户请求过程中涉及的服务节点及其调用关系。
- N N N是一组服务节点, L L L 是一组有向边 < v i , v j > <v_i , v_j> <vi,vj> 表示服务节点 v i v_i vi 调用服务节点 v j v_j vj 其中 v i , v j ∈ N v_i , v_j ∈ N vi,vj∈N。
在图中定义了三种类型的节点:
- 「Bidirectional nodes」:双向节点
v
i
和
v
j
v_i和v_j
vi和vj,在部署图
G
D
G_D
GD中,如果存在
边
<
v
i
,
v
k
>
和边
<
v
j
,
v
k
>
边<v_i ,v_k>和边< v_j ,v_k>
边<vi,vk>和边<vj,vk> 表示,
- 则服务节点 v i 和 v j v_i和v_j vi和vj,部署在同一物理主机 v k v_k vk上。
- 「Parent node」 和 「child node」:父子节点
v
m
是
v
n
v_m是v_n
vm是vn,服务依赖图
G
S
G_S
GS中存在边
<
v
m
、
v
n
>
且
v
m
≠
v
n
<v_m、v_n>且v_m ≠ v_n
<vm、vn>且vm=vn ,
- 则 v m 是 v n 的父节点, v n 是 v m 的子节点 v_m是v_n的父节点,v_n是v_m的子节点 vm是vn的父节点,vn是vm的子节点。
- 「Abnormal call」:异常调用,基于历史数据监测出的异常调用边,如图 Fig. 1. 中的虚线箭头所示。
- 「Abnormal service node」:异常服务节点,在服务依赖图
G
S
G_S
GS中中异常调用包含的节点都被定义为异常服务节点,异常服务节点分为两类:
- 「explicit node」 和 「implicit node」 ,
- 服务依赖图中存在异常调用边 < v i 、 v j > <v_i 、v_j> <vi、vj> 则 v i 、 v j 均为异常服务节点 v_i 、v_j均为异常服务节点 vi、vj均为异常服务节点, v i 为显式节点 v_i 为显式节点 vi为显式节点;
- 如果不存在异常调用 < v j 、 v m > ,则 v j 为隐式节点 <v_j 、v_m> ,则v_j 为隐式节点 <vj、vm>,则vj为隐式节点「implicit node」。
- Nomal nodes、explicit nodes 和 implicit nodes 普通节点、显式节点和隐式节点集分别用 V n o r 、 V e x 和 V i m V^{nor} 、V^{ex} 和V^{im} Vnor、Vex和Vim 表示
论文翻译
摘要
微服务系统是一种架构风格,将单个应用程序开发为一组在其进程中运行并通过轻量级消息机制进行通信的小型服务。虽然微服务架构能够快速、频繁、可靠地交付大型、复杂的应用程序,但对于运维人员来说,定位微服务故障的根本原因越来越具有挑战性,这种故障通常发生在服务节点上,并传播到整个系统。为此,在本文中,我们首先引入部署图和服务依赖图的概念来描述服务节点之间的部署状态和调用关系。然后,我们基于构建的图制定微服务系统中的根本原因定位问题,其中定义故障模型以捕获故障根本原因的特征。后来开发了一种基于故障模型的自动根本原因定位框架,称为 ModelCoder,通过与预定义的故障模型进行比较,找出未知故障的根本原因。我们在跨越 15 天的真实微服务系统监控数据集上评估 ModelCoder。通过大量实验表明,ModelCoder平均可以在80秒内定位故障根因节点,与state-of-the-art根因定位算法相比,根因定位精度(达到93%)提高了12% .索引词——微服务、故障模型、根本原因定位
I. 简介
-
微服务是一种广泛使用的架构,将单个应用程序划分为一组服务节点。每个服务节点都是一个单独的进程,可以独立部署、编译和运行。服务节点通过轻量级的消息机制相互协调配合,为用户提供完善的服务[1]。
-
微服务可以提高Web应用的抽象性、模块化和可扩展性[2],但也带来了一些新的问题,其中之一就是故障的根源定位。快速准确地定位根本原因可以减少故障排除时间和经济损失。微服务系统中庞大的服务节点和监控数据使得它成为可能*通讯作者是彪涵。极难快速自动定位根本原因 [3]。现有的工作应用日志分析工具[4]只能提供非常简单的帮助,并且强烈依赖于操作人员的经验。因此,迫切需要设计一个自动的根本原因定位框架。
-
首先,由于微服务系统有数百个服务节点[5],服务节点之间的调用关系复杂且动态。因此,现有的基于静态拓扑或模型的根本原因定位算法并不适用于微服务系统。
-
其次,由于一个故障往往涉及多个服务节点[6],单个服务节点的分析无法准确捕捉到故障的所有特征。此外,故障的特征是多种多样的,不同故障的根源节点是正常的还是异常的。因此,我们需要从多节点的规模来分析故障。
-
-
为了应对这些挑战,我们首先定义部署图和服务依赖图来描述服务节点之间的复杂关系。将异常节点分为显式节点和隐式节点,进一步表征故障特征。根据上述定义,我们制定了微服务系统的故障根本原因定位问题。为了解决这个问题,我们开发了一个基于故障模型的自动根本原因定位框架ModelCoder,它由三个模块组成:数据预处理、已知故障分析和未知故障分析。基于一种新颖的编码技术,我们定义了故障模型来表示故障的特征,从而将根本原因定位规模从单节点提升到多节点。我们使用真实世界的微服务系统 [7] 的监控数据来评估 ModelCoder。与最先进的根本原因定位算法相比,ModelCoder im 证明定位精度提高了 12%。广泛的实验结果表明,ModelCoder 的根本原因定位时间可以大大减少,而不会显着影响定位精度。
-
本文的主要贡献如下:
- 据我们所知,我们是第一个在微服务系统中提出故障根本原因定位问题的人,我们的目标是通过优化故障特征匹配过程来提高定位精度。
- 我们提出了ModelCoder,一种基于故障模型的根本原因定位框架,其中通过自动匹配已知和未知故障之间的特征向量来解决制定的定位问题。
- 我们在监控数据的微服务系统上评估ModelCoder 的根本原因定位准确性和速度。实验结果表明,Modelcoder 平均可以在 80 秒内实现约 93% 的定位精度,优于当前微服务系统中的根本原因定位算法。
-
本文的其余部分安排如下。第二节简要回顾了相关工作。第三部分描述了系统模型并制定了根本原因定位问题。第四节提供了我们提出的 ModelCoder 的架构。第五节介绍了ModelCoder的实现细节。第六节讨论了 ModelCoder 的评估结果。第七节总结了论文并指出了未来的工作。
二.相关工作
本节回顾与根本原因定位相关的工作,并根据其特点将其分为以下三类。
- Trace-based methods基于跟踪的方法:基于Trace的方法通常用于从事件或功能级别分析单体程序。通过跟踪事件或功能的关系,他们可以构建系统的概览模型,这有助于根本原因分析。 X-Trace [8] 是一个跟踪框架,它提供了结合不同应用程序、管理域、网络机制的系统的综合视图。 DARC [9] 可以使用运行时延迟分析构建正在运行的程序的调用图,并根据它找到根本原因路径。 Insight [10] 可以在检测到故障后的几分钟内创建失败服务请求的执行路径,以帮助定位故障的根本原因。总的来说,这些算法对系统进行了详细的分析;它们会带来相当大的开销,并且需要操作人员非常了解系统才能部署它们。
- Static methods静态方法:静态方法根据系统模型、阈值和图形等静态信息对系统进行分析。 -Diagnosis[11]根据手动设置的阈值判断系统是否异常,并启动故障分析过程。高等。 [12] 提出了一种基于马尔可夫特性的转移概率模型来描述成对测量之间的相关性,从而代表系统的配置文件。 Vscope [13] 基于预先生成的图形和预先定义的函数,在应用程序运行的整个过程中持续检测和跟踪交互。依赖于一定时期内保持不变的信息,这些算法不能适应动态系统。
- Dynamic methods动态方法:动态方法基于实时更新的系统模型定位根本原因。 Automap [14] 基于动态生成和更新的异常行为图分析故障传播。此外,Causeinfer [15] 可以通过构建双层因果图来平衡根本原因定位的粒度和性能。然而,这些方法的根本原因定位是在单节点级别,因为它们只考虑异常节点本身。相比之下,Weng 等人。 [16]通过将节点之间的资源竞争关系添加到系统模型中,首次考虑同一物理主机上的多个节点。基于涟漪效应,Li 等人。 [17]将同根原因产生的异常节点聚类,推导出故障根原因节点。这两种方法都涉及多节点特征的表示,但仅针对特定情况,缺乏可扩展性。
ModelCoder 与上述方法不同。首先,它分析服务节点之间的调用数据,而不是服务节点内部的事件或函数,从而减少系统的根本原因定位开销。其次,实时构建服务依赖图,及时响应系统的拓扑变化。第三,基于故障模型,从多节点层面对故障进行分析,能够准确提取多种故障的特征。
三、系统模型及问题描述
A.系统模型
- 为了表示用户请求中涉及的服务节点之间的资源竞争和调用关系,分别定义了部署图和服务依赖图。
- 部署图
G
D
=
<
V
,
E
>
G_D = <V,E>
GD=<V,E>定义为表示服务节点在物理主机上的部署状态。
- V V V 包括服务节点和物理主机, E E E 是一组有向边 < v i , v j > <v_i,v_j> <vi,vj>,表示服务节点 v i v_i vi 部署在物理主机 v j v_j vj 上,其中 v i , v j ∈ V v_i , v_j \in V vi,vj∈V。
- 定义服务依赖图
G
S
=
<
N
,
L
>
G_S=<N,L>
GS=<N,L>表示用户请求过程中涉及的服务节点及其调用关系。
- N N N是一组服务节点, L L L 是一组有向边 < v i , v j > <v_i , v_j> <vi,vj> 表示服务节点 v i v_i vi 调用服务节点 v j v_j vj 其中 v i , v j ∈ N v_i , v_j ∈ N vi,vj∈N。
- 典型的服务依赖图如图 1 所示,其中圆圈代表服务节点, d o c k e r x x x docker_{xxx} dockerxxx是docker服务节点, o s x x x os_{xxx} osxxx是主机服务节点, d b x x x db_{xxx} dbxxx是数据库服务节点,箭头代表调用,箭头从发起调用的服务节点开始,到调用结束响应调用的服务节点。
- 不同种类的圆圈和箭头的含义将在§III-B中解释。我们定义了三类节点,为后面的概念打下基础。在部署图
G
D
G_D
GD中,如果存在
<
v
i
,
v
k
>
和
<
v
j
,
v
k
>
<v_i ,v_k>和< v_j ,v_k>
<vi,vk>和<vj,vk> ,
- 则服务节点 v i 和 v j v_i和v_j vi和vj是彼此的双向节点,因为它们部署在同一物理主机 v k v_k vk上。
- 在一个服务依赖图
G
S
G_S
GS中,如果存在边
<
v
m
、
v
n
>
且
v
m
≠
v
n
<v_m、v_n>且v_m ≠ v_n
<vm、vn>且vm=vn,
- 则 v m 是 v n 的父节点, v n 是 v m 的子节点 v_m是v_n的父节点,v_n是v_m的子节点 vm是vn的父节点,vn是vm的子节点。
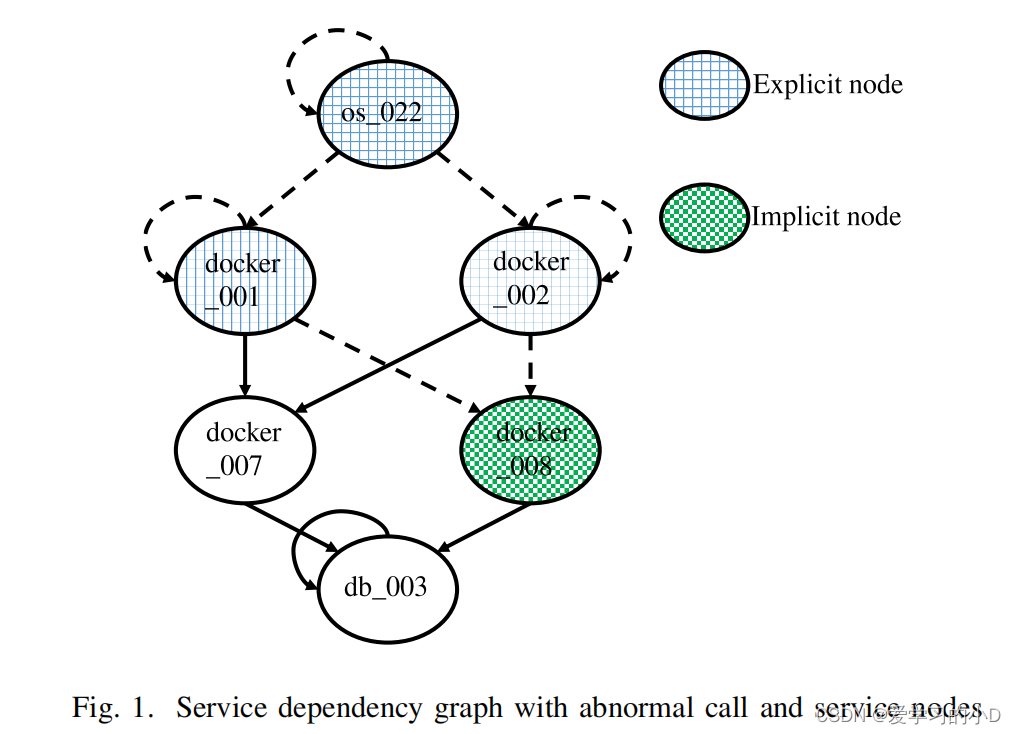
B. 异常检测和表示
从用户的角度来看,我们通过从调用初始化开始到获取返回数据结束的运行时间来识别特定调用是否异常。
- 1)Abnormal call异常呼叫:根据历史数据,将运行时间大于正常值的呼叫识别为异常呼叫,如图1中的虚线箭头所示。计算细节将在§中描述IV-C。
- 2)Abnormal service node异常服务节点:将异常调用链中的服务节点定义为异常服务节点,又分为显式节点和隐式节点,如图1所示。在一个服务依赖图 G S G_S GS中,如果存在异常调用 < v i 、 v j > <v_i 、v_j> <vi、vj> ,则 v i 、 v j 均为异常服务节点 v_i 、v_j均为异常服务节点 vi、vj均为异常服务节点, v i 为显式节点 v_i 为显式节点 vi为显式节点;
- 此外,如果不存在异常调用 < v j 、 v m > ,则 v j 为隐式节点 <v_j 、v_m> ,则v_j 为隐式节点 <vj、vm>,则vj为隐式节点。
- 普通节点、显式节点和隐式节点集分别用 V n o r 、 V e x 和 V i m V^{nor} 、V^{ex} 和V^{im} Vnor、Vex和Vim 表示。
C.问题描述
-
根据以上定义和讨论,我们从理论上制定了微服务系统中的根本原因本地化问题。当微服务系统发生故障时,我们可以得到如下信息:部署图 G D G_D GD,故障期间的一组服务依赖图 G S G_S GS,不同类别的节点集: V n o r 、 V e x 和 V i m V^{nor} 、V^{ex} 和V^{im} Vnor、Vex和Vim ,以及一组已知故障的数量 F K = f 1 , f 2 , . . . , f N K F_K = {f_1, f_2, ..., f_{NK} } FK=f1,f2,...,fNK。
- 对于已知故障 f j ( f j ∈ F K ) f_j (f_j \in F_K) fj(fj∈FK),我们将其特征表示为向量 f j = < x 1 , x 1 , . . . , x m > f_j = <x_1, x_1, ..., x_{m}> fj=<x1,x1,...,xm> .
- 其中 m m m 是向量的维数, x i ( 1 ≤ i ≤ m ) 在 − 1 , 0 , 1 x_i(1 ≤ i ≤ m) 在 { -1, 0, 1} xi(1≤i≤m)在−1,0,1。
-
我们需要定位一组未知故障的根本原因节点 F U = { f 1 , f 2 , . . . , f N U } F_U = \{f_1, f_2, ..., f_{N_U} \} FU={f1,f2,...,fNU}。对于未知故障 f i ( f i ∈ F U ) f_i(f_i \in F_U ) fi(fi∈FU),存在一组候选根本原因节点 C i = { v 1 i , v 2 i , . . . , v N i i } C^i = \{v^i_1 , v^i_2 , ..., v^i_{N_i}\} Ci={v1i,v2i,...,vNii} 。对于候选故障根因节点 v k i ( v k i ∈ C i ) v^i_k (v^i_k \in C^i) vki(vki∈Ci),我们将其特征表示为一个向量 v k i = < x 1 , x 2 , . . . , x m > v^i_k = <x_1, x_2, ..., x_m> vki=<x1,x2,...,xm>,与已知故障相同。
-
定义3.1(特征向量之间的距离)。候选故障根因节点vik的特征向量与已知故障fj的距离定义为:
d ( v k i , f j ) = ∑ 1 ≤ n ≤ m α n c o m p a r e ( v k n j , f j n ) c o m p a r e ( a , b ) = { 1 , i f a = b 0 , i f a ≠ b d(v^i_k, f_j) = \sum_{1≤n≤m}\alpha_n compare(v^j_{kn},f_{jn}) \\ compare(a,b)=\begin{cases} 1,if \ a=b\\ 0,if \ a\neq b \end{cases} d(vki,fj)=1≤n≤m∑αncompare(vknj,fjn)compare(a,b)={1,if a=b0,if a=b -
其中 α n \alpha_n αn 为向量中每一位比较结果的权重
-
在分析未知故障 f i f_i fi 时,我们将其候选故障根节点 C i C^i Ci 分为不同的簇,其中心是已知故障 F K F_K FK 满足:
f k = a r g m i n d ( v k i , f j ) ∣ f j ∈ F K f_k = argmin{d(v_k^i, f_j) |f_j \in F_K} fk=argmind(vki,fj)∣fj∈FK- 的簇中心 f k f_k fk 是 v k i v^i_k vki 所属簇的中心
-
定义3.2 (候选故障根本原因节点得分) v k i v^i_k vki 之间的距离 f k f_k fk 定义为 v k i v^i_k vki 的分值,将 C i C^i Ci 中的候选故障根因节点按分值从小到大排序,得到未知故障 f i f_i fi 的分析结果 A f i A_{f_i} Afi 。
-
f i 是 r f i , P ( r f i , A f i ) f_i 是 r_{f_i} , P (r_{f_i} , A_{f_i} ) fi是rfi,P(rfi,Afi) 被定义为 r f i 在 A f i r_{f_i} 在 A_{f_i} rfi在Afi 中的位置。
-
我们的目标是:
M i n i m i z e ∑ f i ∈ F U P ( r f i , A f i ) Minimize \sum_{f_i\in F_U} P(r_{f_i} , A_{f_i} ) Minimizefi∈FU∑P(rfi,Afi)
四、 MODELCODER 体系结构和实现
A. 关键思想
- 为了解决§III 中提到的问题,我们提出了节点特征组,它包括目标节点本身、它的父节点、子节点和双向节点。节点特征组中显式节点和隐式节点的分布定义为节点特征。故障根因节点的节点特征定义为针对不同故障的故障模型。我们从数据集[7]中总结出四种故障模型:docker网络故障、CPU故障、docker部署主机网络故障和面向用户的主机网络故障。限于篇幅,各故障模式的特点不再详述。提出了节点特征码来表示节点特征,节点特征包括节点特征组中四类节点的信息。编码的细节将在§IV-DB系统架构中进行说明 基于以上思路,我们设计并实现了ModelCoder,主要由三个模块组成:数据预处理、已知故障分析和未知故障分析。被构造为一组依赖图,根据这些依赖图识别异常服务节点,并将其分为显式节点和隐式节点。 2) 已知故障分析:将已知故障根本原因节点的节点特征编码存储在标准化编码库中。 3)未知故障分析:根据显性节点和隐性节点确定候选根本原因服务节点。对其节点特征进行编码,将得到的代码与标准化编码库中的代码进行比对,得到根因业务节点。 C. 异常检测 1)异常调用判断:在判断一个调用是否异常时,我们选择一段时间内所有具有相同cmdb id和callType的调用,计算这些调用经过时间的平均值μ和标准差σ,并设置µ + 3σ 作为阈值。 elapsedtime 大于阈值的调用将被判断为异常调用。 2)显性和隐性节点确定:基于服务依赖图集合来识别显性和隐性节点。显性节点是异常调用的发起节点,隐性节点是异常调用的响应节点。
- D.故障模型编码 1)编码格式:节点特征用8位编码记录,其中第一位反映节点本身的类别:如果节点是显式节点,则第一位为1;否则,第一位为0。第二位反映显式节点在该节点的子节点中的分布情况,1、0、-1分别对应三种情况:全部是显式节点、部分是显式节点和没有显式节点。第三位对应隐含节点在该节点的子节点中的分布情况。第四位和第五位反映节点的父节点的类别,第六位和第七位反映节点的双向节点的类别。 2) 标准代码存储:在处理已知故障时,将故障根因节点id、故障类别、故障模型代码构造成一个三元组cmdb id、故障类型、codei存储在标准cod中图书馆。
E. PSO 优化故障根因节点定位
本节主要介绍如何基于粒子群优化算法优化的编码分析确定故障根因节点和故障类别。
-
1) Candidate fault root cause node searching候选故障根因节点查找:由于故障一般从服务依赖图的底层向上传播,我们将底层显式节点和隐式节点作为候选故障根因节点。
-
2)Code comparing代码比较:我们通过计算两个节点的节点特征代码之间的相似性来计算它们的相似性得分,如(5)和(6)所示。由于代码包含四种节点的类别信息:目标节点本身、其子节点、其父节点和其双向节点,我们设置四个系数: α 1 、 α 2 、 α 3 、 α 4 \alpha_1、\alpha_2、\alpha_3、\alpha_4 α1、α2、α3、α4。
S ( c o d e 1 , c o d e 2 ) = ∑ 1 ≤ i ≤ 4 , 1 ≤ j ≤ 7 α i c o m p l a r e ( c o d e 1 j , c o d e 2 j ) { i = 1 , i f j = 1 i = 2 , i f j = 2 o r 3 i = 3 , i f j = 4 o r 5 i = 4 , i f j = 6 o r 7 c o m p a r e ( a , b ) = { 1 , i f a = b 0 , i f a ≠ b S(code_1,code_2) = \sum_{1≤i≤4,1≤j≤7} \alpha_icomplare(code_{1j},code_{2j}) \\ \begin{cases} i=1,if \ j=1\\ i=2,if \ j = 2 \ or\ 3\\ i=3,if \ j=4 \ or \ 5\\ i=4,if \ j=6 \ or \ 7\\ \end{cases}\\ compare(a,b)=\begin{cases} 1,if \ a=b\\ 0,if \ a\neq b \end{cases} S(code1,code2)=1≤i≤4,1≤j≤7∑αicomplare(code1j,code2j)⎩ ⎨ ⎧i=1,if j=1i=2,if j=2 or 3i=3,if j=4 or 5i=4,if j=6 or 7compare(a,b)={1,if a=b0,if a=b -
3) Coeffificient optimization系数优化:由于系数取值空间较大,需要寻找合适的值,在一定时间内,我们选择使用启发式算法,最后应用粒子群优化算法[18]。四个系数的值作为粒子的坐标,ModelCoder的根因定位精度作为适应度函数的返回值。我们建立一个四维空间,让粒子在里面运动。具体实验装置和结果见§VB。
-
4)Coding analysis 编码分析:对每个候选故障根因节点,将其节点特征码与标准编码库中的特征码进行比较,计算相似度得分,取最大值作为该候选故障根因节点的得分,如图所示在(7)中。
g r a d e n o d e i = m a x S ( c o d e n o d e i , c o d e ) ∣ c o d e ⊆ c o d e s grade_{node_i} = max {S(code_{node_i} , code)|code ⊆ codes} gradenodei=maxS(codenodei,code)∣code⊆codes- 其中 n o d e i node_i nodei为候选故障根因节点,
- c o d e n o d e i 为 n o d e i 的代码 code_{node_i}为nodei的代码 codenodei为nodei的代码, c o d e s codes codes为标准编码库中的代码集,
- g r a d e n o d e i 是 n o d e i 的分数 grade_{node_i}是 node_i 的分数 gradenodei是nodei的分数。
-
将候选故障根因节点按照得分从大到小排序,得到未知故障的分析结果。对于候选故障根因节点节点 n o d e i node_i nodei ,三元组 < c m d i d ′ , f a u l t t y p e ′ , c o d e ′ > < cmd_id' , fault_type' , code'> <cmdid′,faulttype′,code′> 从标准编码库中选出 其中:
c o d e ′ = a r g m a x S ( c o d e n o d e i , c o d e ) ∣ c o d e ⊆ c o d e s code' = argmax {S(code_{node_i} , code)|code ⊆ codes} code′=argmaxS(codenodei,code)∣code⊆codes- 其中 f a u l t t y p e ′ 为 n o d e i 对应的故障类别 fault_type'为node_i对应的故障类别 faulttype′为nodei对应的故障类别。
V. PERFORMANCE EVALUATIONS
A. Dataset and Benchmarks
1)Dataset数据集:数据集来自2020国际AIOps挑战赛,采集自浙江移动运营商搭建的云环境微服务系统监控数据集。监控数据中注入了81个故障的异常调用数据。每个故障持续5分钟,只包含一个故障根因节点。由于ModelCoder只能处理影响系统对用户请求响应时间的故障,我们从所有故障中选择影响响应时间的63个故障,其余18个故障丢弃。以保证每一类故障都包含足够数量的故障,从而生成标准代码,检验算法的准确性。在这63个故障中,29个故障用于已知故障分析,34个故障用于未知故障分析,以测试ModelCoder的根因定位精度和速度。
2)Baseline approach基线方法:为了说明ModelCoder 的根本原因定位精度,选择随机游走作为基线方法,该方法被广泛用作故障原因定位方法[14]、[16]。对比时,我们先构建服务依赖图,判断异常节点。在此基础上,我们分别运行 ModelCoder 和 random walk 来比较它们的性能。
3) Evaluation criteria评估标准:我们使用[16]和[19]提出的PR@K、MAP、AF P来量化每种方法的性能。
B. 实验结果
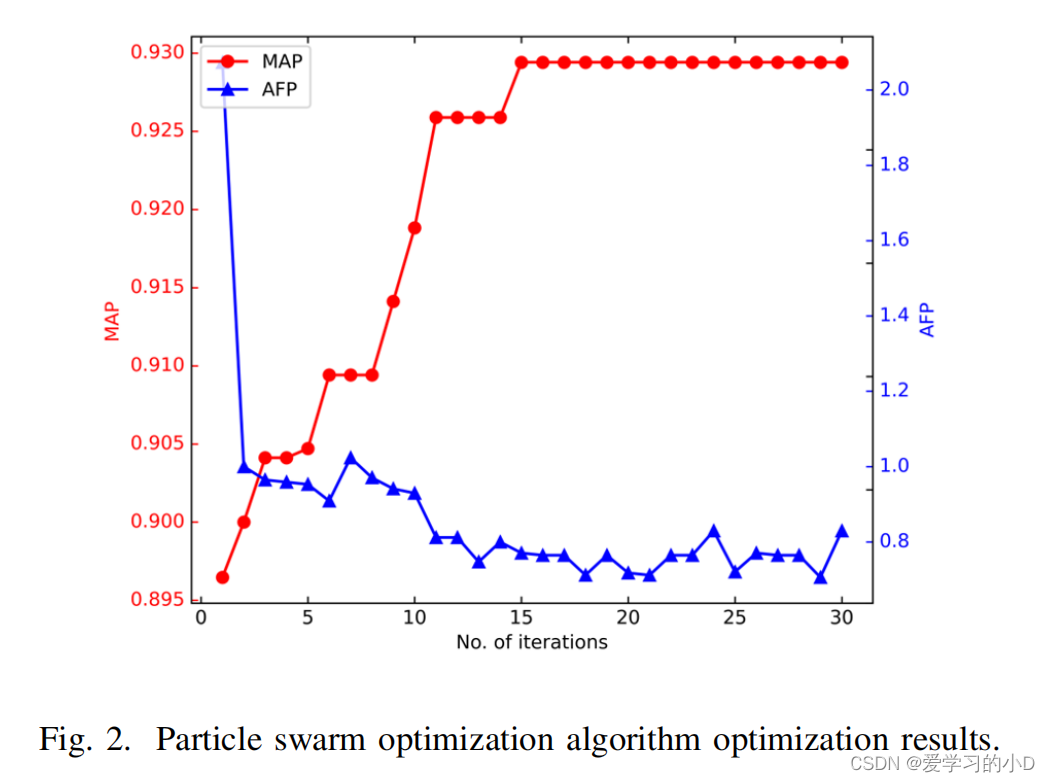
1)Effect of Particle Swarm Optimization Algorithm粒子群优化算法的效果:我们设置粒子群优化算法的参数如下:粒子数为10,迭代次数为30,粒子移动范围为[−10, 10 ],最大粒子速度为1。每轮迭代后,计算所有粒子的平均适应度函数返回值,作为本轮ModelCoder的得分。结果如图2所示,其中横坐标为迭代次数,纵坐标为MAP和AFP的值。如图2所示,ModelCoder的准确率逐渐上升,经过15次迭代后达到最优值。 MAP值从0.896增加到0.929,AFP值从3.835减少到0.8左右。由于我们将MAP值作为粒子的适应度函数值,经过15次迭代后,粒子的分数继续在具有最佳MAP值的区域移动,导致AFP值仍然略有波动。
2)Root Cause Localization Accuracy:将ModelCoder与随机游走进行比较,以评估其根本原因定位精度。根据上一节粒子群优化算法的结果,设置系数 α 1 、 α 2 、 α 3 、 α 4 为 [ 2 , 7 , 3 , 3 ] α_1、α2、α3、α4为[2,7,3,3] α1、α2、α3、α4为[2,7,3,3]。
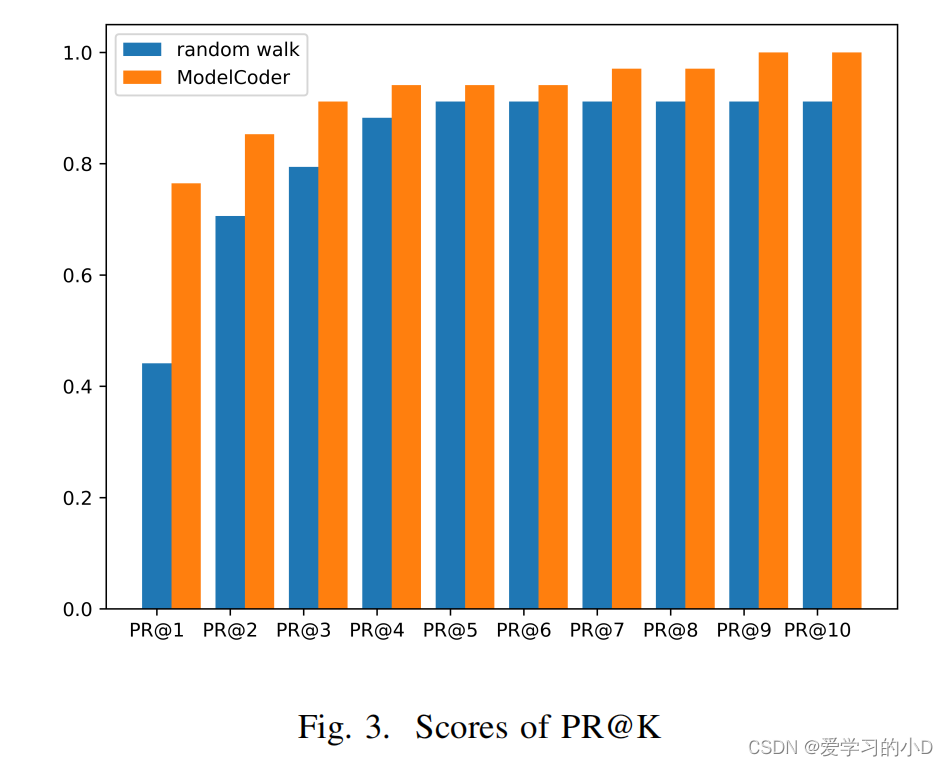
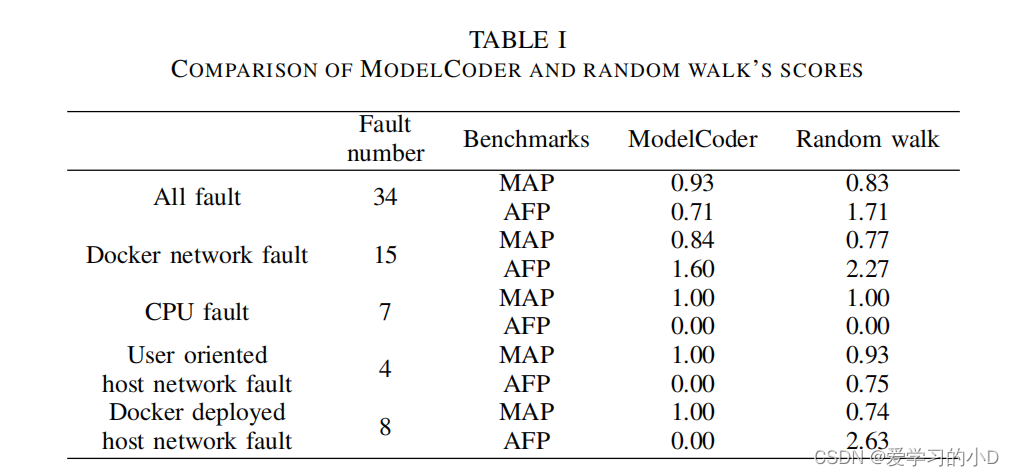
- ModelCoder和random walk从PR@1到PR@10的得分如图3所示,其中横坐标代表不同的K值,纵坐标代表对应的PR@K值。如表1,当考虑所有故障时,ModelCoder的MAP比随机游走高12%,AFP比随机游走低58%。
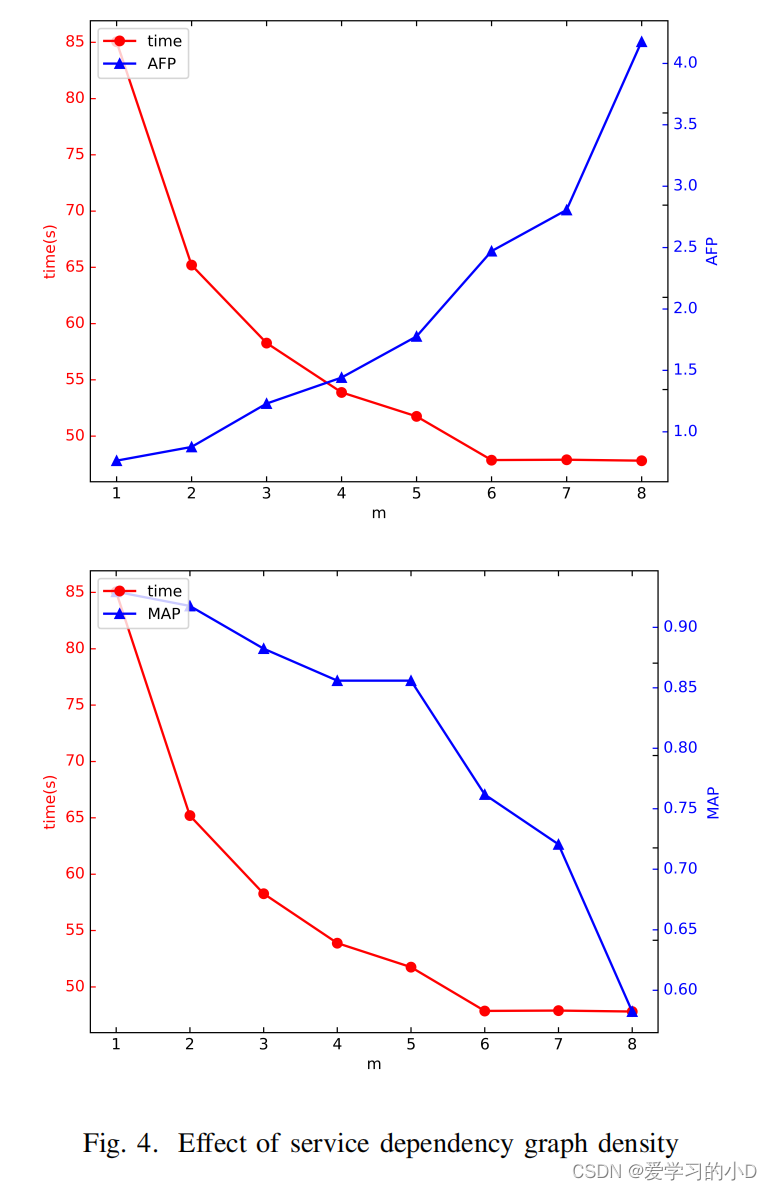
3)Effect of Service Dependency Graph Density服务依赖图密度的影响:如果我们在故障时间内建立所有的服务依赖图,将会有很多重复的服务依赖图;因此,我们从 m 个服务依赖图中选择一个并改变 m,然后记录 ModelCoder 的准确性和速度的变化。我们对每个 m 值重复实验 10 次,并记录所用时间的 95% 置信区间上限。结果如图4所示。
- 从图4可以看出,当m值增加到5时,使用时间从85.05s大幅减少到51.75s,而算法精度仍然可以保持在较高水平, MAP值从0.93下降到0.86,AFP值从0.76上升到1.78。当 m 值大于 5 时,时间减少不明显,但算法的准确率大大降低。
六.结论
- 在本文中,我们提出了ModelCoder,一种基于故障模型的自动根本原因定位框架,可以适应动态微服务系统。与随机游走相比,ModelCoder 的准确率提高了 12%,并且通过优化参数,在不显着影响准确率的情况下,可以大大减少根本原因定位时间。未来,我们将设计一种新的算法来细化从节点级别到指标级别的根本原因定位。
- 这项工作得到了国家自然科学基金(No.61601483)、湖南省青年人才计划(No.2020RC3027)和长沙市优秀青年创新人才培养计划(No.kq2009027)的部分支持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









