






问题描述
在数据预处理过程中,需要进行缺失值分析,某些情况下我们需要知道数据是否有连续缺失的片段,缺失的片段分布在哪些地方,以及缺失片段的长度。
解决方式代码
import pandas as pd
def detect_consecutive_missing(series, threshold):
# 创建一个布尔序列,如果值是NaN,则为True,否则为False
missing = series.isna()
cumsu_value = 0
cumsu_ls = []
for i in missing:
if i:
cumsu_value += 1
else:
cumsu_value = 0
cumsu_ls.append(cumsu_value)
new_missing_groups = pd.Series(cumsu_ls)
return new_missing_groups, new_missing_groups[new_missing_groups == threshold].index
# 示例使用
# 创建一个模拟的时序数据
data = pd.Series([None, 1, None, None, None, 3, None, 5, 6, None, None, 10])
# 检测连续缺失2个及以上的情况
consecutive_missing, gl2_num = detect_consecutive_missing(data, threshold=2)
print(consecutive_missing)
print(gl2_num)
print("缺失片段长度大于等于2的片段数量", len(gl2_num))
print("最长缺失片段长度", consecutive_missing.max())
结果可视
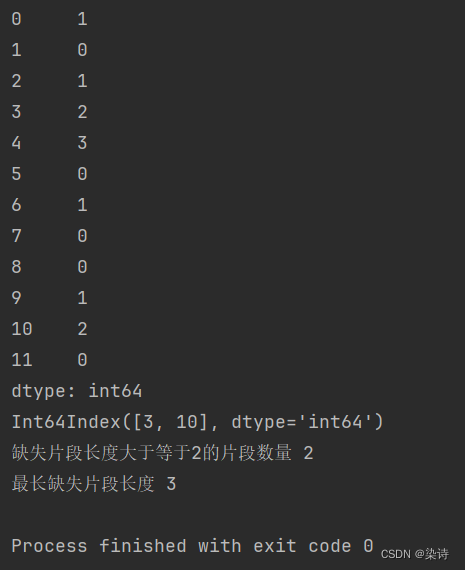
第一部分是对应的缺失片段长度,第二部分是缺失片段长度大于等于3的片段第二个缺失值所在位置索引。
第三个结果是片段数量,第四个结果是缺失最长片段长度。















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









