







性能调优案例
数据准备
创建三张表:客户表、产品表和订单表
CREATE TABLE `customers` (
`customer_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '姓名',
`email` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '邮箱',
PRIMARY KEY (`customer_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 16384 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
CREATE TABLE `products` (
`product_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '产品ID',
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品名称',
`price` decimal(10, 2) NOT NULL COMMENT '价格',
PRIMARY KEY (`product_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8192 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
CREATE TABLE `orders` (
`order_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`customer_id` int(11) NOT NULL COMMENT '客户ID',
`product_id` int(11) NOT NULL COMMENT '产品ID',
`order_date` date NOT NULL COMMENT '下单日期',
`status` int(11) NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 393211 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
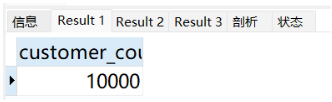
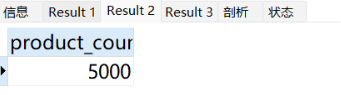
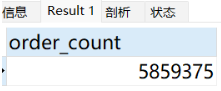
然后生成大量数据(满足正式生产条件):客户表1万条、产品表5000条、订单表500多万数据。
-- 检查客户表数据量
SELECT COUNT(*) AS customer_count FROM customers;
-- 检查产品表数据量
SELECT COUNT(*) AS product_count FROM products;
-- 检查订单表数据量
SELECT COUNT(*) AS order_count FROM orders;
优化前分析
分析工具
- 执行计划分析:
EXPLAIN命令来实现
EXPLAIN SELECT * FROM customers WHERE name = 'Customer_72294';
- 执行成本分析:
EXPLAIN FORMAT=JSON
EXPLAIN FORMAT=JSON SELECT * FROM customers WHERE name = 'Customer_72294';
优化思路
查询需求
- 查询某个时间范围内的所有订单
- 查询某个客户的所有订单
- 查询某个客户在某个时间范围内的订单
- 查询某个产品在某个时间范围内的订单
- 分页查询
- 关联查询…
索引优化
单列索引
- 查看SQL
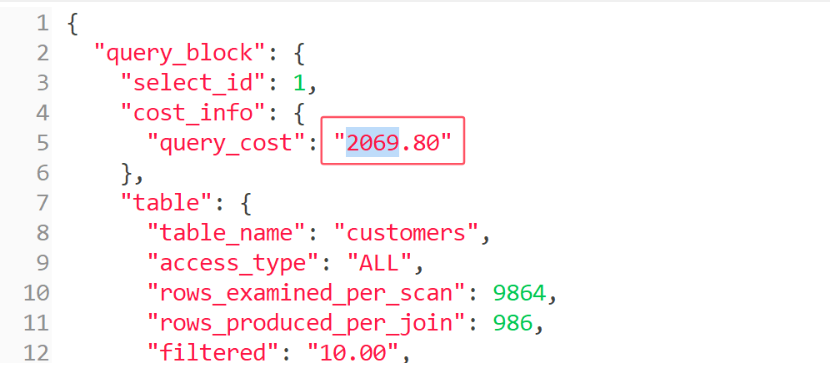
SELECT * FROM customers WHERE name = 'Customer_72294';
- 优化前的执行计划:全表扫描。

- 优化前的成本
- 添加索引
create index idx_username on customers(name);
- 优化后的执行计划

- 再看执行成本
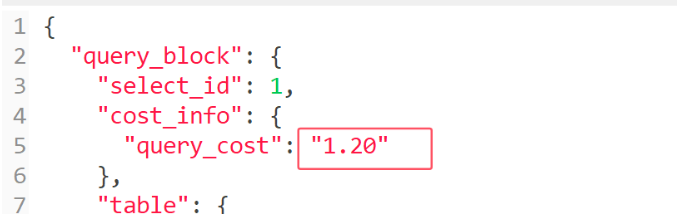
复合索引
- 查询SQL
select * from orders where customer_id = '17' and order_date = '2025-01-22';
select * from orders where customer_id = '17' and order_date between '2025-01-22' and '2025-03-22';
-
执行计划分析:全表扫描,成本分析,成本高

-
看成本
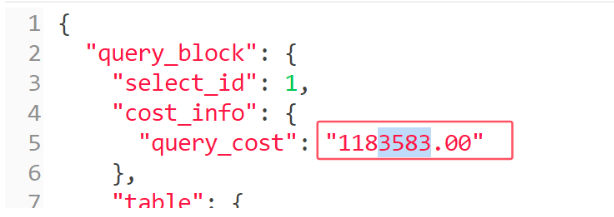
-
加索引优化
create index idx_ordes_cust_date on orders(customer_id,order_date);
索引优化时,需要注意联合索引的最左匹配原则(SQL中最左优先等值匹配,如果是范围之类的,最好放右边)
- 执行计划分析:用到了联合索引,效率贼高

- 成本分析
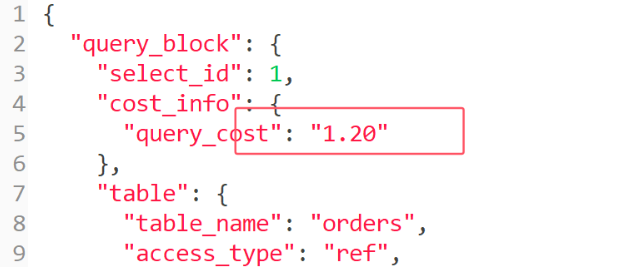
覆盖索引
- SQL语句
select status,order_date from orders where customer_id = 123;
这里的话(因为之前已经有一个联合索引了,不过这个联合索引覆盖不了status),索引执行计划分析,会使用上述的联合索引(复合索引)
-
执行计划

-
成本
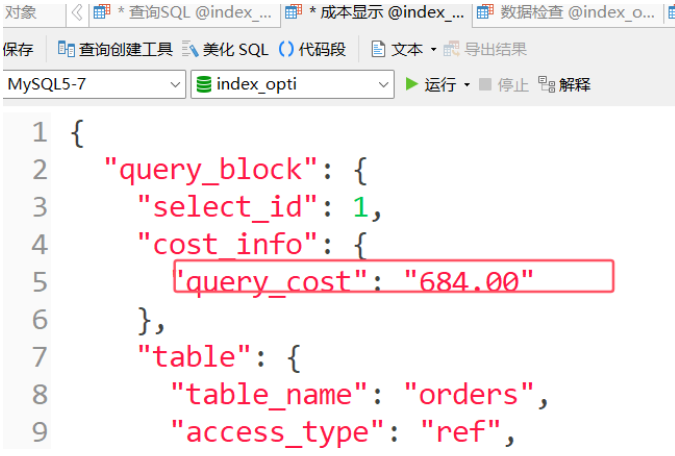
-
创建索引
create index idx_orders_customer_status_date on orders(customer_id, status, order_date);
-
执行计划:注意key的变化,还有Extra

-
再看成本

前缀索引
- 创建SQL
CREATE TABLE logs (
id INT AUTO_INCREMENT PRIMARY KEY,
message TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
- 经常使用的SQL查询
SELECT * FROM logs WHERE message like 'Error: %';
- 执行计划分析:全表扫描

- 创建前缀索引
create index index_prefix_message on logs(message(20));
- 添加索引后的执行计划

关联查询
- SQL
SELECT
c.customer_id,
c.name AS customer_name,
p.product_id,
p.name AS product_name,
o.order_id,
o.order_date,
o.status
FROM
customers c
JOIN
orders o ON c.customer_id = o.customer_id
JOIN
products p ON o.product_id = p.product_id
WHERE
1=1
and o.order_date BETWEEN '2025-01-22' and '2025-03-22'
and p.name = 'Product_4234';
分析如下
-
执行计划分析

这里最重要的o表(order表,数据量是500多万),走了全表扫描,效率低下。 -
成本

-
添加索引
create index idx_orders_date_cust_pro on orders(customer_id,product_id,order_date);
- 优化后,看成本和执行计划


其实这里可以利用之前的联合索引,多加一列,也可以实现类似效果

索引下推
索引下推(Index Condition Pushdown,ICP),MySQL5.6 引入的一项优化技术,用于提高查询性能。它的核心思想就是将部分过滤条件下推到存储引擎层(如InnoDB),从而减少不必要的数据传输和服务器层的计算。
怎么理解呢?用一个SQL案例来解释。
还是之前的Order表,我们只保留一个索引
create index idx_customer_product_date on orders(customer_id, product_id,order_date);
这个SQL语句的执行
explain
select * from orders where customer_id = 1 and product_id > 6 and order_date between '2025-01-22' and '2025-03-22';
若没有启用索引下推(ICP)技术
- 存储引擎会使用索引
idx_customer_product_date查找customer_id = 1 and product_id > 6的所有行(因为product_id是范围查找,根据索引最左前缀法则可知,order_date无法使用索引)。 - 将这些行返回给服务器层。(服务器层主要使用内存来存储解析后的SQL语句、执行计划和连接信息)
- 服务层再过滤
order_date BETWEEN '2025-01-22' and '2025-03-22'的行
启用索引下推(ICP)技术
- 存储引擎会使用索引
idx_customer_product_date查找customer_id = 1 and product_id > 6的所有行。 - 在存储引擎层直接过滤
order_date BETWEEN '2025-01-22' and '2025-03-22'的行。(InnoDB 的 Buffer Pool) - 只返回符合条件的行给服务器层
当然MySQL5.7之后,索引下推默认开启,也禁止不了。
我们来分析 一下执行计划。
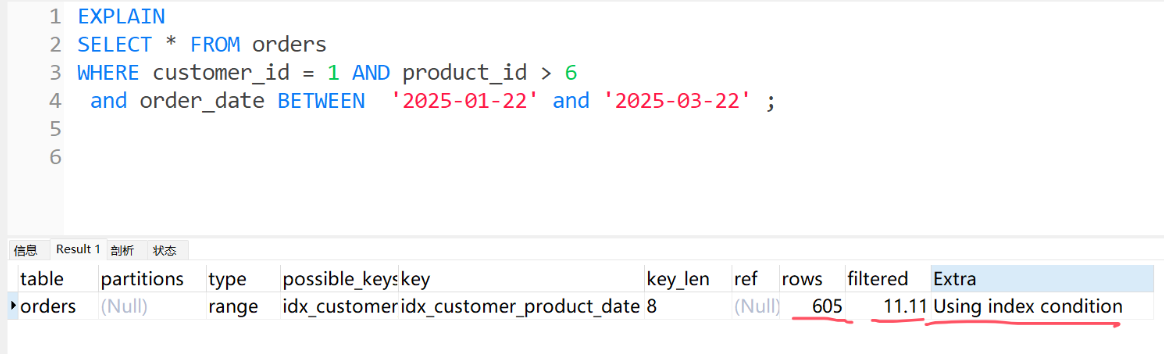
分析索引下推技术在执行计划和成本中的体现。
执行计划
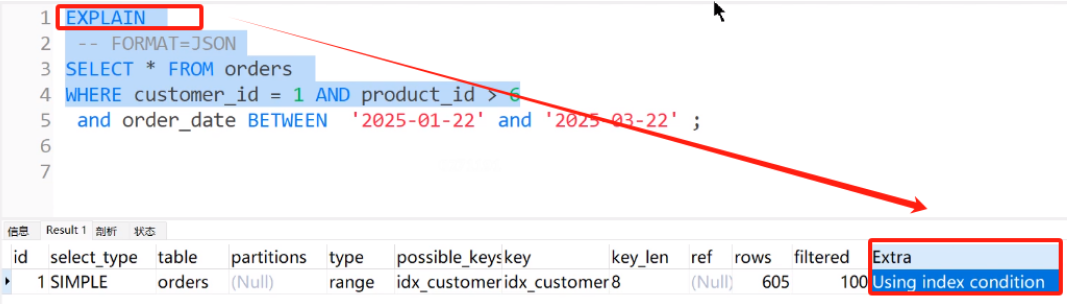
执行成本

通过上图中执行计划和成本上就可以确定使用了索引下推(ICP)技术。
一道索引面试题
华为OD的一道面试题,面试官提供了以下信息,来判断我们的索引选择,我们来分析以下
建表SQL
create table test(id int primary key,name varchar(10),age int,gender int);
alter table test add index idx_name_Age(name,age);
alter table test add index idx_name(name);
alter table test add index idx_name_Age_Gender(name,age,gender);
这里使用脚本插入10万条数据
-- 插入 10 万条随机数据
INSERT INTO test (id, name, age, gender)
SELECT
-- 生成唯一 ID
seq.id,
-- 生成随机名字(假设名字为 User + 随机数)
CONCAT('User', FLOOR(RAND() * 1000000)),
-- 生成随机年龄(18 到 60 岁)
FLOOR(18 + (RAND() * 43)),
-- 生成随机性别(0 或 1)
FLOOR(RAND() * 2)
FROM
-- 生成 10 万行的序列
(SELECT (a.a + (10 * b.a) + (100 * c.a) + (1000 * d.a) + (10000 * e.a)) AS id
FROM (SELECT 0 AS a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS a
CROSS JOIN (SELECT 0 AS a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS b
CROSS JOIN (SELECT 0 AS a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS c
CROSS JOIN (SELECT 0 AS a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS d
CROSS JOIN (SELECT 0 AS a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) AS e
) AS seq;
执行计划
explain
select * from test twhere t.name ='User100234'
面试官提问:查询SQL中 where 条件只有 name 的时候(等值匹配),判断索引选择使用的是两键的联合索引还是3键联合索引?
分析发现:使用两键联合索引!
分析过程:执行计划分析、成本分析!
分析发现,通过force index(idx_name_age_gender)强制使用三建的联合索引,他的成本和两键的联合索引是一样的
为什么选择两键索引呢?原因很简单,就是索引的大小。(三键索引比两键索引要大),所以执行计划是先看索引的大小。(需要结合B+树中索引的构造,还需要结合数据的分页相关的相关原理知识就能懂了)
误区:大家可能通过百度,chatgpt或其他的AI查询,出现一个错误的答案,索引的选择性,索引的选择度。
死锁问题分析与排查实战
要造成死锁,肯定是要多个线程(2个以上)去抢锁,并且抢的锁至少要有2把,同时要手动事务,每个线程尝试抢相同的锁,但顺序不同!
代码在附件中,springboot项目,使用mybatis。
造成死锁的核心代码如下:
@Autowired
private OrderMapper orderMapper;
@Transactional
public void updateOrder(int orderId1, int orderId2) {
Order order1 = orderMapper.findById(orderId1);
Order order2 = orderMapper.findById(orderId2);
orderMapper.updateStatus(orderId1, 1);
// 模拟延迟
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
orderMapper.updateStatus(orderId2, 2);
}
package com.example.deadlock;
import com.example.deadlock.service.OrderService;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan(basePackages = {"com.example.deadlock.mapper"})
public class DeadlockApplication implements CommandLineRunner {
@Autowired
private OrderService orderService;
public static void main(String[] args) {
SpringApplication.run(DeadlockApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
new Thread(() -> orderService.updateOrder(6149746, 6162764)).start();
new Thread(() -> orderService.updateOrder(6162764, 6149746)).start();
}
}
运行以上的代码,程序报错
Exception in thread "Thread-5" org.springframework.dao.DeadlockLoserDataAccessException:
### Error updating database. Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
### The error may exist in com/example/deadlock/mapper/OrderMapper.java (best guess)
### The error may involve com.example.deadlock.mapper.OrderMapper.updateStatus-Inline
### The error occurred while setting parameters
### SQL: UPDATE orders SET status = ? WHERE order_id = ?
### Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
; Deadlock found when trying to get lock; try restarting transaction; nested exception is com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
at org.springframework.jdbc.support.SQLErrorCodeSQLExceptionTranslator.doTranslate(SQLErrorCodeSQLExceptionTranslator.java:271)
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:70)
at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:91)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:441)
at com.sun.proxy.$Proxy48.update(Unknown Source)
at org.mybatis.spring.SqlSessionTemplate.update(SqlSessionTemplate.java:288)
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:67)
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
at com.sun.proxy.$Proxy52.updateStatus(Unknown Source)
at com.example.deadlock.service.OrderService.updateOrder(OrderService.java:29)
at com.example.deadlock.service.OrderService$$FastClassBySpringCGLIB$$233070e.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:793)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:763)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:123)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:388)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:119)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:763)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:708)
at com.example.deadlock.service.OrderService$$EnhancerBySpringCGLIB$$9d60df54.updateOrder(<generated>)
at com.example.deadlock.DeadlockApplication.lambda$run$1(DeadlockApplication.java:23)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:123)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:916)
at com.mysql.cj.jdbc.ClientPreparedStatement.execute(ClientPreparedStatement.java:354)
at com.zaxxer.hikari.pool.ProxyPreparedStatement.execute(ProxyPreparedStatement.java:44)
at com.zaxxer.hikari.pool.HikariProxyPreparedStatement.execute(HikariProxyPreparedStatement.java)
at org.apache.ibatis.executor.statement.PreparedStatementHandler.update(PreparedStatementHandler.java:47)
at org.apache.ibatis.executor.statement.RoutingStatementHandler.update(RoutingStatementHandler.java:74)
at org.apache.ibatis.executor.SimpleExecutor.doUpdate(SimpleExecutor.java:50)
at org.apache.ibatis.executor.BaseExecutor.update(BaseExecutor.java:117)
at org.apache.ibatis.executor.CachingExecutor.update(CachingExecutor.java:76)
at org.apache.ibatis.session.defaults.DefaultSqlSession.update(DefaultSqlSession.java:194)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:427)
... 21 more
2025-02-26 10:54:18.203 INFO 18428 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown initiated...
2025-02-26 10:54:18.208 INFO 18428 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown completed.
上述日志中出现了:Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
很明显可以看出确实死锁了,不过mysql 重启事务把死锁打开了。
我们还是可以通过mysql的命令行,可以看到死锁信息的
SHOW ENGINE INNODB STATUS;
在输出结果中,查找 LATEST DETECTED DEADLOCK 部分,查看最新的死锁信息
LATEST DETECTED DEADLOCK
------------------------
2025-02-26 10:34:15 0x2bfc
*** (1) TRANSACTION:
TRANSACTION 127497, ACTIVE 1 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 18, OS thread handle 4736, query id 3876 localhost 127.0.0.1 root updating
UPDATE orders SET status = 2 WHERE order_id = 6162764
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 845 page no 8406 n bits 480 index PRIMARY of table `index_opti`.`orders` trx id 127497 lock_mode X locks rec but not gap waiting
Record lock, heap no 314 PHYSICAL RECORD: n_fields 7; compact format; info bits 0
0: len 4; hex 805e094c; asc ^ L;;
1: len 6; hex 00000001f20a; asc ;;
2: len 7; hex 66000001ea2ab8; asc f * ;;
3: len 4; hex 80000001; asc ;;
4: len 4; hex 8000005d; asc ];;
5: len 3; hex 8fd232; asc 2;;
6: len 4; hex 80000001; asc ;;
*** (2) TRANSACTION:
TRANSACTION 127498, ACTIVE 1 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 17, OS thread handle 11260, query id 3877 localhost 127.0.0.1 root updating
UPDATE orders SET status = 2 WHERE order_id = 6149746
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 845 page no 8406 n bits 480 index PRIMARY of table `index_opti`.`orders` trx id 127498 lock_mode X locks rec but not gap
Record lock, heap no 314 PHYSICAL RECORD: n_fields 7; compact format; info bits 0
0: len 4; hex 805e094c; asc ^ L;;
1: len 6; hex 00000001f20a; asc ;;
2: len 7; hex 66000001ea2ab8; asc f * ;;
3: len 4; hex 80000001; asc ;;
4: len 4; hex 8000005d; asc ];;
5: len 3; hex 8fd232; asc 2;;
6: len 4; hex 80000001; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 845 page no 8374 n bits 480 index PRIMARY of table `index_opti`.`orders` trx id 127498 lock_mode X locks rec but not gap waiting
Record lock, heap no 288 PHYSICAL RECORD: n_fields 7; compact format; info bits 0
0: len 4; hex 805dd672; asc ] r;;
1: len 6; hex 00000001f209; asc ;;
2: len 7; hex 65000002850204; asc e ;;
3: len 4; hex 80000001; asc ;;
4: len 4; hex 8000005a; asc Z;;
5: len 3; hex 8fd233; asc 3;;
6: len 4; hex 80000001; asc ;;
*** WE ROLL BACK TRANSACTION (2)
当然也可以有一种方式让死锁无法自动释放:关闭MySQL的死锁检测机制(生产环境不要这么做,这仅仅是演示效果)
设置 innodb_deadlock_detect为OFF来禁用死锁检测
SET GLOBAL innodb_deadlock_detect = OFF;
再重启上述springboot应用,就会发现死锁不会立马解开,两个会话会一直等待,直到锁等待超时(由innodb_lock_wait_timeout控制)
show variables like 'innodb_lock_wait_timeout';

一般是50秒,也就是这里会互相锁住50秒左右。
如何避免死锁问题
- 按照顺序来访问资源(加锁的时候)
- 减少事务的粒度(锁的粒度)
大事务拆分成小事务。 - 使用乐观锁
- MySQL锁的超时,死锁的检测机制。
- 检查应用程序的日志(关键字),另外(
show engine innodb status)追溯一下最近的一次死锁情况。
真实调优案例分享
数据量临界点对执行计划的影响
关键技术:也就是常见的,最终索引用不用,不单纯是计划,同时要考核成本。
这里是范围查询何时从索引扫描转为全表扫描,或者反过来说都可以。
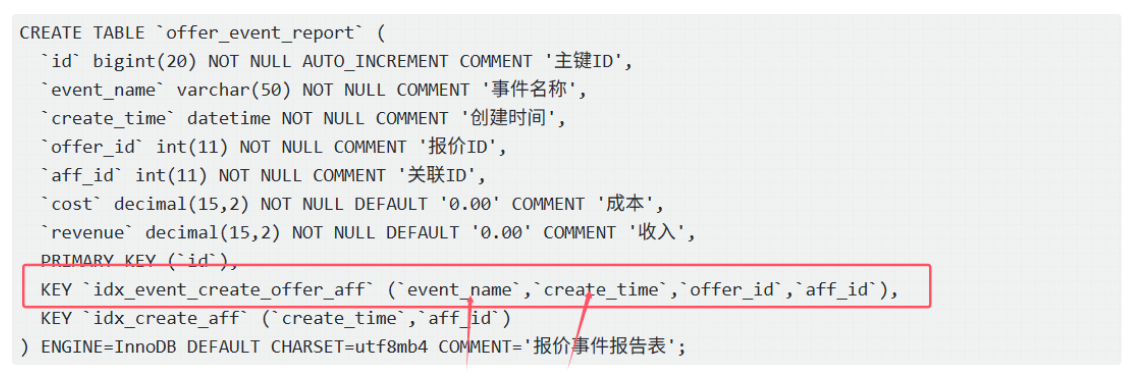
CREATE TABLE `offer_event_report` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`event_name` varchar(50) NOT NULL COMMENT '事件名称',
`create_time` datetime NOT NULL COMMENT '创建时间',
`offer_id` int(11) NOT NULL COMMENT '报价ID',
`aff_id` int(11) NOT NULL COMMENT '关联ID',
`cost` decimal(15,2) NOT NULL DEFAULT '0.00' COMMENT '成本',
`revenue` decimal(15,2) NOT NULL DEFAULT '0.00' COMMENT '收入',
PRIMARY KEY (`id`),
KEY `idx_event_create_offer_aff` (`event_name`,`create_time`,`offer_id`,`aff_id`),
KEY `idx_create_aff` (`create_time`,`aff_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='报价事件报告表';
创建存储过程
CREATE PROCEDURE insert_test_data()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE start_date DATETIME DEFAULT '2025-01-01 00:00:00';
DECLARE end_date DATETIME DEFAULT '2025-04-24 23:59:59';
DECLARE temp_date DATETIME; -- 修改变量名,避免与函数冲突
WHILE i <= 200000 DO
-- 随机生成日期(2025年1到4月内)
SET temp_date = DATE_ADD(start_date, INTERVAL FLOOR(RAND() * DATEDIFF(end_date, start_date)) DAY);
SET temp_date = DATE_ADD(temp_date, INTERVAL FLOOR(RAND() * 24) HOUR);
SET temp_date = DATE_ADD(temp_date, INTERVAL FLOOR(RAND() * 60) MINUTE);
SET temp_date = DATE_ADD(temp_date, INTERVAL FLOOR(RAND() * 60) SECOND);
-- 插入数据
INSERT INTO offer_event_report (
event_name,
create_time,
offer_id,
aff_id,
cost,
revenue
) VALUES (
CONCAT('event_', FLOOR(RAND() * 10)), -- 10种事件类型
temp_date,
FLOOR(RAND() * 1000), -- 1000种offer
IF(RAND() < 0.2, 129, FLOOR(RAND() * 200)), -- 20%概率是aff_id=129,其他随机
ROUND(RAND() * 1000, 2), -- 成本0-1000随机
ROUND(RAND() * 2000, 2) -- 收入0-2000随机
);
SET i = i + 1;
-- 每1000条提交一次
IF i % 1000 = 0 THEN
COMMIT;
END IF;
END WHILE;
COMMIT;
END //
执行存储过程,插入20万数据
call insert_test_data();
查询SQL
SELECT
SUM(cost) AS cost,
SUM(revenue) AS revenue
FROM offer_event_report
WHERE
create_time BETWEEN '2025-03-10 00:00:00' AND '2025-03-31 23:59:59'
AND aff_id = 129;
执行计划分析(发现走了全表扫描)
EXPLAIN
SELECT
SUM(cost) AS cost,
SUM(revenue) AS revenue
FROM offer_event_report
WHERE
create_time BETWEEN '2025-03-10 00:00:00' AND '2025-03-31 23:59:59'
AND aff_id = 129;
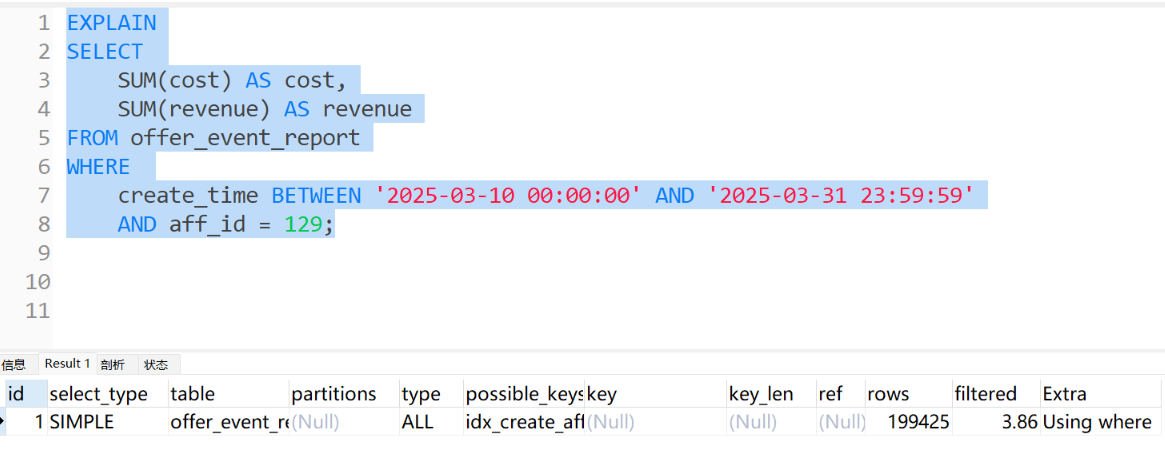
缩小查询范围,再执行计划分析(发现走索引)
EXPLAIN
SELECT
SUM(cost) AS cost,
SUM(revenue) AS revenue
FROM offer_event_report
WHERE
create_time BETWEEN '2025-03-30 00:00:00' AND '2025-03-31 23:59:59'
AND aff_id = 129;

以上现象解释:
- 优化器成本计算:MySQL优化器会根据统计信息估算不同执行计划的成本
- 索引选择性:当范围数据占比超过表总数的约20%~30%,优化器可能认为全表扫描更高效
- 索引覆盖度:您的查询只选择 offer_id ,如果该列被索引完全覆盖,更可能使用索引
- 统计信息准确性:ANALYZE TABLE 更新统计信息会影响优化器决策
最左匹配原则不是真理(Skip Scan)
还是上面的表数据案例,不过这里一定要是MySQL5.8,不能是MySQL5.7
SQL
select offer_id
from offer_event_report where
create_time between '2025-03-10 00:00:00' and '2025-03-31 23:59:59';
按照联合索引的最左匹配原则,这里应该使用不到联合索引(使用复合索引时,查询条件必须从索引的最左列开始,否则索引可能无法被充分利用)
如图:
SQL执行计划分析
EXPLAIN
select offer_id
from offer_event_report where
create_time between '2025-03-10 00:00:00' and '2025-03-31 23:59:59';
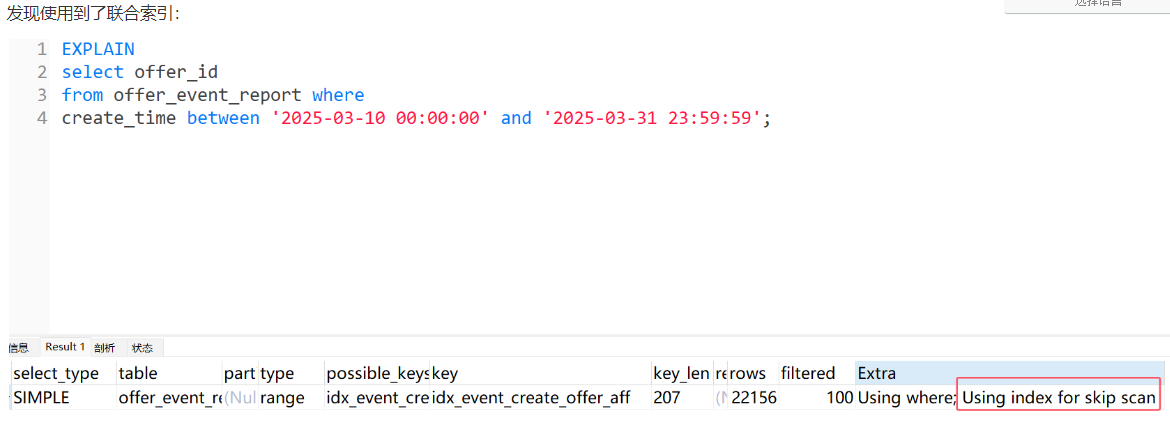
这个 Skip Scan:这是MySQL8.0引入的一种优化技术,允许在某些情况下即使查询条件不满足最左前缀原则,也能使用索引。
当复合索引的第一列有少量不同的值(低基数)时,MySQL可以
- 先枚举第一列不同的值
- 然后对每个值使用索引的剩余部分进行范围扫描
Skip Scan适用条件
- 复合索引的第一列基数较低(不同值较少)
- 查询条件包含了索引中第一列之后的列
- 优化器认为Skip Scan比全表扫描更高效
Using index for skip scan表示查询没有完全遵循最左匹配原则,MySQL找到了一种折衷方法来部分适用索引。
总的来说,其实优化无非就是 执行计划分析 + 成本;排查问题就是 慢查询 + 死锁排查,差不多就够用了。
最后欢迎大佬留下些来过的痕迹!您的支持是我不懈坚持的动力!


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











