







JDBC
JDBC 就是使用 Java 语言操作关系型数据库的一套 API,是 Java 和数据库的一个桥梁,是一个规范,由各大数据库厂商实现,能够执行 SQL 语句。
注:这里使用 MySQL 作为数据库,假设已经安装以及配置好了 MySQL 数据库的环境。
使用 JDBC 的环境准备
为了使用 JDBC,还需要引入一个 MySQL 的 Connector 驱动类,实际上就是 Java 的 JDBC 规范的一个针对 MySQL 的具体实现,这里有两个方式引入 Connector 到项目中:
- 下载驱动 jar 包,导入项目中
- 导入 Maven 依赖
方式一:
点击 MySQL Connector 官方下载链接🔗:MySQL 驱动类官方下载
选择一个合适的版本,一般选择稳定的版本,不需要太新,这里选择的是 5.1.48 版本,然后根据操作系统选择下载的压缩文件格式,如果是 Windows 系统,选择下图 ② 的 ZIP 格式文件,否则,选择 TAR 格式文件下载即可。
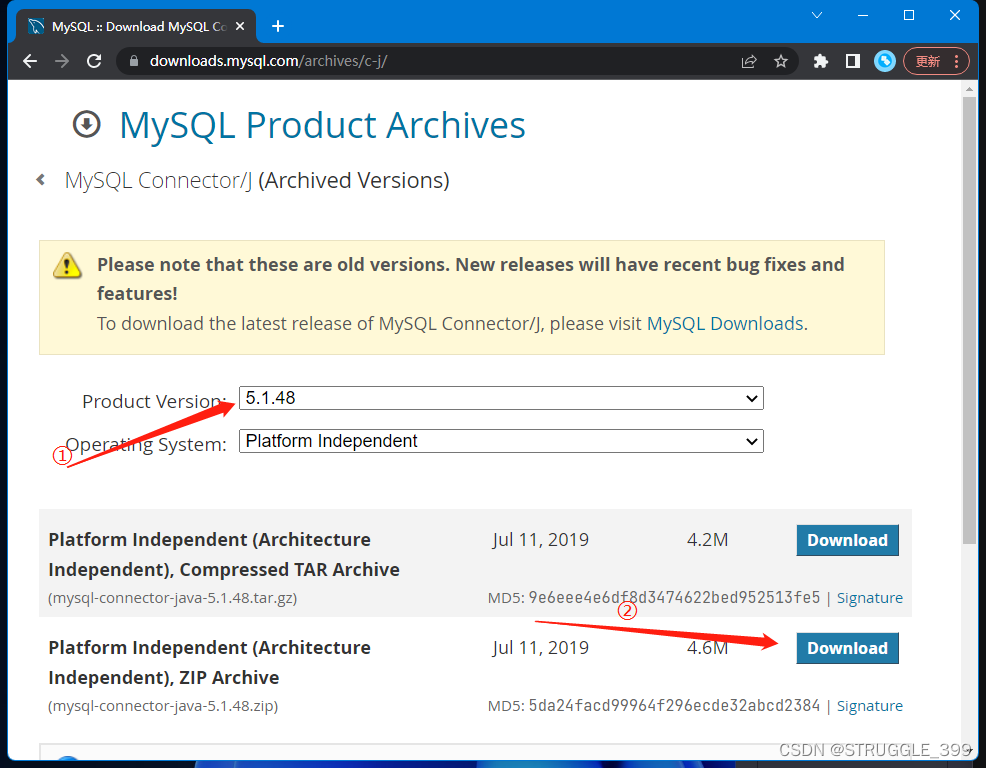
下载完成后,将其解压,获取里面的 jar 包即可。
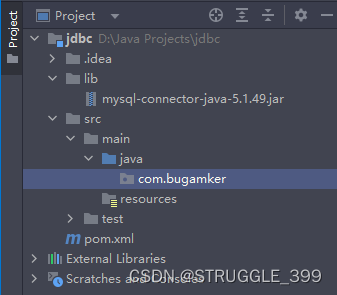
创建 Java 项目,在项目中建立一个 lib 文件夹,专门用来存放项目依赖的 jar 包,引入 Connector 后,项目结构如下:
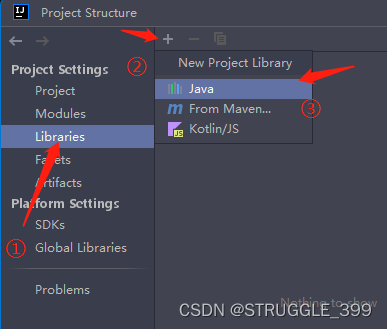
接下来在 IDEA 中,进入项目结构(快捷键:CTRL + ALT + SHIFT + S),按照这个步骤,引入 lib 下Connector jar 包即可
添加后的结果:
这样,Mysql 驱动器类就算正确导入了
方式二:
使用 Maven 导入 Mysql 的驱动器类依赖,这种方式会比较简单,导入依赖的坐标可以在这个链接 Maven 仓库 查找
一个小插曲,自行下载 Maven:Maven 官网
点击 Download 页面,选择图中所示的 maven 进行下载,

解压后,首先可以修改其配置文件,为其设定本地仓库的地址,一般设定为Maven 目录下的 repo 文件夹即可;其次是配置国内镜像的仓库,由于 Maven 的中央仓库在国外,国内访问的速度一般较慢,Maven 依赖的导入,首先查找本地仓库,然后再查找国内镜像仓库(如果有配置),最后才会找中央仓库。
-
找到
<localRepository>标签,修改为:<localRepository>D:\Program Files\apache-maven-3.8.6\repo</localRepository>注:这里的
D:\Program Files\apache-maven-3.8.6是我安装 Maven 的目录 -
找到
<mirror>标签,配置 aliyun 镜像仓库(配置了之后快到飞起😄)<mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> <mirrorOf>central</mirrorOf> </mirror>
在 maven 仓库中搜索 connector,找到 Mysql 的 Java Connector 依赖坐标,复制
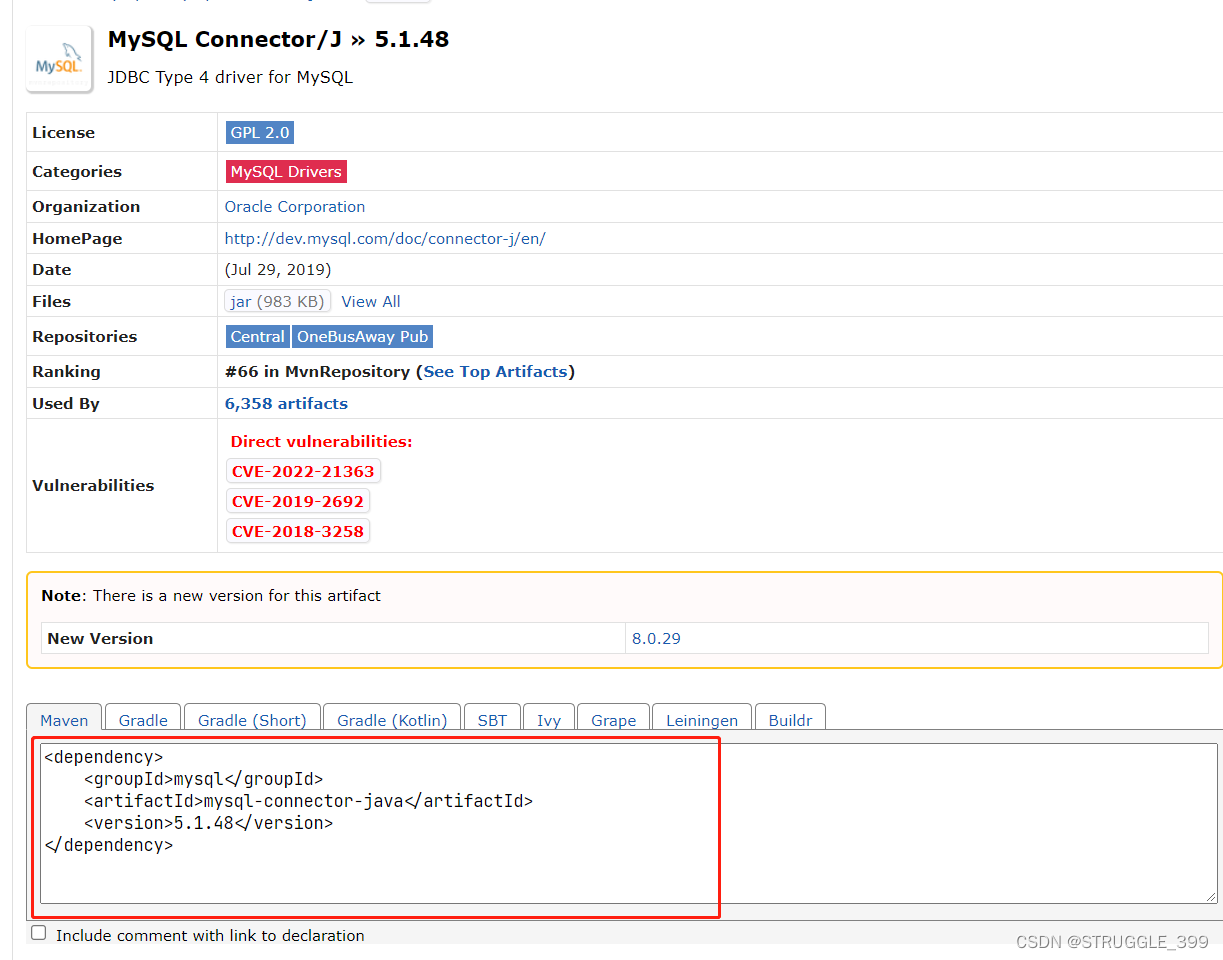
粘贴到 Maven 项目的 pom.xml 文件中即可:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bugmaker</groupId>
<artifactId>jdbc</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
</dependencies>
</project>
以上两种方式选择其一即可,推荐使用第二种,使用 Maven 构建项目会很方便。
快速入门
JDBC 的代码结构基本类似,先看一个入门的案例,一张 account 表,id 主键 + balance 两个字段,创建表的 SQL 语句如下:
DROP TABLE IF EXISTS account;
CREATE TABLE account (
id INT PRIMARY KEY AUTO_INCREMENT,
balance INT NOT NULL
);
INSERT INTO
account (balance)
VALUES
(66),
(77),
(88),
(99);
SELECT * FROM account;
原始的数据如下:
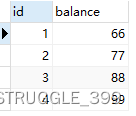
下面将 id 为 2的账户余额设置为 6666
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class JdbcDemo {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 数据库连接信息
String url = "jdbc:mysql://localhost:3306/db";
String username = "root";
String password = "fan1229417754";
// 定义 SQL 语句
String sql = "UPDATE account SET balance=6666 WHERE id = 2";
// 获取连接对象 + 获取 SQL 对象
try (Connection conn = DriverManager.getConnection(url, username, password);
Statement stmt = conn.createStatement()) {
// 执行 SQL 语句 并返回结果
int count = stmt.executeUpdate(sql);
// 处理结果
System.out.println("影响行数: " + count);
}
}
}
执行代码结果:
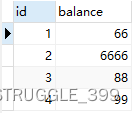
【总结】
JDBC 编程步骤:
- 注册驱动
- 获取连接对象 Connection 以及 SQL 执行对象
- 定义SQL语句
- 执行 SQL 获取返回结果
- 处理结果
- 释放资源
DriverManager
DriverManager 就是驱动管理器对象,它的作用就是获取数据库的连接对象。
-
注册驱动
Class.forName("com.mysql.jdbc.Driver");【注】
- MySQL 5 之后的驱动,可以省略注册驱动的步骤
- 会自动加载 jar 包中的 META-INF/services/java.sql.Driver 文件中的驱动类
-
获取连接
static Connection getConnection(String url, String username, String password);getConnection(url, username, password)是一个静态方法,用于返回一个数据库连接对象参数解析:
-
url:数据库的 url
格式:
jdbc:mysql://ip地址(域名):端口号/数据库名称?参数键值对1&参数键值对2&...例子:
jdbc:mysql://localhost:3306/db?useSSL=false&useServerPrepStmts=true细节:
- 如果连接的是本机的 MySQL 服务器,并且 MySQL 服务器的默认端口是 3306,则 URL 可以简写为:
jdbc:mysql///数据库名称?参数键值对1&参数键值对2... - 配置
useURL=false参数,禁用安全连接方式,解决警告提示
- 如果连接的是本机的 MySQL 服务器,并且 MySQL 服务器的默认端口是 3306,则 URL 可以简写为:
-
username:用户名
-
password:密码
-
Connection
数据库连接对象
-
获取执行 SQL 对象
-
普通执行 SQL 对象
Statement createStatement() -
预编译 SQL 的执行 SQL 对象:防止 SQL 注入
PreparedStatement prepareStatement(sql) -
执行存储过程的对象
CallableStatement prepareCall(sql)
-
-
管理事务
-
MySQL 事务管理
开启事务:BEGIN;/ START TRANSACTION; 提交事务:COMMIT; 回滚事务:ROLLBACK; MySQL 默认自动提交事务 -
JDBC 事务管理
开启事务:setAutoCommit(boolean autoCommit) true 为自动提交事务; false 为手动提交事务 即为开始事务 提交事务:commit() 回滚事务:rollback() -
【例子】
try { // 开启事务 conn.setAutoCommit(false); // 执行多条 SQL ... // 提交事务 conn.commit(); } catch(Exception e) { conn.rollback(); e.printStackTrace(); }【细节】在 catch 中执行事务的回滚操作
-
【案例】
测试事务,使用的表仍然是入门案例的表,注意到模拟事务中,会出现一个运算异常,因此根据事务的原子性,该事务执行的所有 SQL 语句均没有效果,将会被回滚。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class JdbcDemo {
public static void main(String[] args) throws SQLException {
testTransaction();
}
public static void testTransaction() throws SQLException {
// 数据库连接信息
String url = "jdbc:mysql://localhost:3306/db";
String username = "root";
String password = "fan1229417754";
// 定义 SQL 语句
String sql1 = "UPDATE account SET balance=77 WHERE id = 2";
String sql2 = "UPDATE account SET balance=22 WHERE id = 3";
// 获取连接对象 + 获取 SQL 对象
Connection conn = DriverManager.getConnection(url, username, password);
Statement stmt = conn.createStatement();
try {
// 模拟事务
conn.setAutoCommit(false);
stmt.executeUpdate(sql1);
// 出错
System.out.println(1 / 0);
stmt.executeUpdate(sql2);
conn.commit();
} catch (Exception e) {
System.out.println("事务出错... 正在进行回滚");
conn.rollback();
} finally {
// 关闭资源
conn.close();
stmt.close();
}
}
}
不会因为成功执行了 sql1,而造成数据的更改,这实现了事务功能。
Statement
SQL 执行对象,作用是用来执行 SQL 语句
int executeUpdate(sql); // 执行 DML、DDL语句
// 返回值: 1. DML 语句印象的行数 2. DDL 语句返回值可能为 0
ResultSet executeQuery(sql); // 执行 DQL 语句
// 返回值:ResultSet 结果集对象
Example:
// DML 语句
String sql = "UPDATE user SET password=2048 WHERE id=1001 OR id=1002";
int count = stmt.executeUpdate(sql);
if (count > 0) {
System.out.println("修改成功");
} else {
System.out.println("修改失败");
}
PreparedStatement
作用:进行预编译的 SQL 语句并执行:预防 SQL 注入问题
-
获取 PreparedStatment 对象
// SQL 语句中的参数值,使用 ? 占位符进行替代 String sql = "SELECT * FROM tb_user WHERE username=? AND password=?"; // 通过 Connection 对象获取,并传入对应的 SQL 语句 PreparedStatement pstmt = conn.prepareStatement(sql); -
设置参数值
PreparedStatement 对象: setXxx(参数1, 参数2): 给 ? 赋值 // Xxx:数据类型; 如 setInt(参数1, 参数2) /* 参数 * 参数1: ? 的位置编号,从 1 开始 * 参数2: ? 的值 */ -
执行 SQL
pstmt.executeUpdate(); // 不需要再传递 SQL
Example:
// 定义 SQL
String sql = "SELECT * FROM tb_user WHERE username=? AND password=?";
// 通过 Connection 对象获取,并传入对应的 SQL 语句
PreparedStatement pstmt = conn.prepareStatement(sql);
String username="张三";
String password="123456";
// 设置参数
pstmt.setString(1, username);
pstmt.setString(2, password);
ResultSet rs = pstmt.executeQuery();
SQL 注入攻击
SQL 注入:通过操作输入来修改实现定义好的 SQL 语句,用以达到执行代码对服务器进行 攻击 的方法。
【例子】
用户登录操作:
SELECT * FROM tb_user WHERE username='张三' AND pass='123';
后台获取前端输入的用户名和密码,然后将其拼接:
String sql = "SELECT * FROM tb_user WHERE username='" + username + "' AND password='" + password + "'";
当密码为:' OR '1' = '1,拼接后的 SQL 语句为:
String sql = "SELECT * FROM tb_user WHERE username='xxx' AND password='' OR '1'='1'";
第一个单引号将原有password的单引号对截断了,后面则是一个恒等式,从而表达式一定能够成功,就达到了 SQL 注入攻击的效果
Statement 和 PreparedStatement 的区别
-
预编译 SQL,性能更高
-
防止 SQL 注入:将敏感字符进行转义
-
PreparedStatement 预编译功能开启:
useServerPrepStmts=trueString url="jdbc:mysql://localhost:3306/db?useServerPrepStmts=true&useSSL=fasle"
原理:
- 在获取 PreparedStatement 对象时,将 SQL 语句发送给 MySQL 服务器进行检查,编译
- 执行时就不需要再进行这些步骤了,速度很快
- 如果 SQL 模板一样,则只需要进行一次检查、编译
ResultSet
封装了 DQL 查询语句的结果
获取查询结果:
boolean next(); // 1. 将光标从当前位置向前移动一行 2. 判断当前行是否为有效行
// 返回值: true:有效行 false:无效行
xxx getXxx(parameter); // 获取数据
// xxx:数据类型, 如:int getInt(参数); String getString(参数)
/* 参数:
* int: 列的编号,从 1 开始
* String:列的名称
*/
Example:
while (rs.next()) {
// 获取数据
rs.getXxx(参数);
// 处理数据
...
}
【案例】
数据库表 tb_brand 准备
DROP TABLE IF EXISTS tb_brand;
CREATE TABLE tb_brand (
id INT PRIMARY KEY AUTO_INCREMENT,
brand_name VARCHAR(32),
company_name VARCHAR(32),
ordered INT,
description VARCHAR(128),
status INT
);
INSERT INTO tb_brand(brand_name, company_name, ordered, description, status)
VALUES
('三只松鼠', '三只松鼠股份有限公司', 5, '好吃不上火', 0),
('华为', '华为技术有限公司', 100, '是中国人就用华为手机',1),
('小米', '小米科技有限公司', 50, '你没事吧?', 1);
SELECT * FROM tb_brand;
package com.bugamker.jdbc;
import java.sql.*;
public class JdbcDemo {
public static void main(String[] args) throws SQLException {
testResultSet();
}
public static void testResultSet() throws SQLException {
// 数据库连接信息
String url = "jdbc:mysql://localhost:3306/db";
String username = "root";
String password = "fan1229417754";
// 定义 SQL 语句
String sql = "SELECT * FROM tb_brand";
try (Connection conn = DriverManager.getConnection(url, username, password);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
// 执行 SQL 语句
ResultSet rs = pstmt.executeQuery();
// 遍历集合
while (rs.next()) {
int id = rs.getInt("id");
String brandName = rs.getString(2);
String companyName = rs.getString("company_name");
int ordered = rs.getInt(4);
String description = rs.getString("description");
int status = rs.getInt(6);
System.out.println("id=" + id
+ ", brandName=" + brandName
+ ", companyName=" + companyName
+ ", ordered=" + ordered
+ ", description=" + description
+ ", status=" + status);
}
}
}
}
结果:
id=1, brandName=三只松鼠, companyName=三只松鼠股份有限公司, ordered=5, description=好吃不上火, status=0
id=2, brandName=华为, companyName=华为技术有限公司, ordered=100, description=是中国人就用华为手机, status=1
id=3, brandName=小米, companyName=小米科技有限公司, ordered=50, description=你没事吧?, status=1
数据库连接池
简介:
- 数据库连接池是一个容器,负责分配、管理数据库连接(Connection)
- 它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏
优点:
- 资源复用
- 提高系统响应速度
- 避免数据库的连接遗漏
实现
标准接口:DataSource
-
官方提供的数据库连接池标准接口,由第三方组织实现此接口
-
功能:获取连接
Connection getConnection();
下面使用 Alibaba 的 druid 连接池作为例子
Druid 使用步骤
-
导入依赖
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.2.11</version> </dependency> -
定义配置文件
driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost/db?useSSL=false&useServerPrepStmts=true username=root password=fan1229417754 # 初始化连接数量 initialSize=5 # 最大连接数 maxActive=10 # 最大等待时间(ms) maxWait=3000 -
加载配置文件
// 配置文件目录 System.getProperty("user.dir")-- 获取当前工程文件夹路径 String path="..."; // 加载配置文件 Properties prop = new Properties(); prop.load(new FileInputStream(path)); -
获取数据库连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop); -
获取连接对象
Connection conn = dataSource.getConnection();之后的操作就是与之前一样的
【案例】
使用的表是 tb_brand,前面有介绍过,下面介绍 Druid 使用的方法,并测试 Query(成功)
package com.bugamker.jdbc;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
public class DruidDemo {
private final DataSource dataSource;
public DruidDemo(DataSource dataSource) {
this.dataSource = dataSource;
}
public static void main(String[] args) throws Exception {
// System.out.println(System.getProperty("user.dir")); // 获取 当前工作目录
// 加载配置文件
String path = "src\\main\\resources\\druid.properties";
Properties properties = new Properties();
properties.load(Files.newInputStream(Paths.get(path)));
// 获取数据库连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
DruidDemo druid = new DruidDemo(dataSource);
druid.testQuery();
}
void testQuery() throws SQLException {
String sql = "SELECT * FROM tb_brand";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
ResultSet rs = pstmt.executeQuery();
// 遍历集合
while (rs.next()) {
int id = rs.getInt("id");
String brandName = rs.getString("brand_name");
String companyName = rs.getString("company_name");
int ordered = rs.getInt("ordered");
String description = rs.getString("description");
int status = rs.getInt("status");
System.out.println("id=" + id
+ ", brandName=" + brandName
+ ", companyName=" + companyName
+ ", ordered=" + ordered
+ ", description=" + description
+ ", status=" + status);
}
}
}
}
增删改查案例
操作的表仍然是 tb_brand
完成商品品牌数据的增删改查操作
- 查询:查询所有数据
- 添加:添加品牌
- 修改:根据 id 修改
- 删除:根据 id 删除
DROP TABLE IF EXISTS tb_brand;
CREATE TABLE tb_brand (
id INT PRIMARY KEY AUTO_INCREMENT,
brand_name VARCHAR(32),
company_name VARCHAR(32),
ordered INT,
description VARCHAR(128),
status INT
);
INSERT INTO tb_brand(brand_name, company_name, ordered, description, status)
VALUES
('三只松鼠', '三只松鼠股份有限公司', 5, '好吃不上火', 0),
('华为', '华为技术有限公司', 100, '是中国人就用华为手机',1),
('小米', '小米科技有限公司', 50, '你没事吧?', 1);
代码:
package com.bugamker.jdbc;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
public class JdbcOperation {
private final DataSource dataSource;
public JdbcOperation(DataSource dataSource) {
this.dataSource = dataSource;
}
/**
* 查询所有品牌数据
*/
public void selectAll() throws SQLException {
String sql = "SELECT * FROM tb_brand";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
ResultSet rs = pstmt.executeQuery();
// 遍历集合
while (rs.next()) {
int id = rs.getInt("id");
String brandName = rs.getString("brand_name");
String companyName = rs.getString("company_name");
int ordered = rs.getInt("ordered");
String description = rs.getString("description");
int status = rs.getInt("status");
System.out.println("id=" + id
+ ", brandName=" + brandName
+ ", companyName=" + companyName
+ ", ordered=" + ordered
+ ", description=" + description
+ ", status=" + status);
}
}
}
/**
* 添加
*/
public void add() throws SQLException {
// 定义 SQL 语句
String sql = "INSERT INTO tb_brand(brand_name, company_name, ordered, description, status) VALUES (?, ?, ?, ?, ?)";
// 获取连接对象
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)) {
// 接收数据(模拟)
String brandName = "Apple";
String companyName = "Apple.inc";
int ordered = 30;
String description = "为人民服务";
int status = 1;
// 设置参数
pstmt.setString(1, brandName);
pstmt.setString(2, companyName);
pstmt.setInt(3, ordered);
pstmt.setString(4, description);
pstmt.setInt(5, status);
// 执行 sql, 并获取受影响行数(insert 结果)
int count = pstmt.executeUpdate();
// 获取动态自增主键
ResultSet rs = pstmt.getGeneratedKeys();
if (rs.next()) {
int insertedKey = rs.getInt(1);
System.out.println("自增主键:" + insertedKey);
}
// 处理返回结果
if (count > 0) {
System.out.println("Insert Successfully!");
} else {
System.out.println("Insert fail!");
}
}
}
/**
* 修改
*/
public void update() throws SQLException {
// 定义 SQL 语句
String sql = "UPDATE tb_brand SET brand_name=?, company_name=?, ordered=?, description=?, status=? WHERE id=?";
// 获取连接对象
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
// 接收数据(模拟)
int id = 4;
String brandName = "Apple";
String companyName = "Apple.inc";
// 更新排序级别
int ordered = 3000;
String description = "为人民服务";
int status = 1;
// 设置参数
pstmt.setString(1, brandName);
pstmt.setString(2, companyName);
pstmt.setInt(3, ordered);
pstmt.setString(4, description);
pstmt.setInt(5, status);
pstmt.setInt(6, id);
// 执行 sql, 并获取受影响行数(insert 结果)
int count = pstmt.executeUpdate();
// 处理返回结果
if (count > 0) {
System.out.println("Update Successfully!");
} else {
System.out.println("Update fail!");
}
}
}
public void deleteById() throws SQLException {
// 定义 SQL 语句
String sql = "DELETE FROM tb_brand WHERE id=?";
// 获取连接对象
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
// 接收数据(模拟)
int id = 4;
// 设置参数
pstmt.setInt(1, id);
// 执行 sql, 并获取受影响行数(insert 结果)
int count = pstmt.executeUpdate();
// 处理返回结果
if (count > 0) {
System.out.println("Delete Successfully!");
} else {
System.out.println("Delete fail!");
}
}
}
public static void main(String[] args) throws Exception {
// 加载配置文件
String path = "src\\main\\resources\\druid.properties";
Properties properties = new Properties();
properties.load(Files.newInputStream(Paths.get(path)));
// 获取数据库连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
JdbcOperation operation = new JdbcOperation(dataSource);
// 模拟增删查改
operation.selectAll();
operation.add();
operation.selectAll();
operation.update();
operation.selectAll();
operation.deleteById();
operation.selectAll();
}
}
输出结果:
信息: {dataSource-1} inited
id=1, brandName=三只松鼠, companyName=三只松鼠股份有限公司, ordered=5, description=好吃不上火, status=0
id=2, brandName=华为, companyName=华为技术有限公司, ordered=100, description=是中国人就用华为手机, status=1
id=3, brandName=小米, companyName=小米科技有限公司, ordered=50, description=你没事吧?, status=1
Insert Successfully!
id=1, brandName=三只松鼠, companyName=三只松鼠股份有限公司, ordered=5, description=好吃不上火, status=0
id=2, brandName=华为, companyName=华为技术有限公司, ordered=100, description=是中国人就用华为手机, status=1
id=3, brandName=小米, companyName=小米科技有限公司, ordered=50, description=你没事吧?, status=1
id=4, brandName=Apple, companyName=Apple.inc, ordered=30, description=为人民服务, status=1
Update Successfully!
id=1, brandName=三只松鼠, companyName=三只松鼠股份有限公司, ordered=5, description=好吃不上火, status=0
id=2, brandName=华为, companyName=华为技术有限公司, ordered=100, description=是中国人就用华为手机, status=1
id=3, brandName=小米, companyName=小米科技有限公司, ordered=50, description=你没事吧?, status=1
id=4, brandName=Apple, companyName=Apple.inc, ordered=3000, description=为人民服务, status=1
Delete Successfully!
id=1, brandName=三只松鼠, companyName=三只松鼠股份有限公司, ordered=5, description=好吃不上火, status=0
id=2, brandName=华为, companyName=华为技术有限公司, ordered=100, description=是中国人就用华为手机, status=1
id=3, brandName=小米, companyName=小米科技有限公司, ordered=50, description=你没事吧?, status=1
需要注意的是,获取自增主键的方式:
PreparedStatement pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
...
int count = pstmt.executeUpdate();
// 获取动态自增主键
ResultSet rs = pstmt.getGeneratedKeys();
if (rs.next()) {
int insertedKey = rs.getInt(1);
System.out.println("自增主键:" + insertedKey);
}
总结
JDBC 是 Java 操纵数据的一个规范接口,不同数据库的驱动类不同,但是接口规范是相同的,因此使用起来的代码可以是一致的,重要的是理解 JDBC 中涉及到的一些类:DriverManager、Connection、Statement、PreparedStatement、ResultSet等,还需要知道 PreparedStatement 和 Statement 的区别,一般会使用前者,不仅能够防止 SQL 注入,还可以使得执行效率更高。最后还谈及了数据库连接池,并做了一个 Druid 数据库连接池的使用案例,需要知道的是数据库连接池的优点,实际上和线程池的优点差不多,频繁地创建和销毁一个数据库连接的开销会很大,因此数据库连接池对连接作出了管理,使得其效率更高。总之,使用 Java 的 JDBC 操纵数据库,需要有良好的 SQL 语句编写能力,这是个重点。














 5876
5876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









