







论文题目
Rethinking Annotation for Object Detection: Is Annotating Small-size Instances Worth Its Cost?
文章🔗https://arxiv.org/pdf/2412.05611
1简介
在图像中检测仅占据很小区域的物体对人类来说都是困难的,即使是人类也是如此。因此,标注小尺寸物体实例既困难又昂贵。本研究挑战常识,提出了以下问题:标注小尺寸实例是否值得其成本?我们将这一问题重新表述为一个可验证的问题:我们能否使用训练数据中不含小尺寸实例的检测器来检测小尺寸实例?我们评估了两种方法:一种是在测试时放大输入图像的方法,另一种是在训练时缩小图像的方法。使用 COCO 数据集进行的实验表明,第一种方法,加上缩小训练输入与测试输入之间领域差距的补救措施,至少可以达到使用完整训练数据训练的基本检测器的性能。尽管该方法需要对具有不同缩放的输入图像应用相同的检测器两次,但我们证明了其知识蒸馏可以产生一个单路径检测器,其性能与相同的基线检测器相当。这些结果指出了重新思考物体检测训练数据标注的必要性。
为了研究小尺寸实例标注的(不)重要性,考虑了两种方法并评估了它们的性能。一种方法是在测试时将图像上采样后输入检测器,旨在使其检测小尺寸实例。它使用除小尺寸物体以外的物体实例训练检测器。另一种方法是在训练时对图像进行下采样。它对非小尺寸物体实例进行下采样,并使用它们来训练检测器。使用 COCO 数据集,因为它是在社区中使用最广泛的目标检测数据集。采用将其分类为小型/中型/大型实例的方法。
通过实验评估了上述两种方法,并找到了关于小尺寸实例标注重要性的问题的答案。答案是,可以使用在没有小尺寸实例的数据集上训练的检测器来检测小尺寸目标实例。具体来说,在测试时对图像进行上采样的方法,以及缩小训练和测试输入之间域差距的补救措施,至少达到了使用完整训练数据训练的基线检测器的可比性能。实验结果还表明,在训练时对图像进行下采样的方法效果不佳,这可能归因于上述域差距。此外,尽管上采样方法需要对输入图像应用两次相同的检测器,分别使用不同的缩放比例来检测所有实例大小,但我们表明其蒸馏可以生成一个单路径检测器,其性能与基线检测器相当。这些结果表明需要重新思考目标检测训练数据的标注。
2.引言
以往对目标检测的研究已经非常广泛。卷积神经网络(CNNs)的应用带来了显著的性能提升。主流的方法是使用人工手动标注的大规模数据集以监督方式训练 CNN 或其他深度网络。已经创建了多个数据集,如 PascalVOC [4]、COCO [19]、Open Images 数据集 [16] 和 KITTI [7],这些数据集促进了研究的进步。在本文中,我们重新考虑了对象检测中的图像标注。这是一种以某种方式为图像中的每个对象实例提供边界框和类别标签的过程[29, 14, 30]。由于这往往成本较高,因此了解以最低成本(即,在标注数据上训练的模型性能更高如何获得最显著的效果是至关重要的。这种思考对于实践者来说至关重要,尽管研究人员并未给予太多关注。
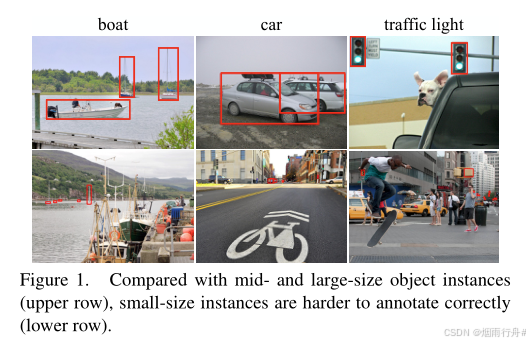
在本文中,我们探讨了图像中小区域物体标注的问题。其背景中存在一个事实,即标注如此小的实例往往比中等或大型实例更昂贵。具体来说,由于它们很小,标注者往往难以找到它们,或者很难对它们的类别甚至存在性做出无误的判断;见图 1。此外,小尺寸实例往往会以大量群体的形式出现(例如,人群),使得一个一个地标注它们变得繁琐,如图 2 所示。因此,标注者需要更多的时间来标注小尺寸实例。实例越小,这些倾向就越明显。

考虑到这些,我们提出如下问题:标注小对象实例是否值得其成本?
对小目标实例进行标注是否值得其成本?没有直接尝试回答这个问题,而是考虑是否可以训练一个检测器来检测小尺寸实例,而无需对其进行标注。鉴于物体表观大小与其距离相关的基本事实,考虑在训练时或测试时调整输入图像的大小,以查看是否可以做到。
这种方法面临的一个障碍是训练数据和测试数据之间可能出现的域差距。通过缩小非小型实例来创建的合成小型实例将与实际小型实例的外观不同。放大其原始尺寸较小的目标实例将与实际非小型实例的外观不同。外观差异可能存在两种类型。一种是图像分辨率的差异;将小尺寸实例进行上采样会导致其外观模糊。另一种是剩余因素的差异,例如物体的视角(例如,由用于捕获图像的相机焦距决定)和上下文(例如,图像中物体的周围区域)。
为了在考虑到上述障碍的情况下调查小尺寸实例标注的重要性,我们考虑了两种方法并评估了它们的性能。一种方法是在测试时将图像放大,目的是让检测器能够检测到小尺寸实例。它仅使用除小尺寸实例之外的对象实例进行训练。另一种方法是在训练时将图像缩小。它将非小尺寸对象实例缩小,并使用这些实例进行检测器的训练。我们使用 COCO 数据集,因为它是社区中用于对象检测最广泛使用的数据集。我们采用了其将实例划分为小/中/大尺寸的分类。
我们实验性地评估了上述两种方法,找到了关于小尺寸实例标注重要性的答案。答案是,我们可以使用在没有小尺寸实例的数据集上训练的检测器来检测小尺寸对象实例。具体来说,测试时放大图像的方法,再加上缩小训练输入与测试输入之间领域差距的补救措施,至少可以达到基线检测器使用完整训练数据训练时的性能。实验结果还表明,训练时缩小图像的方法效果不佳,这可能是由于上述领域差距所致。此外,尽管放大图像方法需要对输入图像应用两次不同缩放的同一检测器来检测所有实例大小,但我们证明了其知识蒸馏可以产生单路径检测器,其性能与基线检测器相当。这些结果指出了重新思考对象检测训练数据标注的必要性。
3 小目标标注存在的问题
3.1. 标注困难
如图 1 所示,通常难以标注小尺寸对象实例。这是因为对象实例越小,识别它们就越接近人类视觉能力的上限。首先,由于小尺寸实例的大小,标注者更容易忽略这些实例。标注者需要在图像中搜索 everywhere。此外,对于小尺寸的视觉实体,标注者往往难以判断它们是否是需要标注的对象,或者它们属于哪个类别。这不可避免地会增加标注时间和成本。
当图像中实例很多时,标注工作会变得繁琐,如图 2 所示。这种情况最常发生在对象类别为人(即人群)、 storefront 中展示的商品以及盘中的食材等。为了避免标注成本增加,COCO 设定了一个规则,限制每类对象在图像中需要标注的实例数量上限。为此提供了一个特殊的标签“iscrowd”。标注人员需要每类对象/图像标注十个实例或更少。他们可以指定一个较大的边界框来包含他们选择不单独标注的小尺寸实例,并将 iscrowd 设为 yes,如图 2(b)所示。带有此标签的边界框在训练时不会使用,并在评估检测器性能时被排除,以避免上述问题。然而,这仍取决于标注人员的判断何时使用此选项,上述困难仍未解决。
3.2. 小目标检测准确性
由于其难度,标注小目标更容易出错。我们推测小目标标注确实会有更多的错误,例如在 COCO 数据集中。然而,这一推测并不容易验证。这涉及许多复杂因素,如人类视觉的界限,即它能精确识别多小的目标物体。因此,我们反而进行了一项简单的实验,其结果提供了间接证据。
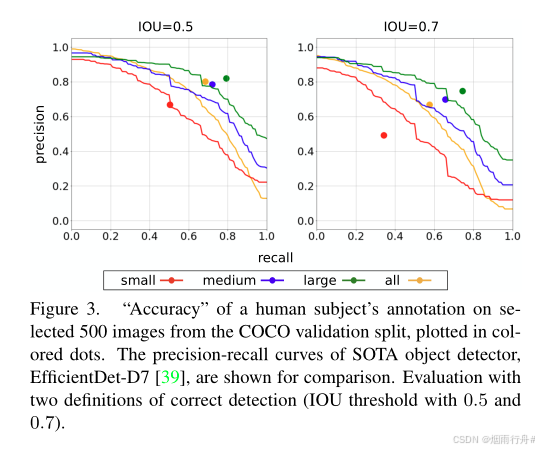
本文的作者之一随机选择了 COCO 2017 数据集验证分割中的 500 张图片进行标注。将他的标注工作视为一个检测器,我们可以使用 COCO 提供的 ground-truth 标注来评估其“准确性”。图 3 显示了结果。为了比较,我们还展示了当前最先进的检测器之一 EfficientDet-D7 的准确性[39]。物体实例根据 COCO 的标准程序分为三类:小、中、大。从图 3 可以看出两点观察结果。一是他对于小尺寸物体实例的表现非常差,远离右上角(即精确率=1 且召回率=1)。这是经过精心工作的结果,其准确性应该接近普通人类平均水平的最佳表现。由此自然会想到结果暗示了上述标注的极限。另一点观察是,虽然他在中等和大型实例上优于 EfficientDet,但在小实例上这种优势消失。现有的 SOTA 检测器是否已经达到了小尺寸实例的人类水平表现,这与普遍认为需要提高检测准确性的观点相矛盾吗?
4. 方法
我们的基本思路是排除小对象实例的标注,并仅使用具有特定大小以上(即 COCO 中的中等和大型实例)的实例进行检测器的训练。为了仍然能够检测小尺寸的对象,我们在训练时间和测试时间中控制输入图像的大小。由于与检测器算法分离,这可以与任何检测器一起使用。在我们的实验中,我们分别使用 Faster RCNN [34] 和 FCOS [42] 作为基于锚点和非锚点检测器的代表。
4.1. 测试时图像上采样
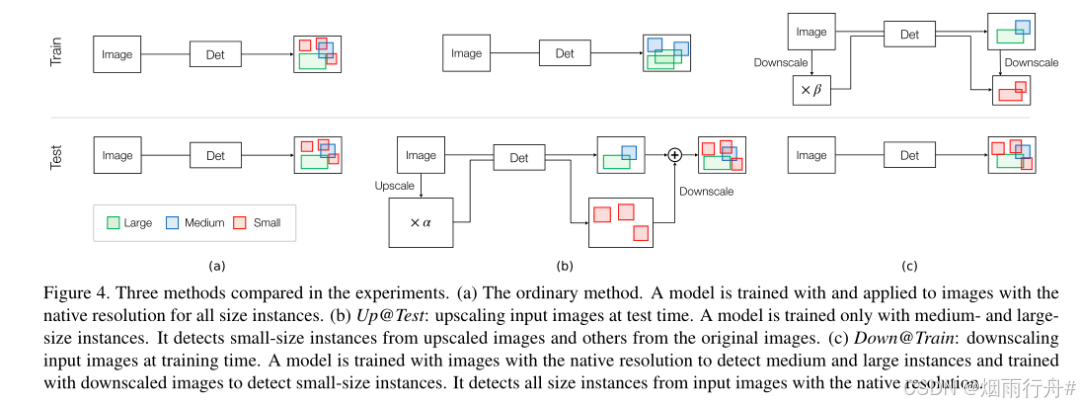
图 4(b) 说明了这种方法。使用仅包含中型和大型实例的数据集训练了一个检测器。因此,该检测器将无法正确检测小型实例。所以在测试时对输入图像进行上采样,然后将其输入到检测器中,将检测器应用于同一图像两次。首先,将输入图像(不调整大小)输入检测器,检测器检测中、大型目标实例。然后将同一图像以放大倍率 α(> 1)进行调整大小,然后输入检测器,检测器检测小型实例。检测到的边界框以 1/α 的比例进行调整大小,并与第一遍检测到的边界框合并,可以并行执行这两个计算,将此方法称为 Up@Test。该方法的一个潜在问题是,小尺寸目标实例的放大图像与其理想对应物(即,中等或大尺寸实例的原生分辨率图像)不同。通常,放大后的图像会变得模糊,缺乏精细细节。中等和大型实例没有这样的模糊,这可能会在训练和测试样本之间产生差距,导致性能下降。针对这个问题,将有两种潜在的解决方法。一种是在将输入图像上采样到与中、大型实例图像的清晰度一致时,对输入图像应用超分辨率。另一种是在训练时使用模糊图像,将训练图像转换为与小尺寸实例的放大图像具有相同模糊程度的图像;然后将它们与原始图像一起使用。有多种方法可以使图像模糊。在实验中测试了两种方法。一个是尺度为 σ(以像素为单位)的高斯模糊。另一个是降采样-升采样,即先将图像缩小 γ 倍,然后放大 γ 倍。使用锚框的检测器不再需要这些用于小实例,但在实验中没有使用 Faster RCNN 来消除它们。
4.2. 训练时图像降尺度
图4(c) 说明了该方法。使用原始的中型和大型实例及其缩小版本来训练检测器。一些调整大小的实例将用作小型实例。与上述方法不同,得到的检测器已经学会检测小型实例。因此可以像使用普通检测器一样使用它;也就是说,将输入图像馈送到模型中,无需调整大小,将这种方法称为 Down@Train。在实验中采用双线性插值来调整图像大小,并测试了 β = 1/2、1/3 和 1/4 的缩放比例。选择这些比例是因为 COCO 数据集中小型和中型实例的面积分别在 [0, 322)和 [322, 962)像素范围内;因此,按 1/3 比例缩小的中型实例与小型实例具有相同的范围。由于图像降尺度产生的效果类似于使用远程相机进行图像采集,因此它们的图像分辨率几乎没有或根本没有差距。
4.3. 训练和测试输入之间的域差距
上述两种方法的区别在于,一种方法在测试时将输入的小实例上采样到与训练集中中等或大型实例相匹配,而另一种方法将它们下采样到与在测试时遇到的小型实例相匹配。然而,它们在统计意义上,训练样本和测试样本之间都会出现差距。
存在两种类型的差距。一种是由分辨率差异引起的。如上所述,这仅在测试时对第一种上采样输入的方法才会发生。预计这种差距可以通过简单的数据增强来缩小或忽略。另一种情况的出现是由于其他原因,例如物体上下文和视角的差异。中等大小或更大的实例在图像中形成明显人群的可能性较小,这会导致上下文差异,即它们周围区域的差异。
4.4. 单路径模型蒸馏
第一个方法,Up@Test,将输入图像以不同的缩放比例两次馈送到检测器 CNN。由于其计算成本是基础检测器的两倍,因此如果 Up@Test 在检测精度方面与基础检测器相当,那么说 Up@Test 与基础检测器相当可能不公平。因此考虑将模型蒸馏成单路径模型。使用双路径模型作为教师,为小物体实例生成伪标签(标注),并使用它们与中型和大型实例的原始标注一起训练单路径学生模型。
5、实验
5.1结果概述
表 2 显示了我们迄今为止所见结果的总结。评估了三种方法(即,Baseline、Up@Test 和 Down@Train)。这三种方法可以通过以下三个因素来表征:由于图像缩放导致的训练和测试输入之间是否存在域差距,是否提供小尺寸目标标注以及输入上采样(即,在测试时对输入图像进行上采样)。可以得出以下观察结果:
i) 即使没有真实的小尺寸实例标注,检测器也能学会检测小尺寸实例。为了达到相同的精度水平,仅使用测试时上采样就足够了。Up@Test-scale 比 Baseline 具有更高的性能,这证实了这一点。
ii) 在训练时对目标实例进行降尺度处理效果不佳。这可能是由于小尺寸实例的原始标注和降尺度标注之间存在域差距。这可能是由图像分辨率以外的因素造成的,即目标的上下文和视角差异。
iii) 在测试时对输入图像进行上采样非常有效,可以弥补由域间隙造成的损失。
5.2单路径蒸馏模型
Up@Test 的性能与 Baseline 相当甚至更好。然而它将输入图像以不同的缩放比例两次馈送到检测器,因此 Up@Test 与 Baseline 相匹配可能不公平。因此考虑将 Up@Test 模型蒸馏到单路径基线检测器。
以以下方式进行蒸馏。首先将 Up@Test 模型应用于 COCO 数据集训练集的所有图像,获得检测结果。然后选择置信度得分大于指定阈值且边界框大小在小目标实例范围内的检测结果。然而将阈值设为大于 0.5 时,实例的数量往往远小于原始的小尺寸实例,如图 8 所示。这导致不同实例大小之间实例数量严重失衡,从而导致性能平庸。因此额外使用 Down@Train 通过缩小中、大型实例标注来生成实例。将所有标注(即伪造和缩小的小型实例以及原始的中、大型实例)合并后,用它们训练一个学生模型。对学生模型使用相同的检测器。
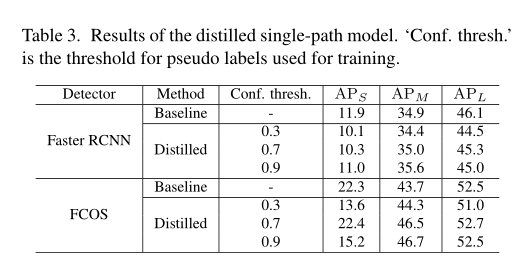
表 3 显示了结果。使用 Up@Test-scale,其中 Faster RCNN 的 α 为 2.0,FCOS 的 α 为 2.2,两者 γ 均为 3.0。可以看出,Faster RCNN 和 FCOS 的最佳模型在 APS 中分别达到了 11.0 和 22.4。它们与使用完整训练数据训练的基础检测器相当。值得注意的是,蒸馏后的检测器在中型和大型实例(即 APM 和 APL)上的精度没有下降,即小型实例的标注并不像想象的那么重要。
总之,
对于较大尺寸的实例,我们质疑是否值得标注小尺寸对象实例。为了研究这个问题,我们将其重新表述为:我们能否使用不含小尺寸实例标注的训练数据训练出的检测器来检测小尺寸对象实例?
为了回答这个问题,我们考虑了两种方法,并使用 COCO 数据集实验性地评估了它们的性能。一种方法是在测试时放大图像,然后将它们输入到检测器中。另一种方法是在训练时缩小图像以创建合成的小尺寸实例,并使用它们训练检测器。我们预计第一种方法会因为训练和测试输入之间的领域差距而受到影响,因为放大的小尺寸实例将具有低图像分辨率。这种差距可能会影响检测器的性能。我们还考虑了一种扩展方法来应对这一问题,该方法使用模糊的中等和大型实例及其原始版本来训练检测器。
实验结果表明,第一种方法在检测性能上至少与使用全部训练数据训练的基础检测器相当。这回答了上述问题:我们可以使用未包含小尺寸实例的数据训练的检测器来检测小尺寸实例。该方法需要将检测器应用于同一张图像两次,并使用不同的缩放比例来检测所有大小的实例。我们已经证明,可以将模型精简为单路径检测器,我们可以在与基础检测器相同的方式使用它。这些结果表明,需要重新考虑小尺寸对象的标注对于目标检测的重要性。

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









