






一、在Microsoft Edge浏览器搜索相关图片并复制链接。
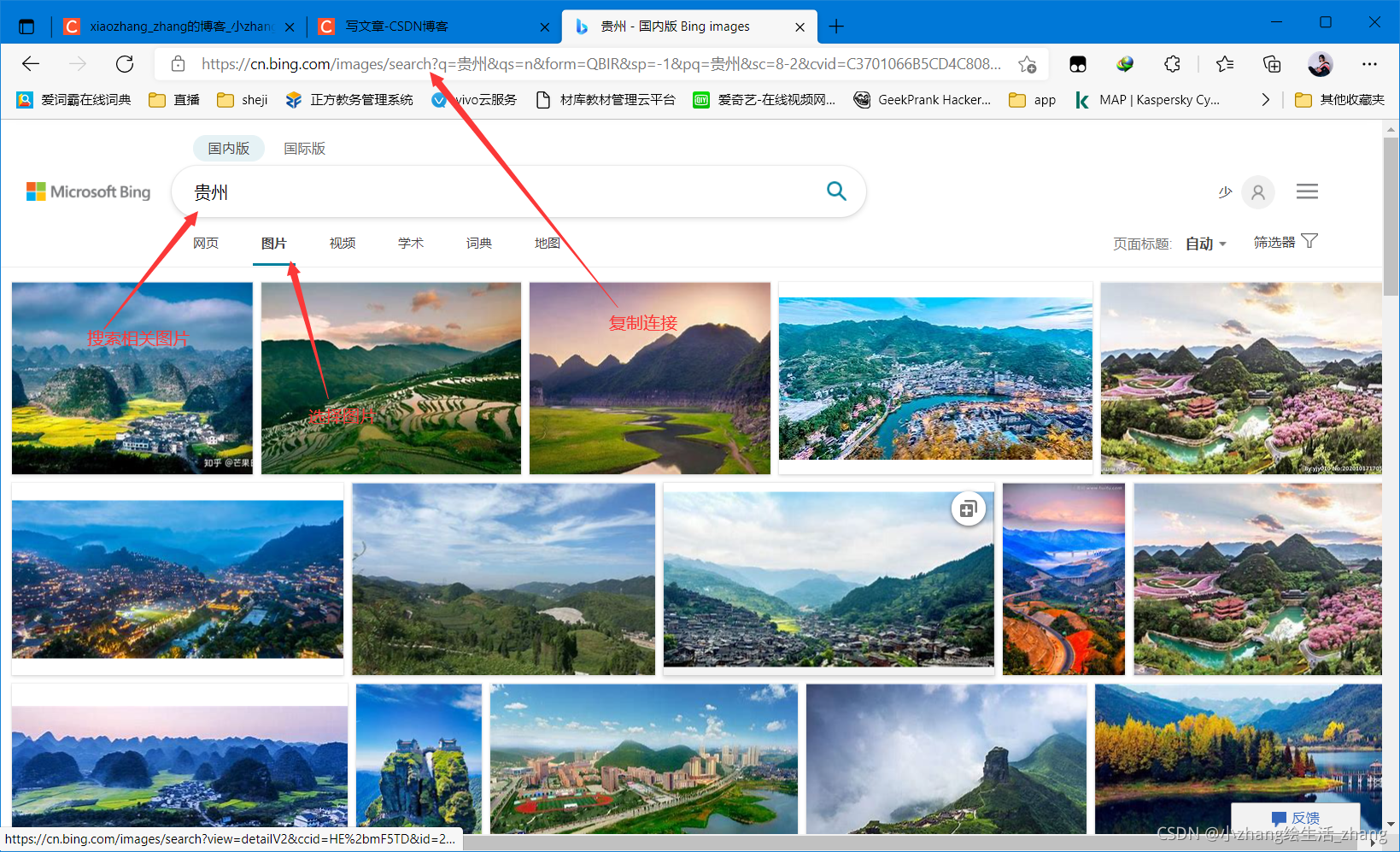
二、Python代码实现爬取图片。
import requests
import re
import os
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
def get_page(num):
img_list = []
for i in range((num // 35) + 1):
url = f'https://cn.bing.com/images/search?q=%E5%87%AF%E9%87%8C%E5%AD%A6%E9%99%A2&qs=n&form=QBILPG&sp=-1&pq=%E5%87%AF%E9%87%8C%E5%AD%A6%E9%99%A2&sc=8-4&cvid=E88DDF7F2D4A4C4C8A90BB07F22A3EBB&first=1&tsc=ImageBasicHover'
r = requests.get(url, headers=headers)#刚才复制的链接地址
html = r.text
html = etree.HTML(html)
conda_list = html.xpath('//a[@class="iusc"]/@m')
for j in conda_list:
pattern = re.compile(r'"murl":"(.*?)"')
img_url = re.findall(pattern, j)[0]
img_list.append(img_url)
return img_list
def download(path, img_list):
for i in range(len(img_list)):
img_url = img_list[i]
print(f'正在爬取: {img_url}')
img_floder = 'F:/xiangce/'+keyword #爬取图片存放的位置并命名
if not os.path.exists(img_floder):
os.makedirs(img_floder)
try:
with open(f'{img_floder}/{i}.jpg', 'wb') as f:
img_content = requests.get(img_url).content
f.write(img_content)
except:
continue
if __name__ == '__main__':
num = 100
keyword = '贵州' #文件名
path = 'F:/xiangce/' #存放位置
img_list = get_page(num)
download(path, img_list)
正在爬取图片
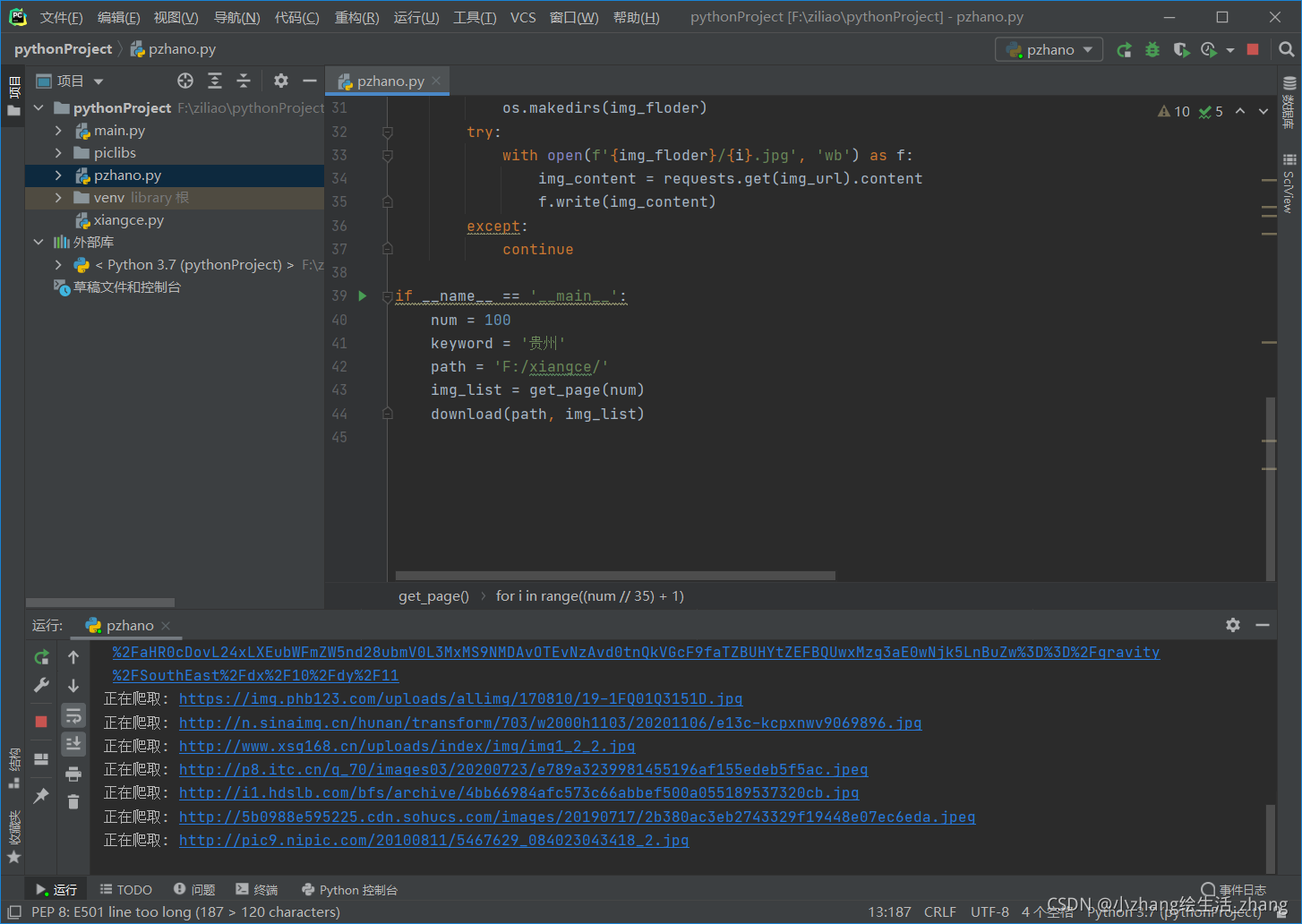
查看结果
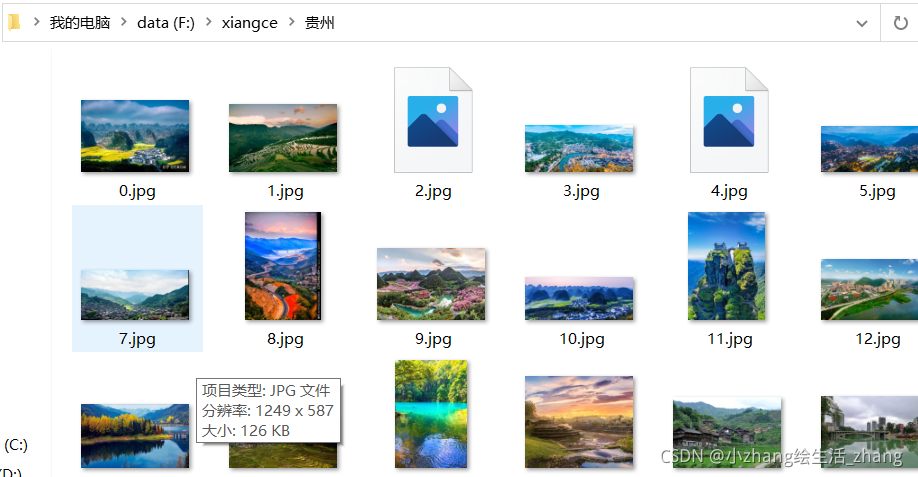
ok















 8222
8222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









