






发晚啦发晚啦,这次用深度学习方案优化之前的电力需求预测,难顶的是之前的BML CodeLab不支持tensorflow,所以这回直接在python上跑了
1、配置环境
准备工作与环境搭建
Datawhale官方有提供详细的速通文档:从零入门机器学习竞赛
按照上述文档可以速通baseline。只要会点运行就可以!
Step 1:下载相关库和导入
pip install numpy
pip install kera
pip install tensorflow
pip install pandas
pip install scikit-learnimport numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, RepeatVector, TimeDistributed
from keras.optimizers import AdamStep 2:导入赛题数据
下载赛题数据给出的训练集和测试集
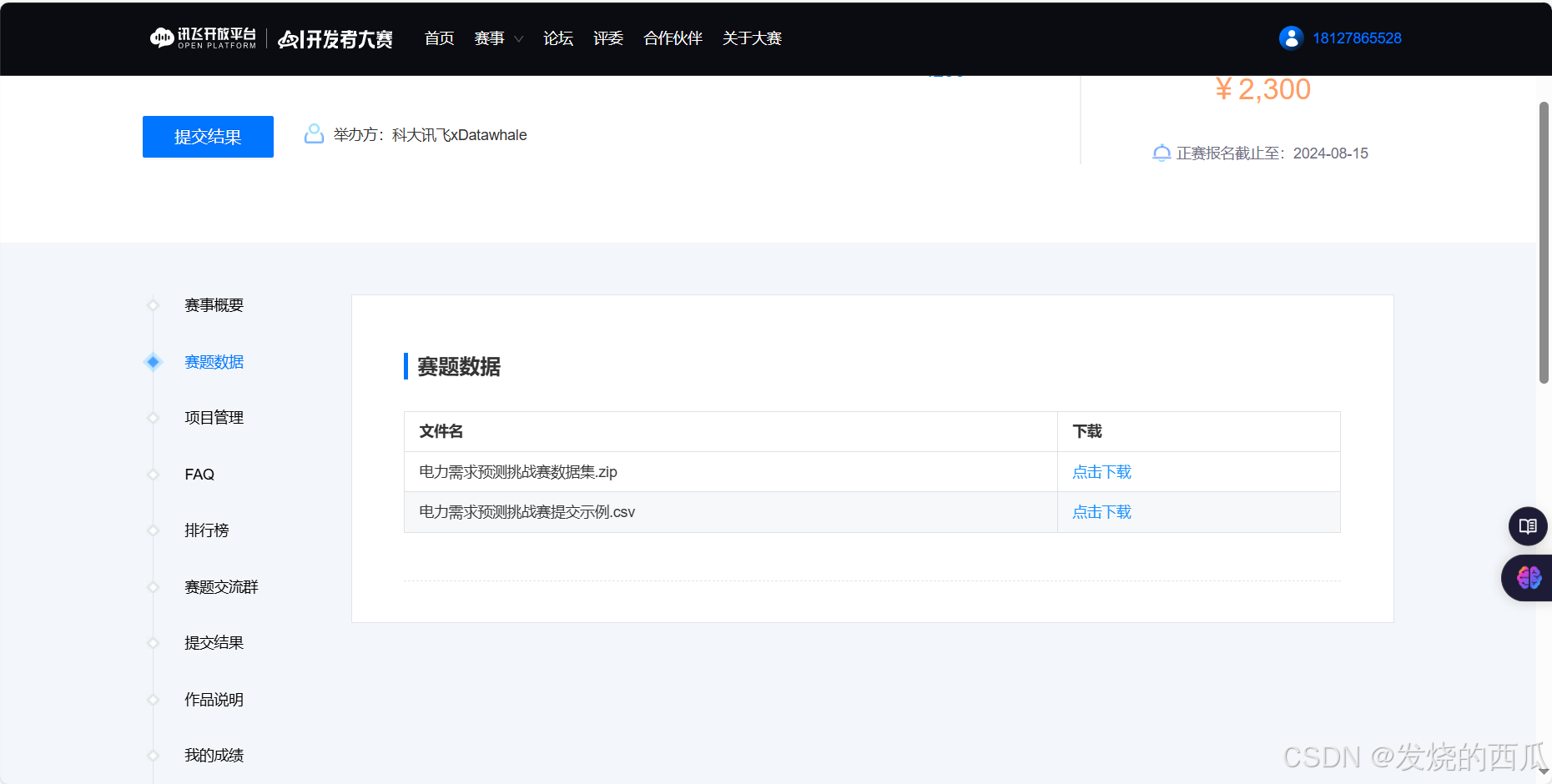
下完之后直接放运行的根目录就行
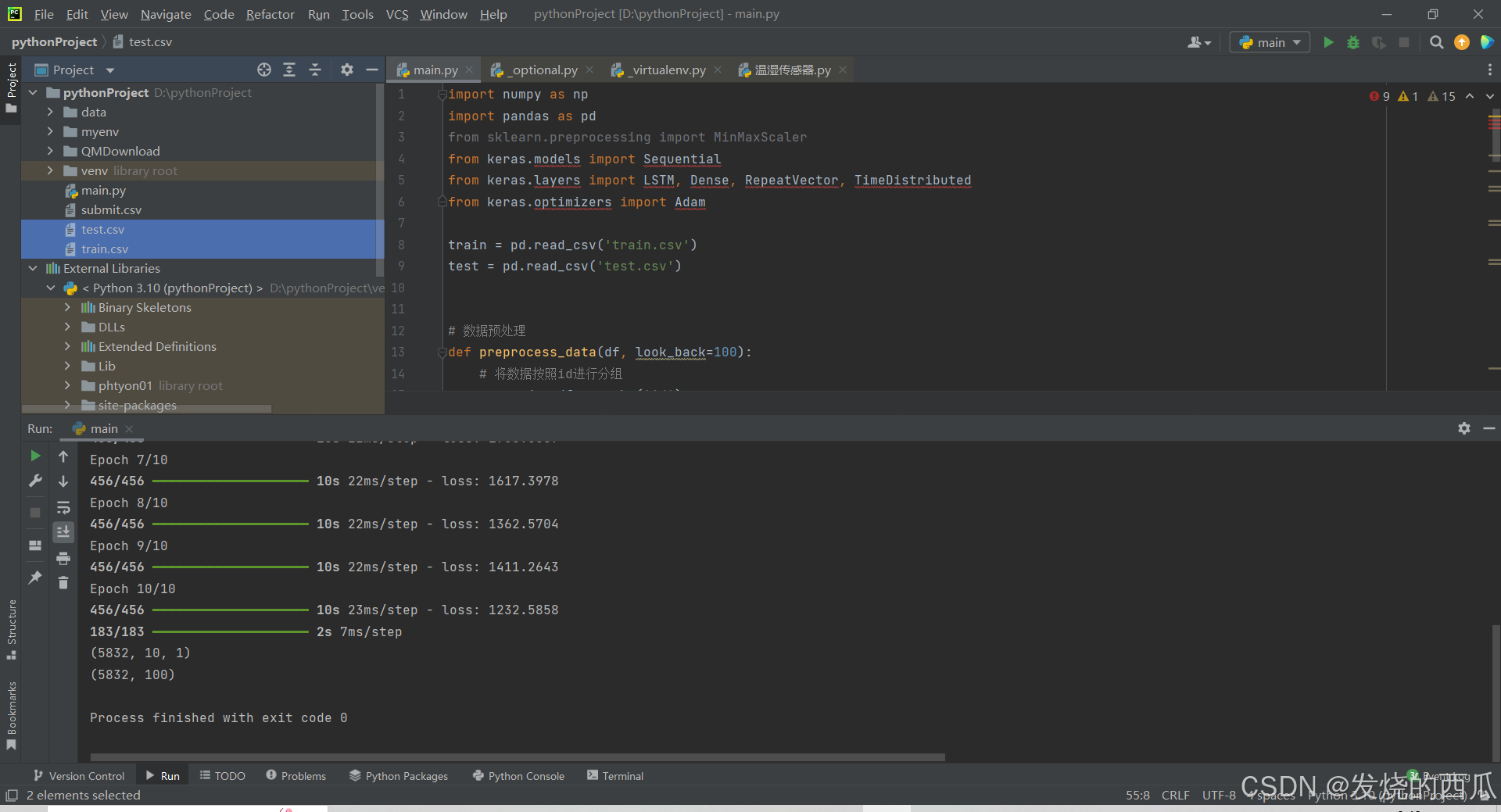
Step 3:运行深度学习尝试方案
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, RepeatVector, TimeDistributed
from keras.optimizers import Adam
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# 数据预处理
def preprocess_data(df, look_back=100):
# 将数据按照id进行分组
grouped = df.groupby('id')
datasets = {}
for id, group in grouped:
datasets[id] = group.values
# 准备训练数据集
X, Y = [], []
for id, data in datasets.items():
for i in range(10, 15): # 每个id构建5个序列
a = data[i:(i + look_back), 3]
a = np.append(a, np.array([0]*(100-len(a))))
X.append(a[::-1])
Y.append(data[i-10:i, 3][::-1])
# 准备测试数据集
OOT = []
for id, data in datasets.items():
a = data[:100, 3]
a = np.append(a, np.array([0]*(100-len(a))))
OOT.append(a[::-1])
return np.array(X, dtype=np.float64), np.array(Y, dtype=np.float64), np.array(OOT, dtype=np.float64)
# 定义模型
def build_model(look_back, n_features, n_output):
model = Sequential()
model.add(LSTM(50, input_shape=(look_back, n_features)))
model.add(RepeatVector(n_output))
model.add(LSTM(50, return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mean_squared_error', optimizer=Adam(0.001))
return model
# 构建和训练模型
look_back = 100 # 序列长度
n_features = 1 # 假设每个时间点只有一个特征
n_output = 10 # 预测未来10个时间单位的值
# 预处理数据
X, Y, OOT = preprocess_data(train, look_back=look_back)
# 构建模型
model = build_model(look_back, n_features, n_output)
# 训练模型
model.fit(X, Y, epochs=10, batch_size=64, verbose=1)
# 进行预测
predicted_values = model.predict(OOT)
print(predicted_values.shape)
print(OOT.shape)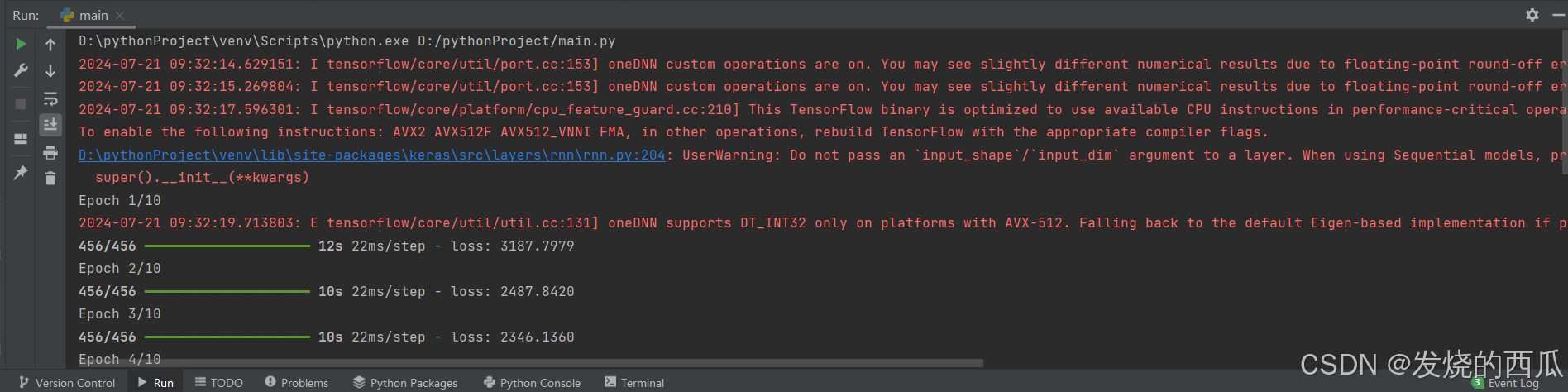
这些属于正常警告,等待运行完毕
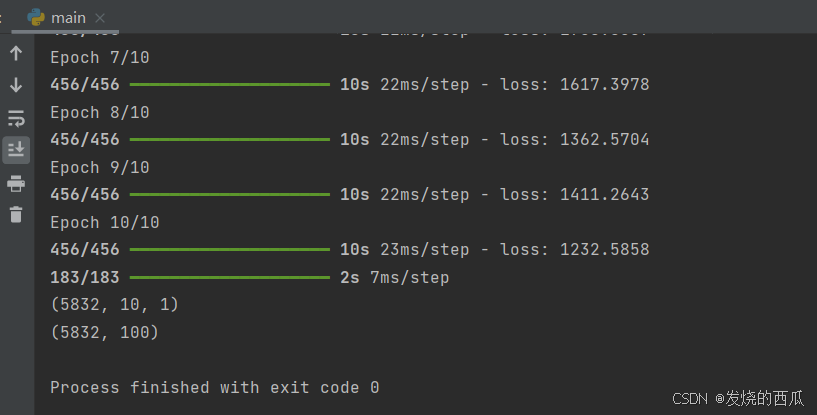
这个就是我们要的答案了。
step4:原理解析(这下面的代码就可以回去BML CodeLab跑了)
夏令营也给出了这次优化方案尝试一个比较详细的解析,它用了两个阶段做介绍和代码模拟:
特征优化
(1)历史平移特征:通过历史平移获取上个阶段的信息;
(2)差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
(3)窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
# 合并训练数据和测试数据
data = data.sort_values(['id','dt'], ascending=False).reset_index(drop=True)
# 历史平移
for i in range(10,36):
data[f'target_shift{i}'] = data.groupby('id')['target'].shift(i)
# 历史平移 + 差分特征
for i in range(1,4):
data[f'target_shift10_diff{i}'] = data.groupby('id')['target_shift10'].diff(i)
# 窗口统计
for win in [15,30,50,70]:
data[f'target_win{win}_mean'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').mean().values
data[f'target_win{win}_max'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').max().values
data[f'target_win{win}_min'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').min().values
data[f'target_win{win}_std'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').std().values
# 历史平移 + 窗口统计
for win in [7,14,28,35,50,70]:
data[f'target_shift10_win{win}_mean'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').mean().values
data[f'target_shift10_win{win}_max'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').max().values
data[f'target_shift10_win{win}_min'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').min().values
data[f'target_shift10_win{win}_sum'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').sum().values
data[f'target_shift710win{win}_std'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').std().values这里相比原来给出的代码少了一句“data = pd.concat([train, test], axis=0).reset_index(drop=True)”
原来的运行会提示“TypeError: cannot concatenate object of type '<class 'module'>'; only Series and DataFrame objs are valid”错误:
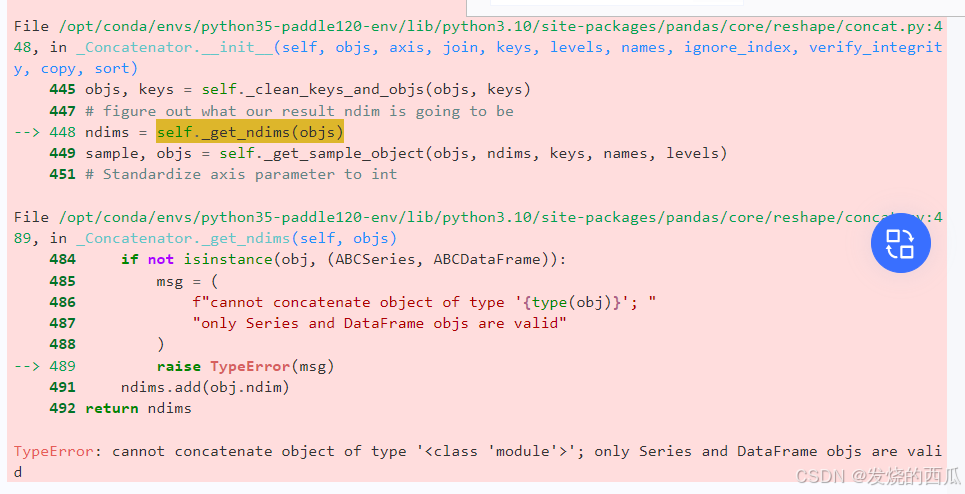
好像是因为这个 TypeError 错误通常发生在你尝试使用 pd.concat() 函数来合并数据时,但是其中一个参数被错误地设置为一个模块(module)对象,而不是 pandas 的 Series 或 DataFrame 对象。
在 Python 中,当你从某个库(如 pandas)导入一个模块时,你实际上是在引用该库中的一个子集或整个库本身。如果你不小心将整个模块作为参数传递给需要 Series 或 DataFrame 的函数,就会遇到这种类型的错误。 我比较省事就把它删了(
然后接着往下
模型融合
(1)加权平均融合
下面我们构建了cv_model函数,内部可以选择使用lightgbm、xgboost和catboost模型,可以依次跑完这三个模型,然后将三个模型的结果进行取平均进行融合。
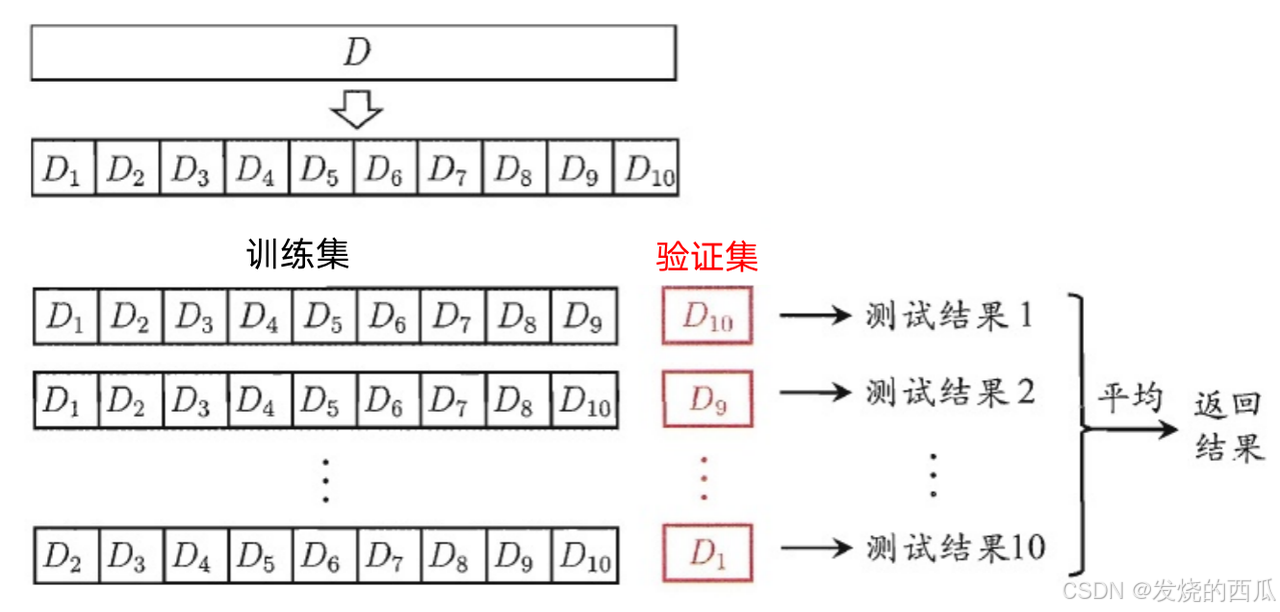
对于每个模型均选择经典的K折交叉验证方法进行离线评估,大体流程如下:
1、K折交叉验证会把样本数据随机的分成K份;
2、每次随机的选择K-1份作为训练集,剩下的1份做验证集;
3、当这一轮完成后,重新随机选择K-1份来训练数据;
4、最后将K折预测结果取平均作为最终提交结果。
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2024):
'''
clf:调用模型
train_x:训练数据
train_y:训练数据对应标签
test_x:测试数据
clf_name:选择使用模型名
seed:随机种子
'''
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
model = clf.train(params, train_matrix, 1000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=200, early_stopping_rounds=100)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
if clf_name == "xgb":
xgb_params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'eval_metric': 'mae',
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.1,
'tree_method': 'hist',
'seed': 520,
'nthread': 16
}
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(xgb_params, train_matrix, num_boost_round=1000, evals=watchlist, verbose_eval=200, early_stopping_rounds=100)
val_pred = model.predict(valid_matrix)
test_pred = model.predict(test_matrix)
if clf_name == "cat":
params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=1000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = mean_absolute_error(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
return oof, test_predict
# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train[train_cols], train['target'], test[train_cols], 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train[train_cols], train['target'], test[train_cols], 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostRegressor, train[train_cols], train['target'], test[train_cols], 'cat')
# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3(2)stacking融合
stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
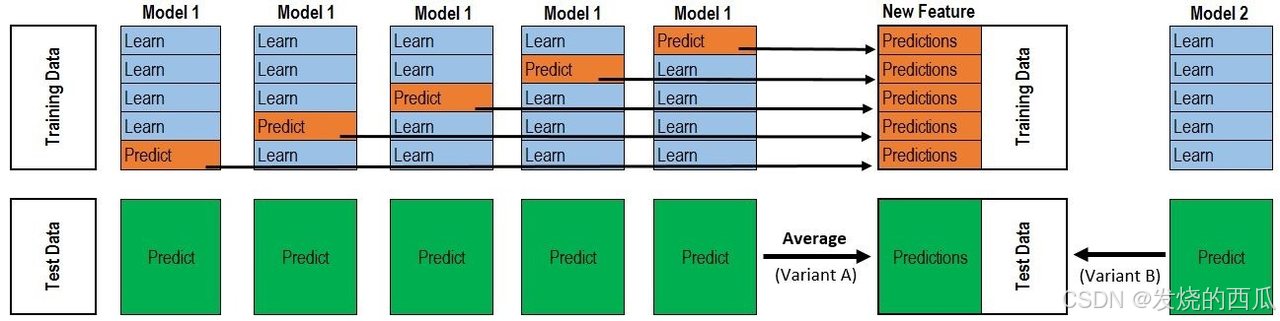
第一层:(类比cv_model函数)
-
划分训练数据为K折(5折为例,每次选择其中四份作为训练集,一份作为验证集);
-
针对各个模型RF、ET、GBDT、XGB,分别进行5次训练,每次训练保留一份样本用作训练时的验证,训练完成后分别对Validation set,Test set进行预测,对于Test set一个模型会对应5个预测结果,将这5个结果取平均;对于Validation set一个模型经过5次交叉验证后,所有验证集数据都含有一个标签。此步骤结束后:5个验证集(总数相当于训练集全部)在每个模型下分别有一个预测标签,每行数据共有4个标签(4个算法模型),测试集每行数据也拥有四个标签(4个模型分别预测得到的)
第二层:(类比stack_model函数)
-
将训练集中的四个标签外加真实标签当作五列新的特征作为新的训练集,选取一个训练模型,根据新的训练集进行训练,然后应用测试集的四个标签组成的测试集进行预测作为最终的result。
def stack_model(oof_1, oof_2, oof_3, predictions_1, predictions_2, predictions_3, y):
'''
输入的oof_1, oof_2, oof_3可以对应lgb_oof,xgb_oof,cat_oof
predictions_1, predictions_2, predictions_3对应lgb_test,xgb_test,cat_test
'''
train_stack = pd.concat([oof_1, oof_2, oof_3], axis=1) # (len(train),3)
test_stack = pd.concat([predictions_1, predictions_2, predictions_3], axis=1) #(len(test),3)
oof = np.zeros((train_stack.shape[0],))
predictions = np.zeros((test_stack.shape[0],))
scores = []
from sklearn.model_selection import RepeatedKFold
folds = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2021)
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_stack, train_stack)):
print("fold n°{}".format(fold_+1))
trn_data, trn_y = train_stack.loc[trn_idx], y[trn_idx]
val_data, val_y = train_stack.loc[val_idx], y[val_idx]
clf = Ridge(random_state=2021)
clf.fit(trn_data, trn_y)
oof[val_idx] = clf.predict(val_data)
predictions += clf.predict(test_stack) / (5 * 2)
score_single = mean_absolute_error(val_y, oof[val_idx])
scores.append(score_single)
print(f'{fold_+1}/{5}', score_single)
print('mean: ',np.mean(scores))
return oof, predictions
stack_oof, stack_pred = stack_model(pd.DataFrame(lgb_oof), pd.DataFrame(xgb_oof), pd.DataFrame(cat_oof),
pd.DataFrame(lgb_test), pd.DataFrame(xgb_test), pd.DataFrame(cat_test), train['target'])复盘总结(结合时间序列预测技术发展趋势)
1. 背景与目标回顾
在解决特定时间序列预测任务的过程中,我们成功地在PC端Python环境中部署并应用了深度学习模型,特别是LSTM或其变体,以验证其在时间序列预测中的效能。此过程不仅验证了技术的可行性,也为后续更深入的探索奠定了基础。
2. 当前成果与挑战
- 成果:通过LSTM等深度学习模型,我们实现了对时间序列数据的有效预测,验证了模型在处理复杂时间序列数据方面的优势。
- 挑战:尽管取得了初步成果,但在实际应用中仍面临模型复杂度、数据多样性、模型解释性、实时预测能力等方面的挑战。
3. 未来技术展望与研究方向
结合时间序列预测领域的最新发展趋势,我们可以预见以下研究方向和潜在的技术革新:
- 更复杂的模型结构:未来的研究将探索引入注意力机制等先进技术的LSTM变体,以进一步提升模型捕捉时间序列中长期依赖关系的能力。
- 多模态数据融合:随着数据类型的多样化,如何有效融合时间序列数据与其他类型的数据(如文本、图像)将成为研究热点,以提供更全面、深入的洞察。
- 模型解释性增强:提高深度学习模型的可解释性,使预测结果更加透明、易于理解,将是未来研究的重要方向之一。
- 自动化特征工程:为了减少手动特征提取的繁琐和主观性,开发高效的自动化特征工程工具将大大提高模型构建的效率和质量。
- 实时预测系统:针对实时数据流,开发能够快速响应并准确预测的模型和系统,将极大拓展时间序列预测的应用场景。
- 模型鲁棒性优化:面对实际数据中的异常值和噪声,提高模型的鲁棒性和抗干扰能力,将是保障预测准确性的关键。
4. 未来规划与实践
基于上述展望,我们计划在未来的工作中:
- 持续跟踪最新研究:密切关注时间序列预测领域的最新研究成果和技术动态,及时将新理论、新方法应用于实践。
- 深化模型优化:尝试引入注意力机制等先进技术,优化模型结构,提升预测性能。
- 探索多模态融合:研究如何将时间序列数据与其他类型数据有效融合,以应对更复杂、多样的预测任务。
- 加强模型解释性:通过可视化、特征重要性分析等手段,提高模型的可解释性,增强预测结果的可信度。
- 推进自动化特征工程:开发或采用成熟的自动化特征工程工具,简化模型构建流程,提高工作效率。
- 构建实时预测系统:探索实时数据处理和预测技术,构建能够应对快速变化数据流的实时预测系统。
通过不断的技术革新和实践探索,我们期待在时间序列预测领域取得更加显著的成果,为各行各业提供更加精准、高效的预测服务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









