









Tesseract介绍
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel Project上。
需要提前安装java运行环境。
1.引入tess4j.jar包
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.4.0</version>
</dependency>
2.代码案例
public void OCR1(){
File imageFile = new File("C:\\1.png");
ITesseract instance = new Tesseract(); // JNA Interface Mapping
//如果采用的不是使用包默认的testdata建议加上一下一行代码:
// instance.setDatapath("D:\\soft\\OCR\\Tesseract-OCR\\tessdata");
// ITesseract instance = new Tesseract1(); // JNA Direct Mapp
instance.setLanguage("chi_sim");//添加中文字库
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
long startTime = System.currentTimeMillis();
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) + " 毫秒");
} catch (TesseractException e) {
e.printStackTrace();
}
}
3.图片效果

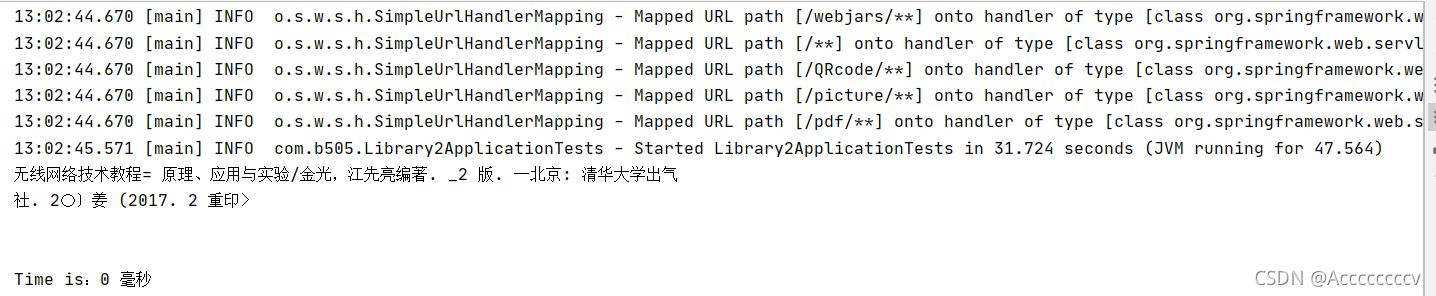
识别准确率不是很高,需要针对场景自行训练字库
注意:
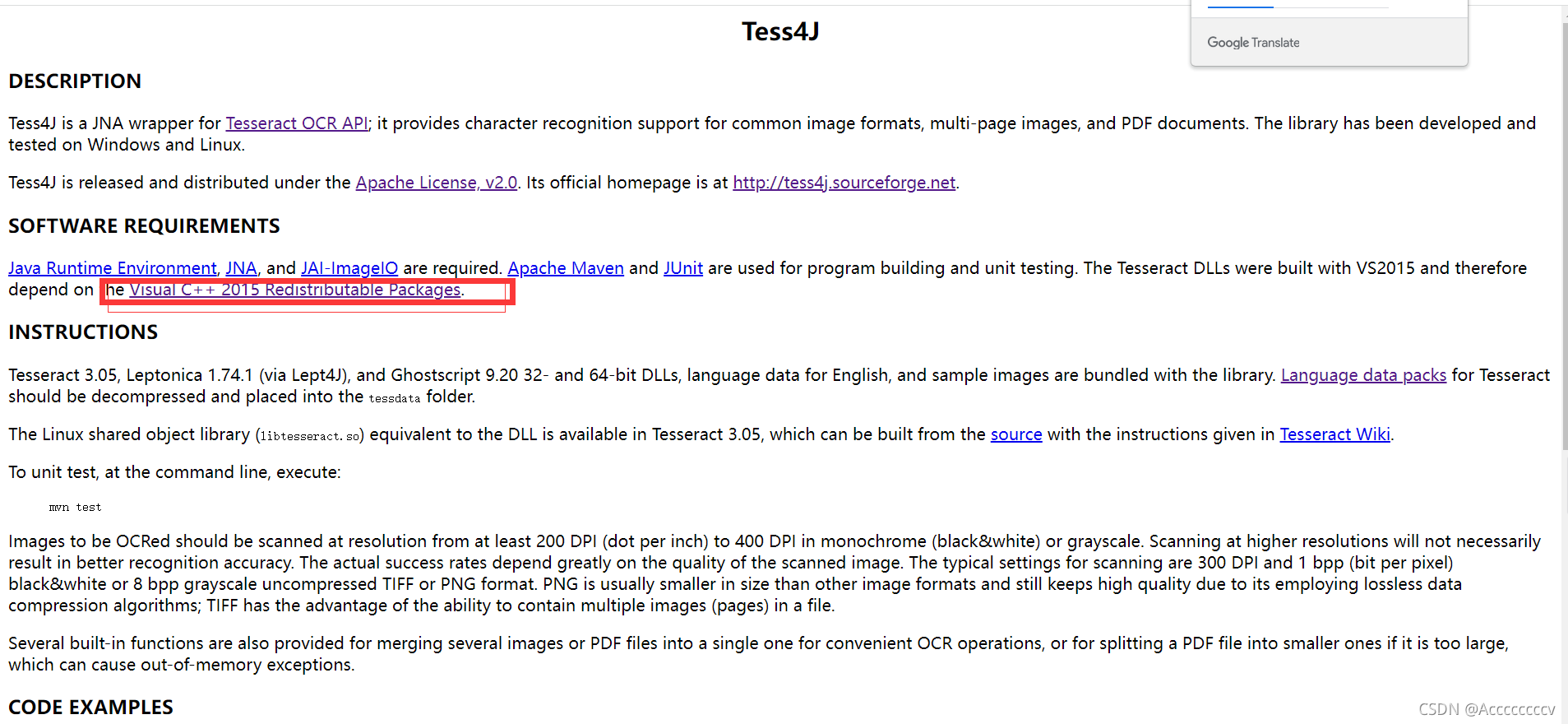
Java Runtime Environment, JNA, and JAI-ImageIO are required. Apache Maven and JUnit are used for program building and unit testing. The Tesseract DLLs were built with VS2015 and therefore depend on the Visual C++ 2015 Redistributable Packages.
需要 Java 运行时环境、 JNA和JAI-ImageIO 。Apache Maven和 JUnit用于程序构建和单元测试。Tesseract DLL 是用 VS2015 构建的,因此依赖于 Visual C++ 2015 Redistributable Packages。
编译jar包时如果报错则需要安装Visual C++ 2015 Redistributable Packages。不同版本的jar包根据具体的安装链接库。可以将jar解压查看其中的readme.html文件
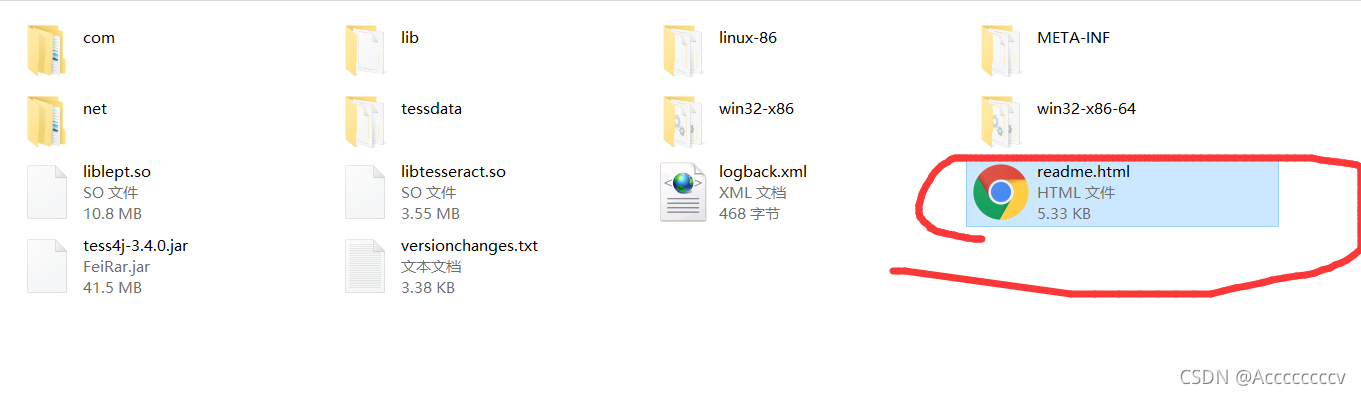
Microsoft Visual C++ 2013 Redistributable安装地址:https://download.csdn.net/download/weixin_47142014/25898225?spm=1001.2014.3001.5503
Visual C++ 2015 Redistributable Packages安装地址:https://download.csdn.net/download/weixin_47142014/25897406?spm=1001.2014.3001.5503



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











