







连接查询的本质
新建两张表
CREATE TABLE e1 (m1 int, n1 char(1)); CREATE TABLE e2 (m2 int, n2 char(1)); INSERT INTO e1 VALUES(1, 'a'), (2, 'b'), (3, 'c'); INSERT INTO e2 VALUES(2, 'b'), (3, 'c'), (4, 'd');
连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。
连接内部实现
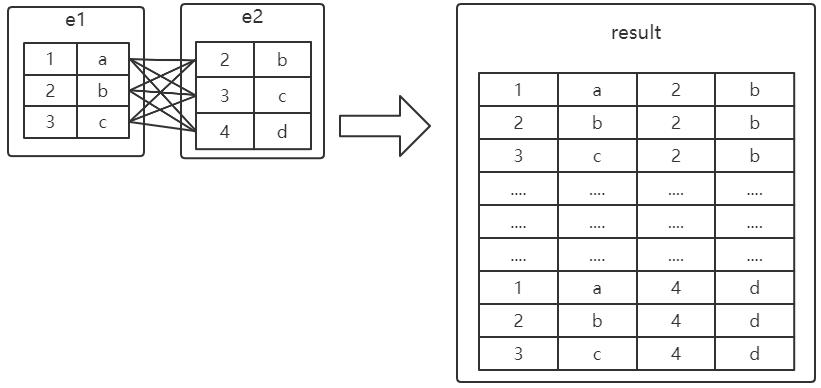
这个过程看起来就是把e1表的记录和e2的记录连起来组成新的更大的记录, 所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条 记录与另一个表中的每一条记录相互匹配的组合,像这样的结果集就可以称之为 笛卡尔积。因为表 e1 中有 3 条记录,表 e2 中也有 3 条记录,所以这两个表连接之后的笛卡尔积就有 3×3=9 行记录。
连接的简单语法
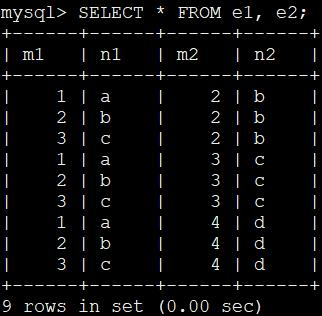
在 MySQL 中,连接查询的语法很随意,只要在 FROM 语句后边跟多个表名就好了,比如我们把 e1 表和 e2 表连接起来的查询语句可以写成这样:
SELECT * FROM e1, e2;
连接流程简介
为什么尽量少的关联表
在最早学习的时候,往往大家为了表明自己"深厚"的优化功底,常常使用一个超多表的关联查询。有的常常关联了7,8张表和朋友们炫耀。但随着深度学习Mysql后,我们发现好像和我们最开始想的不太一样。
我们知道《阿里巴巴JAVA开发手册》里面有这么一个声明:超过三张表禁止join。那么join如此方便的join为什么如此不受阿里大佬的待见呢?
我们可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接 起来产生的笛卡尔积可能是非常巨大的。比方说 3 个 100 行记录的表连接起来产 生的笛卡尔积就有 100×100×100=1000000 行数据!所以在连接的时候过滤掉特定记录组合是有必要的
Sql分析
SELECT * FROM e1, e2 WHERE e1.m1 > 1 AND e1.m1 = e2.m2 AND e2.n2 < 'd';
单表条件筛选
e1.m1 > 1 是只针对 e1 表的过滤条件,e2.n2 < 'd'是只针对 e2 表的过滤条件。
多表条件筛选
e1.m1 = e2.m2、e1.n1 > e2.n2 等,这些条件中涉及到了两个表。
Sql中的筛选条件分析
- e1.m1 > 1
- e1.m1 = e2.m2
- e2.n2 < 'd
那么这个连接查询的大致执行过程如下:
步骤1:选择驱动表
我们可以看到,关联查询假设有A,B两种表,那么实际上就是先单独筛选其中一张表,再使用该表的结果作为条件,去另一张表中进行查询。
那么,我们思考一下,假设我们是优化器,我们会选择过滤后的结果更简单的表作为驱动表,还是过滤后结果更为复杂的表作为驱动表呢?
答案是肯定的,当然是选择结果简单的表。这样当我们的驱动表过滤的条件,就会更少的去作为被驱动表的条件,去执行下一次查询。
那么我们现在做出假设:
- e1.m1 > 1的条件有2条数据
- e2.n2 < 'd的条件有5条数据
那么优化器会选择哪条表作为驱动表呢?自然是e1。
步骤2:拿驱动表的结果条件去被驱动表中查询
此时,e1会取出自己已经筛查好的两个m1(假设第一个m1=2,第二个m1=3),作为等值条件再去e2表中进行查询。也就是e2表紧接着会执行以下sql:
SELECT * FROM e2 WHERE e2.m2 = 2 AND e2.n2 < 'd'; SELECT * FROM e2 WHERE e2.m2 = 3 AND e2.n2 < 'd';
这样更说明了我们说的驱动表要选择过了的条件尽量少的表。因为被驱动表的查询次数完全就指着这哥们儿的过滤后的结果数目了。
执行流程图
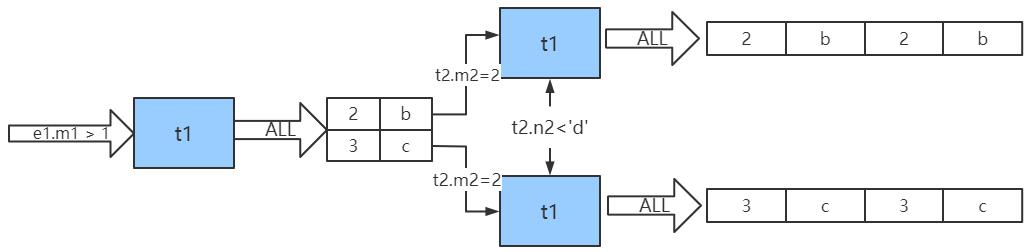
也就是说整个连接查询最后的结果只有两条符合过滤条件的记录。
结论
从上边两个步骤可以看出来,这个两表连接查询共需要查询 1 次 e1 表,2 次 e2 表。也就是说在两表连接查询中,驱动表只需要访问一次,被驱动表可能被访问多次。
基于我们对IO成本了解,选择结果集较小的表作为驱动表,可以有效的减少被驱动表的IO次数。这也就是优化器为什么要尽量让外连接转换为内连接的原因。(可以自行判断驱动表与被驱动表)
内连接与外链接
建表
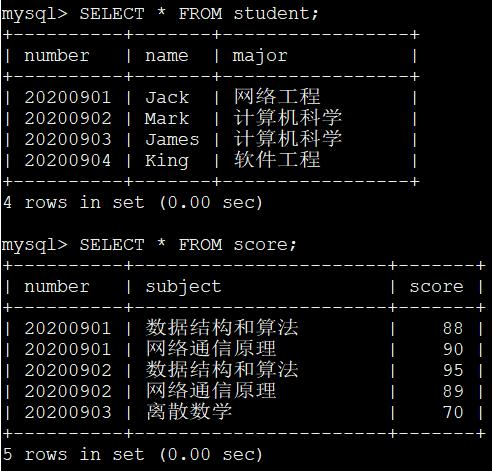
CREATE TABLE student ( number INT NOT NULL AUTO_INCREMENT COMMENT '学号', name VARCHAR(5) COMMENT '姓名', major VARCHAR(30) COMMENT '专业', PRIMARY KEY (number) ) Engine=InnoDB CHARSET=utf8 COMMENT '客户信息表';
CREATE TABLE score ( number INT COMMENT '学号', subject VARCHAR(30) COMMENT '科目', score TINYINT COMMENT '成绩', PRIMARY KEY (number, subject) ) Engine=InnoDB CHARSET=utf8 COMMENT '客户成绩表';
单表查询显示
SELECT * FROM student; SELECT * FROM score;
内连接
现在我们想把每个学生的考试成绩都查询出来就需要进行两表连接了(因为 score 中没有姓名信息,所以不能单纯只查询 score 表)。连接过程就是从 student 表中取出记录,在 score 表中查找 number 相同的成绩记录,所以过滤条件就是 student.number = socre.number,整个查询语句就是这样:
SELECT s1.number, s1.name, s2.subject, s2.score FROM student AS s1, score AS s2 WHERE s1.number = s2.number;

内连接本质以为带来的问题
从上述查询结果中我们可以看到,各个同学对应的各科成绩就都被查出来了,可是有个问题,King 同学,也就是学号为 20200904 的同学因为某些原因没有参加考试,所以在 score 表中没有对应的成绩记录。
因此,内连接的本质实际上是:
对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集。
如何补足内连接缺陷
如果老师想查看所有同学的考试成绩,即使是缺考的同学也应该展示出来, 但是到目前为止我们介绍的连接查询是无法完成这样的需求的。
为了解决这个问题,就有了内连接和外连接的概念。
外链接
相比于内连接的局限而言,外链接的定义是:
对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录, 也仍然需要加入到结果集。
在 MySQL 中,根据选取驱动表的不同,外连接仍然可以细分为 2 种:
- 左外连接,选取左侧的表为驱动表。
- 右外连接,选取右侧的表为驱动表。
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。 这就犯难了,怎么办?把过滤条件分为两种就可以就解决这个问题了,所以放在不同地方的过滤条件是有不同语义的:
WHERE 子句语义(查询条件)
WHERE 子句中的过滤条件就是我们平时见的那种。
不论是内连接还是外连接,凡是不符合 WHERE 子句中的过滤条件的记录都不会被加入最后的结果集。
ON 子句语义(连接条件)
ON 子句是专门为外连接驱动表中的记录,在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的。,
当外链接使用 ON进行关联查询时,ON 后的条件作为连接条件。若被驱动表中成功匹配到了驱动表的数据,则以驱动表,被驱动表一对一,或一对多的情况拼凑数据。若是匹配不失败,则生成一条包含所有驱动表数据,被驱动表数据全部为NULL的查询结果。
连接语法
对于外链接而言,驱动表和被驱动表都由我们自己决定。
左(外)连接的语法
SELECT * FROM e1 LEFT [OUTER] JOIN e2 ON 连接条件 [WHERE 普通过滤条件];
括号中的OUTER可以省略。上面e1就是我们的驱动表,e2是我们的被驱动表。
右(外)连接的语法
SELECT * FROM e1 RIGHT [OUTER] JOIN e2 ON 连接条件 [WHERE 普通过滤条件];
括号中的OUTER可以省略。上面e2就是我们的驱动表,e1是我们的被驱动表。
内连接的语法
SELECT * FROM e1 JOIN e2; SELECT * FROM e1 INNER JOIN e2; SELECT * FROM e1 CROSS JOIN e2; SELECT * FROM e1, e2;
内连接中 ON 子句和 WHERE 子句是等价的,所以内连接中不要求强制写明 ON 子句。
内连接外链接的驱动表和被驱动表
连接的本质就是把各个连接表中的记录都取出来依次匹配的 组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。
而对于内连接来说,由于凡是不符合 ON 子句或 WHERE 子句 中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。
对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合 ON 子句条件的记录时也要将其加入到结果集,所以此时驱动表和被驱动表的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。
嵌套循环连接(Nested-Loop Join)
普通嵌套查询时间复杂度
对于两表连接来说,驱动表只会被访问一遍,但被驱动表却 要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。
对于内连接来说,选取哪个表为驱动表,对结果的条数都没关系。而外连接的驱动表是固定的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表 就是右边的那个表。
如果有 3 个表进行连接的话,那么首先两表连接得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表,可以用伪代码表示一下这个过程就是这样:
for each row in e1 { #此处表示遍历满足对 e1 单表查询结果集中的每一条 记录,N 条
for each row in e2 { #此处表示对于某条 e1 表的记录来说,遍历满足 对 e2 单表查询结果集中的每一条记录,M 条
for each row in t3 { #此处表示对于某条 e1 和 e2 表的记录组 合来说,对 t3 表进行单表查询,L 条
#最终结果
}
}
这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表 却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录 条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),这是最简单, 也是最笨拙的一种连接查询算法,时间复杂度是 O(N*M*L)。
使用索引加快连接速度
我们知道,关联查询的驱动表和被驱动表往往是一对多的关系。假设驱动表过滤出的条件,每条的去被驱动表中进行全表扫描查询,那速度绝对慢到超乎想象。
因此,在被驱动表中增加索引,可以极大地提高查询效率。
基于块的嵌套循环连接
被驱动表无索引的代价
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。
现实生活中的表成千上万条记录都是少的,几百万、几千万甚至几亿条记录的表到处都是。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。
而采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个 I/O 代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
无join buffer的连接流程
- 当被驱动表中的数据非常多且无索引时,关联查询的顺序是这样的:
- 取出一条驱动表结果放入内存
- 取出所有被驱动表结果,并与驱动表的这条结果对比
- 释放内存中的驱动表结果,并将下一条驱动表结果放入内存
- 循环执行上面步骤,直到驱动表中所有结果全部与被驱动表全部数据对比一次
我们发现,我们在无join buffer的情况下,驱动表有多少次结果,驱动表就需要与内存IO多少次。
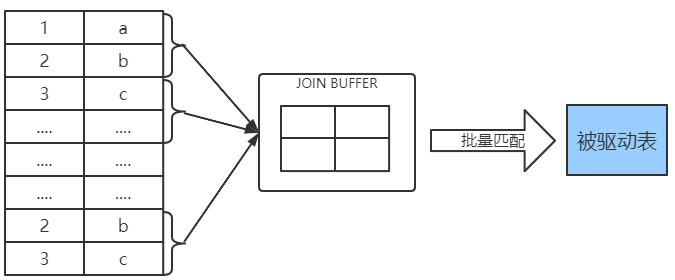
有join buffer的连接流程
因此提出了join buffer的概念:
join buffer 就是执行连接查询前申请 的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个 join buffer 中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和 join buffer 中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的 I/O 代价。
这个 join buffer 的大小是可以通过启动参数或者系统变量 join_buffer_size 进 行配置,默认大小为 262144 字节(也就是 256KB),最小可以设置为 128 字节。
show variables like 'join_buffer_size' ;
当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引, 如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大 join_buffer_size 的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到 join buffer 中, 只有查询列表中的列和过滤条件中的列才会被放到 join buffer 中,所以再次提醒 我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了, 这样还可以在 join buffer 中放置更多的记录。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











