







 超级会员免费看
超级会员免费看
 本文整理了2012年计算机统考408科目中的选择题和解答题,涉及后缀表达式计算、平衡二叉树、图的遍历、虚拟内存管理、IO接口、处理机调度等多个知识点,重点解析了边界对齐、小端存储、中断处理机制和虚拟内存的实际容量计算。
本文整理了2012年计算机统考408科目中的选择题和解答题,涉及后缀表达式计算、平衡二叉树、图的遍历、虚拟内存管理、IO接口、处理机调度等多个知识点,重点解析了边界对齐、小端存储、中断处理机制和虚拟内存的实际容量计算。
选择题
T2:后缀表达式(逆波兰表达式)—— 注意 操作数的顺序!
- 中缀转后缀

- 运算顺序不唯一,因此对应的后缀表达式也不唯一
- “左优先”原则:只要左边的运算符能先计算,就优先算左边的
- 用栈实现中缀表达式的计算
- 1、初始化两个栈,操作数栈和运算符栈
- 2、若扫描到操作数,压入操作数栈
- 3、若扫描到运算符或界限符,则按照“中缀转后缀”相同的逻辑压入运算符栈(期间也会弹出运算符,每当弹出一个运算符时,就需要再弹出两个操作数栈的栈顶元素并执行相应运算,运算结果再压回操作数栈)
- 后缀求值
- 后缀表达式的手算方法
- 从左往右扫描,每遇到一个运算符,就让运算符前面最近的两个操作数执行对应运算,合体为一个操作数。注意:两个操作数的左右顺序。
- 后缀表达式用栈实现计算
- 后缀表达式的手算方法

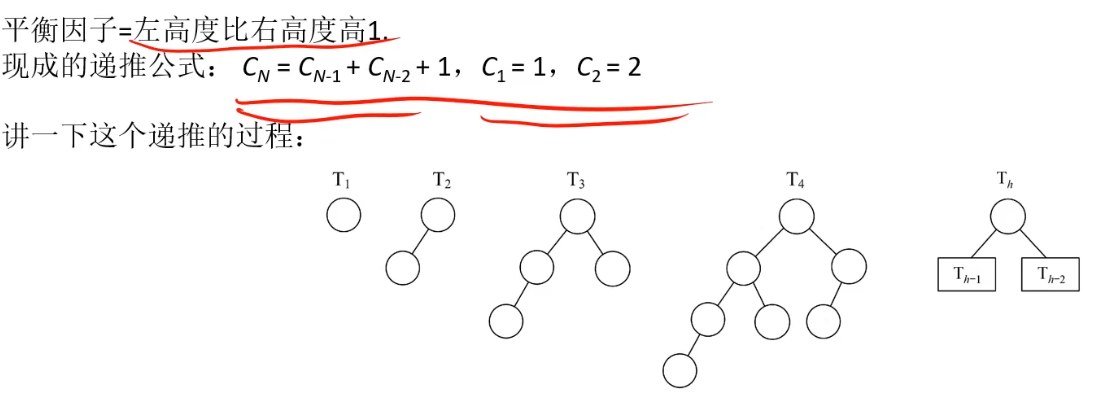
T4:平衡二叉树
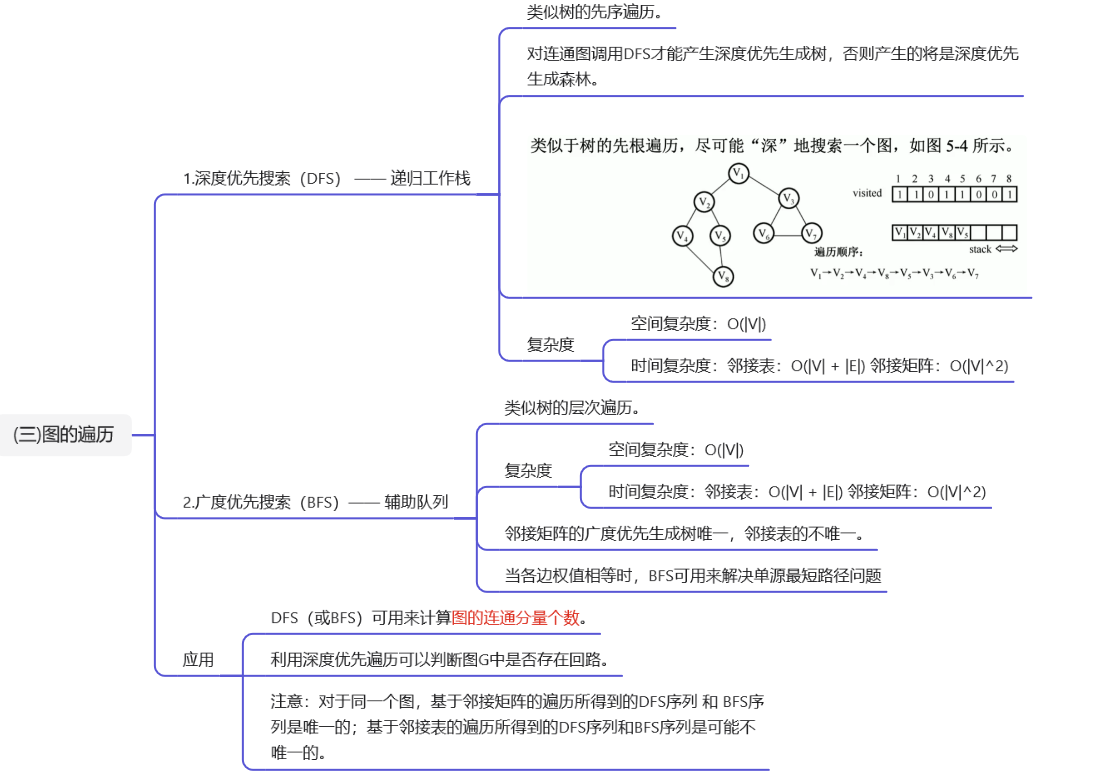
T5:图的遍历
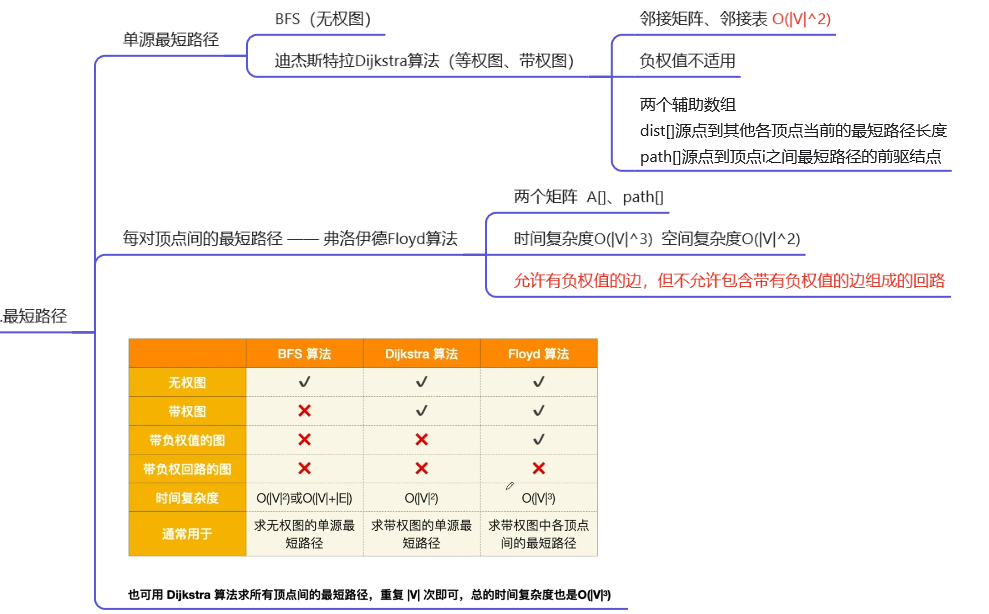
T7:迪杰斯特拉算法 —— 最短路径

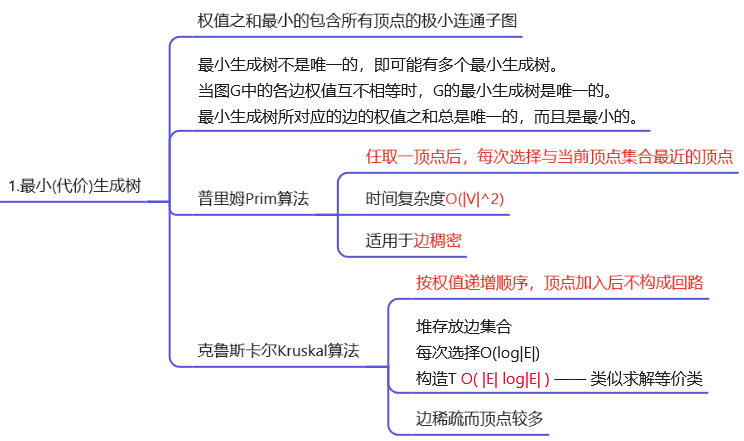
T8:最小生成树 —— 注意环
T12:速度提高。提高。不是提高了。

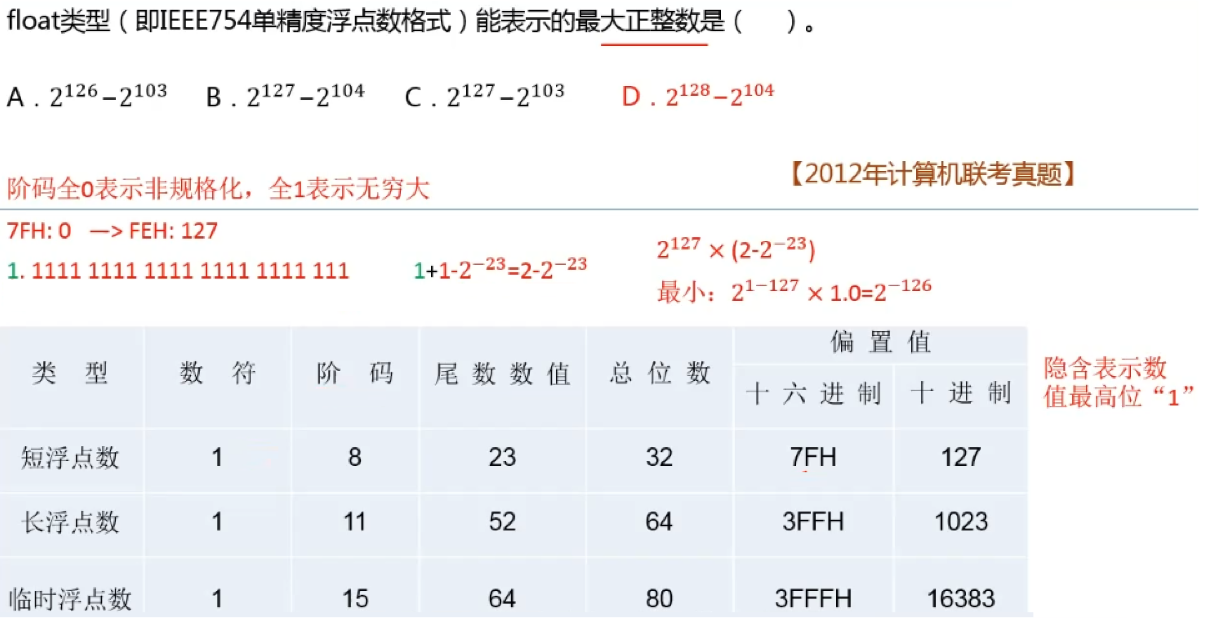
T14:IEEE754
T15:边界对齐、小端存储
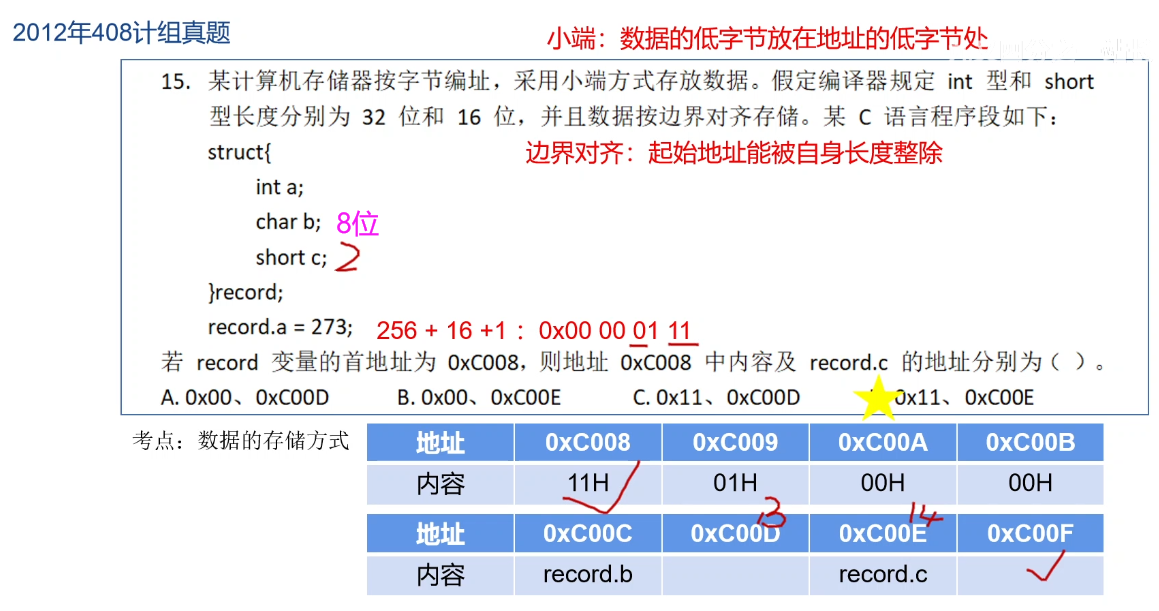
注意这里的十六进制表示。直接写成16进制!int 32b就对应 8个16进制位!
边界对齐:起始地址能被自身长度整除。
b为char类型,8位,占用一个存储单元,存放在 C00C中。
存放C时,由于C为16位,占用2个存储单元,而下一个地址 C00D 不能整除 2,故空出一个,往后。
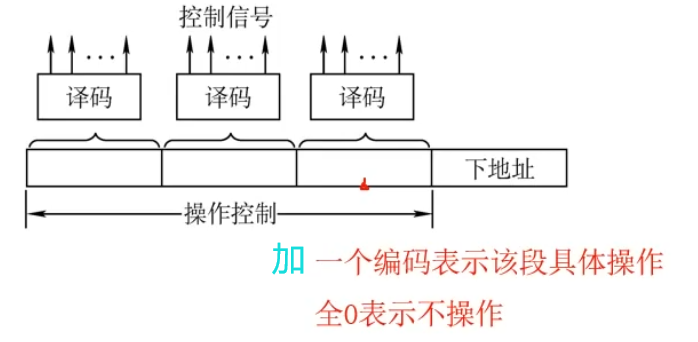
T18:微程序控制
T21:IO接口
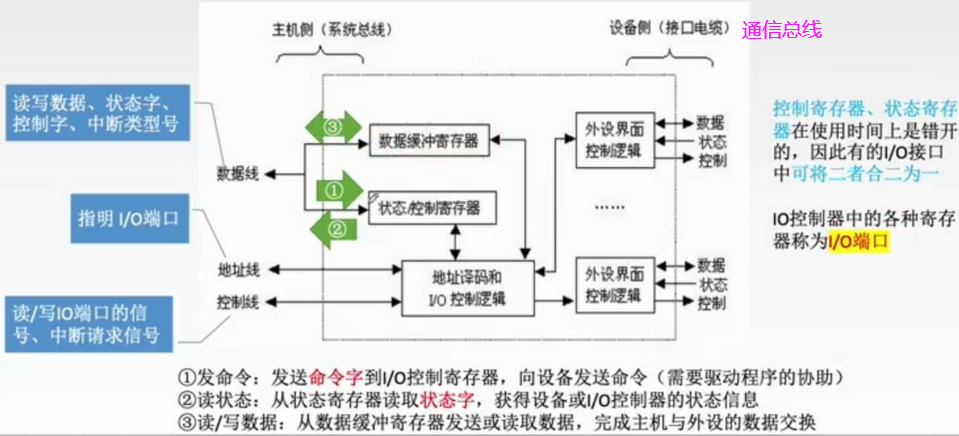
- 硬件向量法识别中断源(向量中断、80x86采用)
- 中断类型号(向量地址):中断服务程序的入口地址的地址。指针的指针,对应一个中断服务程序
- 中断向量表(入口地址):中断服务程序的入口地址
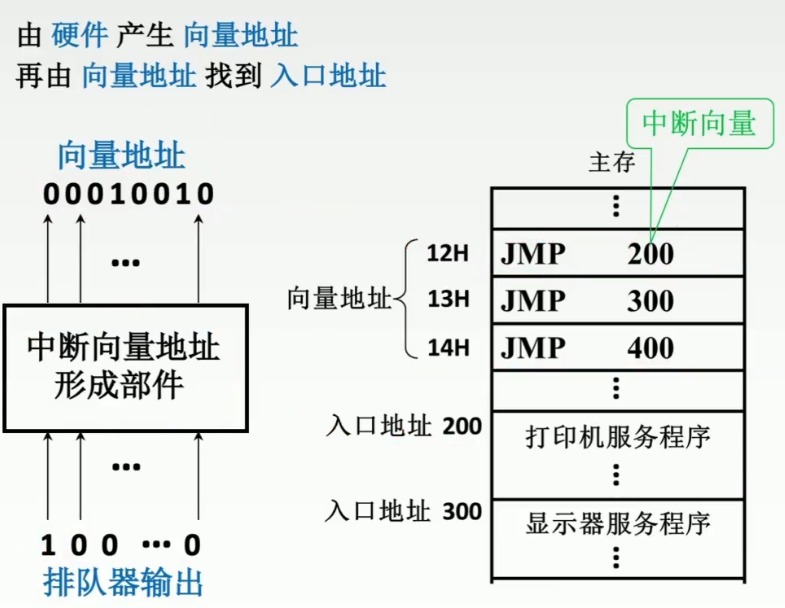
- 中断类型号用于指出中断向量的地址,CPU响应中断请求后,将中断应答信号INTR 发回到数据总线上,CPU从数据总线上读取中断类型号后,查找中断向量表,找到相应中断处理程序的入口
T25:虚拟内存管理
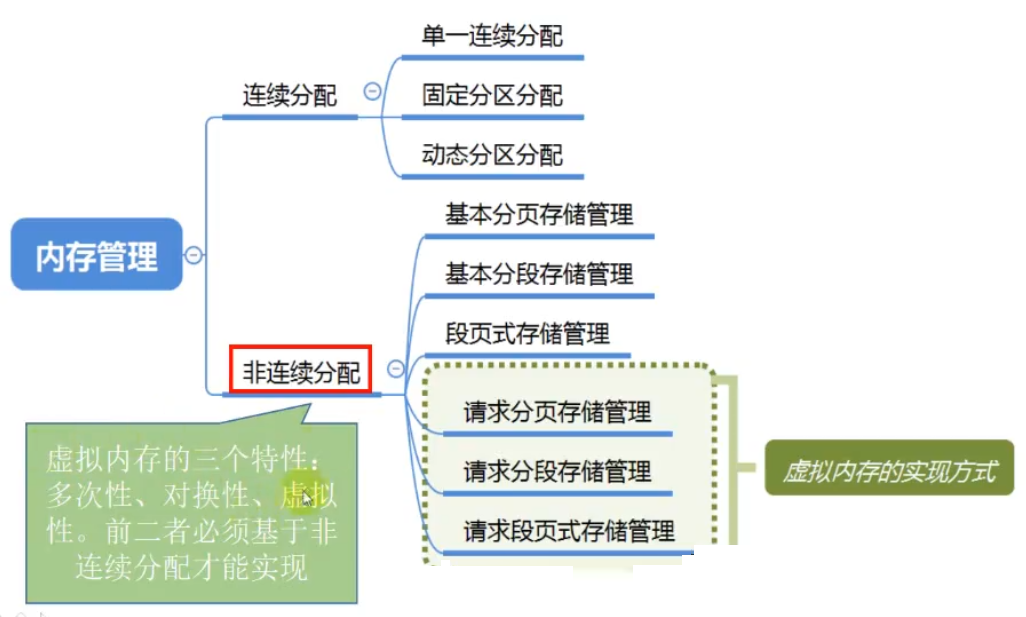
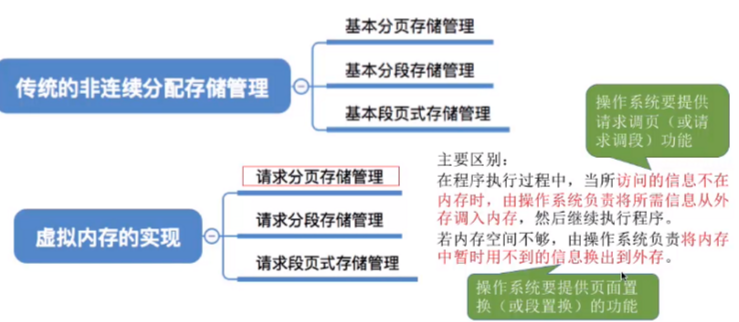
易混知识点:
虚拟内存的最大容量是由计算机的地址结构(CPU寻址范围)确定的。
如:某计算机地址结构为32位,按字节编址,则虚拟内存的最大容量为2^32字节。
虚拟内存的实际容量= min(内存和外存容量之和,CPU寻址范围)
T28:open、read系统调用
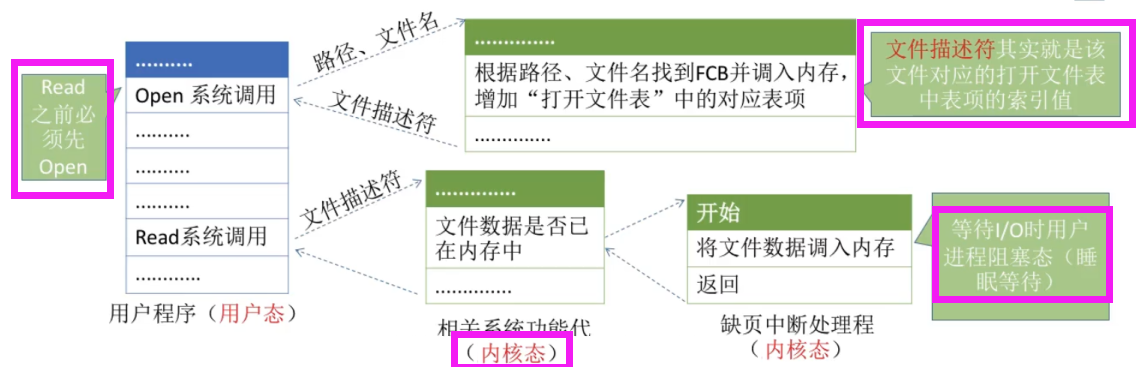
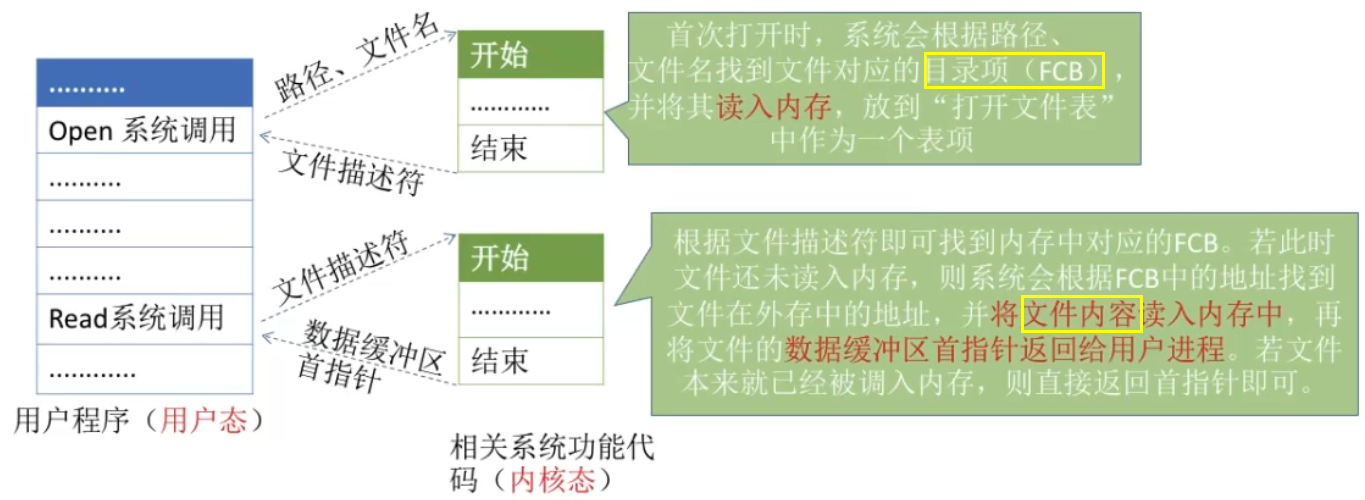
read要求用户提供三个输入参数:①文件描述符fd ②buf缓冲区首址 ③传送的字节数n
read的功能是试图从fd所指示的文件中读入n字节的数据,并将它们送至由指针buf所指示的缓冲区。
open系统调用将文件目录项读入内存,read系统调用将文件内容读入内存。
这里的阻塞状态即睡眠等待态。OS | 【四 文件管理】强化阶段大题解构 —— FAT文件系统、UFS文件系统访问文件过程_西皮呦的博客-CSDN博客
T30:处理机调度
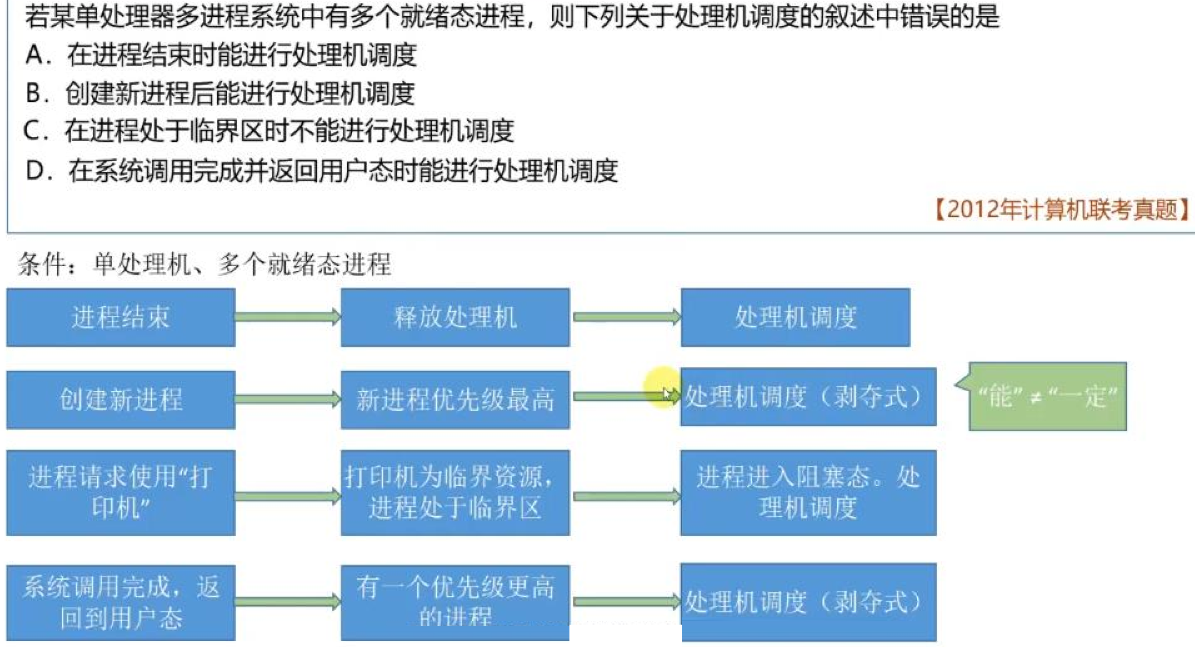
- 内核临界区和临界区不一样。
- 普通临界区:打印机,不影响计算机内核,可以进行调度。
- 内核临界区:计算机的就绪队列,必须用完赶快解锁,否则会影响内核工作。
- 不能进行调度和切换的时机:
- 处理中断
- 进程在OS内核临界区(普通临界区可以)
- 原子操作,此时置请求调度标志。
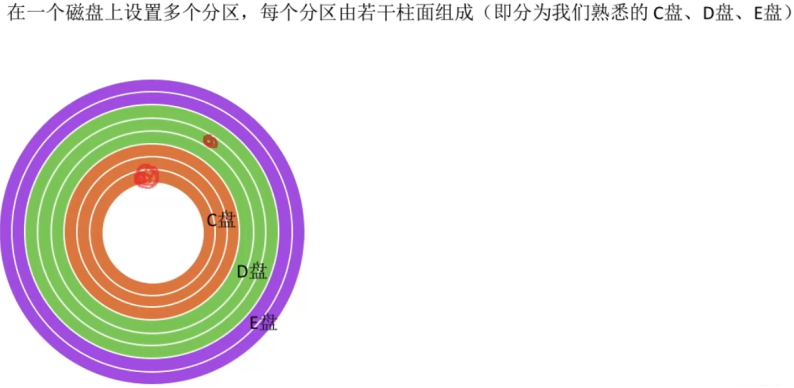
T32:改善磁盘设备I/O性能
- 1、重排I/O请求次序
- 2、预读和滞后写
- 预读(提前读)∶如果采用的顺序访问方式对文件进行访问,便可预知下一次要读的盘块。此时可采用预读策略,即在读当前块的同时,也将下一个盘块提前读入内存缓冲区,这样在访问下一个盘块时就不需要再启动磁盘,从而提升磁盘I/O速度。
- 滞后写(延迟写)∶滞后写是指缓冲区A中的数据本应立即写回磁盘,但考虑到其中的数据在不久之后有可能再次被访问,因此并不会立即把A中的数据写回磁盘,而是将缓冲区A挂到空闲缓冲区队列。如果有别的进程申请使用该缓冲区时,才把A中的数据写回磁盘。这样做的好处是,只要缓冲区A仍在队列中,任何访问该数据的进程,都可以直接读出其中的数据而不必访问磁盘。因而这种方式也可以减少磁盘I/O次数,改善性能。
- 3、优化文件物理块的分布
- 在采用链接组织和索引组织方式时,可以将一个文件分散在磁盘的任意位置,但如果安排的过于分散,则访问该文件时会增加磁头的移动距离。而如果把文件物理块安排在相邻的一些磁道上,则访问文件时磁头移动距离就能减少,从而改善磁盘设备I/O性能。
- 设置多个分区相反还会带来处理的复杂和降低利用率。
T33:ICMP、各层协议、各层服务

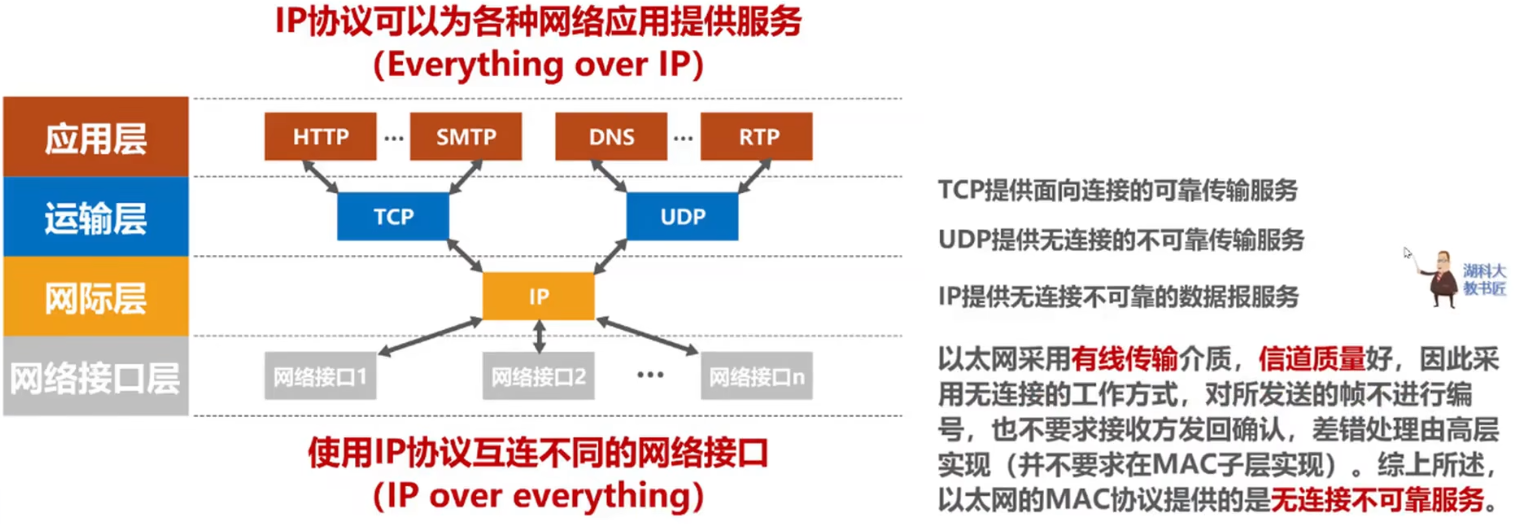
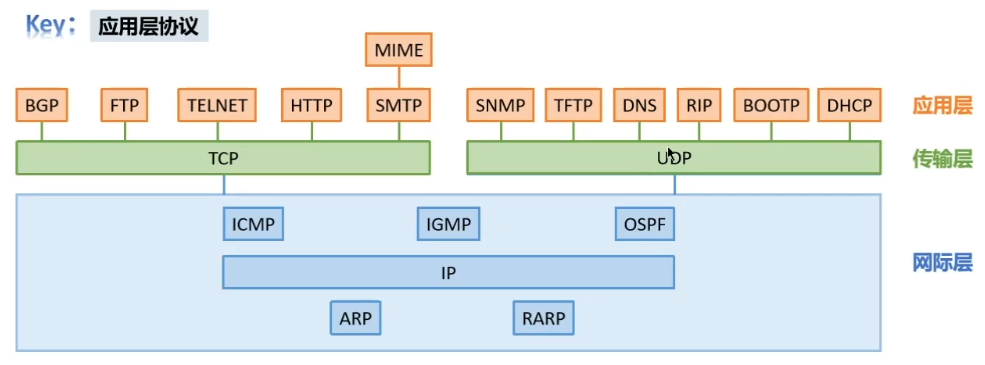
T34:物理层接口特性
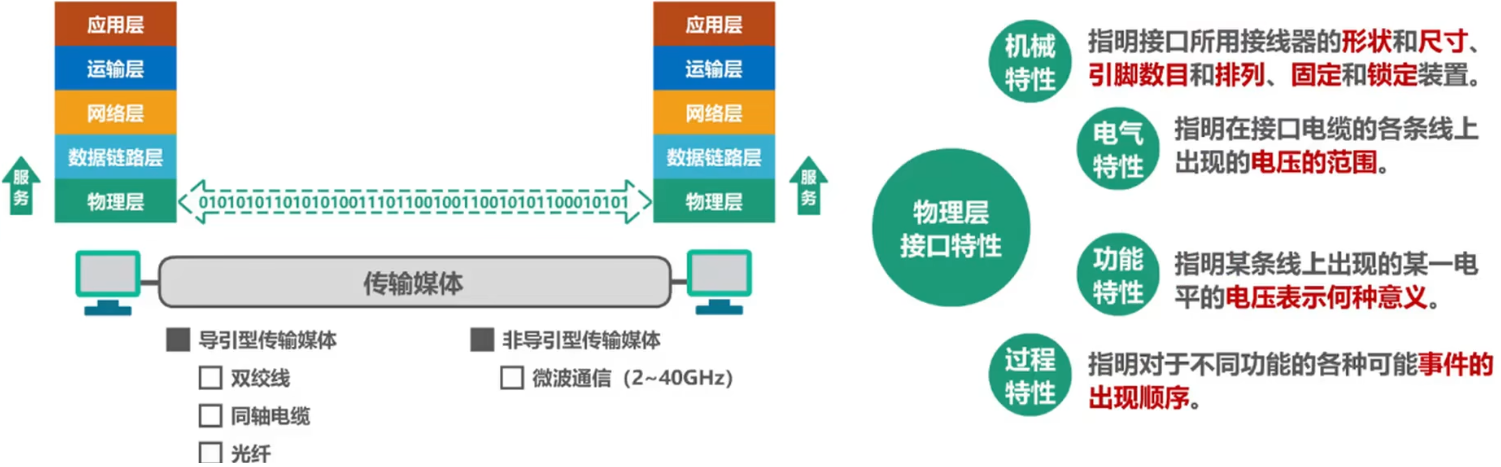
计算机网络协议的三要素:语法、语义、同步。
数据链路层的主要任务:封装成帧、差错检测、可靠传输。
T36:数据传输率、GBN与停-等协议

法二:

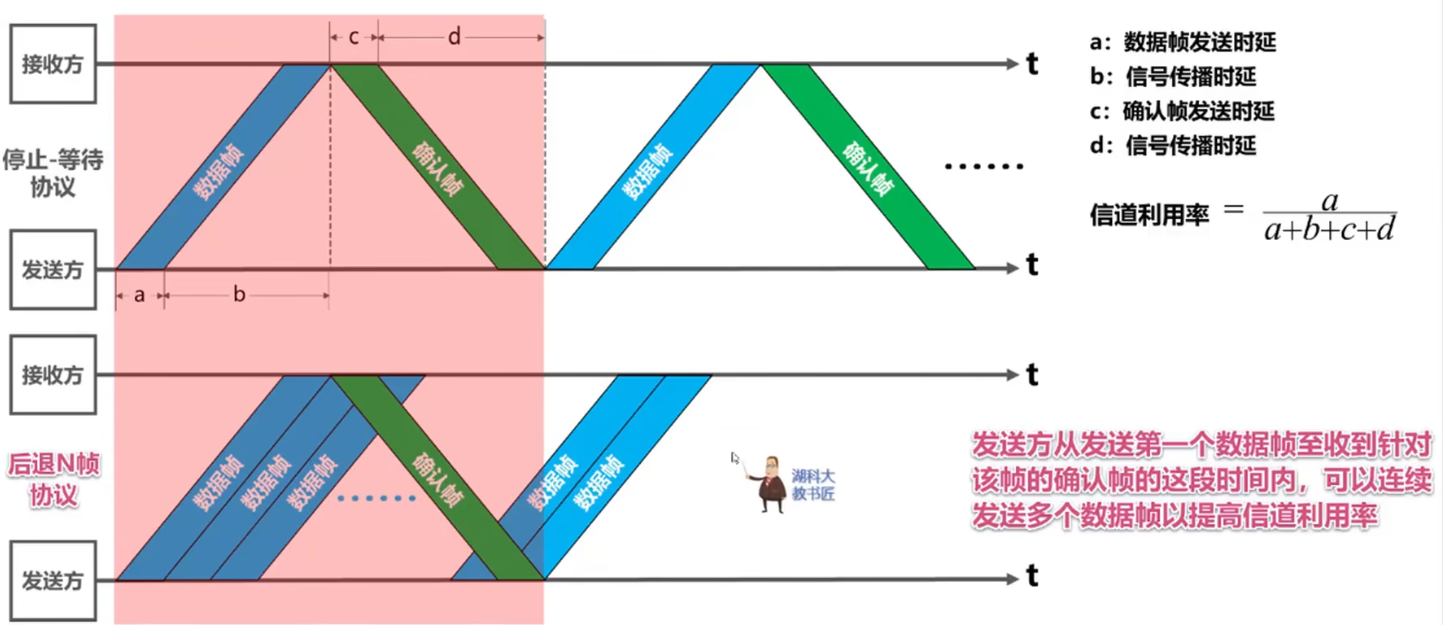
1、信道利用率公式 (有效时间/周期)
2、1个周期=4个时延(大部分和信道利用率有关的题目都会用到! )
3、找出帧数量n与帧长度l之间的关系(很新颖)
T37:路由器的功能
1、转发分组(依据自身的转发表和分组首部的目的地址)
2、执行路由选择协议构建路由表进而构建转发表
3、IP路由器采用主动队列管理AQM对路由器中的分组排队进行智能管理。现在已经有几种具体的算法,也就是路由器的拥塞控制算法。
4、IP路由器对收到的IP分组头进行差错校验,若发现错误则丢弃该IP分组(转发该分组是没有意义的)。
IP路由器工作在TCP/IP体系的网际层,该层并不负责可靠传输,而是“尽最大努力的交付”,这并不能确保传输的IP分组不丢失。
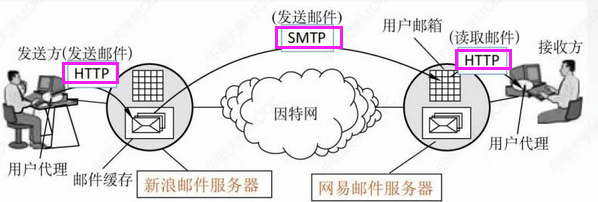
T40:电子邮件
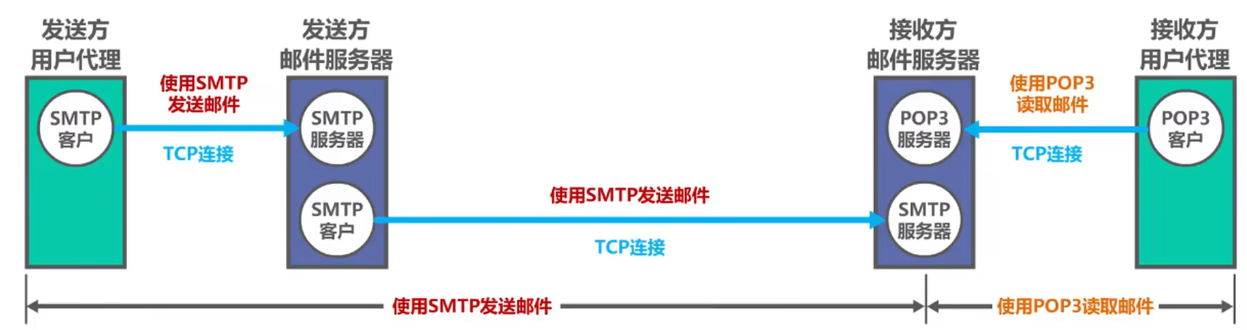
解答题
T41:哈夫曼树(最佳归并树)
有序表合并的最坏情况下的比较次数 m+n-1.
T43:计算机的性能指标 计算

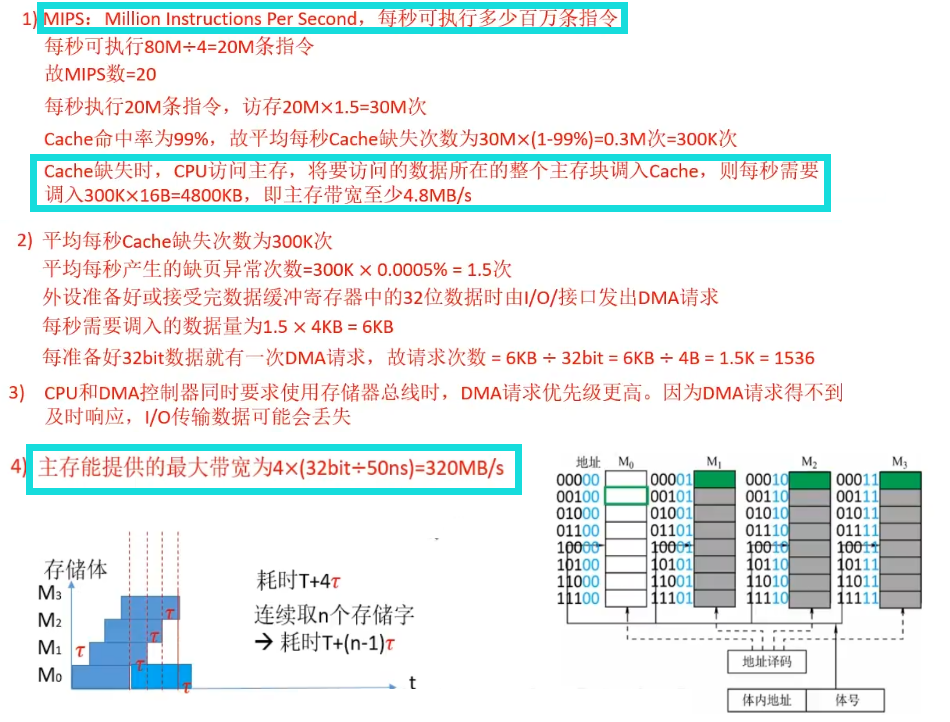
注:
第一问中问的是 至少 。因为此时除了CPU可能还要其他部件需要访存,比如DMA。
第四问中考虑 宏观 的情况。
计算机的性能指标

访存过程中的一些参数
平均每条指令访存n次; Cache命中率为H;
假设使用页式虚拟存储器,在cache缺失的情况下访问主存时缺页率为m。
则
平均每条指令访问cache次数为nxH;
平均每条指令访问主存次数为n×(1-H);平均每条指令访存缺页次数为n×(1-H)×m。
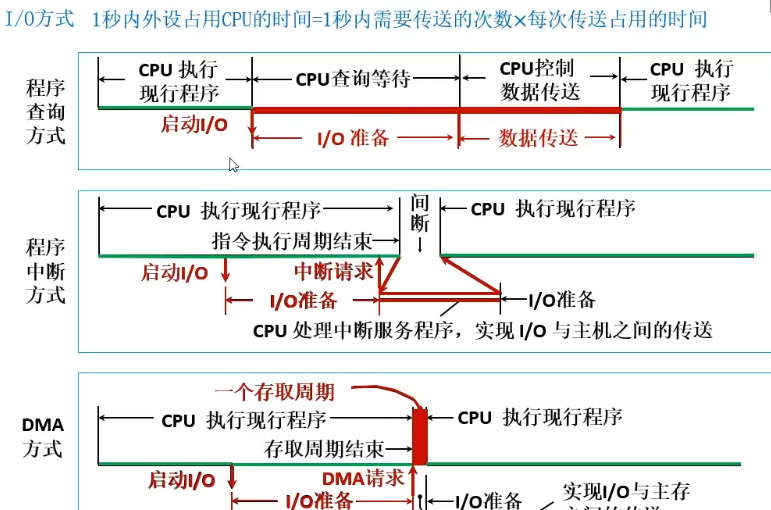
I/0方式 1秒内外设占用CPU的时间=1秒内需要传送的次数×每次传送占用的时间
DMA控制器与CPU共用内存的安排
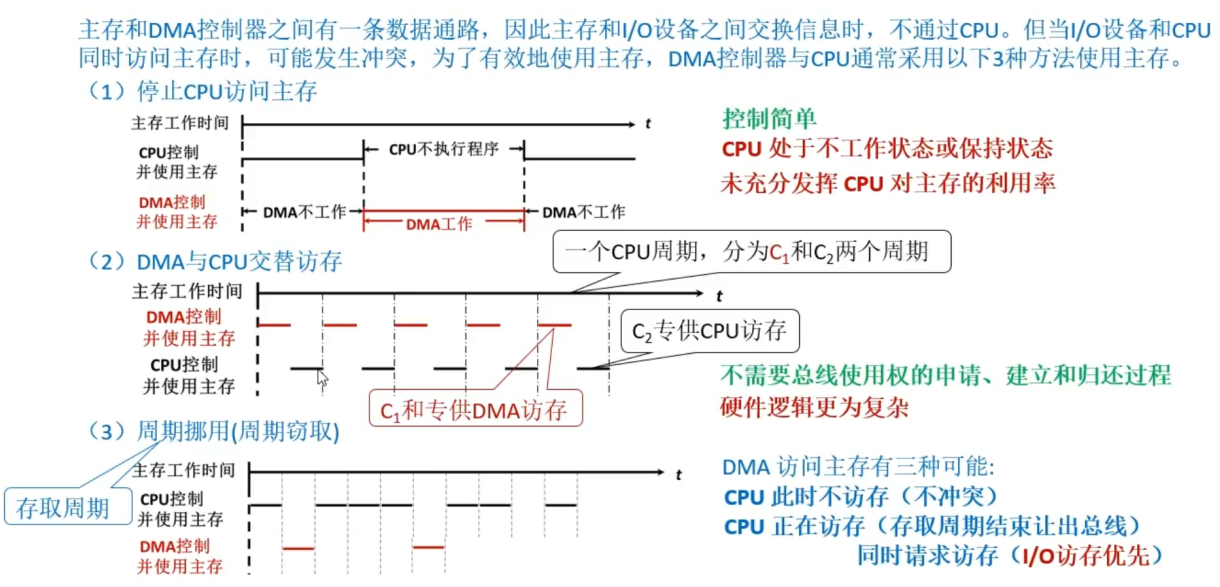
低位交叉存储器
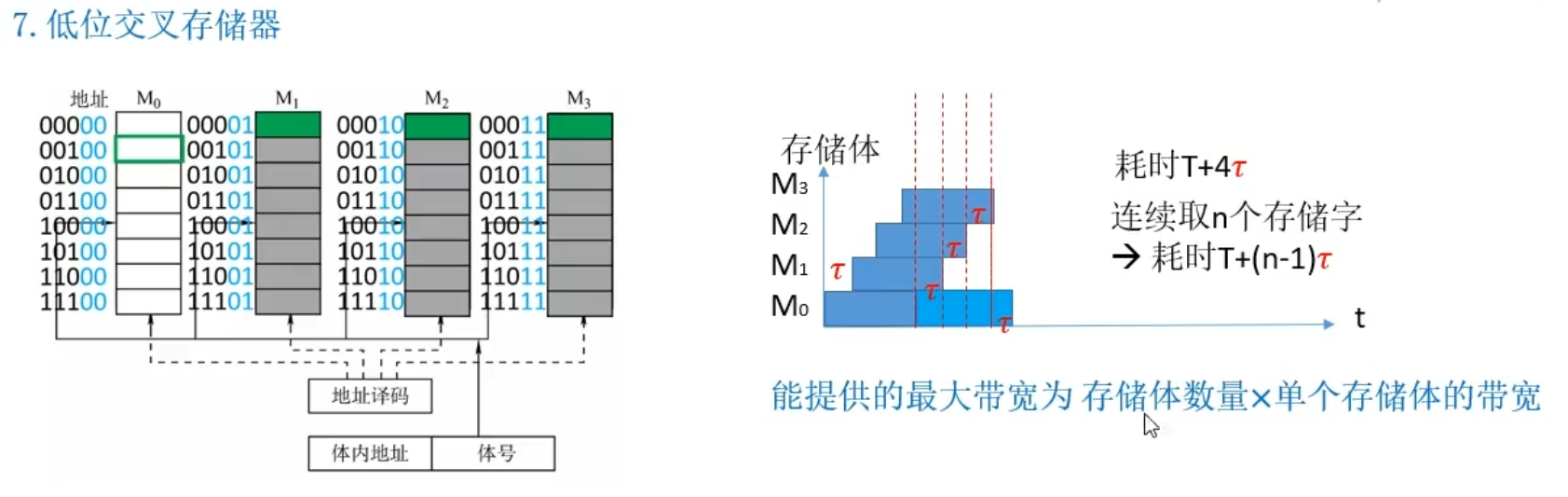
存储器带宽:每秒能访问的位数
低位交叉能提供的最大带宽为存储体数量×单个存储体的带宽
计组 | 交叉编址 & 流水线_西皮呦的博客-CSDN博客_交叉编址
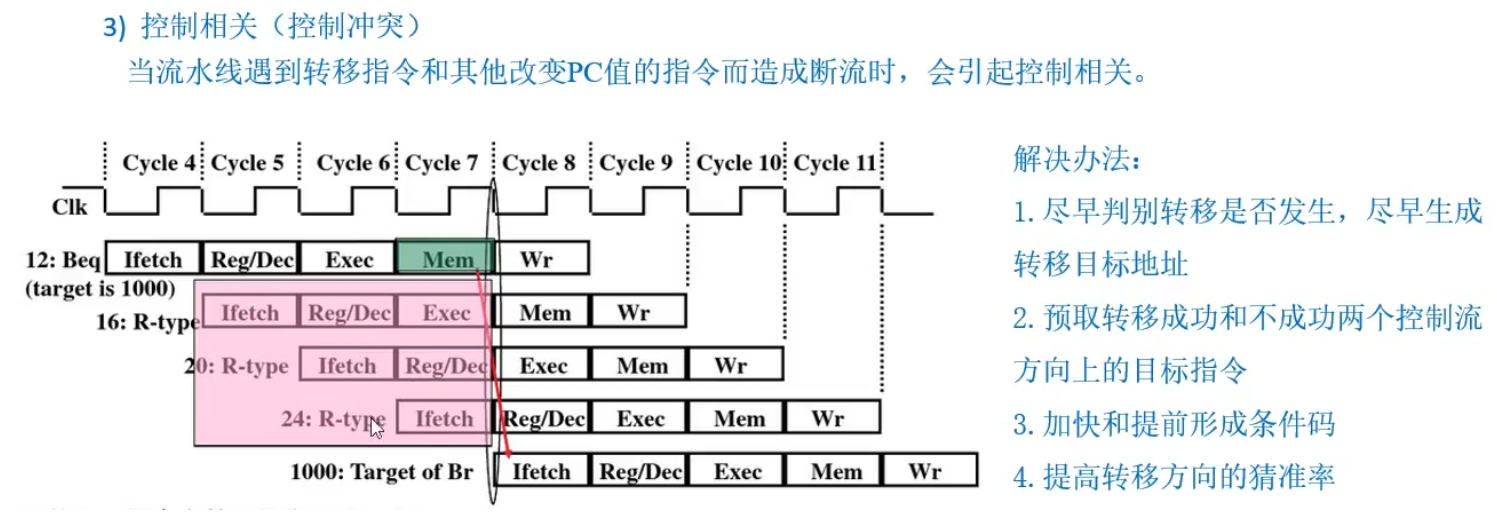
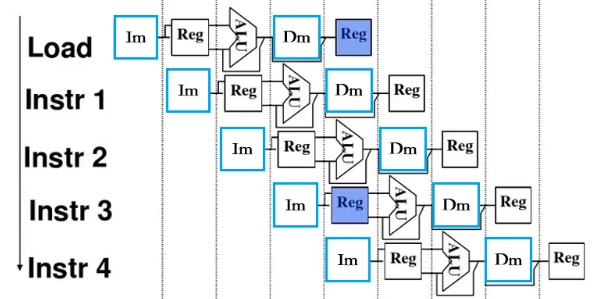
T44:指令流水线
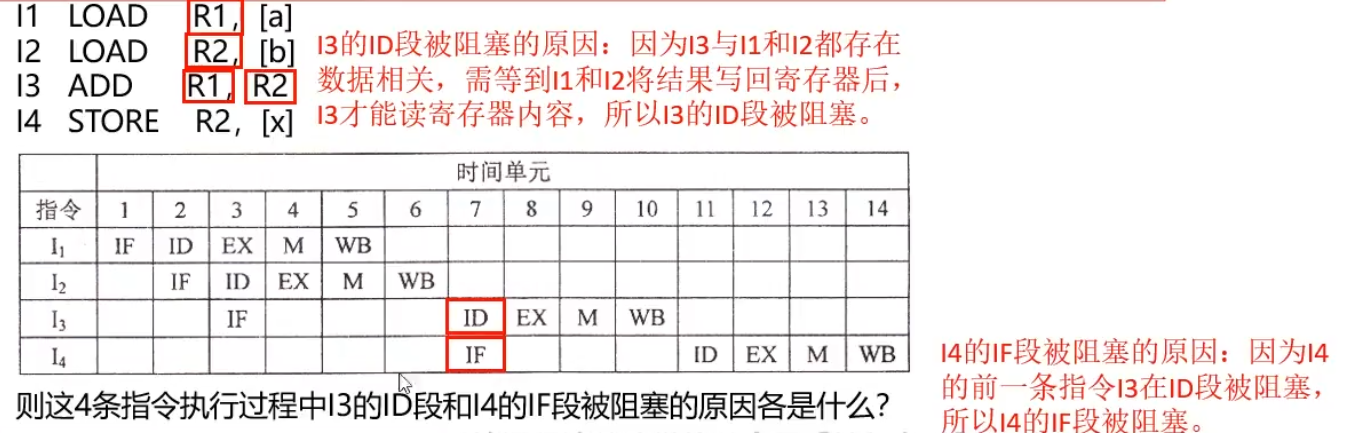
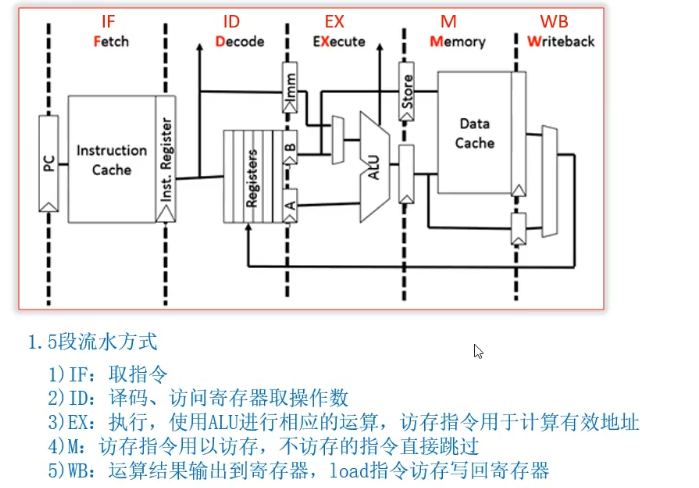
1、计算机采用5段流水方式执行指令,各流水段分别是
取指(IF)、译码/读寄存器(ID)、执行/计算有效地址(EX)、访问存储器(M)、和结果写回寄存器(WB)
2、流水线的耗时计算
1)使用k段流水线时,一般每段占用一个时钟周期,若没有阻塞,连续执行n条指令耗费的时钟周期数为k+(n-1)。
2)流水线充分流动时,每个时钟周期均有一条指令完成;不使用流水线时,每k个时钟周期有一条指令完成;
故使用k段流水线的机器工作能力与k台不使用流水线的机器相同。
3、影响流水线的因素
-
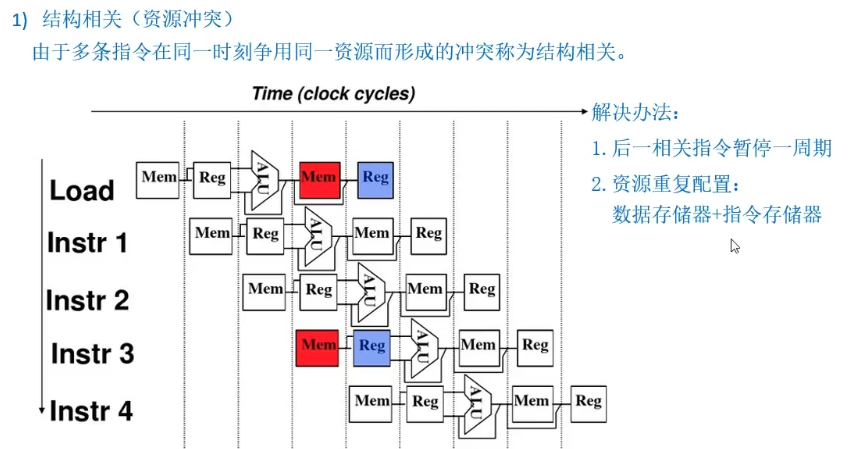
- 数据 指令 分开:
- 数据 指令 分开:
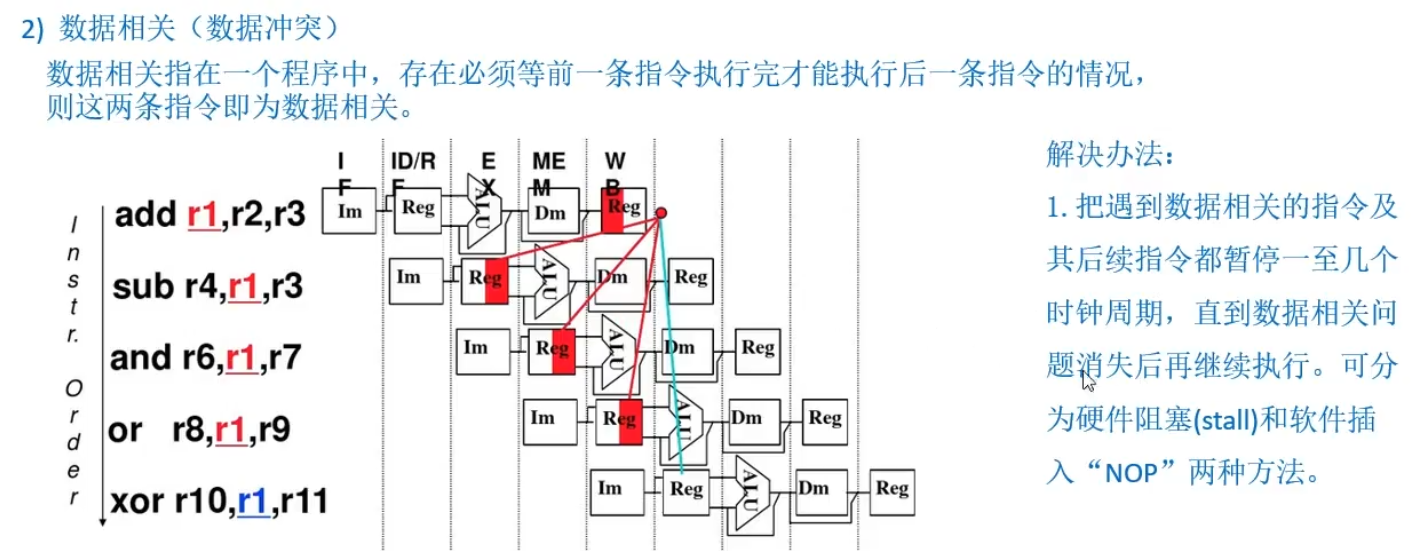
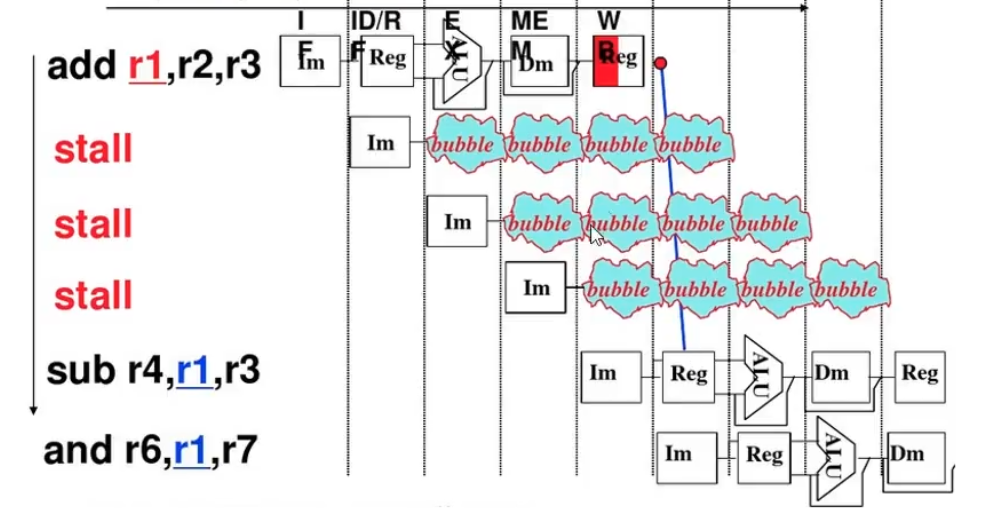
- 1、把遇到数据相关的指令及其后续指令都暂停一至几个时钟周期,直到数据相关问题消失后再继续执行。
-
-
- 硬件阻塞(stall)
- 软件插入“NOP”
- 硬件阻塞(stall)
-
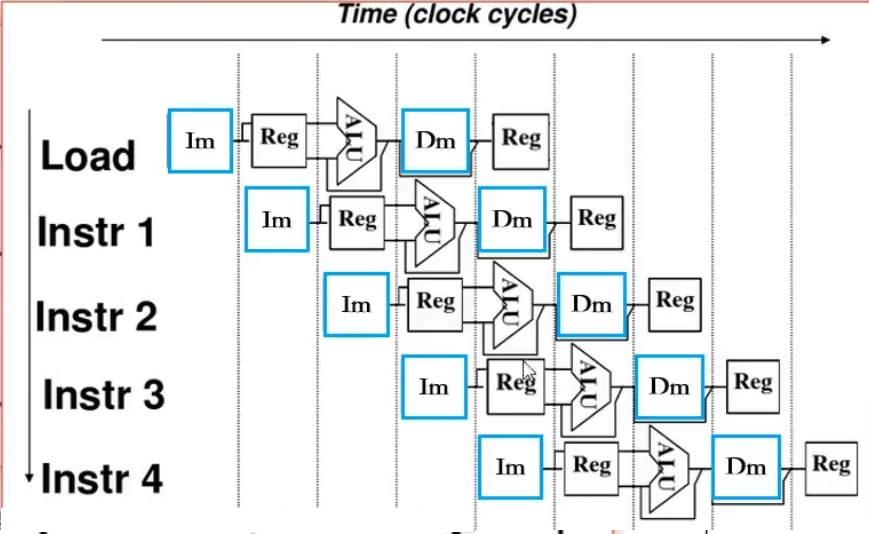
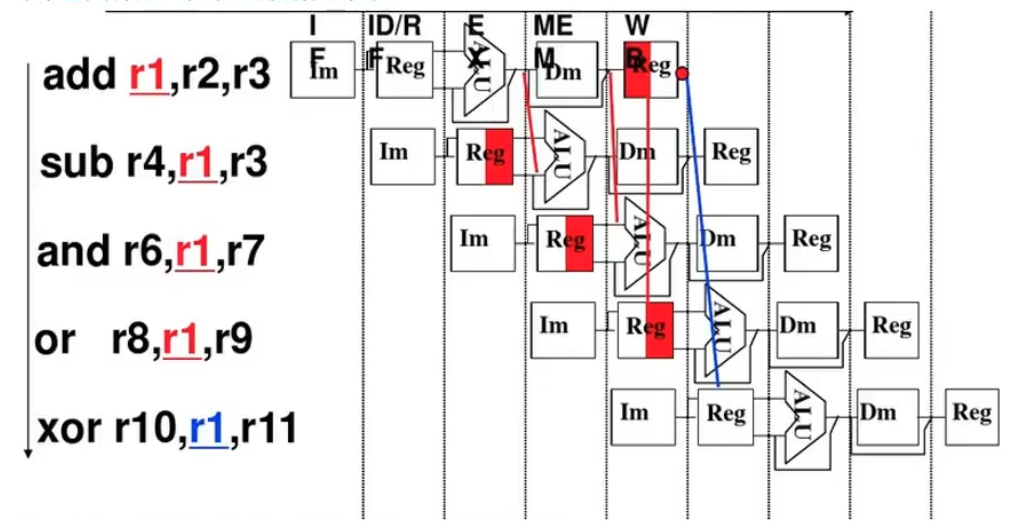
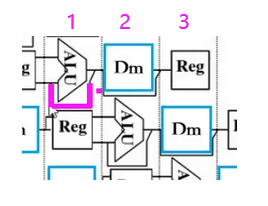
- 2、转发技术即数据旁路技术。下图中那条线 ~
- 即下一条想要取出Reg的数据,不必等前一条指令将Reg的数据写回(其实1存储周期结束后已经准备好咯),而是用数据旁路技术直接用。
-
- 即下一条想要取出Reg的数据,不必等前一条指令将Reg的数据写回(其实1存储周期结束后已经准备好咯),而是用数据旁路技术直接用。
- 3、编译优化:通过编译器调整指令顺序来解决数据相关。
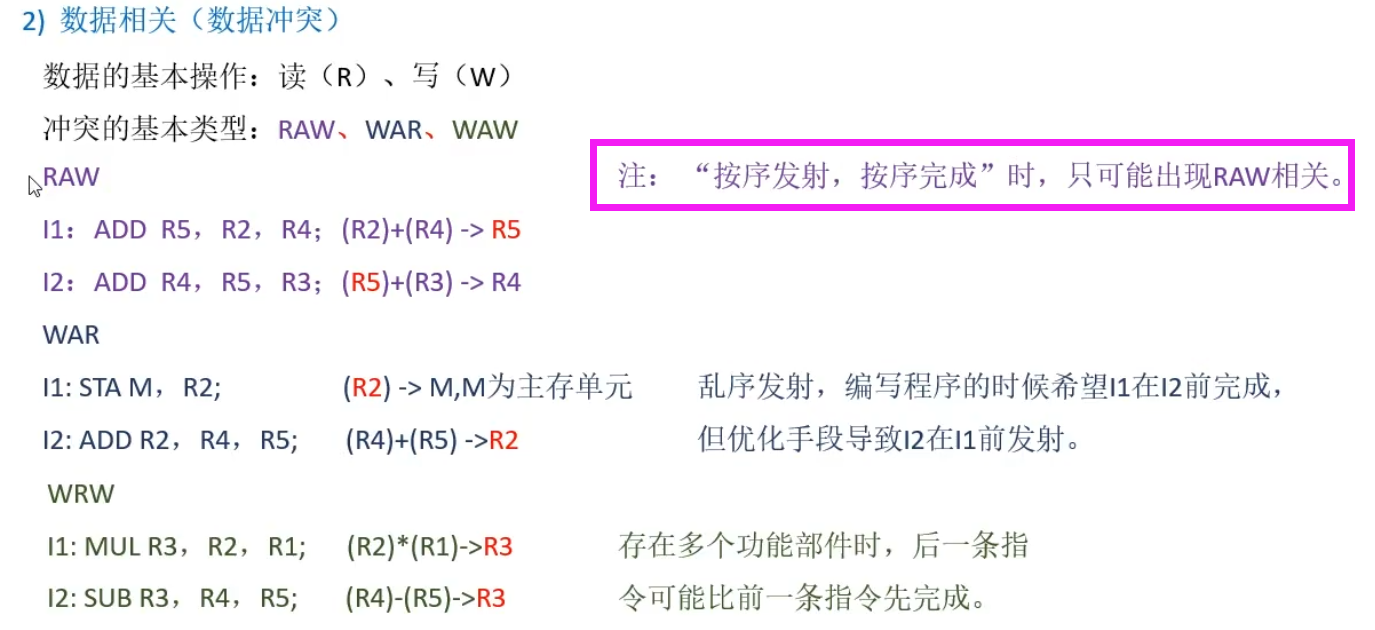
- 按序发射:当一条指令之前的指令都进行取指操作后,才可进行取指。
- 按序完成:前面的指令执行完之后后面指令才能执行完。
- 即不考虑任何优化。

T45:驻留集算法
驻留集:给一个进程分配的物理页框的集合。
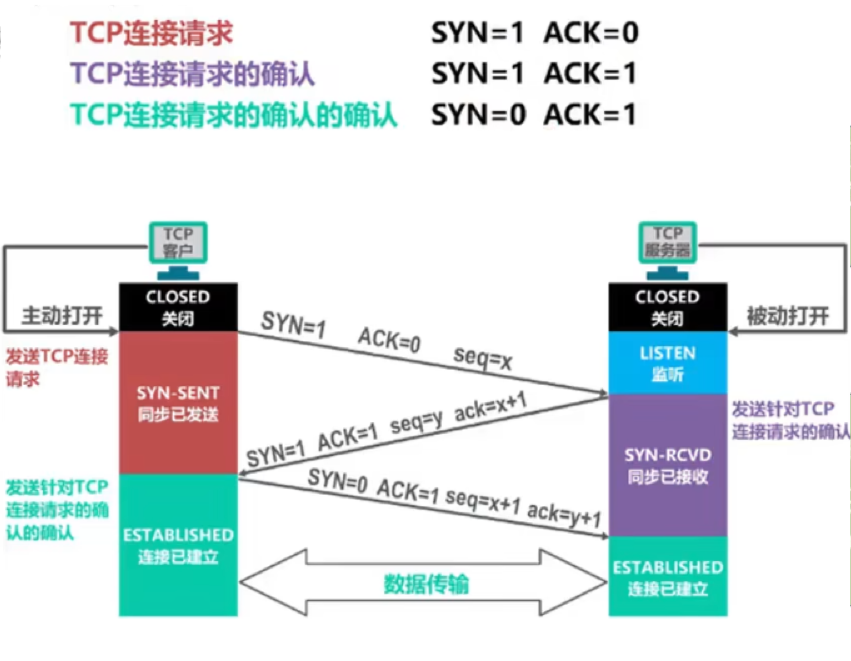
T47:TCP三次握手、报文格式


以太网的最小帧长为64字节,除去首部和尾部共18字节外.数据载荷的最小长度为46字节。


















 2094
2094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











