







本文并非逐句翻译,添加个人理解与疑惑,如有需要,请自行阅读原文。

CTFN: Hierarchical Learning for Multimodal Sentiment Analysis Using Coupled-Translation Fusion Network
基于耦合翻译融合网络的多模态情感分析的层次学习
发表在 2021 ACL-long
数据集:CMU-MOSI、MELD
代码地址:GitHub - deepsuperviser/CTFN: This is the code for Coupled-translation Fusion Network.
多模态情感分析涉及多个异构模态的融合。主要挑战在于在多模态融合过程中可能会出现一些缺失的模态。然而,现有的技术需要所有模态作为输入,因此对于预测时缺失的模态非常敏感。
在这项工作中,首次提出了耦合翻译融合网络(CTFN),通过耦合学习来建模双向交互作用,确保了对缺失模态的鲁棒性。
- 具体而言,引入了循环一致性约束来提高翻译性能,使本文直接丢弃了解码器,只保留了Transformer的编码器。这有助于构建一个更轻量级的模型。
- 由于耦合学习的存在,CTFN能够并行地进行双向跨模态互相关。
- 基于CTFN,进一步建立了一个分层架构来利用多个双向翻译,与传统的翻译方法相比,可以得到双倍的多模态融合嵌入。
- 此外,利用卷积块进一步突出了这些翻译之间的显式交互作用。
对于评估,CTFN在两个多模态基准数据集上进行了验证,并进行了广泛的消融研究。实验表明,所提出的框架在性能上达到了最先进或通常有竞争力的水平。此外,CTFN在考虑缺失模态时仍保持了鲁棒性。
1 Introduction
直观地说,由于不同来源之间的一致性和互补性,联合表示关注多模态消息的推理,这能够提高特定任务的性能。
现有的融合通常是通过利用模型不可知的过程来完成的,考虑到早期融合、晚期融合和混合融合技术。其中,早期融合侧重于单模态表示的串联。相反,后期融合通过在所有模型结果中进行投票,在决策层进行集成。关于混合融合,输出来自早期融合和单模态预测的结合。
然而,多模态情感序列往往由不一致的属性组成,传统的融合方式未能仔细考虑异质性和不一致性,这就提出了研究更复杂的模型和估计情感信息的问题。
最近,基于Transformer的多模态融合框架已经被开发出来,以在多头注意力机制的帮助下解决上述问题。然而,使用标准Transformer的解码器组件来提高翻译性能,这可能会导致一些冗余。此外,没有考虑跨模态翻译之间的显式互动。从本质上讲,与本文的CTFN相比,它们的架构需要访问所有模态,作为探索与顺序融合策略的多模态相互作用的输入,因此在多个缺失模态的情况下相当敏感。
现有多模态情感融合架构包含:translation-based、non-translation based model.。
Translation-based:GEM-LSTM、bc-LSTM、MELD-base、CHFusion、MMMU-BA.
Non-translation based model:seqseq2sent、MCTN、TransModality.
CTFN与现有基于翻译的模型的比较:
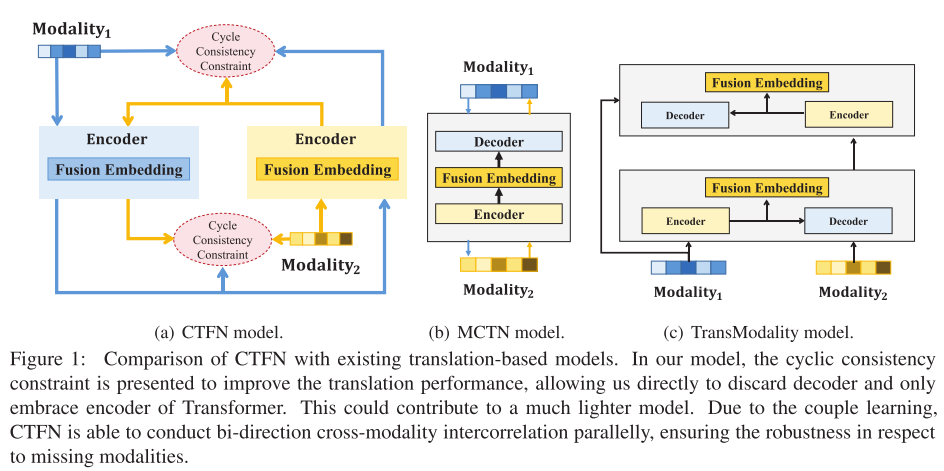
3 Methodology
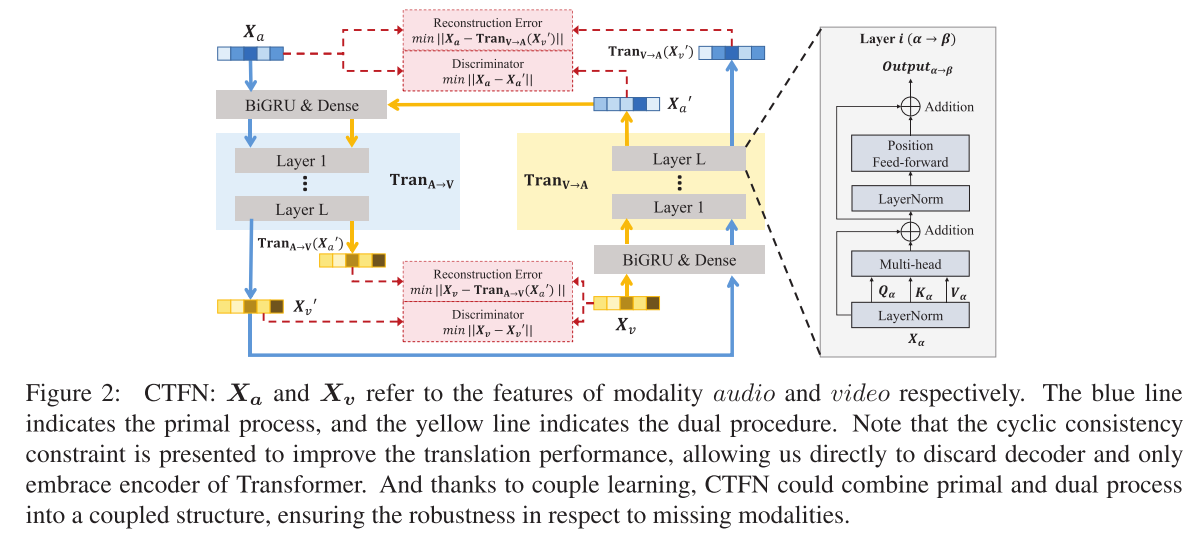
首先介绍了CTFN(图2),它能够通过配对学习探索双向跨模态翻译。
在CTFN的基础上,建立了一个层次结构来利用多个双向翻译,从而产生双多模态融合嵌入(图4)。
该论文的模型是一个分层体系结构,主要由3个CTFN结合构成的Coupled-Translation Fusion Network;以及一个Multimodal convolutional fusion block构成。
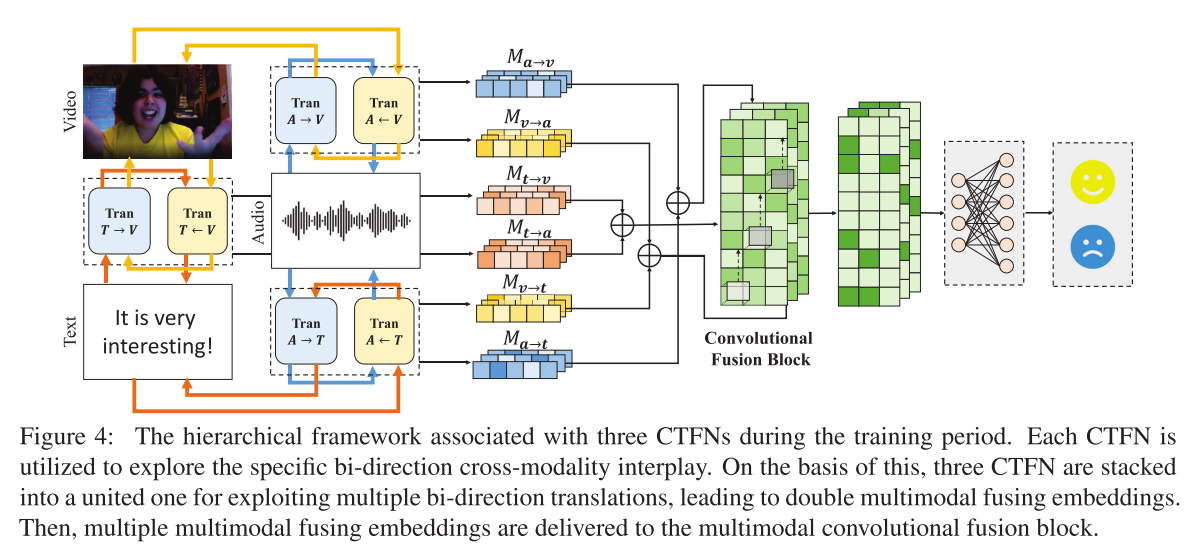
然后,应用卷积融合块(图3)来进一步突出跨模态翻译之间的显式相关性。
3.1 Preliminaries 准备工作
两个基准包括三种模态,即音频、视频和文本模态。具体而言,上述话语级模态分别表示为![]() 。话语的数量表示为
。话语的数量表示为![]() ,并且
,并且![]() 代表单峰特征的维数。
代表单峰特征的维数。
3.2 Coupled-Translation Fusion Network 耦合翻译融合网络
该模块的整体架构如下图,它主要由3个CTFN构成,其中CTFN旨在融合双向翻译过程中的信息(进行双向跨模态的关联)。CTNF模型还包含有the cyclic consistency constraint,该约束提高了Translation的性能,并丢掉了Transformer的decoder使其变得更加轻便。主要工作流程包含the primal process和the dual process两个流程。the primal process是模态的正向转换,如:audio->video表示为TranA→V (Xa,Xv);the dual process则是反向转换TranV →A(Xv, Xa)。
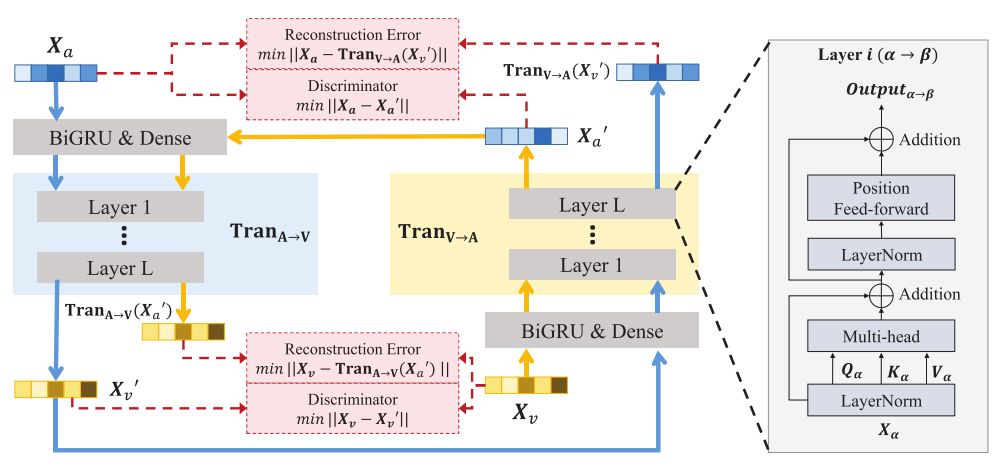
为了简单起见,这里考虑从audio(A)和video(V)分别提取的两种单模态表示,分别为Xa和Xv。在CTFN的原始过程中,专注于学习一个方向性翻译器TranA→V(Xa,Xv),用于将音频模态转换为视频。然后,双重过程旨在学习一个逆向方向翻译器TranV→A(Xv,Xa),允许从视频模态到音频的转换。
受到Transformer在自然语言处理中的成功启发,本文将Transformer的编码器引入到模型中作为翻译模块,这是一种有效且适应性强的方法,用于在时间域中检索长距离的相互作用。重要的是,本文引入了循环一致性约束来提高翻译性能。由于耦合学习的作用,CTFN能够将原始和双重过程结合成一个耦合结构,确保对于缺失模态的鲁棒性。
1)the primal process
![]() 首先被送往 a densely connected layer来得到一个线性转换
首先被送往 a densely connected layer来得到一个线性转换![]() ,
,
从audio到video的翻译可以表示为:![]()
Xv' 是指伪 Xv,输入Xv被用来分析真实数据Xv和伪输出Xv'的差异。
之后,Xv' 被传递给TranV→A,导致重构输出![]() ,而Xa仅用于计算真实数据和重构数据之间的差异。
,而Xa仅用于计算真实数据和重构数据之间的差异。
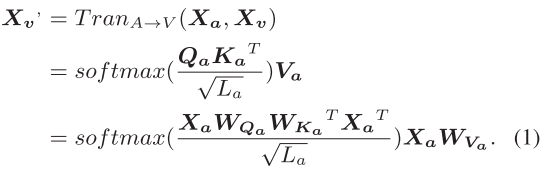
2)the dual process
类似的,在双重过程中,Xv是在输入Xv、Xa'和重构表示Xv'的基础上生成的。
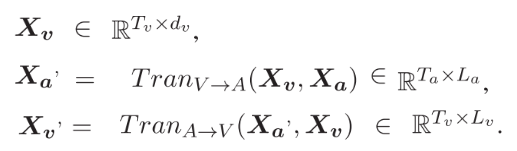
本质上,TranA→V和TranV→A是由几个顺序编码器层实现的。在转换过程中,作者假设中间编码器层包含跨模态融合信息,并能有效平衡两模态的贡献。
因此,中间编码器层的输出TranA→V [L/2]和TranV→A [L/2]表示多模态融合知识,其中L表示层数,当L为奇数时,则L = L +1。
对于模型奖励,primal process 具有即时奖励 rp = ![]() ,dual step相关奖励为
,dual step相关奖励为![]() ,表明真实数据与translator重构输出之间的相似性。为简单起见,采用线性变换模块将两个奖励合并为总模型奖励,例如
,表明真实数据与translator重构输出之间的相似性。为简单起见,采用线性变换模块将两个奖励合并为总模型奖励,例如![]() ,其中α用于平衡dual块和primal块之间的贡献。
,其中α用于平衡dual块和primal块之间的贡献。
此外,耦合翻译多模态融合块中使用的损失函数定义如下:
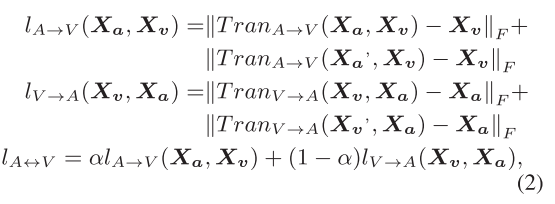
其中lA→V(Xa,Xv)和lV→A(Xv,Xa)分别表示原始翻译器和对偶翻译器的训练损失,lA ↔V表示双向翻译器单元的损失。
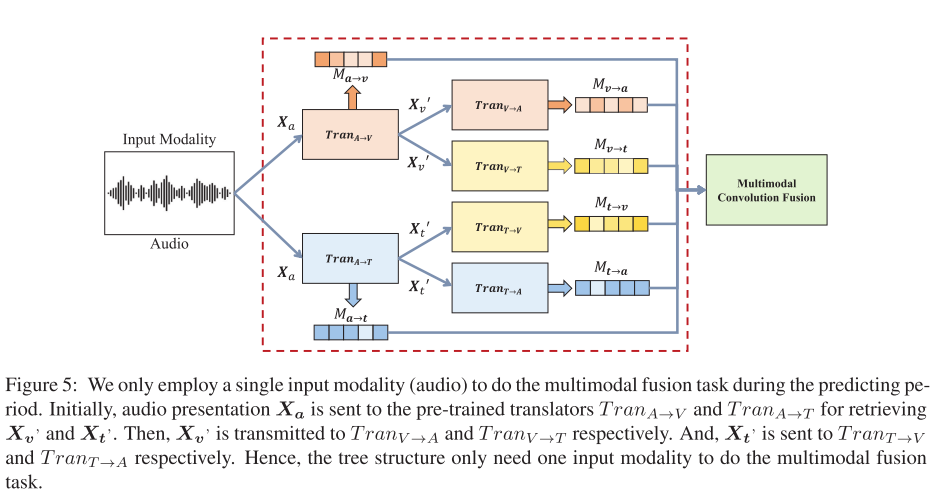
从本质上讲,当所有成对翻译块的训练过程完成之后,在预测时,此模型只需要一个输入模态,而不需要目标模态的帮助。
事实上,lA↔V表明了本耦合学习模型中的循环一致性约束。循环一致性是众所周知的,它指的是向前和向后周期一致性的组合。然而,我们的目标是解决多通道学习中的丢失通道问题,而这不是直接应用循环一致性所能实现的。这是因为将这种严格的循环一致性引入到CTFN模型中,并不能有效地将primal任务与耦合学习模型的dual任务联系起来。为了解决这个问题,本文通过使用一个参数α来平衡前向和后向循环一致性的贡献,从而放松了对原始循环一致性的约束,从而得到了更加灵活的循环一致性。由于新提出的周期一致性具有很大的灵活性,可以自适应地充分地将原始任务与双重任务相关联,从而在不同模态之间产生更平衡的一致性。
作者认为直接应用严格的循环一致性约束并不能有效地将原始任务和对偶任务联系起来,因为严格的循环一致性通常意味着一个模态能够被完美地翻译到另一个模态,然后再翻译回来,不会考虑到某些模态可能缺失的情况。这在多模态学习中是不实际的,因为在真实世界的应用中,往往会遇到某些模态信息缺失的情况。因此,CTFN通过引入一个平衡因子α来放宽这一约束,使模型能够在模态丢失时仍然有效地工作。
CTFN的核心结构包含了一系列双向翻译器(即耦合翻译器),它们被训练用来学习从一个模态到另一个模态的映射(即“翻译”),并且还能处理来自对方模态的反馈。具体来说:
- 每个双向翻译器负责两个模态间的转换。这意味着,如果有三个模态A、B、C,那么会有A到B、B到A、A到C、C到A、B到C和C到B这六个转换过程。
- 对于每种转换,都会有一个翻译器来学习如何把来自一个模态的特征映射到另一个模态的特征。
- 在训练时,每个模态都会作为输入,以确保模型能够学习到不同模态间的互动和依赖。
- Fusion模块进一步整合来自各个翻译器的信息,以得到一个综合的多模态表征。
因此,CTFN的训练过程不单单是训练六个翻译器,还包括训练fusion模块,这样就可以确保模型即使在某些模态数据丢失的情况下,仍能够通过已有的模态信息来推断和补全丢失的部分。通过这样的设计,CTFN提高了模型在处理现实世界数据时的鲁棒性和灵活性。
3.3 Multimodal convolutional fusion block 多模态卷积融合块
基于CFTN,每个模态作为(M-1)次源时刻,即意味着每个模态持有(M-1)个方向转换。![]() ,M为模态的总数。
,M为模态的总数。
例如,给定音频模态,我们可以retrieve到以下两种模态引导的转换。
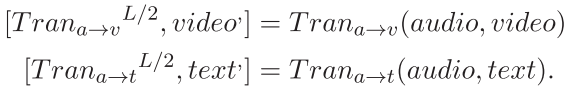
注意 audio在不同跨模态翻译中起到了关键的作用并且为形成多样的跨模态interplay提供了strong guidance。为了有效地融合源通道(audio)的贡献,引入了卷积融合块来探索通道引导翻译之间的显性和局部相关性。
将两个跨模态中间关联![]() 和
和![]() 沿时间域连接到一个表示单元中,其时间序列都相同(Tt=Tv=Ta),因此连接的大小为Ta × (Lv + Lt):
沿时间域连接到一个表示单元中,其时间序列都相同(Tt=Tv=Ta),因此连接的大小为Ta × (Lv + Lt):
![]()
之后,这个时序卷积被用来进一步检索跨模态翻译之间的显式交互。具体来说,本文使用一个1D时序卷积层以一种轻量的方式来利用local patten。
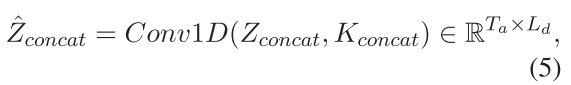
式中Kconcat为卷积核的大小,Ld为跨模态积分维的长度。时间核用于沿特征维度执行卷积操作,允许进一步利用跨模态转换之间的局部相互作用。也就是说,局部的相互作用充分利用了modality-guidance翻译的贡献。
卷积块的原理:
想象一下你在制作一幅拼贴画,你有来自几个不同角度的图片片段,你需要把它们组合起来,才能得到一个完整的图景。卷积块就像是一种工具,它可以识别这些片段之间的联系,并将它们融合成一个统一的图像。在CTFN中,卷积块处理的不是图片片段,而是不同模态(如文本、音频、视频)翻译后的特征。这个块会寻找这些不同来源特征之间的局部模式和联系,然后把它们结合成一个整体的多模态表示。
分层结构的原理:
使用分层结构有点像建造一座多层楼房。每层楼都有其独特的功能,但最终它们共同组成一个整体的建筑。在CTFN中,每一层都被设计来处理和学习从一个模态到另一个模态的转换(翻译),而当这些层合在一起时,就能生成一个更加全面和深入的多模态理解。这意味着从最底层到最顶层,模型能够从基本的模态转换逐步学习到更复杂的跨模态关系。
Fusion块的输入是分别联合三个模态翻译后的两个表示,这是为了从每个模态的角度充分利用和整合跨模态的信息。具体来说:
-
捕获跨模态特征: 在多模态情境中,每个模态(如文本、音频、视频)都包含独特且有用的信息。将一个模态翻译成另一个模态可以帮助模型捕获在原始模态中可能不是很明显的特征。
-
增强模态间的互补性: 不同模态之间存在互补性。例如,文本可能明确表达了某个概念,而音频中的语调和强度则传达了情绪的微妙变化。通过结合这些翻译后的表示,fusion块能够构建一个更加全面且细致的多模态表示。
-
促进深度学习和特征融合: 分层架构使得每个层级都能够专注于不同模态之间的特定翻译任务,这样可以生成深度特征表示。在这个基础上,fusion块可以进一步探索这些不同层级生成的特征之间的高级关系和交互。
-
提高模型的鲁棒性: 在实际应用中,可能会遇到某些模态信息不完整或缺失的情况。通过使用翻译后的表示作为输入,fusion块能够更好地处理这种模态信息缺失的情况,因为它不仅仅依赖于原始的模态数据,而是利用了模态间转换后的深层次特征。
-
充分利用模态导向的翻译: 每个模态都充当过“源模态”,并指导其他模态的翻译。fusion块通过融合这些导向的翻译来确保所有模态都对最终的多模态表示有所贡献。
通过这种方式,fusion块能够生成一个既包含原始模态数据,也包含模态间转换信息的综合特征表示,为最终的情感分析或其他多模态任务提供了一个坚实和丰富的信息基础。
3.4 Hierarchical Architecture
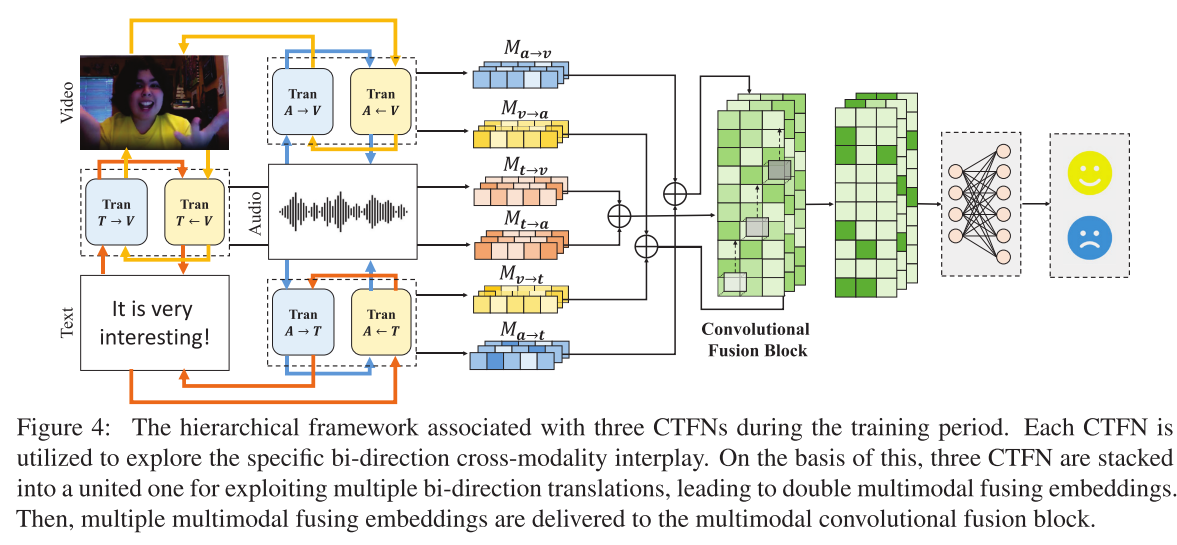
基于CTFN和多模态卷积融合网络提出了多模态双向翻译分层体系架构模型,从而实现双模态的融合嵌入。例:如果有M个模态,则有个双模态嵌入。
本论文根据源模态(source/guidance)的贡献, the modality-guidance translations可以表示为: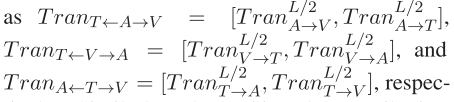
随后,多模态卷积网络利用和source/target(源模态/目标模态)相关联的the modality-guidance translations间的显示局部交互。
该模型总共有“12+1”个损失结构——3个CTFN,每个含有4个训练损失((primal & dual translator training loss);1个分类损失(classifification loss)。为了平衡primal和dual的贡献引入超参数α,3个CTFN公用同一个α。分类损失用于训练对3个CTFN输出进行分类。
4 Experiment
该模型只在CMU-MOSI和MELD(Sentiment)数据集上进行了实验证明。在CMU-MOSI数据集上CTFN超过SOTA--TranModality模型4.5,在MELD数据集上CFTN提升了0.78。在三模态融合任务上CTFN比SOTA--TranModality模型提升了0.06,且TranModality需要4 encoders and 4 decoders,而CTFN只需要6个encoder。

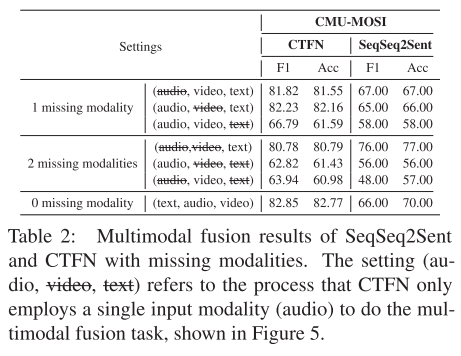
对于模态缺失问题,本文提出了与基于翻译的序列模型seqseq2sent分别再三模态、双模态(缺失一个模态)、单模态(缺失两个模态)情况下仅在CMU-MOSI数据集上进行对比实验。结果如下:
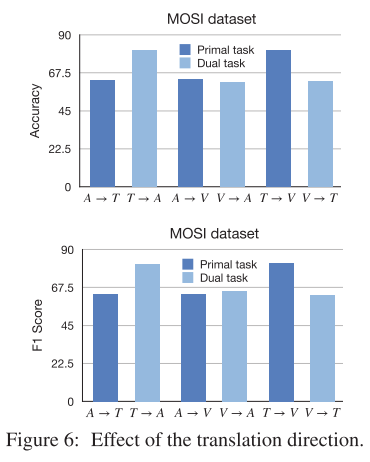
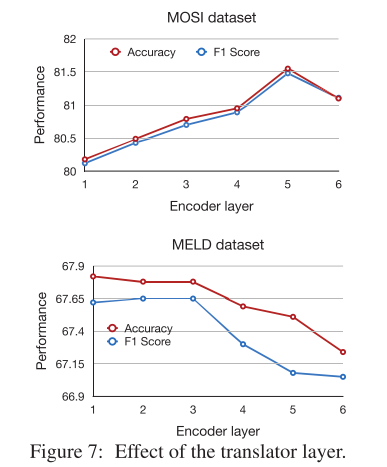
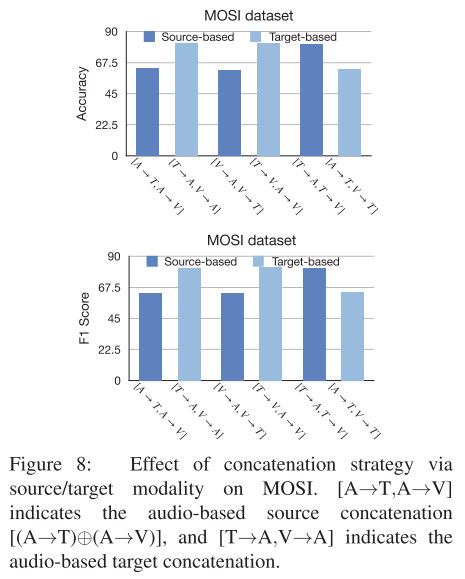
除此之外,作者还进行了消融实验来探究模态间的翻译方向、翻译层数、翻译的链接策略。
其中text->audio和text->video效果比audio->text、video->text更好。audio->video和video->audio效果相差不大。翻译层数则在CMU-MOSI上5层最佳,MELD上1层最佳。对于连接策略,基于音频的目标连接[(T→A)⊕(V→A)]的表现明显优于[(A→T)⊕(A→V)],并且具有很大的边际。类似地,基于视频的目标连接[(T→V)⊕(A→V)]比[(V→A)⊕(V→T))效果更好。
本文还提出了单个模态的输入,其流程如下:
部分参考于



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











