






来源:量子位
自拍的视频也能转换成高清动漫脸,这个AI能够在线玩了!
多达数十种肖像风格,并且支持高分辨率,生成的视频是酱婶的~

比如想生成“迪士尼”卡通风格:

又或者想生成游戏里的角色风格:

这是生成的皮克斯动画风格的效果:

这是南洋理工大学开源的一个叫VToonify的框架,目前在Huggingface和Colab上都可以运行,一作还是北大博士。

看完上面的示例,是不是心痒痒了,下面有详细教程手把手教你怎么玩,还不快学起来!
在线可玩
VToonify的操作可以说非常简单易上手了。
首先,选取你喜欢的卡通风格,公主风、肌肉风、大眼特效……还有5种插图风供你选择。

其次,上传包含正脸的视频(或图像),点击一键缩放,这一步是为了避免CPU/GPU过载,不过不用担心,不会对最后生成视频的质量有影响。
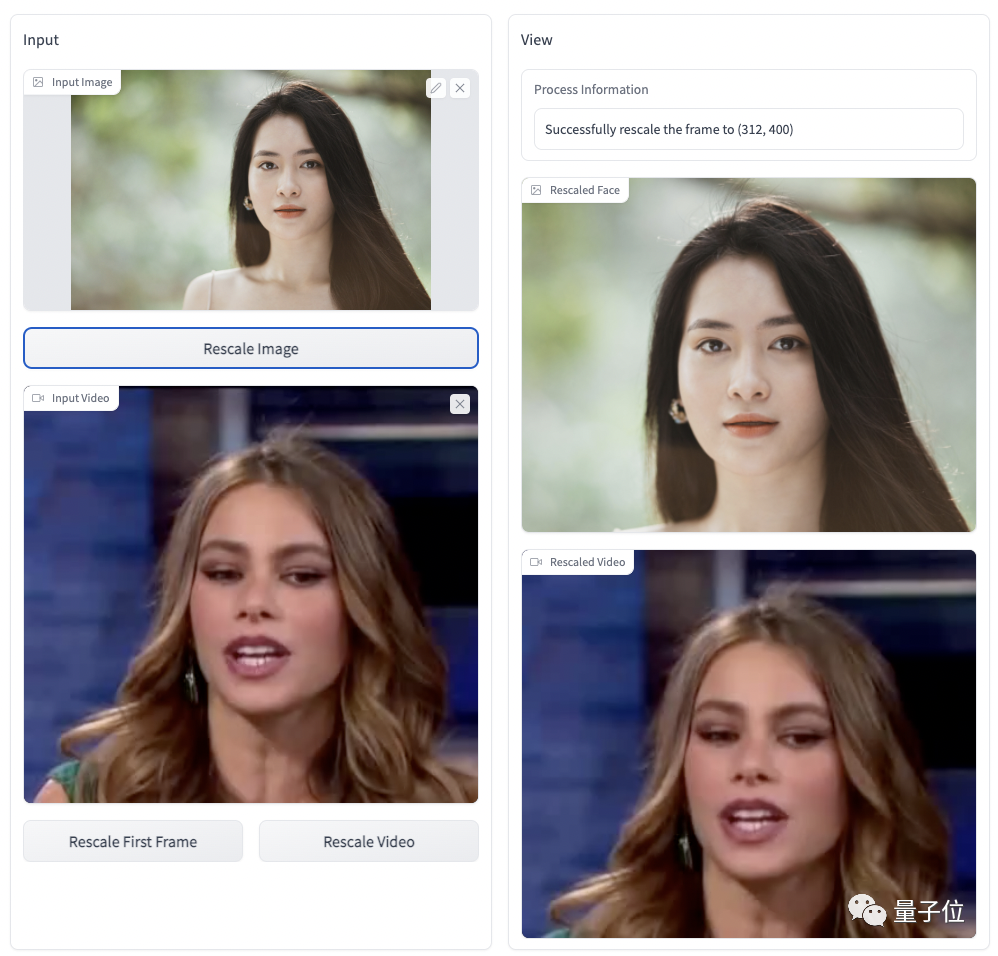
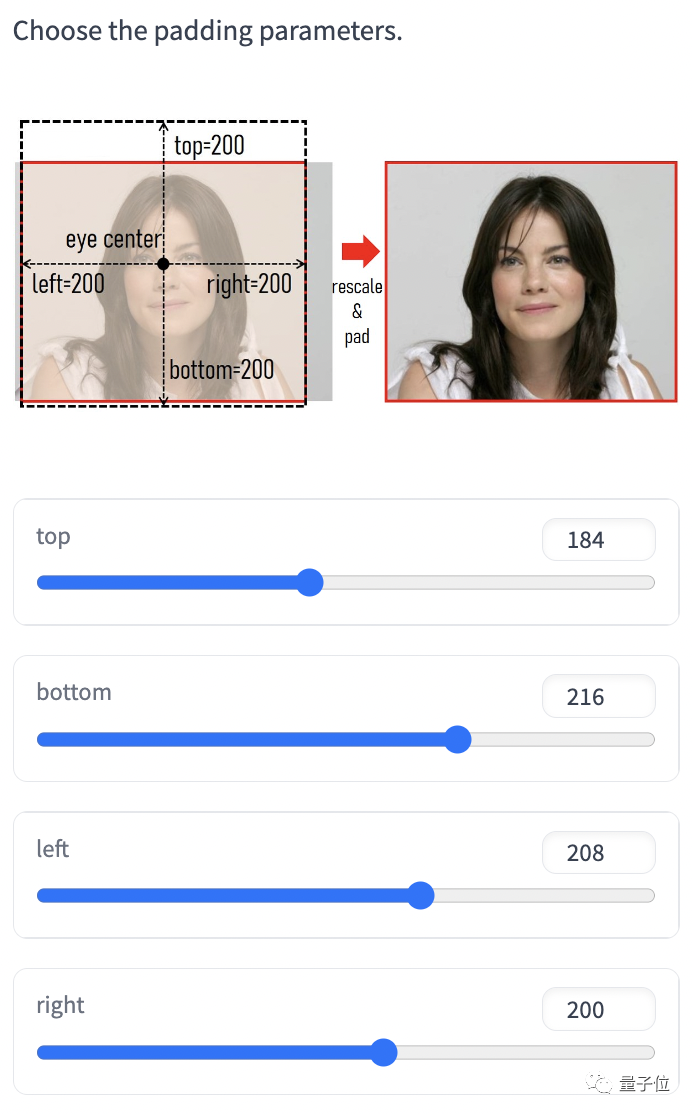
除此之外,还可以对上传视频的尺寸进行裁剪或填充。
接下来,只需等待十几秒,即可得到最终的高清版卡通肖像。

而且,如果对“美颜程度”不满意,还可以后期调整。

那么,如此神奇的效果,背后的原理是什么呢?
集成两种框架
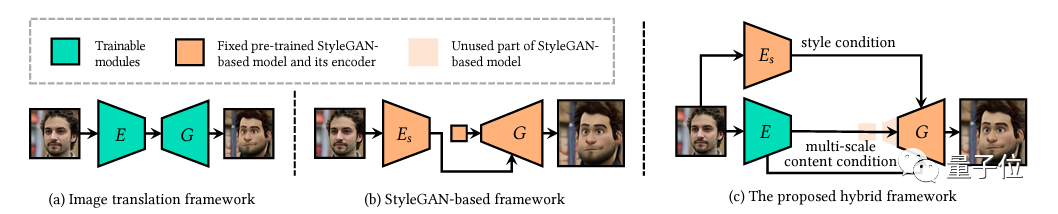
要讲明白VToonify风格转移的原理,就不得不提到StyleGAN,很多图像风格迁移框架都是以这个模型为基础的。
基于StyleGAN的方法也被称作图片卡通化,它将人脸编码到潜在空间中,然后再将生成的代码应用到被艺术肖像数据集调整后的StyleGAN,最终生成不同风格的肖像图。
重要的是,它可以生成1024*1024高分辨率的图像。
但StyleGAN在调整肖像的风格时,需要在固定的尺寸下进行,而且不完整的面孔以及一些奇怪的手势都会对它的效果产生影响,因此StyleGAN对动态肖像是不太友好的。
这时,就需要再介绍另外一种图像转换框架了——采用卷积网络的图像转换框架,它能够很好地忽略在测试阶段图像大小和人脸位置的限制 (与StyleGAN完全互补了)。
说回VToonify,它集两个框架的大成于一身,成为一个全新的混合框架。
研究人员删除了StyleGAN固定大小的输入特性和低分辨率层,然后创建了创建了一个完全卷积的编码器生成器架构。
具体来说,就是将StyleGAN模型集成到生成器中,将模型和数据结合起来,从而它的样式修改特性由VToonify继承。
并且,作为生成器的StyleGAN对编码器进行训练,可以大大减少训练时间和难度。
值得一提的是,该研究团队在今年3月就曾开发过一款图像风格转移AI:模仿大师(Pastiche Master),基于DualStyleGAN的框架,能够灵活控制风格并修改风格度。

而这次研究团队推出VToonify,不仅继承了DualStyleGAN的优点,并且通过修改DualStyleGAN的风格控制模块将这些特性进一步扩展到视频。
研究团队
VToonify的研究团队全部来自南洋理工大学。

论文一作杨帅,是南洋理工大学的研究员,主要研究方向是图像生成和图像编辑,本科和博士均就读于北京大学。

通讯作者吕健勤,是南洋理工大学计算机科学与工程学院的副教授,也是香港中文大学客座副教授,其研究方向主要为计算机视觉和深度学习。

以下是VToonify在线试玩链接,感兴趣的小伙伴们自己动手试试吧~
在线可玩:
[1]https://huggingface.co/spaces/PKUWilliamYang/VToonify?continueFlag=4b9ae61e5c13076ecd7ba4f70434f863
[2]https://colab.research.google.com/github/williamyang1991/VToonify/blob/master/notebooks/inference_playground.ipynb
论文原文:
https://arxiv.org/abs/2209.11224
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/xyxe8w/r_vtoonify_controllable_highresolution_portrait/
[2]https://huggingface.co/PKUWilliamYang/VToonify?continueFlag=4b9ae61e5c13076ecd7ba4f70434f863
[3]https://twitter.com/ShuaiYang1991/status/1576937439528042499
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









