







前言
相信大家在很多的时候,在公众号上经常会看到很多关于购买股票或者是基金的课程,让大家学会理财。就是所谓钱生钱。买股票与基金靠的不是运气,而是长期以来的经验,特别是对数据的敏感程度,做出正确的决策,因此今天我就特定的将股票网站的数据爬取下来,让各位买股票的小伙伴做一个参考。
网页分析
爬取的网址如下:
https://xueqiu.com/
打开页面如下所示:
现在,我要找的是沪A成交额的数据,如何查找呢?如下所示:
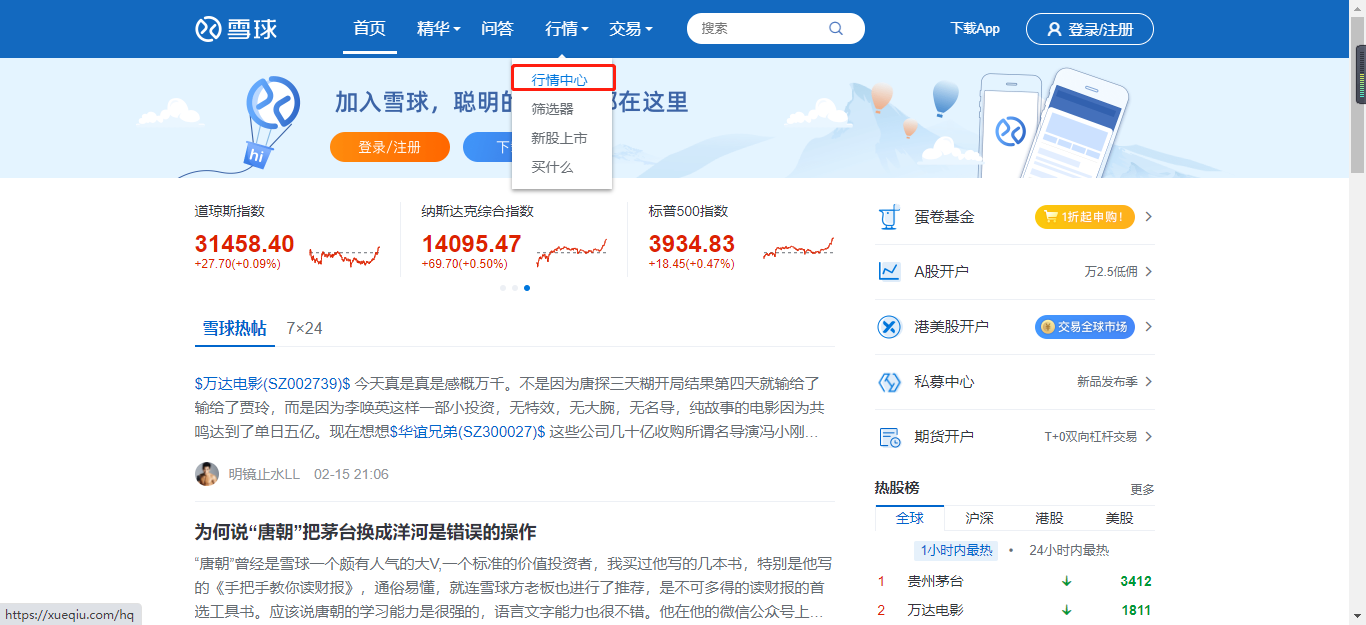
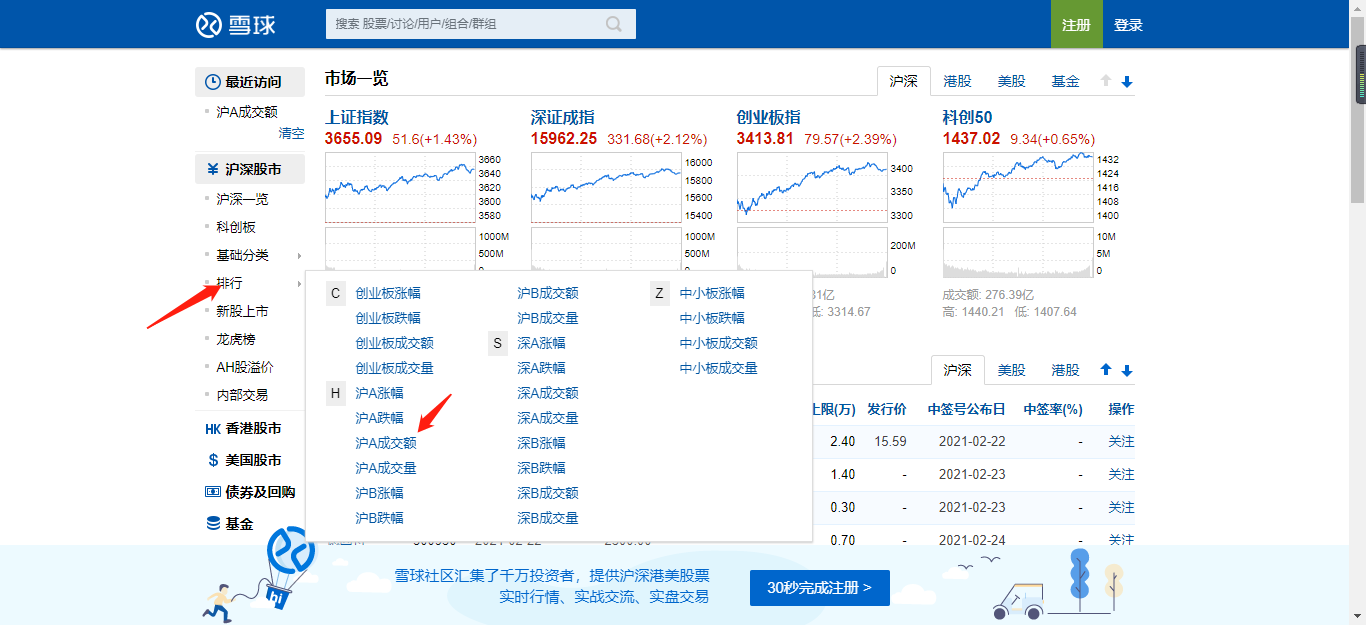
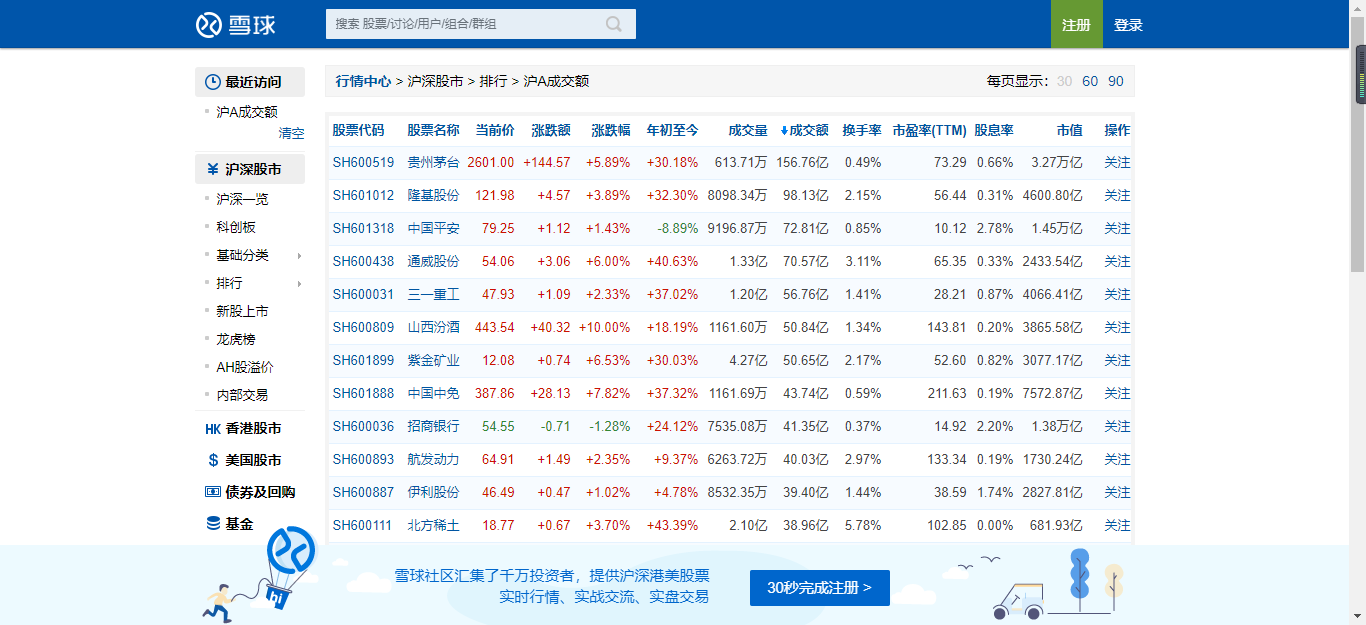
按着上图的顺序依次下来你就会来到我要寻找的数据的位置了。
说句题外话,刚刚打开页面的时候看到茅台的价格这么高,着实吓到了我,虽然我不买股票,但是偶尔也会跟一下基金。现在看来,我还是蛮后悔年前没有买白酒的。
好了,言归正传。现在对该网页进行分析。首先打开开发者工具。如下图所示:
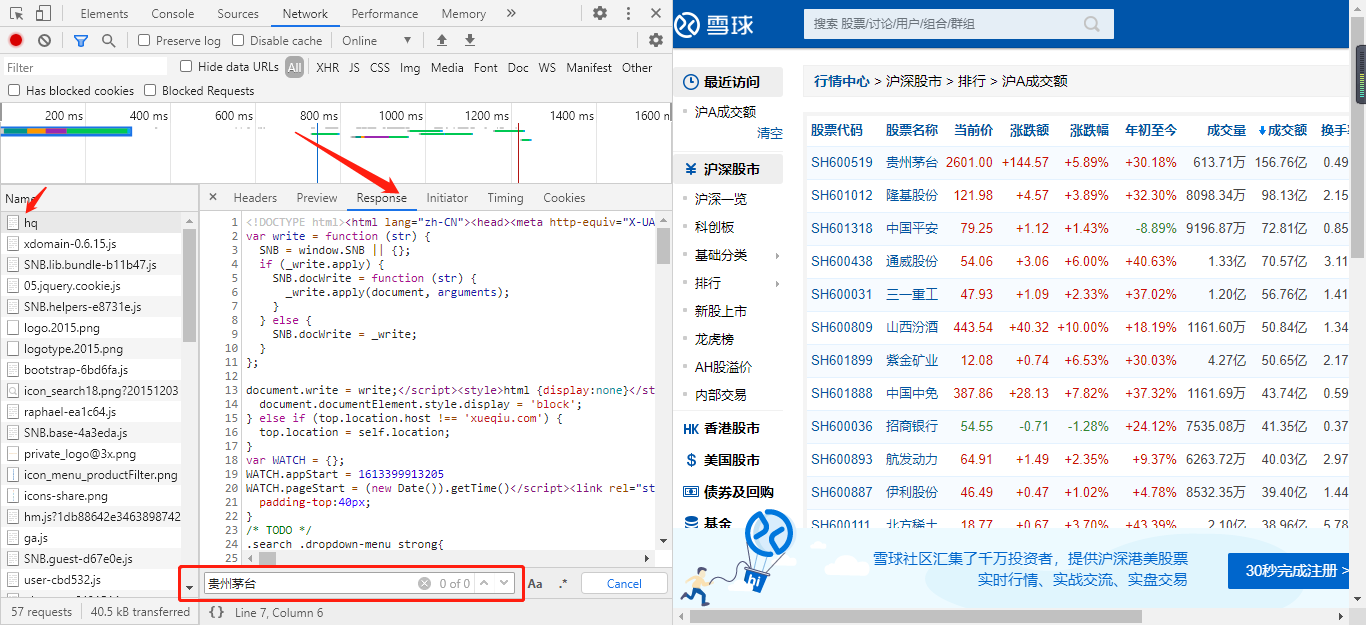
从上图可以看到,数据并不在响应中,所以初步判断,数据是动态加载出来的。
那么接下来可以先点击XHR,再重新刷新页面。结果如下图所示:
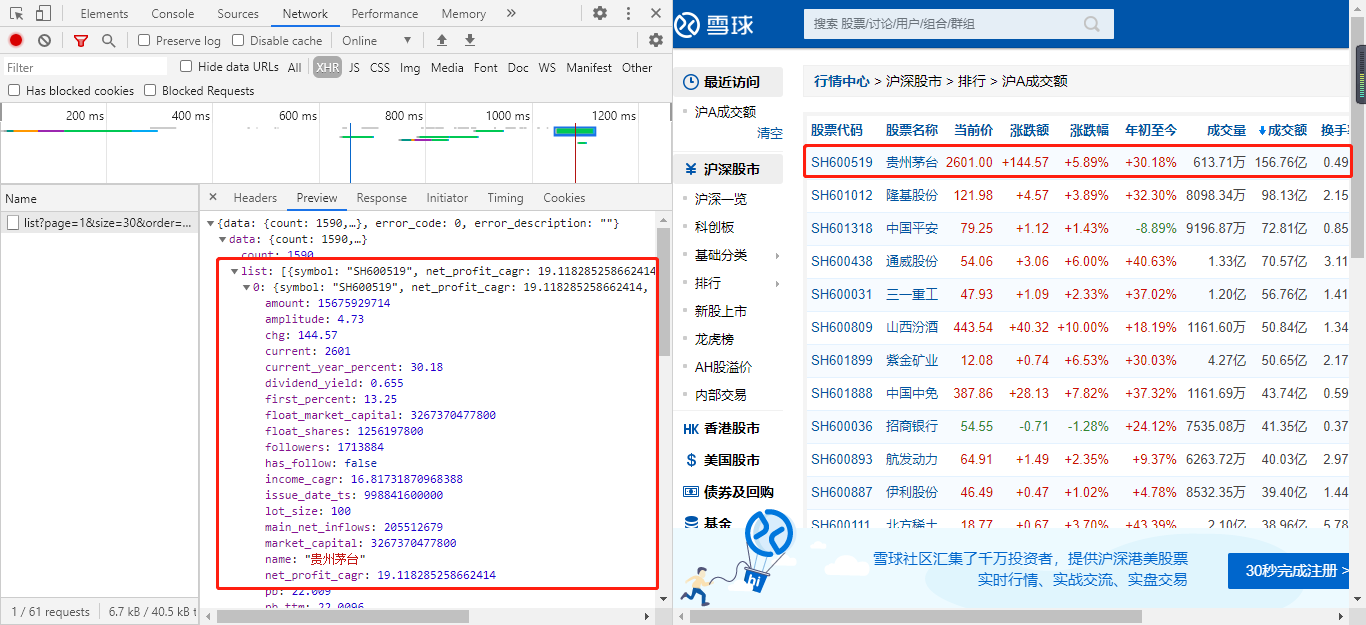
通过上图分析XHR数据,可以精准的确定,该数据就是通过动态加载出来的,并且可以知道数据类型是json。
分析之后,我们也可以发现这个是第一页的数据,接下来依次点击第二页,第三页,它们的URL如下所示:
# 第一页
https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1613400107752
# 第二页
https://xueqiu.com/service/v5/stock/screener/quote/list?page=2&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1613400455501
# 第三页
https://xueqiu.com/service/v5/stock/screener/quote/list?page=3&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1613400541459
通过分析它们的URL地址,不难发现,page值就是代表着每一页。至此,网页基本分析完毕,可以开始写代码了。
获取json数据
向目标网站发送URL请求,获取响应信息。具体代码如下所示:
def get_json(url):
response = requests.get(url, headers=headers)
json_data = response.json()
return json_data
可以将返回值进行打印,运行结果如下所示:
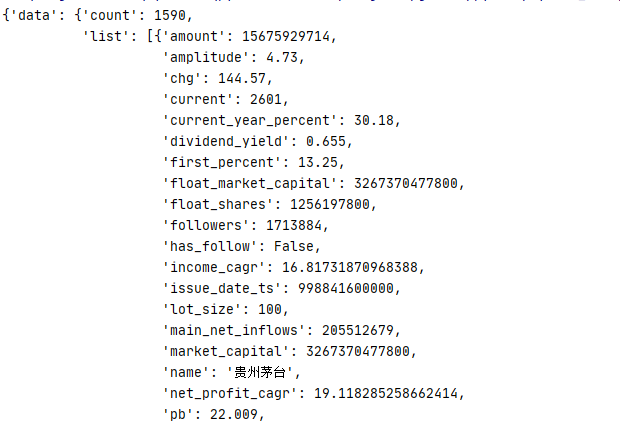
获取数据
我们需要获取的数据主要有以下几点:
- 股票代码
- 股票名称
- 当前价
- 涨跌额
- 涨跌幅
- 年初至今
- 成交量
- 成交额
- 换手率
- 市营率
- 股息率
- 市值
这些数据都是保存在json中,那要获取就不难了,在之前的文章中我也有写过关于获取json数的库jsonpath的讲解,不熟悉的小伙伴可以自己去文章,并学习。
具体代码如下所示:
def get_info(json_data):
# 股票代码
symbol = jsonpath.jsonpath(json_data,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 46万+
46万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









