






目录
前言
我们在序列化和反序列化这一章中,实现了一个网络版的计算器。这个里面设计到了对协议的分析与处理。比如我们应该以约定好的格式发送,然后对方再以特定的方式解析数据。这种双方约定好的格式叫做协议。而实现加减乘除计算的那些逻辑代码,正是我们所说的业务。
我们也发现了制定协议,然后解析协议这些步骤的繁琐。所以已经有大佬帮我们制定好现成的协议了,可以供我们使用和参考。那么http协议顾名思义,也就是对数据的一种解析工作。
认识URL
我们平常所说的“网址”,其实就是url.
URL 是 Uniform Resource Locator 的缩写,中文称为统一资源定位符,它是互联网上标识和定位资源(如网页、图片、视频等)的字符串。URL 用于指定一个资源在互联网上的位置,使用户可以通过浏览器或其他网络工具来访问这个资源。
也就是说,在全球范围内,只要找到它的url就能访问该资源,一个url的组成如下:
协议(Protocol):指定访问资源所使用的协议,如 HTTP、HTTPS、FTP 等。协议通常用于指定客户端与服务器之间的通信规则和方式。
主机名(Host):指定存储资源的计算机的域名或 IP 地址。例如,www.example.com 或 192.168.0.1。其中域名需要解析成先解析成ip地址。域名解析过程需要通过域名系统(DNS)进行,将域名转换为对应的 IP 地址,而 IP 地址可以直接用于网络通信。
端口号(Port):可选项,指定用于访问资源的端口号。如果未指定,默认使用资源所属协议的默认端口。例如,HTTP 默认使用端口号 80,HTTPS 默认使用端口号 443。
路径(Path):指定服务器上资源的路径,用斜杠 “/” 分隔。路径可以是文件的路径或目录的路径。
查询参数(Query Parameters):可选项,提供额外的参数传递给服务器。查询参数以问号 “?” 开头,多个参数之间使用 “&” 分隔。例如,?key1=value1&key2=value2。
片段标识(Fragment Identifier):可选项,用于指定资源中的特定片段。片段标识以井号 “#” 开头,常用于在网页中定位特定的位置。
例如,我们在网站上搜索魔方,然后随便找一张照片,观察此时的地址:
1.协议:可以看到采用的是https协议,具体后面会细讲.
2.主机名:baike.baidu.com,没有指定端口,则默认指定端口为443.
3.路径:剩下的就都是路径了,其中也包括一些参数等。

也就是说一个url格式如下:
协议://server ip:[port] /a/b/c/d
其中server ip来标识唯一的一台机器,port标识该机器上服务的进程,后面/a/b/c/d代表用户想要的文件名。
URLEncode和URLDecode
URLEncode 和 URLDecode 是用于对 URL 中特殊字符进行编码和解码的过程.
URLEncode
URLEncode 是将 URL 中的特殊字符转换为特殊编码表示的过程。在 URL 中,某些字符具有特殊的含义或用途(例如用于分隔协议、主机名、路径等),如果 URL 中包含这些特殊字符,就需要将其进行编码以确保 URL 的正确解析和传输。
编码规则如下:将需要转码的字符转为两位16进制,前面加上%,编码成%XY格式
例如,字符‘+’的ASCII码值是43,现将其转为16进制,为2B,然后我们再它的前面加上%,成为%2B.例如,我们在网站中输入c++:
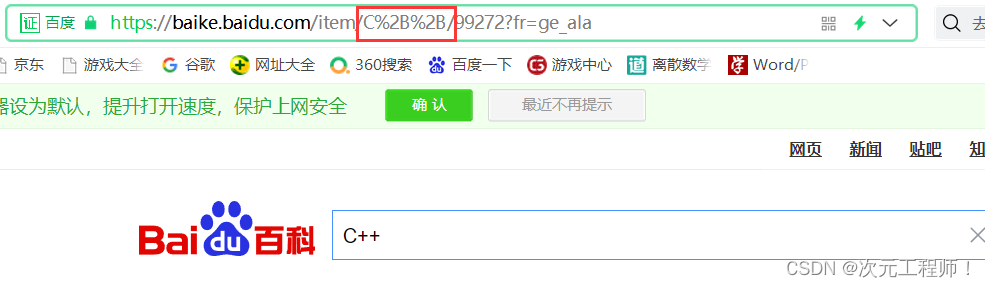
还有空格被转化为“%20”等等,都是按这种规则转化的.
URLDecode
URLDecode 是将 URL 中的特殊编码表示转换为原始字符的过程。当服务器接收到一个 URL 时,如果其中包含编码字符,就需要对这些编码字符进行解码以恢复原始的字符表示。URLDecode 通过将特殊编码表示转换为相应的原始字符来实现。例如,将“%2B”解码为‘+’,“%20” 解码为空格。
http协议格式
http请求和响应的报文格式

单纯的站在请求和响应的报文角度,http是基于行的文本协议.
http请求报头格式:

<方法>:HTTP 请求方法,如 GET、POST、PUT、DELETE 等。<url>:请求的绝对或相对 URL。<HTTP Version>:HTTP 协议版本,如 HTTP/1.1、HTTP/2.0。<Header Key>:报头字段的名称。<Header Value>:报头字段的值。(<Request Body>):可选项,请求正文的内容。
响应的报文格式
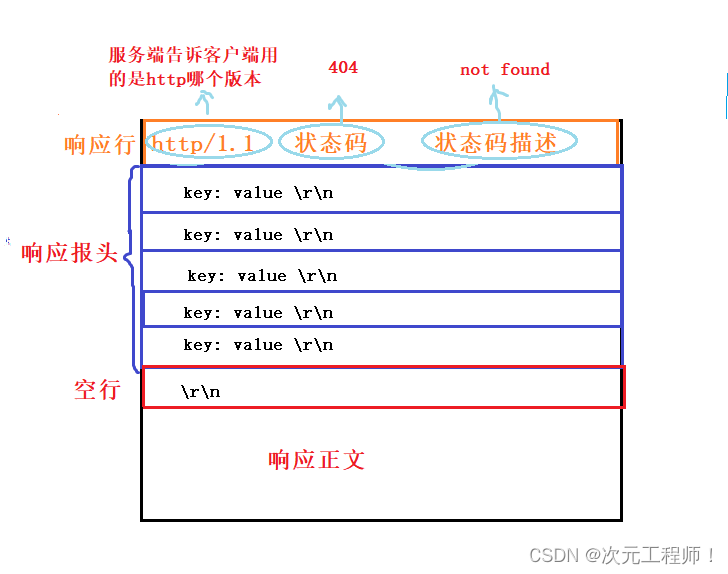
<HTTP Version>:HTTP 协议版本,如 HTTP/1.1、HTTP/2.0。<Status Code>:请求处理的状态码,如 200(成功)、404(未找到)、500(服务器错误)等。<Reason Phrase>:状态码对应的简短说明。<Header Key>:报头字段的名称。<Header Value>:报头字段的值。(<Response Body>):可选项,响应正文的内容。、
首行: [版本号] + [状态码] + [状态码解释]
Header(响应报头): 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
http方法
我们平时上网的这种行为,其实就两种:
- 1.从服务器中拿下来资源
- 2.将客户端数据上传到服务器
这里是所有方法的汇总:
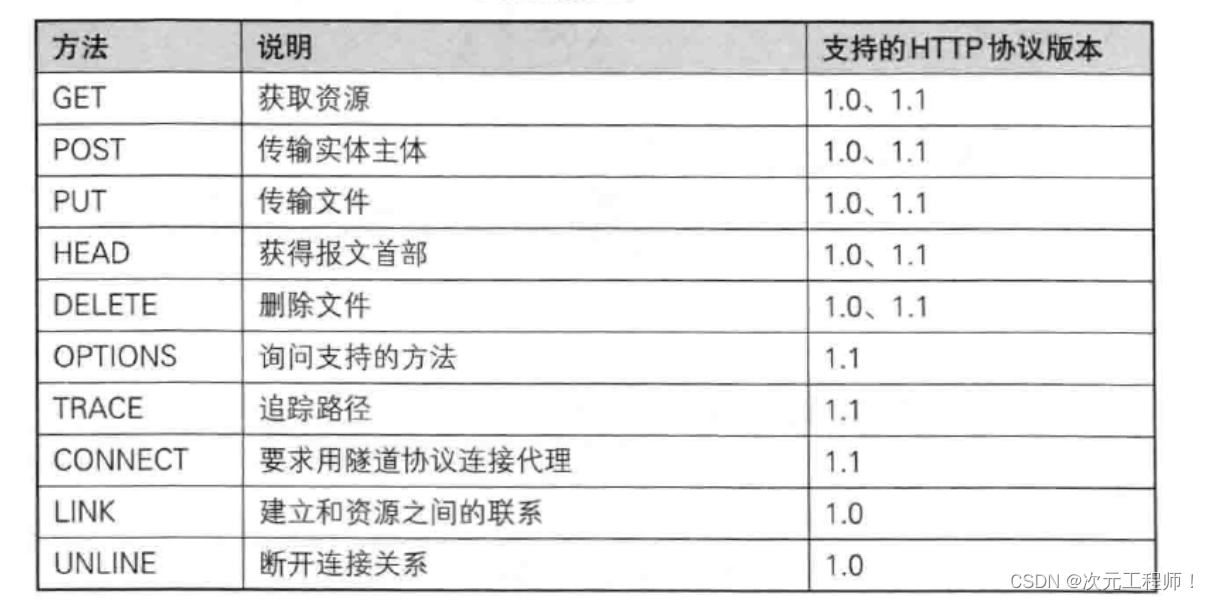
不同的行为有不同的方法。这里主要有两种GET和POST.
GET
GET通过url传参,即会把获取到的数据回显到url上.
我们从网站上获得、请求到的各种资源,大多是GET方法。例如我们想获取百度首页,我们先telnet连接到百度,然后GET:

- GET用于从服务器获取(或检索)资源,通过URL查询字符串传递参数。
- GET请求可以通过在URL中附加参数来传递数据,这些参数以键值对的形式出现,并使用"?“来将URL路径与参数分隔,不同参数之间使用”&"进行分隔。例如(https://blog.csdn.net/weixin_47257473/article/details/132575491?spm=1001.2014.3001.5501会将参数"spm=1001.2014.3001.5501" 传递给/132575491)
- GET请求的参数会显示在URL中,因此对于敏感数据不宜使用GET请求。GET请求通常用于读取数据,如获取网页内容、检索资源等。
- GET请求是幂等的,即多次执行相同的GET请求,服务器的状态和资源都不应该发生变化。(常见的就是我们点击某个按钮没反应,然后我们就点击多次,但最后就只执行了一次。比如登录的时候,点击多次登录按钮,但最后并不会登录多个qq号).
POST
post是通过正文传参,因此url上不会有相关的数据。
- POST用于向服务器提交(或发送)数据,通过请求体(Request Body)传递参数。
- POST请求的参数通过请求头的Content-Type字段和请求体发送,参数不会显示在URL中,并且可以传输更大量的数据。
- POST请求不会在浏览器的历史记录中留下记录,对于敏感数据和数据的修改操作,应该使用POST请求。
- POST请求是非幂等的,即多次执行相同的POST请求,会对服务器的状态和资源进行修改。
GET与POST的区别
GET和POST本质是没有区别的.使用GET的场景可以使用用POST, POST的场景也可以使用GET。
但是在一些细微的地方还是有一些区别:
- GET是通过把客户端的数据通过请求行(query)来传输到服务端,POST会将客户端数据放入到正文部分然后传输。
- GET 习惯上用于客户端从服务器获取数据,而由于是通过query传输数据,所以是明文的;POST 习惯上是客户端向服务器提交数据,是通过正文部分传输,所以不会显示在上方url中.
- GET的请求是幂等的,而POST的请求可以不是幂等的.
- GET 请求可以被缓存,可以被浏览器保存到收藏夹中;POST 请求不能被缓存.
POST从客户端提交表单给服务器,然后服务器返回给客户端结果.
客户端发送GET请求到服务器,服务器把请求的资源同样返回给客户端.
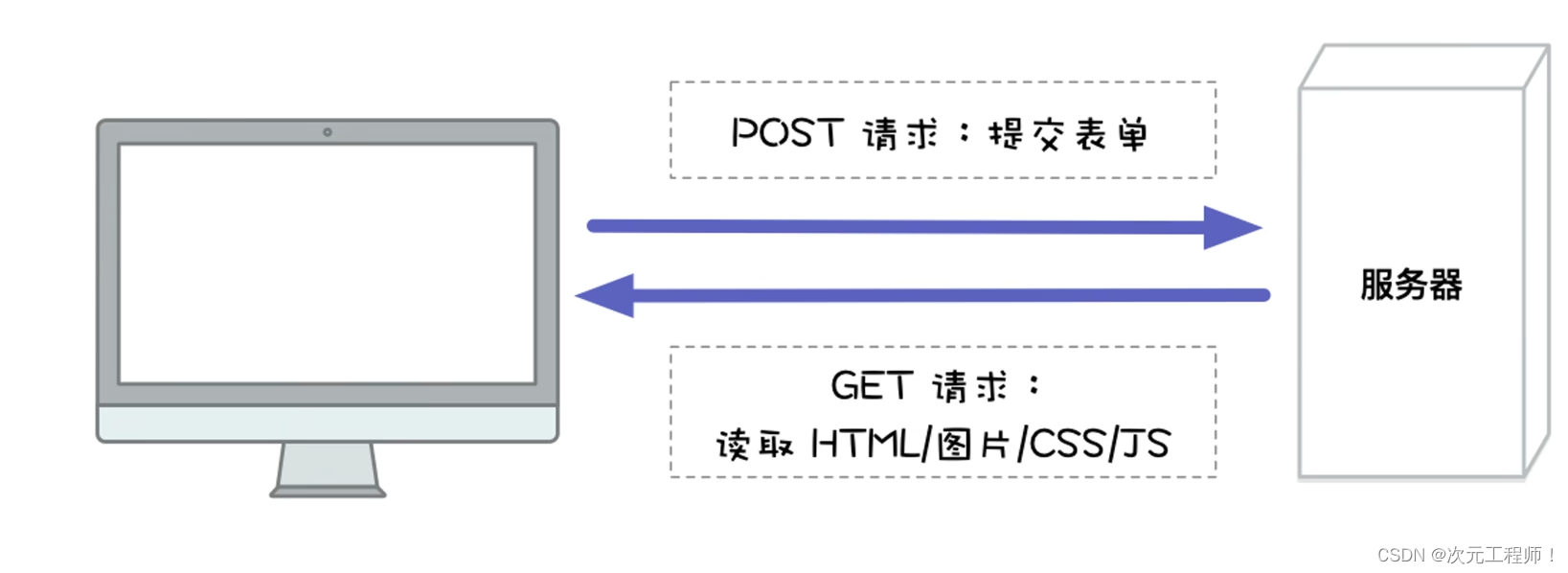
同样有一点需要说明的是,POST并不比GET安全,因为它们的数据都是明文的,没有加密的。GET只不过是把结果显示到了url中,POST的虽然在正文中没有显示出来,但同样可以获取到正文的数据。
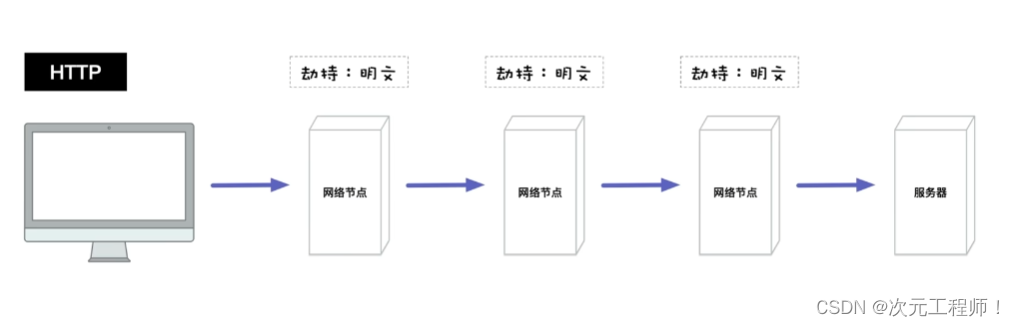
黑客们完全可以在转发的网络节点劫取http请求,然后获得其中的数据,造成我们私密信息的泄露。
http状态码
HTTP状态码是服务器在处理客户端请求时返回的3位数字代码,用于表示请求的处理结果的标准化表示方式。状态码提供了关于请求是否成功、发生了什么错误以及如何处理请求的信息,方便客户端和服务器之间进行通信和理解。
比如我们常见的是404 Not Found.表示服务器没有你请求的资源。
下面是常见的状态码:
1xx:信息性状态码
表示请求已经被接收或正在处理,需要进一步操作或等待,常见的状态码有:
- 100 Continue:接收到请求的初始部分,客户端应继续发送剩余部分。
- 101 Switching Protocols:请求者要求服务器切换协议。
2xx:成功状态码
表示请求已成功处理和接受,常见的状态码有:
- 200 OK:请求成功,返回响应正常。
- 201 Created:请求成功并创建了新的资源。
- 204 No Content:请求成功,但响应没有任何内容。
3xx:重定向状态码
表示请求需要进一步操作以完成请求,常见的状态码有:
- 301 Moved Permanently:请求的资源已永久移动到新位置。
- 302 Found:请求的资源临时移动到其他位置。
- 304 Not Modified:客户端可以使用缓存的版本。
4xx:客户端错误状态码
表示由于客户端的错误或无效请求导致服务器无法处理请求,常见的状态码有:
- 400 Bad Request:请求无效,服务器无法理解。
- 401 Unauthorized:请求需要身份验证。
- 404 Not Found:请求的资源不存在。
5xx:服务器错误状态码
表示由于服务器内部错误导致无法完成请求,常见的状态码有:
- 500 Internal Server Error:服务器遇到了意外的错误,无法完成请求。
- 503 Service Unavailable:服务器当前无法处理请求,通常是由于过载或维护。
总结一张表如下:

http常见header
我们先开启我们的服务端,然后从浏览器中请求服务端,我们看收到的客户端请求:
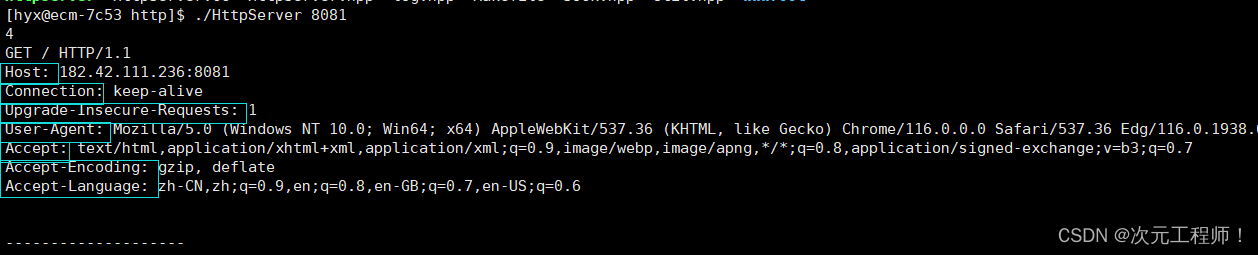
我们可以看到有很多以冒号分割的(key-value)键值对;每组属性之间使用\n分隔;遇到空行结束。
这些便是header上面http协议格式中也提到了。
- Content-Type: 数据类型(text/html等,例如选择text,浏览器则不会解释html语言,而是直接以文本形式显示.)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
我们这里在详细说一下cookie.
我们要知道http特征是:
1.简单快速
2.无连接(连接工作TCP通过三次握手已经帮我们完成了).
3.无状态(即浏览器不知道你是否访问过此界面,但实际我们使用的时候,一般网站会记录我的状态的)
针对于第3点,例如我们需要登录账号才能访问服务。我这次登录后,由于网站没有状态,所以每次进该网站都要登录,会非常的麻烦。所以便有了cookie文件.cookie文件保存了此次用户输入的账号和密码等信息,当用户再次访问该网站时,cookie会自动携带用户的账户和密码发送给服务端,便省去了每次都要登录的步骤。
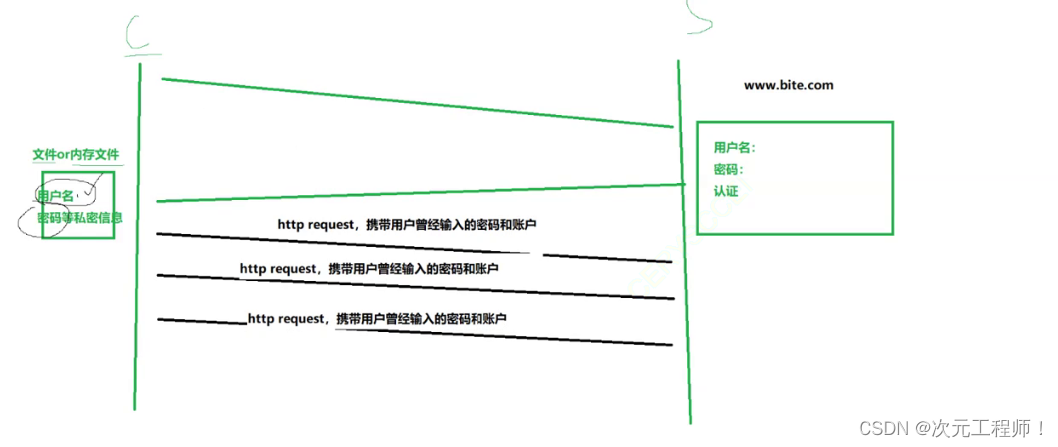
但是如果有黑客在我们电脑的浏览器中注入了一个木马,然后获取到了我们的cookie信息,这样也就把我们的账号和密码就全部获取到了,这是非常危险的。所以为了避免这些,我们在输入用户名和密码的基础上,加上了认证这一步骤。
当我们从客户端输入账号和密码后,服务器端会利用算法生成一个唯一id -- session id,然后把你的账号和密码全部维护在服务器端,然后把这个session id返回给客户端,此时cookie文件中不再保存账号和密码,而是直接保存这个session id,所以后面再访问服务时不再传输账号和密码,而是直接传输这个session id.
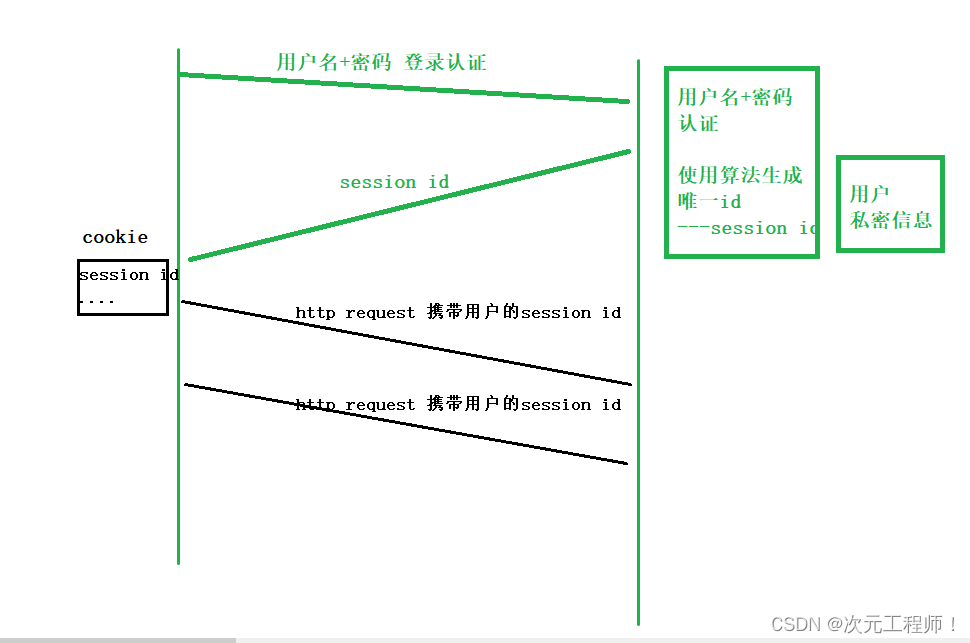
这样就极大程度的保护了用户的个人信息,虽然说黑客还是有一定可能通过这个登录我们的账号,但是我们的个人信息被保护了起来,没有被泄露。而且对应网站也可以采取一些措施,比如如果位置变化很远,服务端便立马让此cookie失效,需要重新输入账号密码。极大程度的保护了我们的隐私安全。
这里便是http协议的全部内容了。
简易的http服务器
这个我们将制作一个简易版的http的demo。我们的目的是当有客户端请求我们的网站时,我们能对这个请求做出响应,并展示请求的结果。
这里我们主要编写服务端,客户端我们使用telnet或者直接网页输入地址进行连接访问即可。
这里共有5个文件,包括Sock.hpp(对socket系列接口的封装)、HttpServer.hpp(服务器的相关接口,主要是包括对服务器的初始化,以及启动等相关操作)、HttpServer.cc(服务器的主逻辑,调用相关接口初始化服务器,并提供一个回调函数即对请求的处理方法HandlerHttpRequest)、Util.hpp(用于对客户端请求字段的切分,服务端提取相关的字段进行处理)、log.hpp(日志文件,只要用于记录相关接口是否被成功调用)。
Sock.hpp
Sock.hpp
这部分前面好几章都已经详细介绍了,代码不变,主要就是对一些接口的封装:
#pragma once #include <iostream> #include <stdlib.h> #include <assert.h> #include <unistd.h> #include <string.h> #include <memory> #include <pthread.h> #include <signal.h> #include <cstring> #include <ctype.h> #include <sys/types.h> #include <sys/wait.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include "log.hpp" using namespace std; class Sock { public: const static int gbacklog = 20; Sock(){} int Socket() { // 1.创建套接字 int listensock = socket(AF_INET, SOCK_STREAM, 0); if (listensock < 0) { logMessage(FATAL, "%d:%s", errno, strerror(errno)); exit(2); } return listensock; } int Bind(int sock, uint16_t port, string ip = "0.0.0.0") { // 2.bind struct sockaddr_in local; memset(&local, 0, sizeof local); local.sin_family = AF_INET;//使用的协议簇为IPv4 local.sin_port = htons(port);//填入端口号 //local.sin_addr.s_addr = ip.empty() ? INADDR_ANY : inet_addr(ip.c_str()); local.sin_addr.s_addr = INADDR_ANY; if (bind(sock, (struct sockaddr *)&local, sizeof local) < 0) { logMessage(FATAL, "bind error", errno, strerror(errno)); exit(3); } } void Listen(int sock) { // 3.因为TCP是面向连接的,意味着当我们正式通信的时候,需要先建立连接 if (listen(sock, gbacklog) < 0) { logMessage(FATAL, "listen error", errno, strerror(errno)); exit(3); } } // const string& 输入型参数 // string* 输出型参数 // string& 输入输出型参数 int Accept(int listensock, string *ip, uint16_t *port) { struct sockaddr_in src; socklen_t len = sizeof src; int servicesock = accept(listensock, (struct sockaddr *)&src, &len); if (servicesock < 0) { logMessage(ERROR, "accept error", errno, strerror(errno)); return -1; } if (port) *port = ntohs(src.sin_port); if (ip) *ip = inet_ntoa(src.sin_addr); return servicesock; } bool Conncect(int sock,string server_ip, uint16_t server_port) { struct sockaddr_in server; memset(&server,0,sizeof(server)); server.sin_family = AF_INET; server.sin_port = htons(server_port); server.sin_addr.s_addr=inet_addr(server_ip.c_str()); // cout << server.sin_port << " " << server.sin_addr.s_addr << endl; if(connect(sock,(struct sockaddr*)&server,sizeof server) == 0) return true; else {perror("connect"); return false; } } ~Sock() { } };
HttpServer.hpp
该服务器类有四个成员变量,分别是listensock_,表示监听的套接字;port_,表示该服务器开放的端口号;Sock类的sock_,用于后续调用相关的socket的接口;func_,表示调用的方法。
#pragma once #include <iostream> #include <unistd.h> #include <signal.h> #include <functional> #include <sys/types.h> #include <string> #include "Sock.hpp" class HttpServer { public: using func_t = function<void(int)>; private: int listensock_;//监听的套接字 uint16_t port_;//端口号 Sock sock; func_t func_; public: HttpServer(const uint16_t& port,func_t func):port_(port),func_(func) { listensock_ = sock.Socket(); sock.Bind(listensock_,port_); sock.Listen(listensock_); } void Start() { for(;;) { signal(SIGCHLD,SIG_IGN); string clientIp; uint16_t clientPort; int sockfd = sock.Accept(listensock_,&clientIp,&clientPort); cout << sockfd << endl; if(sockfd < 0) { cout << "Accept Error" << endl; continue; } if(fork() == 0) { func_(sockfd); exit(1); } close(sockfd); } } ~HttpServer() { if(listensock_ >= 0) { close(listensock_); } } };
HttpServer.cc
main函数主要是初始化和启动服务器。
然后我们使用的方法是HandlerHttpRequest,该函数如下实现:
先将客户端的请求数据读取到自定义的缓冲,然后对请求到的数据进行切分。
首先由于http协议格式是基于行的文本协议,所以我们可以先按行切分成每段,存放到vector中,然后对第一行进行按空格解析,第一行是 方法 url 协议版本.
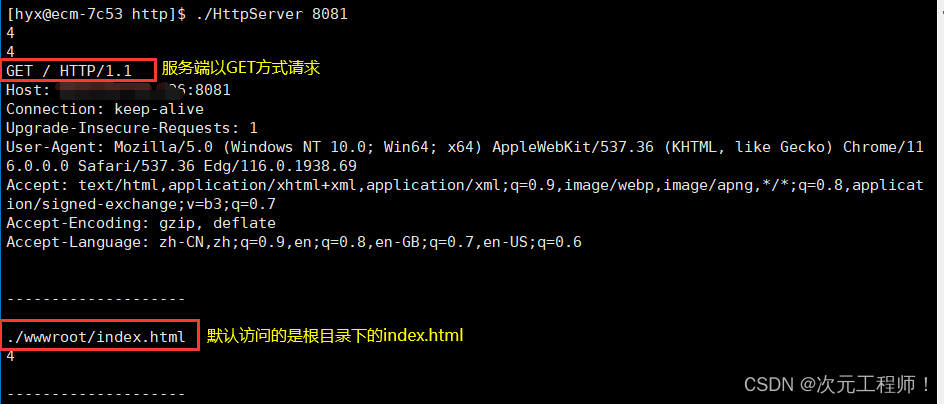
我们接下来要对解析出来的url进行分析。我们要知道,根目录在url地址中默认不显示。当我们访问一个网站时,实则是访问的是根目录,默认访问的是根目录中的index.html。
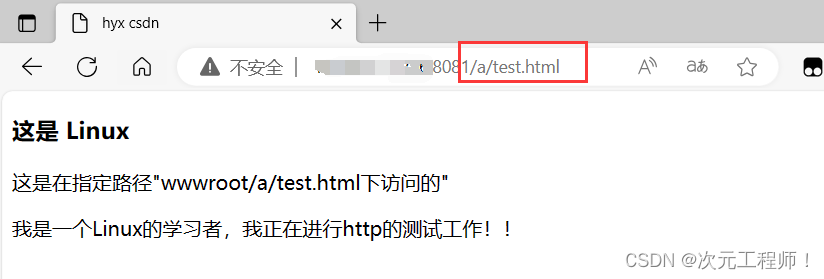
假设我们创建一个根目录是wwwroot,然后在里面再创建一个子目录a,再在a目录中创建一个test.html。这样假设我们要访问test.html时,需要在端口号后面加上/a/index.html.
然后我们构建一个string 响应,先在开头加上"HTTP/1.1 200 OK\r\n" 表示访问成功,然后加上刚才文件的路径,构成一个完整的响应然后send发送给客户端。
代码如下:
#include <iostream> #include <stdio.h> #include <memory> #include <fstream> #include <assert.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include "HttpServer.hpp" #include "Util.hpp" // 一般http都有要自己的web根目录 #define ROOT "./wwwroot" // 如果客户端只请求了一个/,我们默认返回首页 #define HOMEPAGE "index.html" using namespace std; void Usage(string proc) { cout << "\nUsage: " << " port\n" << endl; } void HandlerHttpRequest(int sockfd) { // 1. 读取请求 for test char buffer[10240]; ssize_t s = recv(sockfd, buffer, sizeof(buffer) - 1, 0); if (s > 0) { buffer[s] = 0; } std::cout << buffer << "\n--------------------\n" << std::endl; std::vector<std::string> vline; Util::cutString(buffer, "\n", &vline); std::vector<std::string> vblock; Util::cutString(vline[0], " ", &vblock); std::string file = vblock[1]; std::string target = ROOT; if(file == "/") file = "/index.html"; // wwwroot/index.html target += file; std::cout << target << std::endl; std::string content; std::ifstream in(target); if(in.is_open()) { std::string line; while(std::getline(in, line)) { content += line; } in.close(); } std::string HttpResponse; HttpResponse = "HTTP/1.1 200 OK\r\n"; HttpResponse += "\r\n"; HttpResponse += content; // 2. 试着构建一个http的响应 send(sockfd, HttpResponse.c_str(), HttpResponse.size(), 0); } int main(int argc, char *argv[]) { if (argc != 2) { Usage(argv[0]); exit(0); } std::unique_ptr<HttpServer> httpserver(new HttpServer(atoi(argv[1]), HandlerHttpRequest)); httpserver->Start(); return 0; }
Util.hpp
这个文件作用主要是对字符串 按照 指定的字符进行划分。
首先使用find函数,查找指定的字符,得到该字符的下标,然后利用substr得到这一段字符串,然后后面循环如此进行,便把字符串按照指定的字符分隔开了。
#pragma once #include <iostream> #include <vector> #include <string> class Util { public: // aaaa\r\nbbbbb\r\nccc\r\n\r\n static void cutString(std::string s, const std::string &sep, std::vector<std::string> *out) { std::size_t start = 0; while (start < s.size()) { auto pos = s.find(sep, start); if (pos == std::string::npos) break; std::string sub = s.substr(start, pos - start); // std::cout << "----" << sub << std::endl; out->push_back(sub); start += sub.size(); start += sep.size(); } if(start < s.size()) out->push_back(s.substr(start)); } };
还有最后一个日志log.hpp,这个写不写无所谓了,大家可以把上面有关logMessage的去掉即可,或改成if判断也可。
最终效果,我们运行起服务器:

然后我们利用网页访问8081这个端口:
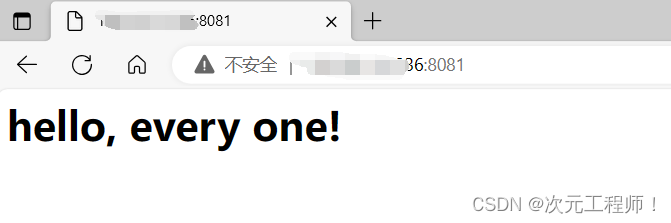
便可以看到已经请求到了,我们看看服务端,客户端发送的请求:
或者我们可以访问指定路径下的资源:
这样便完成了一个简单版的http服务器的编写了。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











