







点滴积累
一、Python标准库
1.1 标准库——glob
功能:文件名模式匹配,不用遍历整个目录判断每个文件是不是符合。
用法:它可以查找符合特定规则的文件路径名。查找文件只用到三个匹配符:“ * ”,“ ?”,“ [ ] ”。
其中:“ * ”:匹配0个或多个字符;“ ?”:匹配单个字符;“ [ ] ”:匹配指定范围内的字符,如:[0-9]匹配数字。
用法示例:
我的目录结构:
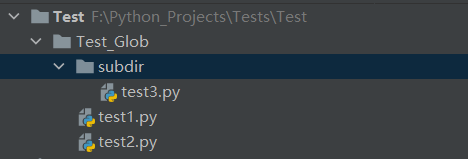
“ * ”:匹配0个或多个字符
import glob
for name in glob.glob('*'):
print(name)
subdir
test1.py
test2.py
列出子目录中的文件,必须在模式中包括子目录名:
import glob
# 用子目录查询文件
print('Named explicitly:')
for name in glob.glob('subdir/*'):
print('\t', name)
# 用通配符* 代替子目录名
print('Named with wildcard:')
for name in glob.glob('*/*'):
print('\t', name)
Named explicitly:
subdir\test3.py
Named with wildcard:
subdir\test3.py
“ ?”:匹配单个字符
import glob
for name in glob.glob('test?.py'):
print(name)
print("--------------------")
for name in glob.glob('subdir/test?.py'):
print(name)
test1.py
test2.py
--------------------
subdir\test3.py
“ [ ] ”:匹配指定范围内的字符
import glob
for name in glob.glob('*.*'):
print(name)
print("--------------")
for name in glob.glob('*[1].*'):
print(name)
print("--------------")
for name in glob.glob('*[1-2].*'):
print(name)
test1.py
test2.py
--------------
test1.py
--------------
test1.py
test2.py
1.2 标准库——os
功能:os.path模块主要用于文件的属性获取
os.path.abspath(path) #返回绝对路径
os.path.basename(path) #返回文件名
os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径。
os.path.dirname(path) #返回文件路径
os.path.exists(path) #路径存在则返回True,路径损坏返回False
os.path.lexists #路径存在则返回True,路径损坏也返回True
os.path.expanduser(path) #把path中包含的""和"user"转换成用户目录
os.path.expandvars(path) #根据环境变量的值替换path中包含的” n a m e ” 和 ” name”和” name”和”{name}”
os.path.getatime(path) #返回最后一次进入此path的时间。
os.path.getmtime(path) #返回在此path下最后一次修改的时间。
os.path.getctime(path) #返回path的大小
os.path.getsize(path) #返回文件大小,如果文件不存在就返回错误
os.path.isabs(path) #判断是否为绝对路径
os.path.isfile(path) #判断路径是否为文件
os.path.isdir(path) #判断路径是否为目录
os.path.islink(path) #判断路径是否为链接
os.path.ismount(path) #判断路径是否为挂载点()
os.path.join(path1[, path2[, …]]) #把目录和文件名合成一个路径
os.path.normcase(path) #转换path的大小写和斜杠
os.path.normpath(path) #规范path字符串形式
os.path.realpath(path) #返回path的真实路径
os.path.relpath(path[, start]) #从start开始计算相对路径
os.path.samefile(path1, path2) #判断目录或文件是否相同
os.path.sameopenfile(fp1, fp2) #判断fp1和fp2是否指向同一文件
os.path.samestat(stat1, stat2) #判断stat tuple stat1和stat2是否指向同一个文件
os.path.split(path) #把路径分割成dirname和basename,返回一个元组
os.path.splitdrive(path) #一般用在windows下,返回驱动器名和路径组成的元组
os.path.splitext(path) #分割路径,返回路径名和文件扩展名的元组
os.path.splitunc(path) #把路径分割为加载点与文件
os.path.walk(path, visit, arg) #遍历path,进入每个目录都调用visit函数,visit函数必须有3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有文件名,args则为walk的第三个参数
os.path.supports_unicode_filenames #设置是否支持unicode路径名
1.3 标准库——json
JSON介绍
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它是JavaScript的子集,易于人阅读和编写。
前端和后端进行数据交互,其实就是JS和Python进行数据交互
JSON注意事项:
(1)名称必须用双引号(即:””)来包括
(2)值可以是双引号包括的字符串、数字、true、false、null、JavaScript数组,或子对象。
python数据类型与json数据类型的映射关系
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str, unicode | string |
| int, long, float | number |
| True | true |
| False | false |
| None | null |
json中常用的方法
在使用json这个模块前,首先要导入json库:import json
| 方法 | 描述 |
|---|---|
| json.dumps() | 将 Python 对象编码成 JSON 字符串 |
| json.loads() | 将已编码的 JSON 字符串解码为 Python 对象 |
| json.dump() | 将Python内置类型序列化为json对象后写入文件 |
| json.load() | 读取文件中json形式的字符串元素转化为Python类型 |
常用方法示例:
json.dumps()
import json
data ={'name':'pengyuan','age':18}
# 将 Python 对象编码成 JSON 字符串
print(json.dumps(data))
{"name": "pengyuan", "age": 18}
注: 在这里我们可以看到,原先的单引号已经变成双引号了
json.loads()
import json
data ={'name':'pengyuan','age':18}
# 将已编码的 JSON 字符串解码为 Python 对象
a=json.dumps(data)# 此时的a为一个JSON字符串
print(json.loads(a))# 此时的a为一个JSON对象
{'name': 'pengyuan', 'age': 18}
在这里举个元组和列表的例子:
import json
data = (1,2,3,4)
data_json = [1,2,3,4]
print(data)
print(data_json)
print("---------")
# 将Python对象编码成json字符串
print(json.dumps(data))
print(json.dumps(data_json))
print("---------")
# 将json字符串编码成Python对象
a = json.dumps(data)
b = json.dumps(data_json)
print(json.loads(a))
print(json.loads(b))
(1, 2, 3, 4)
[1, 2, 3, 4]
---------
[1, 2, 3, 4]
[1, 2, 3, 4]
---------
[1, 2, 3, 4]
[1, 2, 3, 4]
可以看到,元组和列表解析出来的均是数组.
json.dump()
import json
data = {
'nanbei':'haha',
'a':[1,2,3,4],
'b':(1,2,3)
}
# dump()将Python内置类型序列化为json对象后写入文件
with open('json_test.txt','w+') as f:
json.dump(data,f)

json.load()
import json
data = {
'nanbei':'haha',
'a':[1,2,3,4],
'b':(1,2,3)
}
# dump()将Python内置类型序列化为json对象后写入文件
with open('json_test.txt','w+') as f:
json.dump(data,f)
# load()读取文件中json形式的字符串元素转化为Python类型
with open('json_test.txt','r+') as f:
print(json.load(f))
{'nanbei': 'haha', 'a': [1, 2, 3, 4], 'b': [1, 2, 3]}
1.4 标准库——numpy
二、Python中的map()函数与lambda()函数
2.1 map()函数
用法:map(function, iterable, …)
参数function: 传的是一个函数名,可以是python内置的,也可以是自定义的。
参数iterable: 传的是一个可以迭代的对象,例如列表,元组,字符串…
功能: 将iterable中的每一个元素执行一遍function
例子一:
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:
def f(x):
return x*x
print(list(map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]))) # Python中map无法直接显示,需要加list
结果为: [1, 4, 9, 16, 25, 36, 49, 64, 81]
例子二:
首字母大写,其余小写
输入:[‘adam’, ‘LISA’, ‘barT’]
#1.利用---->切片和字符串拼接
def format_name(s):
return s[0].upper() + s[1:].lower()
print(list(map(format_name, ['adam', 'LISA', 'barT'])))
#2.为了增强可读性:
def format_name(s):
return s[0].upper() + s[1:].lower()
L1 = ['adam', 'LISA', 'barT']
L2 = list(map(format_name, L1))
print(L2)
结果为: [‘Adam’, ‘Lisa’, ‘Bart’]
2.2 lambda()函数
lambda函数是Python的内置函数,其功能主要是实现匿名函数的目的。
匿名函数的优点就是简洁、轻量化。匿名函数无需起名,用完即可被回收,节约资源。
lambda函数的形式为:
(单参数)lambda x:x*2,(多参数)lambda x,y : x+y其中,冒号左边的x、y为参数,冒号右边的为函数体
例子一:
求两列表之和
def add_list(x, y):
return x + y
list_num1 = [1, 2, 3, 0, 8, 0, 3]
list_num2 = [1, 2, 3, 4, 6.6, 0, 9]
print(list(map(add_list, list_num1, list_num2)))
结果为: [2, 4, 6, 4, 14.6, 0, 12]
用lambda与map处理之后有:
list_num1 = [1, 2, 3, 0, 8, 0, 3]
list_num2 = [1, 2, 3, 4, 6.6, 0, 9]
print(list(map(lambda x, y: x+y, list_num1, list_num2)))
结果为: [2, 4, 6, 4, 14.6, 0, 12]














 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









