








html模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>网页</title>
<style>
*{
margin: 0;
padding: 0;
}
#a1{
width: 30%;
height: 499px;
float: left;
background-color: red;
}
#a2{
width: 40%;
height: 400px;
float: left;
padding: 100px 0 0;
background-color: red;
}
#a3{
width: 30%;
height: 499px;
float: left;
background: orange;
}
#a21{
width: 100%;
font-size: 40px;
line-height: 200px;
text-align: center;
height: 200px;
display: inline-block;
background-color: yellow;
}
#a22{
width: 100%;
font-size: 40px;
line-height: 200px;
text-align: center;
height: 200px;
display: inline-block;
background-color: orange;
}
body{
text-align: center;
}
#a31{
font-size: 70px;
font-weight: bold;
margin: 10px;
}
</style>
</head>
<body>
<div id="a1">
</div>
<div id="a2">
<h3 id="a21">
09 : 07 : 89
</h3>
<h3 id="a22">
06 : 06 : 86
</h3>
</div>
<div id="a3">
<button id="a31">改变样式的按钮</button>
</div>
<script>
window.onload=function(){
document.getElementById('a31').onclick=changestyle;
}
function changestyle(){
var a3=document.getElementById("a3");
var a2=document.getElementById("a2");
var a1=document.getElementById("a1");
a1.style.backgroundColor='black';
a2.style.backgroundColor='pink';
a3.style.backgroundColor='green';
}
</script>
</body>
</html>创建两个正则表达式;分别匹配style和script
使用fs模块,读取需要处理的文件
自定义css方法:拆分css写入css文件
自定义js方法:拆分js写入js文件
自定义html方法:拆分html写入html文件
使用 \ 转义字符,使用\S表示非空白字符 ;*表示匹配任意次 \s表示空白字符----------------即正则
[\s\S]*
// <style>............</style>----------------如何匹配style
// <script>............</script>---------------如何匹配script
const css=/<style>[\s\S]*<\/style>/
const js=/<script>[\S\s]*<\/script>/
使用文件模块 读取文件
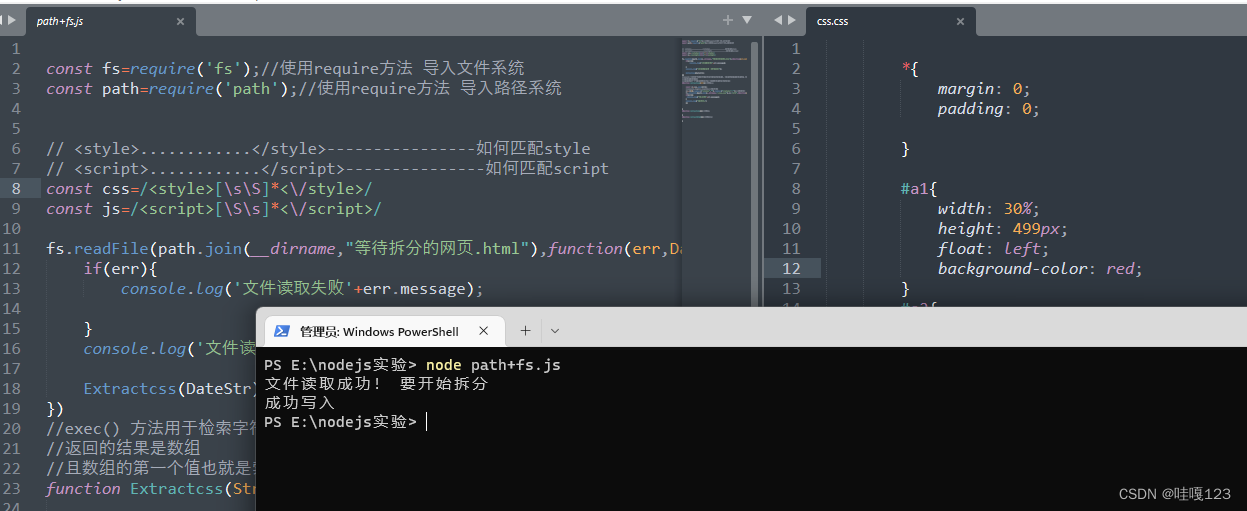
const fs=require('fs');//使用require方法 导入文件系统
const path=require('path');//使用require方法 导入路径系统
fs.readFile(path.join(__dirname,"等待拆分的网页.html"),function(err,DateStr){
if(err){
console.log('文件读取失败'+err.message);
}
console.log('文件读取成功! 要开始拆分');
Extractcss(DateStr);//拆分的函数
})开始进行拆分的函数————用到了exec函数进行字符串正则的提取 使用索引来拿+replace字符串的替换——替换两次--------------替换css部分
const fs=require('fs');//使用require方法 导入文件系统
const path=require('path');//使用require方法 导入路径系统
// <style>............</style>----------------如何匹配style
// <script>............</script>---------------如何匹配script
const css=/<style>[\s\S]*<\/style>/
const js=/<script>[\S\s]*<\/script>/
fs.readFile(path.join(__dirname,"等待拆分的网页.html"),function(err,DateStr){
if(err){
console.log('文件读取失败'+err.message);
}
console.log('文件读取成功! 要开始拆分');
Extractcss(DateStr);
})
//exec() 方法用于检索字符串中的正则表达式的匹配。 有匹配的值返回该匹配值,否则返回 null。
//返回的结果是数组
//且数组的第一个值也就是索引为0 的值是所匹配的正则的内容
function Extractcss(Str){//提取css
const c1=css.exec(Str);
//console.log(c1.length);//测试代码
c2=c1[0].replace('<style>','').replace('</style>','');//替换两次
fs.writeFile(path.join(__dirname,'./css.css'),c2,'utf8',function(err){
if(err){
console.log('写入失败'+err.message);
}
console.log("成功写入")
})
}
function Extractcjs(){//提取js
}
function Extracthtml(){//提取html
}
开始进行拆分的函数————用到了exec函数进行字符串正则的提取 使用索引来拿+replace字符串的替换——替换两次--------------替换js部分
function Extractcjs(Str){//提取js
const j1=js.exec(Str);
//console.log(c1.length);//测试代码
j2=j1[0].replace('<script>','').replace('</script>','');//替换两次
fs.writeFile(path.join(__dirname,'./js.js'),j2,'utf8',function(err){
if(err){
console.log('写入失败'+err.message);
}
console.log("成功写入")
})
}
开始进行拆分完整的HTML代码————replace字符串的替换script-+style---变成link script——替换两次---------将那些内嵌的变成外嵌的----------使用正则匹配--两次replcae
//因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
用到了buffer转字符串Str.toString();
function Extracthtml(Str){//提取html
//因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
var str=Str.toString();//将其用itf-8转换成字符串
//console.log(str);//测试
const html=str.replace(css,'<link rel="stylesheet" href="./css.css">').replace(js,'<script src="./js.js" ></script>');
fs.writeFile(path.join(__dirname,'./index.html'),html,'utf8',function(err){
if(err){
console.log('写入失败'+err.message);
}
console.log("成功写入")
})
}
全部代码
const fs=require('fs');//使用require方法 导入文件系统
const path=require('path');//使用require方法 导入路径系统
// <style>............</style>----------------如何匹配style
// <script>............</script>---------------如何匹配script
const css=/<style>[\s\S]*<\/style>/
const js=/<script>[\S\s]*<\/script>/
fs.readFile(path.join(__dirname,"等待拆分的网页.html"),function(err,DateStr){
if(err){
console.log('文件读取失败'+err.message);
}
console.log('文件读取成功! 要开始拆分');
Extractcss(DateStr);
Extractcjs(DateStr);
Extracthtml(DateStr);
})
//exec() 方法用于检索字符串中的正则表达式的匹配。 有匹配的值返回该匹配值,否则返回 null。
//返回的结果是数组
//且数组的第一个值也就是索引为0 的值是所匹配的正则的内容
function Extractcss(Str){//提取css
const c1=css.exec(Str);
//console.log(c1.length);//测试代码
c2=c1[0].replace('<style>','').replace('</style>','');//替换两次
fs.writeFile(path.join(__dirname,'./css.css'),c2,'utf8',function(err){
if(err){
console.log('写入失败'+err.message);
}
console.log("成功写入")
})
}
function Extractcjs(Str){//提取js
const j1=js.exec(Str);
//console.log(c1.length);//测试代码
j2=j1[0].replace('<script>','').replace('</script>','');//替换两次
fs.writeFile(path.join(__dirname,'./js.js'),j2,'utf8',function(err){
if(err){
console.log('写入失败'+err.message);
}
console.log("成功写入")
})
}
function Extracthtml(Str){//提取html
//因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
var str=Str.toString();//将其用itf-8转换成字符串
//console.log(str);//测试
const html=str.replace(css,'<link rel="stylesheet" href="./css.css">').replace(js,'<script src="./js.js" ></script>');
fs.writeFile(path.join(__dirname,'./index.html'),html,'utf8',function(err){
if(err){
console.log('写入失败'+err.message);
}
console.log("成功写入")
})
}执行
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









