







排序
时间复杂度先不展开讲,等到了实际的算法中,再慢慢的分析,这样就懂了.
排序分类
排序其实是一种算法,分为内部排序和外部排序,所谓内部排序是指在内存中进行排序,外部排序则需要借助一些外部的空间进行排序,比如磁盘文件.
我们一般学习的是内部排序,面试问的最多的也是内部排序.
内部排序的顺序图: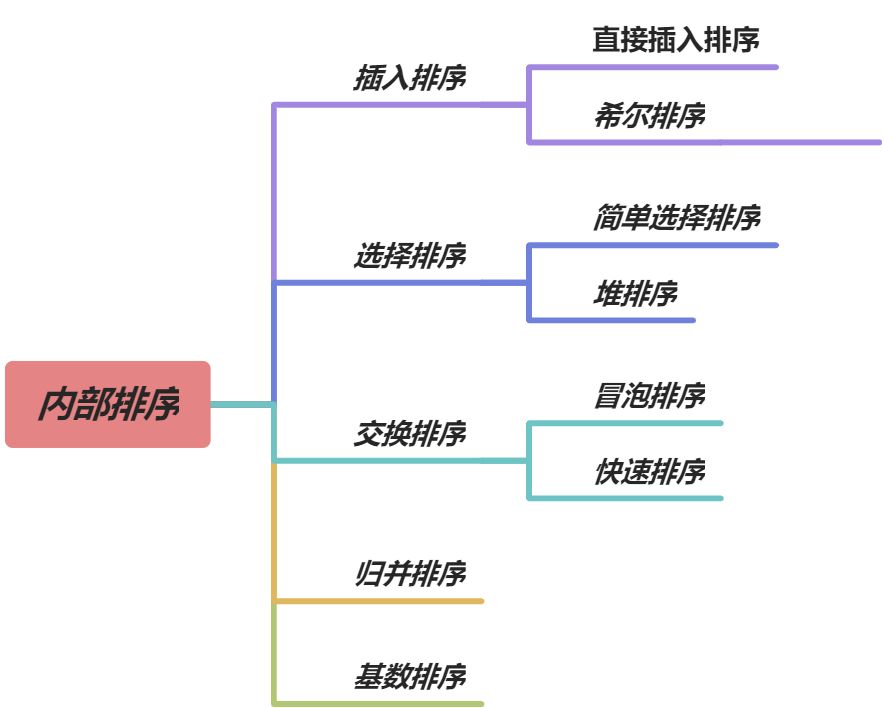
时间复杂度表:
时间的平均复杂度越低,性能整体上越好.比如o(n2)和o(nlogn),如果你知道这两个曲线的雏形就会了解,当n越大,n2就会便会变化得很快,而且是往大的方向增长.而后者的logn就不一样了,n越大,值会趋于平缓,时间复杂度趋于平缓(不是没有增长),且肯定没有n^2大,所以当n变大的时候,性能的优越性logn便更能体现出来.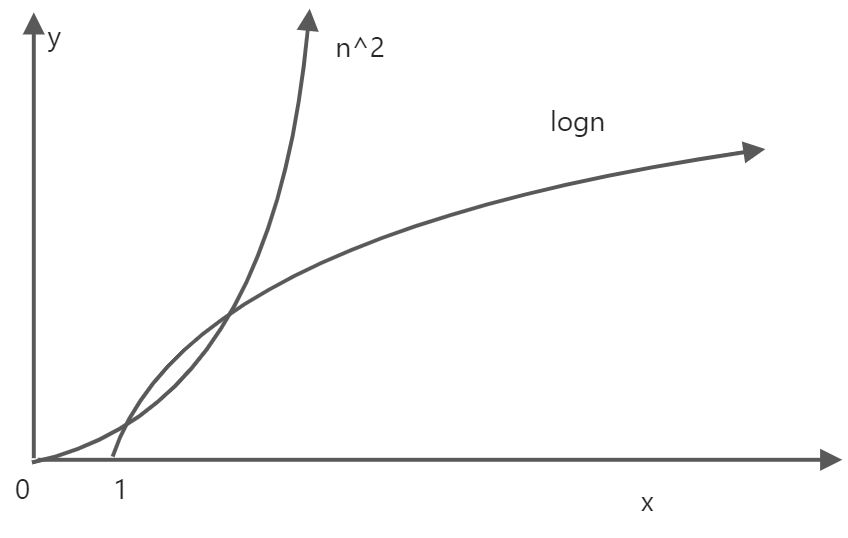
冒泡排序
分析
闻如其名,冒泡,就是规定将大的值给排到最后,下一次冒泡就去掉上一次冒泡的值,这样每一次都取出本次冒泡的最大值,就是排序的一系列值了.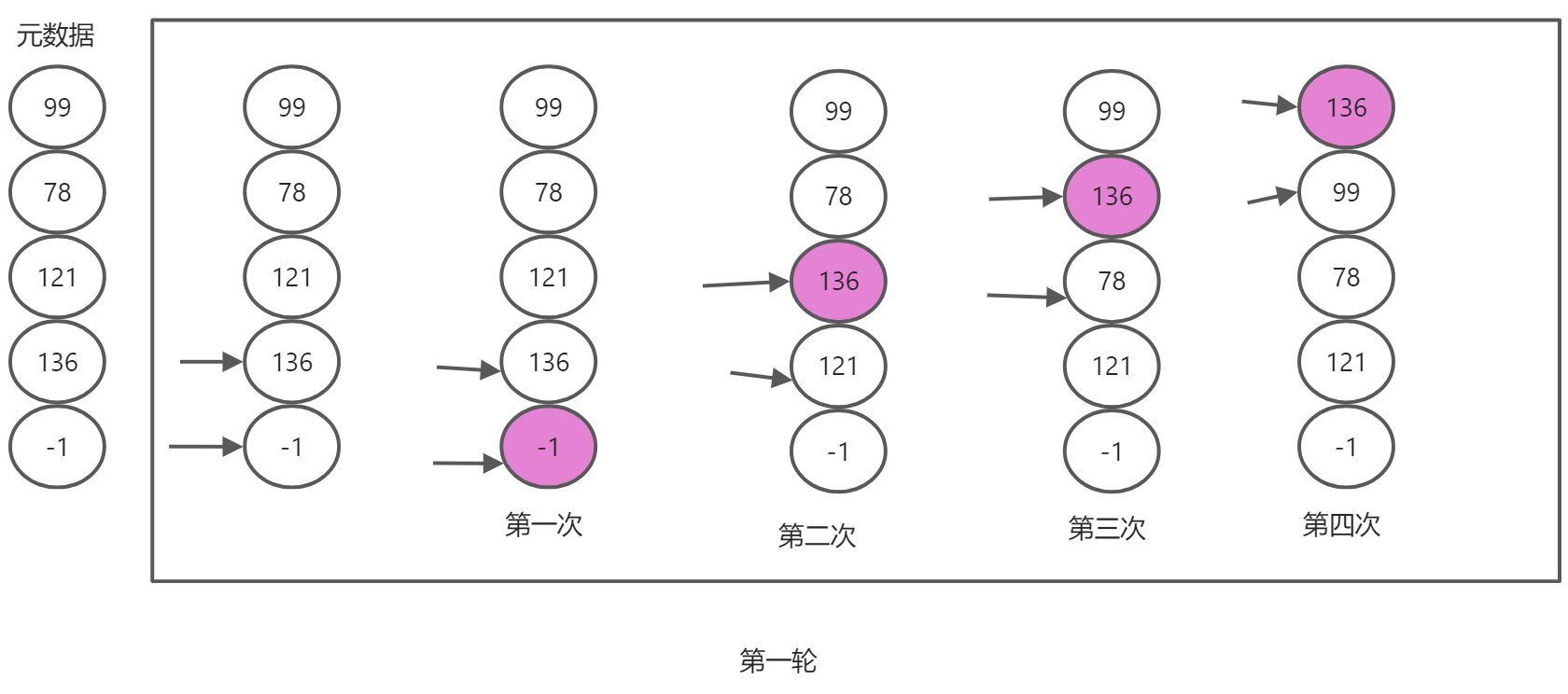
我们先分析它是如何冒泡出最大值的,首先拿到元数据,然后从下面分析,-1<136,理论上冒泡,但是我们按照大的往上冒,所以-1不动.第二次比较136>121,将136往上冒,第三次比较136>78大,继续往上冒,第四次比较136>99,继续往上冒.然后136没得比较了,就是本次冒泡最大的.
那为什么要多次冒泡?因为我们可以看到,经过一轮冒泡只是将本次冒泡的最大值拿到,但是后面121才是第二次最大的啊,所以还要进行多轮冒泡,直到最后只剩下一个泡泡要冒,就不进行该泡泡的冒出工作,因为没必要了,剩下的最后一个就是最小值了.
那么我们可以总结,进行一次冒泡,要经过四次循环比较,进行完全部冒泡,要经过4轮冒泡.所以可以得出以下结论:
当有n个元素进行冒泡排序比较时,要进行n-1轮冒泡,每轮冒泡都有n-1次比较.
所以我们在写代码的时候,就需要两个for循环因为每次for循环都是n-1次,那么时间复杂度不就是o((n-1)2)了吗?这个(n-1)2等于n2-2*n-1,又因为时间复杂度计算的规则,当有指数项的时候,要去除掉系数项和常数项,所以这里的时间复杂度近似等于o(n2).
但这只是最大的时间复杂度,其实本质没有这么多,认真分析你会发现,笔者忽略了一件事.在每次冒泡的时候,我们是不需要将上次冒泡得到的最大值加入到本次冒泡的过程里的,所以本次冒泡的的迭代次数是上一次迭代次数-1,那么每次循环最多是n-1,不是每次循环都是n-1,真实的时间复杂度就比不上上面的分析的.
代码实现
package com.hyb.ds.排序.冒泡排序;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class BubbleSort<E> {
public List<E> BubbleMaxSort(List<E> sort){
int length = sort.size();
//代码优化,如果当前冒泡这一轮一次都没有发生过冒泡,说明已经是顺序的了,后面用再排序了.
boolean f=false;
for (int i = 0; i < length - 1; i++) {
for (int j = 0; j < length-i-1; j++) {
E o1 = sort.get(j);
E o2 = sort.get(j+1);
if (o1 instanceof Integer && o2 instanceof Integer){
if (((Integer) o1).compareTo((Integer) o2) > 0){
f=true;
sort.set(j+1, o1);
sort.set(j,o2);
}
}
}
if (!f){
break;
}
f=false;
}
return sort;
}
}
class Test{
public static void main(String[] args) {
BubbleSort<Integer> integerBubbleSort = new BubbleSort<>();
/*
* Arrays.asList(11, 2, -1, 33, 4, 55, 6) 返回的是
* java.util.Arrays的静态内部类,
* 并不是import java.util.List里的ArrayList
* 所以要利用import java.util.List里的ArrayList进行初始化
* */
List<Integer> integers = integerBubbleSort.BubbleMaxSort(new ArrayList<>(Arrays.asList(11, 2, -1, 33, 4, 55, 6)));
integers.forEach(System.out::println);
}
}
快速排序**
快速排序是冒泡排序的一种升级,因为冒泡排序要将每两个相邻的值都进行比较,耗费的时间是比较久,所以产生了快速排序.
分析
- 找到一个基数,让基数放在数组中间某个位置,规定左边的数一定要小于该基数,右边的数一定要大于该基数.
- 只是这个基数怎么找是一个问题,甚至大多数人都不知道快速排序的原理是什么,请看下面这张图:
先选出一个基数,为6,也就是我们要将6放在中间某个位置,那么得左指针得往右找,找到第一个比6大的数停下来,这里是7,右指针往左找,找到第一个比6小的数为0,之后两个值交换位置:

- 之后左指针继续往右找,右指针继续往左找,规则一致,找到并交换,直到两个指针重叠,就达到了第一轮放基数的目的.
- 但这样还不行,虽然知道了6的左边是全小于它的,右边是全大于它的,但是左边的还是错乱的,右边的还是错乱的,所以以同样的方式分别处理两边,最后得到一个完整的从小到大的数组.
代码实现
- 首先指定基数,作为判断标准.
- 整体有一个大的循环,就是当左指针位置小于右指针位置的时候
- 在这个大循环内,分别有一个左循环和一个右循环,左循环负责寻找大于基数的工作,右循环负责找小于基数的工作,各自找到了第一个后,直接进行交换.
- 在大循环内注意若是左右循环各自找到的值相等,直接跳过,不进行交换.
- 大循环完毕后,注意,两个指针的位置一定是相等的,这个时候可以进行下一轮,调用两次本函数,实现左右递归
public class QuickSort {
public void quickSort(int[] a,int leftIndex,int rightIndex){
int i=leftIndex;
int j=rightIndex;
int key=a[i];
while (leftIndex<rightIndex){
while ((leftIndex<rightIndex)&&a[leftIndex]<key){
leftIndex++;
}
while ((leftIndex<rightIndex)&&a[rightIndex]>key){
rightIndex--;
}
if ((a[leftIndex]==a[rightIndex])&&(leftIndex<rightIndex)) {
leftIndex++;
}else{
int t=a[leftIndex];
a[leftIndex]=a[rightIndex];
a[rightIndex]=t;
}
}
if (leftIndex-1>i)
quickSort(a,i,leftIndex-1);
if (rightIndex+1<j)
quickSort(a,rightIndex+1,j);
}
public static void main(String[] args) {
QuickSort quickSort = new QuickSort();
int [] ints=new int[]{6, 6, 2, 7, 9, 3, 4, 5, 10, 6,8};
quickSort.quickSort(ints, 0, 10);
for (int s :
ints) {
System.out.println(s);
}
}
}
选择排序
分析
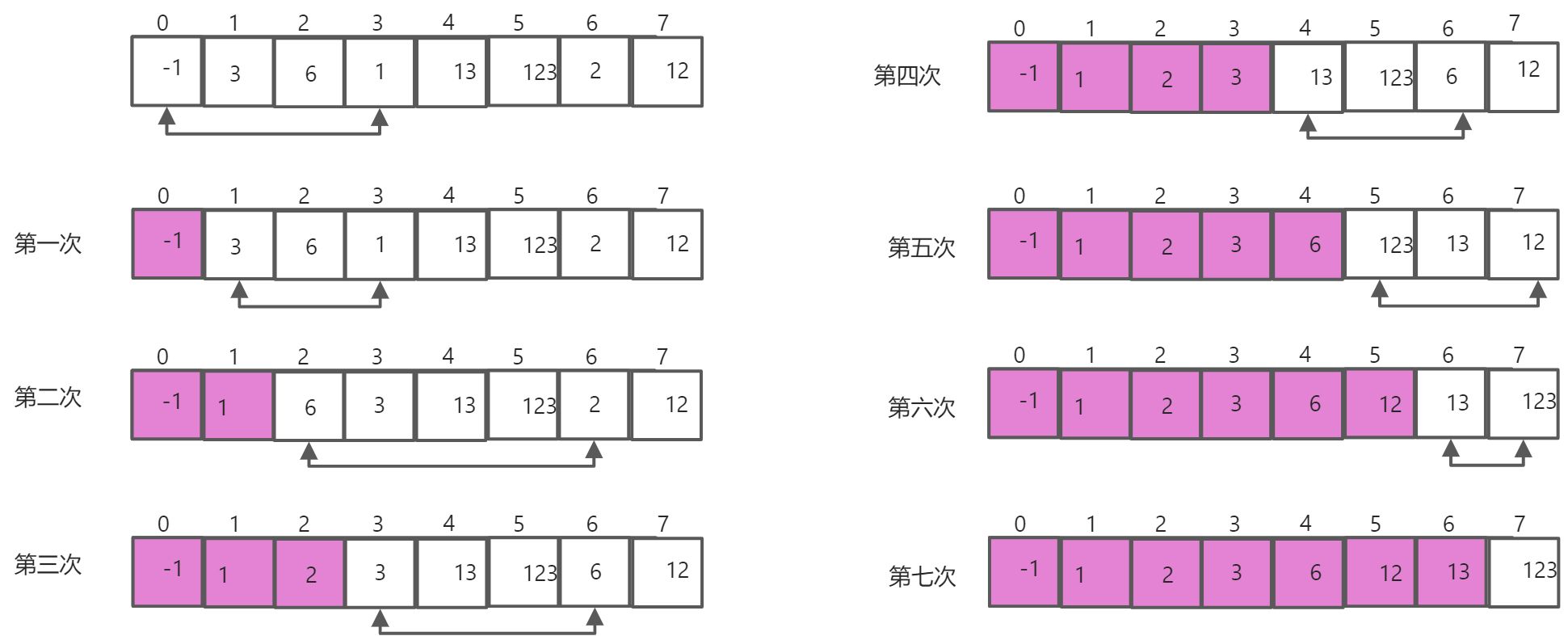
加入有八个元素-1,3,6,1,13,123,2,12
那么第n次排序,就拿第n-1号位元素与后面所有元素(size-n个)的最小值做对比,如果自己最小,原地不动,如果自己最大,与之交换位置.(注意我图中的箭头是代表下一次交换的两个数),最多进行length-1次排序
如此迭代,直到最后仅剩123一个元素,就不用排序,这个值便是最大.
代码实现
package com.hyb.ds.排序.选择排序;
import java.util.Arrays;
public class SelectSort {
public int[] selectSort(int[] sort){
for (int i=1;i<=sort.length-1;i++){
//假定p1就是最小的
int p1=sort[i-1];
int index=-1;
for (int j=i+1;j<=sort.length-1;j++){
int p3=sort[j-1];
//如果后面有值比p1小
if (p3<p1){
//让p1重新复制
p1=p3;
//拿到最小值的下标
index=j-1;
}
}
//交换
//index=-1代表后面没有比p1还小的值,那就是p1就是最小值
if (index!=-1){
//先让后面最小值的位置填入当前位置
sort[index]=sort[i-1];
//然后让当前位置填入后面的最小值
sort[i-1]=p1;
}
}
return sort;
}
}
class Test{
public static void main(String[] args) {
SelectSort selectSort = new SelectSort();
int[] p=new int[]{22,-1,3,32,12,90};
int[] ints = selectSort.selectSort(p);
System.out.println(Arrays.toString(ints));
}
}
插入排序
分析
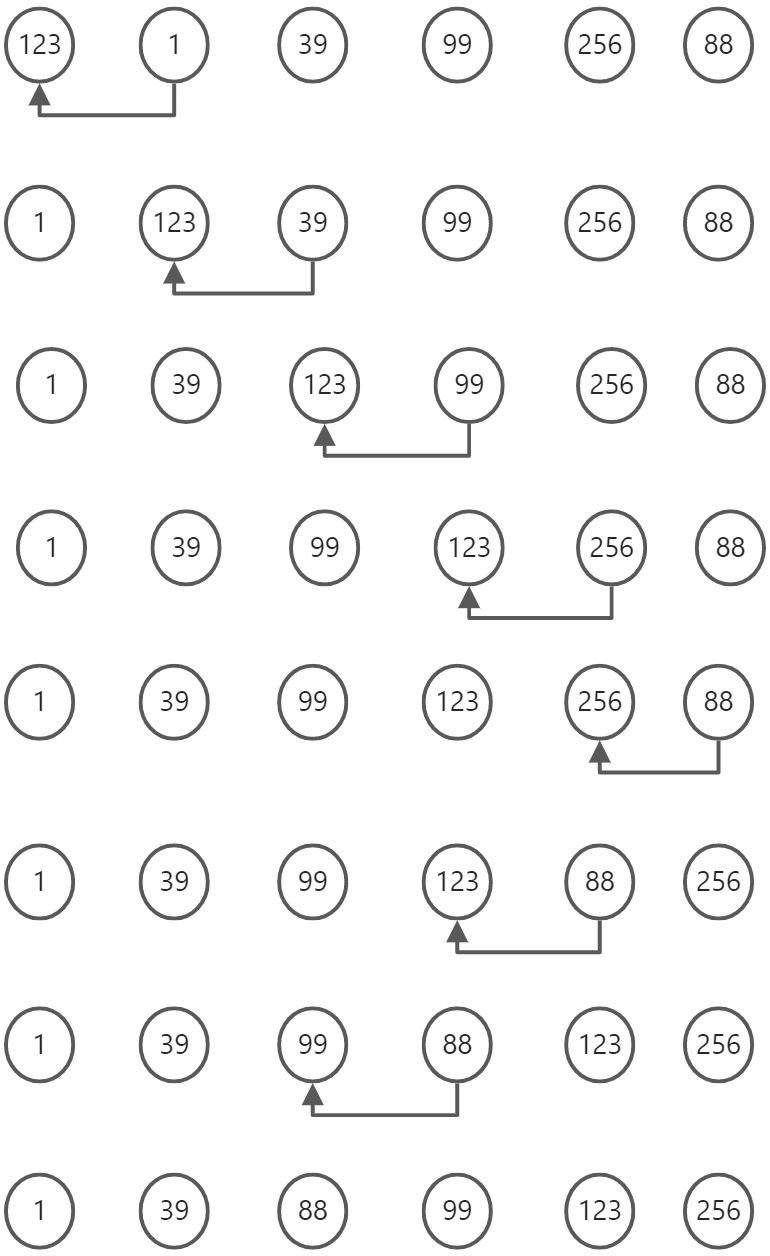
代码分析
从小到大排序:
前面的图可以看出,从1开始,发现123比它大就,就交换位置,每次都是这样,先比较前一位数据,但仅仅比较前一位数据还不行,比如到了88与256比较后交换位置会发现88所在位置的前一个位置的值还是比它大,所以又要交换位置,依次类推,直到88所在位置的前一个位置的值比88小,才说明88前面所有的值都比它小,这个时候就可以进行下一轮.
public class InsertSort {
public int[] insertSort(int [] sort){
for (int i = 1; i <= sort.length-1; i++) {
int n=i;
while (true){
int f=sort[n-1];
int e=sort[n];
if (f>e){
sort[n]=f;
sort[n-1]=e;
}else if (f<e)
break;
n--;
if (n==0)
break;
}
}
return sort;
}
public static void main(String[] args) {
InsertSort insertSort = new InsertSort();
int[] ints = insertSort.insertSort(new int[]{123, 650, 15555, 34, 890, 4003});
for (int i = 0; i < ints.length; i++) {
System.out.println(ints[i]);
}
}
}
希尔排序
分析

自己画的没那个意思,所以截取网上的一张图片,很清晰明了.
- 首次取数组长度n/2的值为步长进行一个交换排序,如第一轮十个数,所以步长是5,所以第一个和第六个数交换,依次类推,第二个和第七个交换…
- 进行完一轮之后取(n/2)/2的值,也就是上一个值的1/2,以这个步长进行交换排序.
- 直到步长为1,进行排序.
代码
public class ShellSort {
public int[] shellSort(int[] a){
int n=a.length;
do {
n = n / 2;
if (n==1){
InsertSort insertSort = new InsertSort();
a=insertSort.insertSort(a);
}
for (int i = 0; i < n; i++) {
if (a[i] > a[i + n]) {
int t = a[i + n];
a[i + n] = a[i];
a[i] = t;
}
}
} while (n != 1);
return a;
}
public static void main(String[] args) {
ShellSort shellSort = new ShellSort();
int[] ints = shellSort.shellSort(new int[]{9, 6,8,9,45,78,23, 7, 4, 3, 1});
for (int i :
ints) {
System.out.println(i);
}
}
}
归并排序**
带了**的排序就有点难了,反正小编做不出来,所以觉得难.
分析
归并排序主要采用了一种分治思想,你可以理解为分合思想.

先看尚硅谷这张图片,这样子一下子豁然开朗了吧.
归并排序主要的难点在于这个治,拆分倒是容易,主要是拆分过后如果进行合并,这里的合并是要按照规则合并,也就是我们要保证拆分后各个分组里必须是有序的,才能将各个分组合并,最终合并成一个有序的.
那么,我们不妨想一下,这个合并过程该怎么去做,请看下面这张图片:

合并过程用到了另一个新数组,这也是归并排序的缺点,就是浪费空间,但是效率是极高的,因为各个分组内是有序的,如果某个分组排完,另一个分组是可以直接转移的.
代码分析
- 使用递归进行拆分,分为左右两边拆分.
- 拆到左指针到达右指针为止,注意这里的左指针和右指针值得是每个分组里的.
- 之后就合并,合并的重点在于新数组如何将值复制给旧数组,不是简单的转移引用就行了,因为这个新数组是每次递归都会产生的引用,而旧数组只有一个数组,所以如果直接拷贝因为,就会让每次新的数组引用直接覆盖了原数组,所以只能将对应下表的值复制过去.
public class MergeSort {
public static void mergeSort(int left,int right,int[] a,int[] b){
if (left<right){
//不能直接用长度计算mid,这要根据每个分组情况计算mid
int mid=(left+right)/2;
//左边递归
mergeSort(left,mid,a,b);
//右边递归
mergeSort(mid+1,right,a,b);
//合并
merge(left,right,mid,a,b);
}
}
private static void merge(int left,int right,int mid, int[] a,int [] b) {
int i=left;
int j=mid+1;
int t=0;
//只能循环左右两边,不能越过mid,或者越过right
while (i<=mid && j<=right){
if (a[i]<=a[j]){
b[t]=a[i];
i++;
t++;
}else{
b[t]=a[j];
j++;
t++;
}
}
//如果循环完毕,i不等于mid,j不等于right
//说明两边都有剩余,直接将剩余的转移到b数组中
while (i<=mid){
b[t]=a[i];
i++;
t++;
}
while (j<=right){
b[t]=a[j];;
j++;
t++;
}
//这一步和关键,要将新数组的值复制到原数组中
//这里有人可能会问,能否直接返回新数组?
//不行,因为这里是递归,有可能新数组针对的是旧数组某些分组进行排序,如果直接返回,就代替了原数组
//所以这里只能一一复制,没有别的选择
// 初始化新数组下标
t=0;
//初始化left,因为这个left是不能改变,切记一定要用给一个变量去接,因为在循环中可能被改变
int bleft=left;
while (bleft<=right){
a[bleft]=b[t];
t++;
bleft++;
}
}
public static void main(String[] args) {
int[] a=new int[]{9,3,10,5,89,0,4};
int[] b=new int[a.length];
MergeSort.mergeSort(0,a.length-1,a,b);
for (int i :
a) {
System.out.println(i);
}
}
}
基数排序
分析
基数排序的思想很简单,就是将每个数的位数进行拆分,然后按规律放在桶里,这样说可能有些抽象,可以看下面这张图: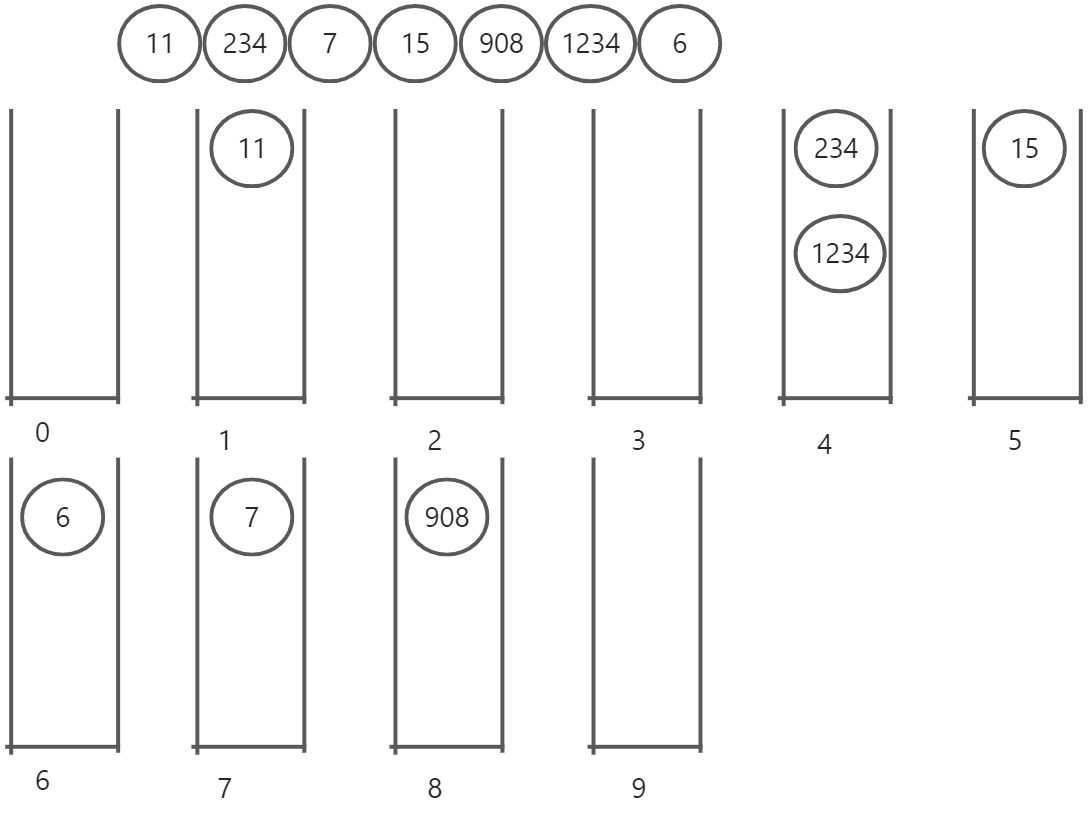
遍历待排序的数组,从左到右,先到第一个数字11,发现个位是1,放在第一个桶内,碰到234,发现其个位数是4,放在第四个桶内…,如果出现个位数相同的,比如1234和234是相同的,那么也是放在第四个桶内,但是要往后放入.遍历一次后,再从桶内顺序拿出数字,如果某个桶含多个数,从上往下先遍历完该桶内数字,才能进入下一个桶内遍历.这里进行一轮后得到的顺序是: 11,234,1234,15,6,7,908.你会发现这个还不是最有序的,所以要进入下一轮,这个时候,是看十位数字,规律都一样,等最大数字的高位都遍历完后,才能完全结束,此刻数字一定有序,比如1234,这个数字是四位的,也就是要进行四轮放桶.如果中间过程出现有些数字没有高位,比如这里遍历1234的1的时候,11这个数就没有千位的1,只有个位和十位,这个时候将11放入第0个桶.
代码
- 一定要十个桶,0-9编号,因为所有出现的数位范围是0-9.
- 总的轮次是最大数的数位量,比如1234,就要四个轮次.
- 若是出现没有该数位的数字,则放入第0个桶内,比如11在第四轮遍历或者第三轮遍历的时候,由于没有百位,所以放入第0个桶.
- 要记录每个桶每轮放入的数量,这样方便从桶内拿出数据,这个放入的数量可以是一个数组,保存着每个桶的实际存放数量.
- 也可以巧妙的保存: 舍去每个桶的第0个位置,该位置用来存放本桶的实际存放数量,那么实际存放元素的是第1位开始的,这样节省重新创建数组保存每个桶实际存放数量的空间.
public class BucketSort {
public static void bucketSort(int [] a){
//10为桶数量,a.length代表每个桶存放的最多数量
int[][] bucket=new int[10][a.length];
//求出最大值
int max = maxValue(a);
//计算最大值位数
int count = count(max);
int mod=1;
for (int i = 0; i < count; i++) {
for (int j = 0; j < a.length; j++) {
int k=(a[j]/mod)%10;
//从1开始放
int index=++bucket[k][0];
bucket[k][index]=a[j];
}
//取出元素放到原数组中
int index=0;
for (int m=0;m<10;m++){
if (bucket[m][0]!=0){
for (int n=1;n<=bucket[m][0];n++){
a[index]=bucket[m][n];
index++;
}
//相等于情况,实际没清空,但这一步很重要
bucket[m][0]=0;
}
}
mod=mod*10;
}
}
private static int count(int value){
int v=value;
int count=0;
while (v!=0){
v=v/10;
count++;
}
return count;
}
private static int maxValue(int[]a){
int max=a[0];
for (int i = 1; i < a.length; i++) {
if (max< a[i]){
max=a[i];
}
}
return max;
}
public static void main(String[] args) {
int[] a=new int[]{10,18,9,923,69842,90,1781978};
long l = System.currentTimeMillis();
System.out.println(l);
BucketSort.bucketSort(a);
System.out.println(System.currentTimeMillis());
for (int i = 0; i < a.length; i++) {
System.out.println(a[i]);
}
}
}
堆排序
堆排序要理解堆的结构,请翻看我们的主页查阅.
















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









