







第五章 NumPy数值计算
NumPy是最著名的Python库之一。NumPy提供了两种基本的对象:ndarray 和 ufunc。(终于开始了快乐的Python库学习之旅)
关于ndarray
创建与索引
NumPy提供了多种创建ndarray的方式,其中array函数可以创建一维或多维ndarray,其基本语法格式如下:
numpy.array(object, dtype = None, copy = True, order = ‘k’, subok = False, ndmin = 0)
| 参数 | 说明 |
|---|---|
| object | 接收array、list、tuple等,表示用于创建ndarray的数据,无默认值。 |
| dtype | 接收data-type,表示创建的ndarray的数据类型。如果未给定,那么选择保存对象所需的最小字节数的字节类型。无默认值。 |
| ndmin | 接收Int,指定生成ndarray应该具有的最小维数。默认为0。 |
特殊的创建函数
| 特殊的创建函数 | 说明 |
|---|---|
| arange | 创建等差数列(指定开始值、终值和步长) |
| linspace | 创建等差数列(指定开始值、终值和元素个数) |
| logspace | 创建等比数列 |
| zeros | 创建值全为0的矩阵 |
| eye | 创建单位矩阵(对角线元素为1,其余为0) |
| diag | 创建对焦矩阵(对角线元素为指定值,其余为0) |
| ones | 创建值全部为1的矩阵 |
也可采用相应函数如reshape、ravel等,实现对ndarry数组的索引,形状变换,组合和分割等。(具体内容可使用时自行查阅,略)
关于ufunc
ufunc,全称通用函数(universal function),是一种能够对ndarray中所有元素进行操作的函数。因此,ndarray能够运用向量化运算来处理整个数组,而完成同样的任务,Python的列表则通常需要借助循环语句遍历列表,并对逐个元素进行相应的处理。
常用的ufunc运算有算术运算、三角函数、集合函数、比较运算、逻辑运算和统计计算等。
在实际的数据分析人物中,更多使用文本格式的数据,如txt或csv,因此经常使用loadtxt函数执行对文本格式的数据的读取任务。savetxt函数是将ndarray写到由某种分隔符隔开的文本文件中。
numpy.linalg模块提供的常用的线性运算功能。
第五章课后题概述
课后题概述
-
BC
NumPy提供了两种基本的对象:ndarray和ufunc。其中,ndarray(N-dimensional Array Object)是一个具有矢量算术运算和复杂广播能力的、快速且节省空间的多维数组。ufunc(Universal Function Object)则提供了对ndarray进行快速运算和复杂广播能力 -
D
常用的ndarray属性主要有维数、尺寸、元素总数、数据类型、每个元素的存储字节数等,分别用ndim、shape、size、dtype和itemsize来表示。 -
C
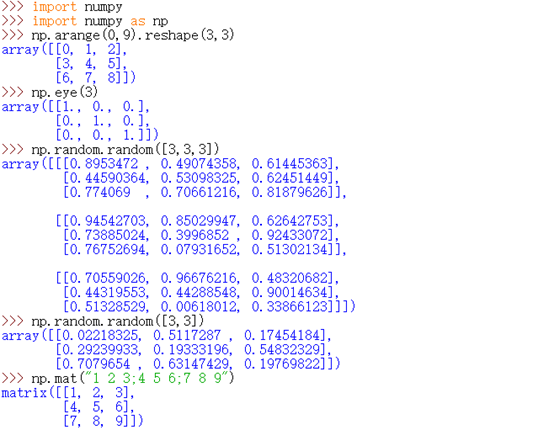
np.arange(0,9).reshape(3,3)的结果为
[[0 1 2]
[3 4 5]
[6 7 8]]
np.eye(3)的结果为
[[1 0 0]
[0 1 0]
[0 0 1]]
np.random.random([3,3,3])应改为np.random.random([3,3]),才会产生一个3×3的随机数值矩阵
np.mat(“1 2 3; 4 5 6; 7 8 9”)的结果为
[[ 1 2 3]
[4 5 6]
[7 8 9]
具体展示如下:
-
D
逐项解释一下。NumPy中常用排序函数有sort、argsort和lexsort,其中sort属直接排序,argsort和lexsort属于间接排序。故ABC均属于排序函数,只有D是提取函数。 -
C
借助ufunc,ndarry能够运用向量化运算来处理整个数组,而完成同样的任务,Python的列表则通常需要借助循环语句遍历列表,并对逐个元素进行相应的处理。因此效率更高。 -
ABCD
ufunc广播的4个原则是:
1) 让所有输入ndarray都向其中shape最长的ndarray看齐,shape中不足的部分都通过在前面加1补齐。
2) 输出ndarray的shape是输入ndarray shape的各个轴上的最大值。
3) 输入ndarray的某个轴和输出ndarray的对应轴的长度相同或其长度为1时,这个ndarray能够用于计算,否则出错。
4) 当输入ndarray的某个轴的长度为1,且沿着此轴运算时,都用此轴上的第一组值。 -
填空题
(1)reshape函数在改变ndarray的形状的同时不改变原始数据的值。
(2)在NumPy中直接排序经常使用sort函数,间接排序经常使用argsort函数和lexsort函数。
*直接排序指对数值直接进行排序;间接排序指根据一个或多个键值对数据集进行排序。
(3)广播(Broadcasting)是指不同形状的ndarray之间执行算术运算的方式。
*当进行ndarray计算时,ufunc会对两个数据的每个对应元素进行计算,执行这种计算方式的前提是两个ndarray的shape大小一致。若两个ndarray的shape不一致,Numpy则会实行广播机制。
(4)argsort函数可以返回集合中的唯一元素并排序 -
生成范围在0~1之间,服从均匀分布的10行5列的ndarray。
import numpy as np
print('rand函数生成的服从均匀分布的随机数ndarray为:\n', np.random.rand(10, 5))
rand函数生成的服从均匀分布的随机数ndarray为:
[[0.53470725 0.83219815 0.82950181 0.29835395 0.87077822]
[0.72346779 0.98923055 0.39596073 0.66288948 0.9117126 ]
[0.59255231 0.40580931 0.93153048 0.07059021 0.02105296]
[0.59124075 0.16790755 0.78345497 0.14842275 0.09439926]
[0.26743091 0.99961359 0.32414099 0.31877465 0.90340814]
[0.15710332 0.0123013 0.9728615 0.85520103 0.79700842]
[0.30682381 0.69617665 0.77889846 0.61151817 0.96931321]
[0.94790973 0.289788 0.89968492 0.33548125 0.57415498]
[0.47943747 0.5394681 0.70409507 0.69844242 0.07203066]
[0.01936026 0.02759766 0.23318908 0.89592223 0.20423337]]
- 计算2×2矩阵的乘积。
import numpy as np
arr1= np.matrix([[1,2],[12,12]])
arr2= np.matrix([[84,67],[678,56]])
print('矩阵乘积的结果为:\n',arr1*arr2)
矩阵乘积的结果为:
[[1440 179]
[9144 1476]]
- 求矩阵的特征值和特征向量
import numpy as np
A= np.matrix([[3,-1],[-1,3]])
eigenvalue,featurevector = np.linalg.eig(A)
print('特征值为:',eigenvalue,'\n特征向量为:\n',featurevector)
特征值为: [4. 2.]
特征向量为:
[[ 0.70710678 0.70710678]
[-0.70710678 0.70710678]]
- 对矩阵进行奇异分解
import numpy as np
A= np.matrix([[4,11,14],[8,7,-2]])
U, D,Vt=np.linalg.svd(A)
print('U:\n',U,'\nD为:\n',D,'\nVt为:\n',Vt)
U:
[[-0.9486833 -0.31622777]
[-0.31622777 0.9486833 ]]
D为:
[18.97366596 9.48683298]
Vt为:
[[-0.33333333 -0.66666667 -0.66666667]
[ 0.66666667 0.33333333 -0.66666667]
[-0.66666667 0.66666667 -0.33333333]]
- 行列式计算
import numpy as np
D=np.array([[4,6,8],[4,6,9],[5,6,8]])
print('D计算结果为:',np.linalg.det(D),"\nD'计算结果为:",np.linalg.det(D.T))
D计算结果为: 5.999999999999996
D'计算结果为: 6.0
注:代码除部分经本人修改外,主要来自 机械工业出版社的《Python3智能数据分析快速入门》 的配套资料。















 1866
1866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









