







PostgreSQL本身是支持全文检索的,提供两个数据类型(tsvector,tsquery),并且通过动态检索自然语言文档的集合,定位到最匹配的查询结果。其内置的默认的分词解析器采用空格进行分词,但是因为中文的词语之间没有空格分割,所以这种方法并不适用于中文。
要支持中文的全文检索需要额外的中文分词插件,zhparser就是其中一种,是基于Simple Chinese Word Segmentation(SCWS)中文分词库实现的一个PG扩展。
zhparser的源码地址为:https://github.com/amutu/zhparser
中文分词库的下载地址为:http://www.xunsearch.com/scws/download.php
一、安装中文分词库SCWS和zhparser分词插件
1.下载scws-1.2.3和zhparser的包
postgres@ubuntu-linux-22-04-desktop:~$ cd zhparser/
postgres@ubuntu-linux-22-04-desktop:~/zhparser$ ls
scws-1.2.3.tar.bz2 zhparser-master.zip

2.安装中文分词库SCWS
root@ubuntu-linux-22-04-desktop:/home/postgres# cd zhparser/
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# ls
scws-1.2.3.tar.bz2 zhparser-master.zip
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# tar -xf scws-1.2.3.tar.bz2
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# ls
scws-1.2.3 scws-1.2.3.tar.bz2 zhparser-master.zip
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser# cd scws-1.2.3/
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# ls
API.md ChangeLog Makefile.in aclocal.m4 config.guess configure etc ltmain.sh win32
AUTHORS INSTALL NEWS cli config.h.in configure.ac install-sh missing
COPYING Makefile.am README compile config.sub depcomp libscws phpext
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# ./configure
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking for gcc... gcc
...
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# make install
Making install in .
make[1]: Entering directory '/home/postgres/zhparser/scws-1.2.3'
make[2]: Entering directory '/home/postgres/zhparser/scws-1.2.3'
make[2]: Nothing to be done for 'install-exec-am'.
make[2]: Nothing to be done for 'install-data-am'.
make[2]: Leaving directory '/home/postgres/zhparser/scws-1.2.3'
make[1]: Leaving directory '/home/postgres/zhparser/scws-1.2.3'
Making install in libscws
make[1]: Entering directory '/home/postgres/zhparser/scws-1.2.3/libscws'
/bin/sh ../libtool --preserve-dup-deps --tag=CC --mode=compile gcc -DHAVE_CONFIG_H -I. -I.. -g -O2 -MT charset.lo -MD -MP -MF .deps/charset.Tpo -c -o charset.lo charset.c
libtool: compile: gcc -DHAVE_CONFIG_H -I. -I.. -g -O2 -MT charset.lo -MD -MP -M
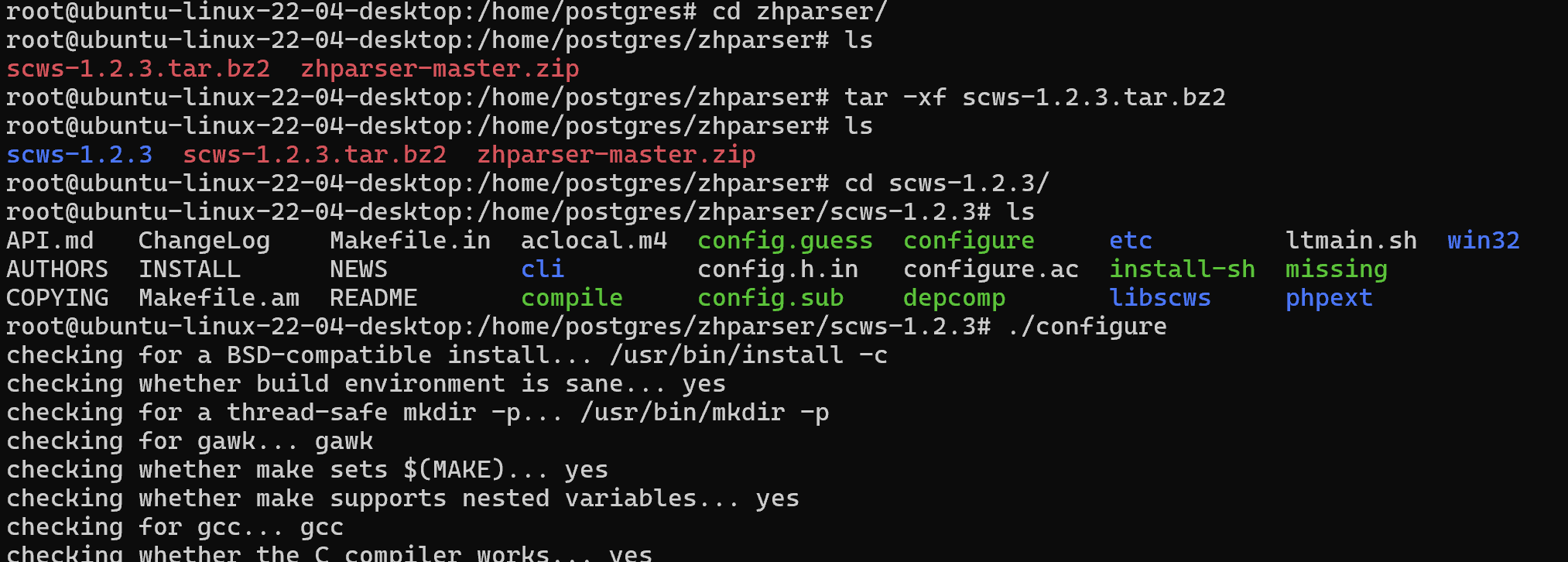
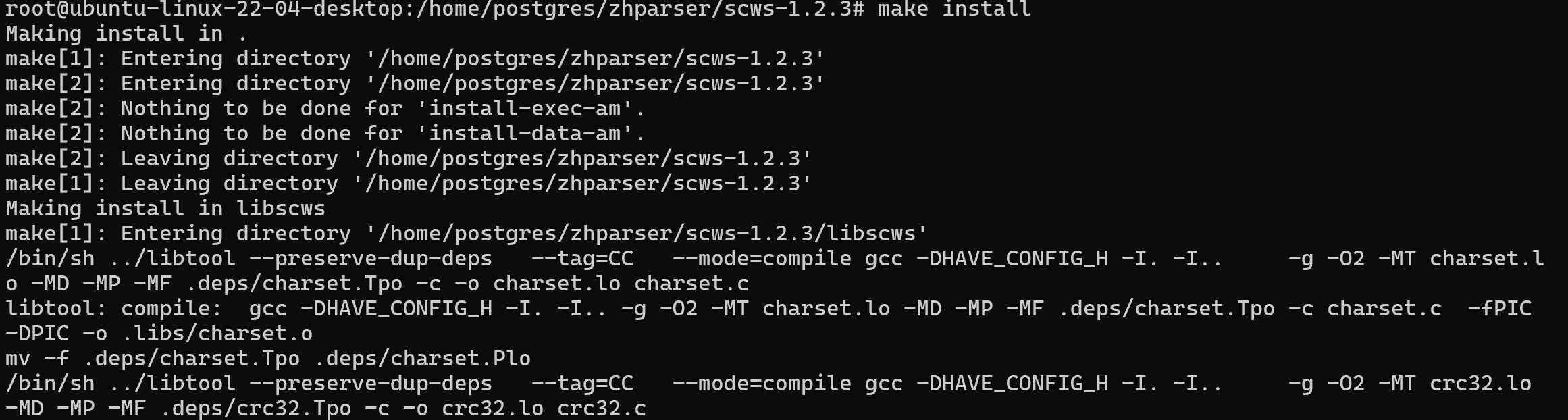
3.安装zhparser插件
root@ubuntu-linux-22-04-desktop:/home/postgres/zhparser/scws-1.2.3# su - postgres
postgres@ubuntu-linux-22-04-desktop:~$ cd zhparser/
postgres@ubuntu-linux-22-04-desktop:~/zhparser$ ls
scws-1.2.3 scws-1.2.3.tar.bz2 zhparser-master.zip
postgres@ubuntu-linux-22-04-desktop:~/zhparser$ unzip zhparser-master.zip
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ export SCWS_HOME=/usr/local
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ make -j 24
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wcast-function-type -Wshadow=compatible-local -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -Wno-stringop-truncation -g -O2 -fPIC -fvisibility=hidden -I/usr/local/include/scws -I. -I./ -I/home/postgres/soft-16/include/server -I/home/postgres/soft-16/include/internal -D_GNU_SOURCE -c -o zhparser.o zhparser.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wcast-function-type -Wshadow=compatible-local -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -Wno-stringop-truncation -g -O2 -fPIC -fvisibility=hidden -shared -o zhparser.so zhparser.o -L/home/postgres/soft-16/lib -Wl,--as-needed -Wl,-rpath,'/home/postgres/soft-16/lib',--enable-new-dtags -fvisibility=hidden -lscws -L/usr/local/lib -Wl,-rpath -Wl,/usr/local/lib
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ make install -j 24
/usr/bin/mkdir -p '/home/postgres/soft-16/lib'
/usr/bin/mkdir -p '/home/postgres/soft-16/share/extension'
/usr/bin/install -c -m 755 zhparser.so '/home/postgres/soft-16/lib/zhparser.so'
/usr/bin/mkdir -p '/home/postgres/soft-16/share/extension'
/usr/bin/mkdir -p '/home/postgres/soft-16/share/tsearch_data'
/usr/bin/install -c -m 644 .//zhparser.control '/home/postgres/soft-16/share/extension/'
/usr/bin/install -c -m 644 .//zhparser--1.0.sql .//zhparser--unpackaged--1.0.sql .//zhparser--1.0--2.0.sql .//zhparser--2.0.sql .//zhparser--2.0--2.1.sql .//zhparser--2.1.sql .//zhparser--2.1--2.2.sql '/home/postgres/soft-16/share/extension/'
/usr/bin/install -c -m 644 .//dict.utf8.xdb .//rules.utf8.ini '/home/postgres/soft-16/share/tsearch_data/'
进入到数据库里创建插件
postgres@ubuntu-linux-22-04-desktop:~/zhparser/zhparser-master$ psql
Border style is 2.
Line style is ascii.
psql (16.1)
Type "help" for help.
postgres<16.1>(ConnAs[postgres]:PID[462964] 2024-05-14/15:13:10)=# create database test_zhparser;
CREATE DATABASE
postgres<16.1>(ConnAs[postgres]:PID[462964] 2024-05-14/15:13:23)=# \c test_zhparser
You are now connected to database "test_zhparser" as user "postgres".
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:28)=# create extension zhparser;
CREATE EXTENSION
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:38)=# \dx
List of installed extensions
+----------+---------+------------+------------------------------------------+
| Name | Version | Schema | Description |
+----------+---------+------------+------------------------------------------+
| plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language |
| zhparser | 2.2 | public | a parser for full-text search of Chinese |
+----------+---------+------------+------------------------------------------+
(2 rows)
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:41)=# \dFp
List of text search parsers
+------------+----------+---------------------+
| Schema | Name | Description |
+------------+----------+---------------------+
| pg_catalog | default | default word parser |
| public | zhparser | |
+------------+----------+---------------------+
(2 rows)
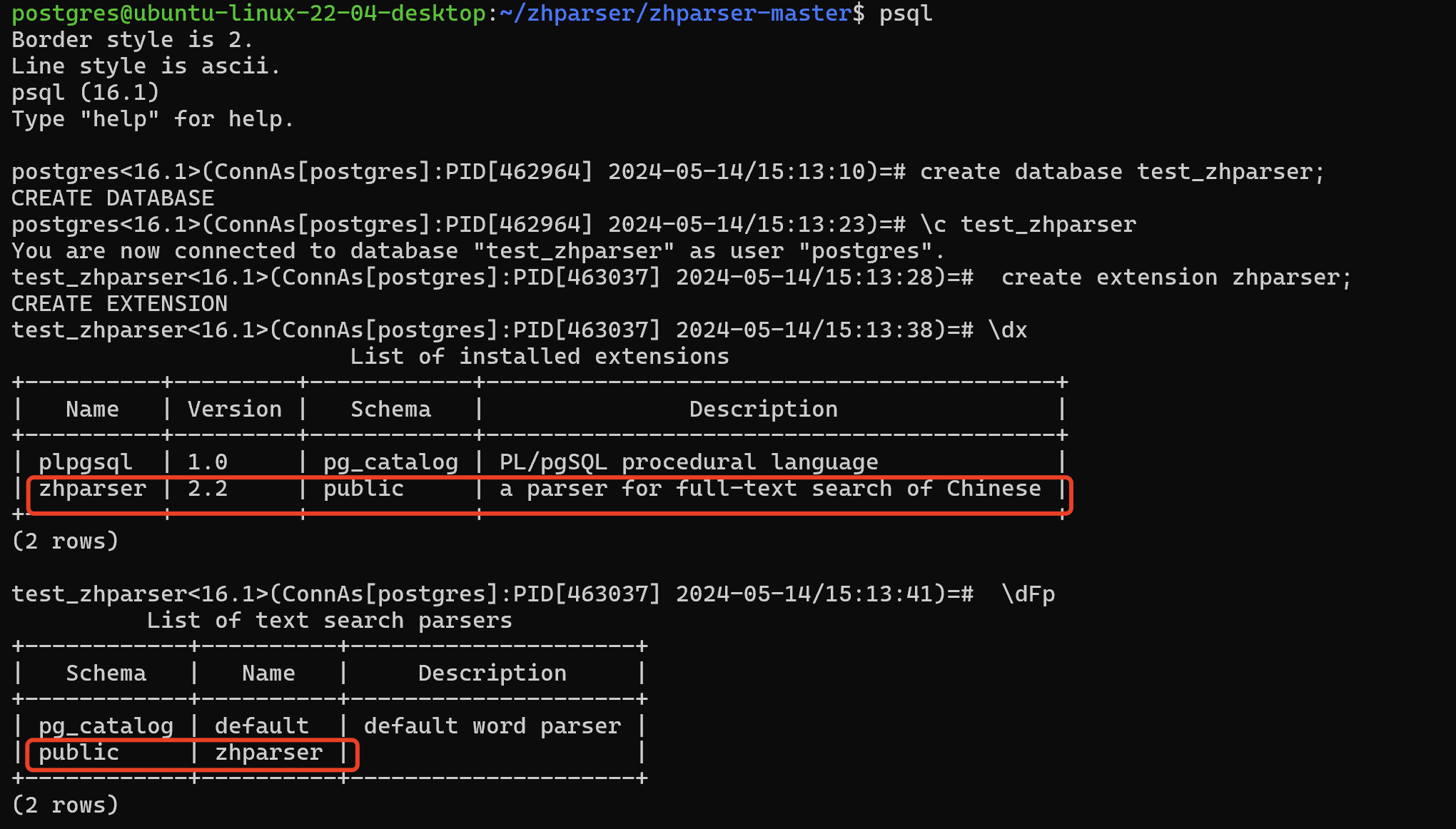
二、zhparser分词插件的相关配置
zhparser可以将中文切分成下面26种token
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:13:45)=# select ts_token_type('zhparser');
+---------------------------------+
| ts_token_type |
+---------------------------------+
| (97,a,"adjective,形容词") |
| (98,b,"differentiation,区别词") |
| (99,c,"conjunction,连词") |
| (100,d,"adverb,副词") |
| (101,e,"exclamation,感叹词") |
| (102,f,"position,方位词") |
| (103,g,"root,词根") |
| (104,h,"head,前连接成分") |
| (105,i,"idiom,成语") |
| (106,j,"abbreviation,简称") |
| (107,k,"tail,后连接成分") |
| (108,l,"tmp,习用语") |
| (109,m,"numeral,数词") |
| (110,n,"noun,名词") |
| (111,o,"onomatopoeia,拟声词") |
| (112,p,"prepositional,介词") |
| (113,q,"quantity,量词") |
| (114,r,"pronoun,代词") |
| (115,s,"space,处所词") |
| (116,t,"time,时语素") |
| (117,u,"auxiliary,助词") |
| (118,v,"verb,动词") |
| (119,w,"punctuation,标点符号") |
| (120,x,"unknown,未知词") |
| (121,y,"modal,语气词") |
| (122,z,"status,状态词") |
+---------------------------------+
(26 rows)
创建使用zhparser作为解析器的全文搜索的配置
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:14:36)=# CREATE TEXT SEARCH CONFIGURATION test_zhparserC (PARSER = zhparser);
CREATE TEXT SEARCH CONFIGURATION
往全文搜索配置中增加token映射
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:15:54)=# ALTER TEXT SEARCH CONFIGURATION test_zhparserC A
DD MAPPING FOR n,v,a,i,e,l WITH simple;
ALTER TEXT SEARCH CONFIGURATION
上面的token只映射了名词(n),动词(v),形容词(a),成语(i),叹词(e)和习用语(l)6种。词典使用的是内置的simple词典,即仅做小写转换。可以根据自己的需求自定义,实现屏蔽词和同义词归并等功能。
三、测试zhparser中文分词插件
PostgreSQL本身是支持全文检索的,提供两个数据类型(tsvector,tsquery),自带了to_tsquery函数和plainto_tsquery函数,来处理分析搜索语句。
而一个tsvector的值是唯一分词的分类列表,把一话一句词格式化为不同的词条,在进行分词处理的时候tsvector会自动去掉分词中重复的词条,按照一定的顺序装入。处理加工的文本应该通过使用to_tsvector函数来使之规格化,标注化的应用于搜索。
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:14:15)=# SELECT to_tsquery('english', 'The & Fat & Rats');
+---------------+
| to_tsquery |
+---------------+
| 'fat' & 'rat' |
+---------------+
(1 row)
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:16:51)=# SELECT to_tsvector('english', 'The Fat Rats');
+-----------------+
| to_tsvector |
+-----------------+
| 'fat':2 'rat':3 |
+-----------------+
(1 row)
如下是针对中文全文检索插件的验证:
test_zhparser<16.1>(ConnAs[postgres]:PID[463037] 2024-05-14/15:24:01)=# select to_tsvector('test_zhparserC','大连星海湾');
+---------------------+
| to_tsvector |
+---------------------+
| '大连':1 '星海湾':2 |
+---------------------+
(1 row)
test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:43:24)=# select to_tsvector('test_zhparserC','大连市星海 广场');
+------------------------------+
| to_tsvector |
+------------------------------+
| '大连市':1 '广场':3 '星海':2 |
+------------------------------+
(1 row)
分词的粒度越粗,效率越高,但遗漏的可能性也会高一点,即召回率受影响。
召回率=提取出的正确信息条数 / 样本中的信息条数
准确率=提取出的正确信息条数 / 提取出的信息条数
可以使用函数后边带 @@ ‘xxx&xxx’;的方式判断是否能从取样的文字里提取出的正确信息,像’大连&广’就无法提取到。效率,召回率和准确率3个指标往往不能兼顾,如果想提高召回率,可以对SCWS的一些选项参数进行调节。
test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:45:23)=# select to_tsvector('test_zhparserC','大连市星海广场');
+------------------------------+
| to_tsvector |
+------------------------------+
| '大连市':1 '广场':3 '星海':2 |
+------------------------------+
(1 row)
test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:45:31)=# select to_tsvector('test_zhparserC','大连市星海广场')@@ '大连市&广场';
+----------+
| ?column? |
+----------+
| t |
+----------+
(1 row)
test_zhparser<16.1>(ConnAs[postgres]:PID[469953] 2024-05-14/15:45:39)=# select to_tsvector('test_zhparserC','大连市星海广场')@@ '大连&广场';
+----------+
| ?column? |
+----------+
| f |
+----------+
(1 row)
也可以使用ts_debug函数,来调试全文检索。这个函数显示的是文档的每个词条通过基本词典的分析和处理的信息。
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:01:34)=# select ts_debug('test_zhparserC','大连市星海广场');
+-------------------------------------------------+
| ts_debug |
+-------------------------------------------------+
| (n,"noun,名词",大连市,{simple},simple,{大连市}) |
| (n,"noun,名词",星海,{simple},simple,{星海}) |
| (n,"noun,名词",广场,{simple},simple,{广场}) |
+-------------------------------------------------+
(3 rows)
这个函数返回的信息为:
1.文本别名-词的类型名称
alias text — short name of the token type
2.描述-描述词的类型
description text — description of the token type
3.词内容-词的文本内容
token text — text of the token
4.词典-词的配置所选择的词典
dictionaries regdictionary[] — the dictionaries selected by the configuration for this token type
5.词典-识别该令牌的字典,如果没有,则为NULL
dictionary regdictionary — the dictionary that recognized the token, or NULL if none did
6.处理后的词条
lexemes text[] — the lexeme(s) produced by the dictionary that recognized the token, or NULL if none did; an empty array ({}) means it was recognized as a stop word
四、结合gin索引的相关使用举例
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:23)=# create table test_zhpc(info text);
CREATE TABLE
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:32)=# insert into test_zhpc select '大连市星海广场' from generate_series(1,10000,1);
INSERT 0 10000
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:45)=# explain analyze select count(*) from test_zhpc where to_tsvector('test_zhparserC', info) @@ '大连市 & 星海广场'::tsquery;
+--------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
+--------------------------------------------------------------------------------------------------------------+
| Aggregate (cost=2348.80..2348.81 rows=1 width=8) (actual time=39.306..39.307 rows=1 loops=1) |
| -> Seq Scan on test_zhpc (cost=0.00..2348.80 rows=1 width=0) (actual time=39.258..39.259 rows=0 loops=1) |
| Filter: (to_tsvector('test_zhparserc'::regconfig, info) @@ '''大连市'' & ''星海广场'''::tsquery) |
| Rows Removed by Filter: 10000 |
| Planning Time: 0.199 ms |
| Execution Time: 39.424 ms |
+--------------------------------------------------------------------------------------------------------------+
(6 rows)
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:35:49)=# create index idx_gin_1 on test_zhpc using gin (to_tsvector('test_zhparserC'::regconfig,info));
CREATE INDEX
test_zhparser<16.1>(ConnAs[postgres]:PID[474113] 2024-05-14/16:36:00)=# explain analyze select count(*) from test_zhpc where to_tsvector('test_zhparserC', info) @@ '大连市 & 星海广场'::tsquery;
+-------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
+-------------------------------------------------------------------------------------------------------------------------+
| Aggregate (cost=37.79..37.80 rows=1 width=8) (actual time=0.073..0.074 rows=1 loops=1) |
| -> Bitmap Heap Scan on test_zhpc (cost=33.53..37.79 rows=1 width=0) (actual time=0.069..0.070 rows=0 loops=1) |
| Recheck Cond: (to_tsvector('test_zhparserc'::regconfig, info) @@ '''大连市'' & ''星海广场'''::tsquery) |
| -> Bitmap Index Scan on idx_gin_1 (cost=0.00..33.53 rows=1 width=0) (actual time=0.067..0.067 rows=0 loops=1) |
| Index Cond: (to_tsvector('test_zhparserc'::regconfig, info) @@ '''大连市'' & ''星海广场'''::tsquery) |
| Planning Time: 0.112 ms |
| Execution Time: 0.146 ms |
+-------------------------------------------------------------------------------------------------------------------------+
(7 rows)
















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











