







一、导入request库
import requests二、获取网页响应,request.get
response = request.get("http://www.baidu.com")
# reqponse可以任意取名三、是否访问成功,XXX.status_code
response.status_code
# 如成功会返回200 
四、assert断言(假设)
assert response.status_code==200
# 断言成功,假设响应成功,assert后面跟一个布尔类型1.断言成功不会返回任何属性,断言失败会出现提示:
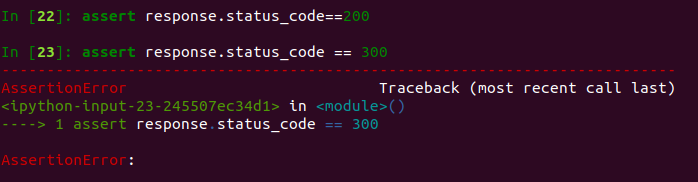
2.我们可以调用这个办法判断请求是否成功
五、请求头与响应头
1.响应头:
response.headers
# 显示页面的响应头文件 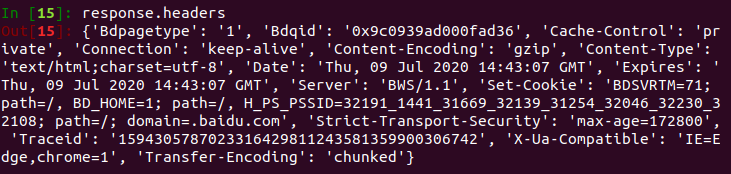
2.请求头:
response.request.headers
# 请求头 
六、响应url地址与请求url地址
response.url # 响应url地址
response.request.url # 请求url地址
# 两个地址可能会不一样,当服务器将访问重定向到另外一个网站时可能不一样七、用编译器自带的User-Agent访问网站时会被定义为爬虫,此时我们需要自定义header内容模拟一个浏览器。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









