







一张数据表

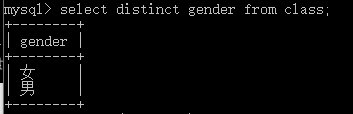
1.查询时 [ 筛选 ] 掉重复的数据
select distinct gender from class;

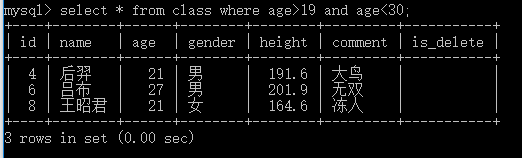
2. 条件筛选 [ and ] 的使用 ,and 的 [ 左边 ] 和 [ 右边 ] 都要写明范围
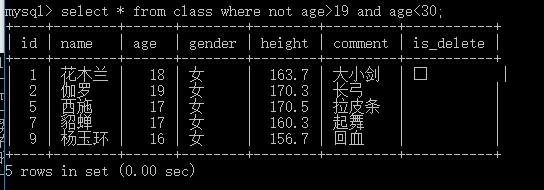
3. 条件筛选 [ not ] 的使用 ,两个以上的时候 [ 加上括号 ],比如查出 年龄 [ 不 ] 在19岁到30岁之间的人物。显然第二个是正确的,如果不增加括号,逻辑为:
( not age > 19 ) and age < 30

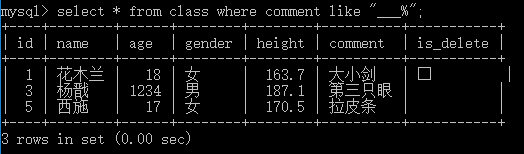
4. %表示替换一个或者多个字符,like表示模糊查询,用的比较少。
将表中 [ comment ] 带 [ 大 ] 字的内容全部查出来

5. _ 表示替换一个字符
将两个字的名字全部查出来。

6. _ 和 % 一起使用
添加了三个下划线,将 comment 至少三个字的内容全部查询出来。
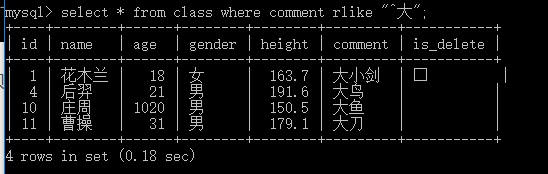
7. [ rlike ] 正则匹配
匹配 comment 中以 大 开头的记述















 4978
4978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









