







爬虫虎牙网站lol主播人气和姓名(附人气值排名新方法)
- 大家好,我是bd,新人小白,这是我第一次尝试将自己对于爬虫知识的一些心得分享给大家。由于是最近刚接触python,所以在学习完爬虫这个知识点后自己动手尝试了一下,对象就是虎牙lol主播姓名和人气值排名的爬取,废话不多说,直接开始。(在编写的过程中参考了作者一曲无痕奈何的避坑贴士,让自己顺利编码,感谢!附链接https://blog.csdn.net/qq_41479464/article/details/91048147)
import re
from urllib import request
class Spider( ):
url = 'https://www.huya.com/g/wzry'
# 正则
root_pattern = '<span class="txt">([\s\S]*?)</li>' #结尾</span>并没有包含 人气值,这种情况下需要结尾处再往下找
name_pattern = '<i class="nick" title="([\s\S]*?)">([\s\S]*?)</i>' #此时会输出元组,包含两个名字,注意此处的用法
number_pattern='<i class="js-num">([\s\S]*?)</i>'
#获取要爬取的html
def __fetch_content(self): #定义私密实例方法
r=request.urlopen(Spider.url)#类调用类变量
htmls=r.read()
htmls=str(htmls,encoding='utf-8')
return htmls
#利用正则表达式匹配需要数据
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)#正则表达式返回列表,name列表[('姓名'),('姓名')]
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
print(anchors[0:10])
return anchors
#过滤重复名字以及将anchor和number里内容以字符串输出
def __refine(self,anchors):
l=lambda anchor:{'name':anchor['name'][0][0],'number':anchor['number'][0]}
r=map(l,anchors) #map格式需要转化成list,才能输出
# print(list(r))
return r
# 排序,按照人气值数值大小
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sort_seed,reverse=True)
return anchors
#将人气值数值取出来,作比较 单个anocher
def __sort_seed(self,anchor):
r=re.findall('[\d.]*',anchor['number'])
number=float(r[0])
print(r,number)
if ',' in anchor['number']:
number=number*1000+float(r[2])
print(number)
if '万' in anchor['number']:
number*=10000
print(number)
return number
def __show(self,anchors):
for rank in range(0,len(anchors)):
print('rank'+':'+str(rank+1)+' '+anchors[rank]['name']+':'+anchors[rank]['number'])
def go(self):
htmls=self.__fetch_content() #获取爬取页面htmls
anchors=self.__analysis(htmls) #解析获取页面htmls,寻找到所需姓名和人气
anchors=list(self.__refine(anchors))
anchors=self.__sort(anchors)
self.__show(anchors)
spider=Spider()
spider.go()
- 上述代码中有三点要和大家分享,下面一一来叙述
(1)虎牙网站主播姓名和人气值正则表达式的匹配
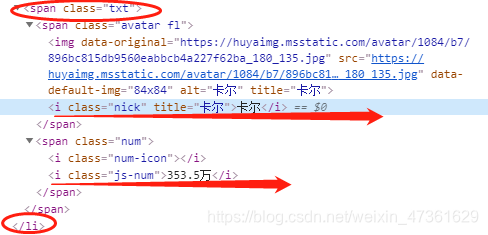
这是参考博主的方法,不然我就要炸了
root_pattern = '<span class="txt">([\s\S]*?)</li>' #结尾</span>并没有包含 人气值,这种情况下需要结尾处再往下找
name_pattern = '<i class="nick" title="([\s\S]*?)">([\s\S]*?)</i>' #此时会输出元组,包含两个名字,注意此处的用法
number_pattern='<i class="js-num">([\s\S]*?)</i>'
(2)人气值与主播姓名的提炼
从上图可以看出,在源代码中主播姓名出现了两次,因此精炼数据时值需要出现1次即可
def __refine(self,anchors):
l=lambda anchor:{'name':anchor['name'][0][0],'number':anchor['number'][0]}
r=map(l,anchors) #map格式需要转化成list,才能输出
return r
name列表:[('姓名','姓名')],因此采用anchor['name'][0][0]提取
(3)!!!!!人气值排名!!!!

由于学习资料和查询的博主都是采用这种方式,但是我在实操的过程中出现了不能正确匹配的情况,这主要是人气值超过1000万时,在python正则表达式输出时会是[‘1’,’ ',‘000’],选择浮点数输出时只会输出‘1’,因此会出现错误。我自己想了一个更正的办法,即加入if()函数,使人气超过1000万时也可以正常显示。代码如下:
r=re.findall('[\d.]*',anchor['number'])
number=float(r[0])
print(r,number)
if ',' in anchor['number']:
number=number*1000+float(r[2])
print(number)
加入该函数后可以保证人气在9999万以下正确输出,人气过亿就得重调代码了,目前主播人气在线人气还没有破亿的吧,2333。
- 以上就是我这个代码小白在学习python原生爬虫遇到的问题,希望分享给大家,顺利跳坑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









