







探秘Transformer系列之(4)— 编码器 & 解码器
0x00 摘要
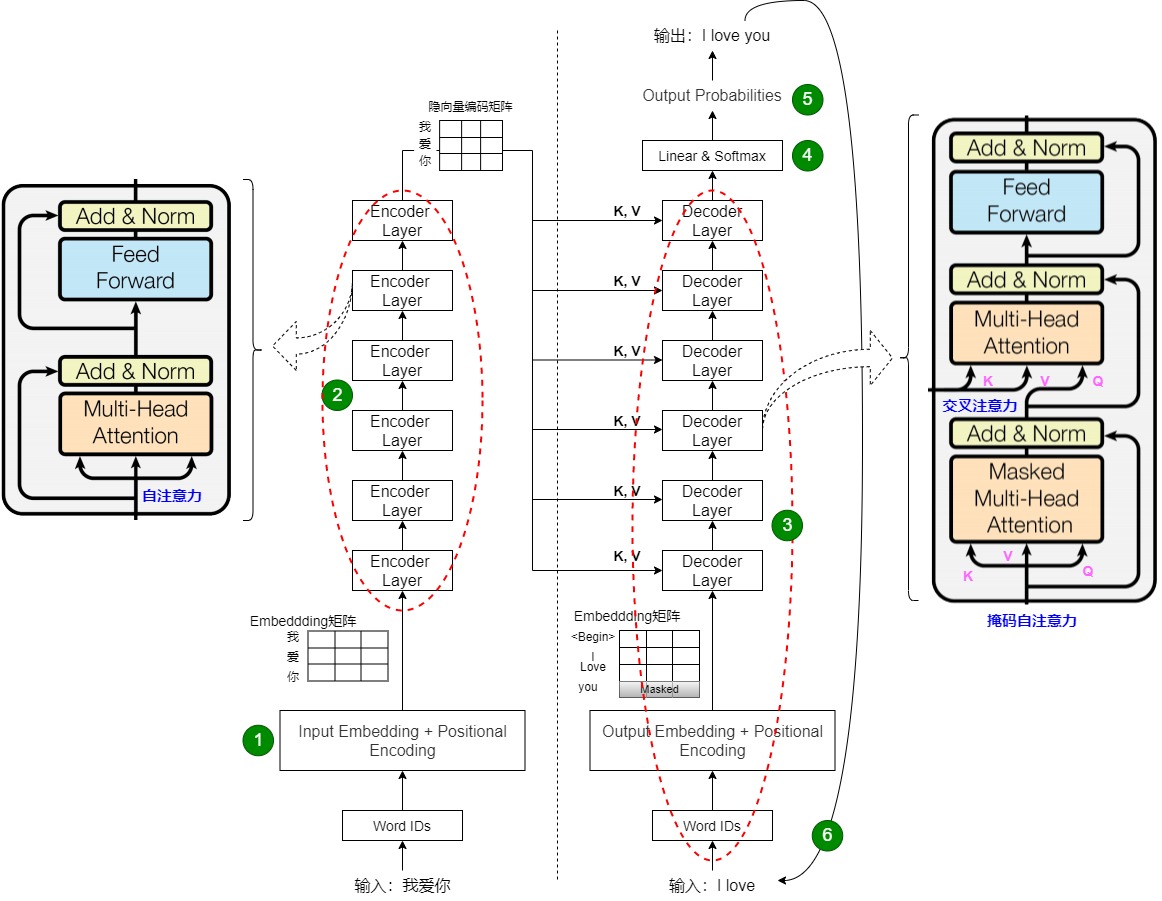
对于机器翻译,Transformer完整的前向计算过程如下图所示(与总体架构那章的流程图相比较,此处重点突出了编码器和解码器内部以及之间的关联)。图左侧是编码器栈,右侧是解码器栈,这两个构成了 Transformer 的“躯干”。具体流程如下。
- 将输入序列转换为嵌入矩阵,再加上位置编码(表示每个单词的位置)之后构成word embedding,然后把word embedding输入解码器。此步骤对应下图的标号1。
- 编码器接收输入序列的word embedding并生成相关隐向量。编码器是并行处理,因此只会进行一次前向传播。编码器栈内部通过自注意力机制完成了对源序列的特征的提取,得到了源序列内部元素之间的彼此相关性,保留了高维度潜藏的逻辑信息。或者说,自注意力负责基于其全部输入向量来建模每个输出均可以借鉴的隐向量。此步骤对应下图的标号2。
- 与编码器不同,解码器会循环执行,直到输出所有结果。解码器以标记和编码器的输出作为起点,生成输出序列的下一个 token。就像我们对编码器的输入所做的那样,我们会生成嵌入并添加位置编码来传给那些解码器。此步骤对应下图的标号3。
- 解码器栈内部通过掩码自注意力机制完成了对目标序列特征的提取,得到了目标序列内部元素之间的彼此相关性,保留了高维度潜藏的逻辑信息。或者说,掩码自注意力负责基于解码器的输入向量来建模每个解码器的输出向量。
- 自注意力机制只能提炼解构本序列的关联性特征,因此编码器栈和解码器栈之间通过交叉注意力在编码器和解码器之间传递信息,完成彼此的联系,确保了对特征进行非对称的压缩和还原。或者说,交叉注意力层则负责基于编码器的所有输出隐向量来进一步建模每个解码器的输出向量。
- 使用一个线性层来生成 logits。此步骤对应下图的标号4。
- 应用一个 softmax 层来生成概率,最终依据某种策略输出一个最可能的单词。此步骤对应下图的标号5。
- 解码器使用解码器的新输出token和先前生成的 token 作为输入序列来生成输出序列的下一个 token。此步骤对应下图的标号6。
- 重复步骤 3-6循环(对于步骤3,每次输入是变化的)来对下一个时刻的输出进行解码预测,直到生成 EOS 标记表示解码结束或者达到指定长度后停止。
这个解码过程其实就是标准的seq2seq流程。因此,注意力机制是Transformer 的“灵魂”,Transformer 实际上是通过三重注意力机制建立起了序列内部以及序列之间的全局联系。
本章依然用机器翻译来分析说明。
文章目录
注:全部文章列表在这里,估计最终在35篇左右,后续每发一篇文章,会修改文章列表。
csdn 探秘Transformer系列之文章列表
0x01 编码器
编码器的输入是word embedding序列,这是一个低阶语义向量序列。编码器的目标就是对这个低阶语义向量序列进行特征提取、转换,并且最终映射到一个新的语义空间,从而得到一个高阶语义向量序列。因为编码器使用了注意力机制,所以这个高阶语义向量序列具有更加丰富和完整的语义,也是上下文感知的。这个高阶语义向量序列将被后续的解码器使用并生成最终输出序列。而且,编码器是为每一个待预测词都生成一个上下文向量。为何要在每一步针对每一个待预测词都生成一个新的上下文向量?我们可以通过例子来解答。
- 中文:我吃了一个苹果,然后吃了一个香蕉。
- 英文:I ate an apple and then a banana。
如果逐字翻译,翻译到”我吃了一个“时候,得到的英文应该是”I ate a“?还是”I ate an”?这就需要依据后面的“苹果”来判断。所以,翻译“苹果”之后,需要依据“苹果”才能确定是"a"还是“an”,进而更新之前”一个“这个词对于的上下文向量。
1.1 结构
Transformer的编码器模块结构如下图紫色方框所示。编码器是由多个相同的EncoderLayer(编码器层,即下图的黄色部分)堆叠而成的。Transformer论文原图中只画了一个EncoderLayer,然后旁边写了个 Nx,这个Nx就表示编码器是由几个EncoderLayer堆叠而成。论文中设置N = 6。
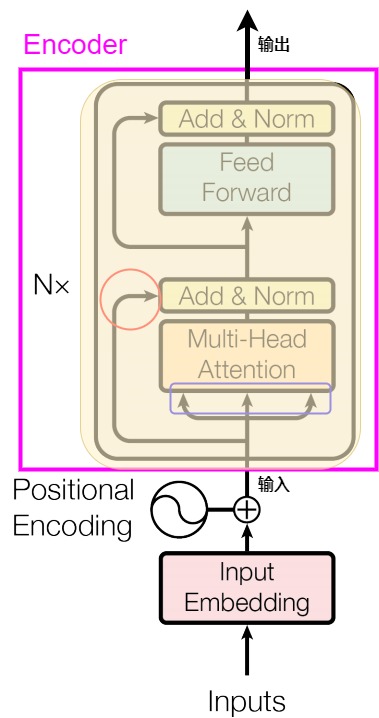
每个EncoderLayer由以下模块组成:
- 多头自注意力机制(Multi-Head Self-Attention/MHA),其特点如下:
- MHA是对输入序列自身进行的注意力计算,用于获取输入序列中不同单词之间的相关性。
- 编码器的输入被转换(即输入经过嵌入层和位置编码后,分别与Query、Key 和 Value 的参数矩阵相乘)后,作为Query、Key 和 Value这三个参数传递给MHA,即QKV均来自一个序列。
- MHA可以使网络在进行预测时对输入句子的不同位置的分配不同的注意力。多头注意力意味着模型有多组不同的注意力参数,每组都会输出一个依据注意力权重来加权求和的向量,这些向量会被合并成最终的向量进行输出。
- 第一个残差连接(Residual Connection)。残差连接使注意力机制中产生的新数据和最开始输入的原始数据合并在一起,这个合并其实就是简单的加法,这样可以避免深度神经网络中的梯度消失问题。残差连接对应上图中的“Add”。
- 第一个Layer Normalization(层归一化)。该模块可以让数据更稳定,便于后续处理。具体对应图上的“Norm”,其会对层的输入进行归一化处理,使得其均值为0,方差为1。
- FFN(Feed-Forward Networks/前馈神经网络)。这个模块由两个线性变换组成,中间夹有一个ReLU激活函数。它对每个位置的词向量独立地进行变换。这个层对经过注意力处理后的向量进一步进行处理和优化,产生一个新的表示。FFN输出是一个更具抽象性、更丰富的上下文表示,可以增加模型的非线性表示能力。
- 第二个残差连接,作用同第一个残差连接。
- 第二个Layer Normalization,作用同第一个Layer Normalization。
或者简化来看,编码器模块由一系列相同层构成,每个层分为两个重要子模块:MHA和FFN。每个重要子模块周围有一个残差连接,并且每个重要子模块的输出都会经过Layer Normalization。
1.2 输入和输出
因为编码器是层叠的栈结构,因此不同EncoderLayer的输入输出不尽相同。
编码器栈第一个EncoderLayer的输入是单词的Embedding加上位置编码,即图上的Input Embedding和Positional Encoding相加之后的结果,我们称之为Word Embedding(词向量)。加上位置编码的原因是由于Transformer模型没有循环或卷积操作,为了让模型能够利用词的顺序信息,需要在输入嵌入层中加入位置编码。因为多个EncoderLayer是串联在一起,所以栈的其它EncoderLayer的输入是上一个EncoderLayer的输出。
经过多层计算之后,最后一个EncoderLayer的输出就是编码器的输出(编码器和解码器之间的隐状态)。该输出会送入解码器堆栈中的每一个DecoderLayer中。通常在代码实现中把这个输出叫做memory。编码器的输出就是对原始输入的高阶抽象表达,是在更高维的向量空间中的表示。
输入的维度一般是[batch_size, seq_len, embedding_dim]。为了方便残差连接,每一个EncoderLayer输出的矩阵维度与输入完全一致。其形状也是[batch_size, seq_len, embedding_dim]。这样的设计也确保了模型在多个编码器层之间能够有效地传递和处理信息,同时也为更复杂的计算和解码阶段做好了准备。
1.3 流程
我们继续细化编码流程。一个Transformer编码块做的事情如下图所示。图中分为两部分,既包括编码器,也包括其输入(为了更好的说明,把处理输入部分也涵盖进来)。
- 上面部分( #2)就是Encoder模块里的一个独立的EncoderLayer。这个模块想要做的事情就是想把输入X转换为另外一个向量R,这两个向量的维度是一样的。然后向量R作为上一层的输入,会一层层往上传。
- 下面部分(#1)的是两个单词的embedding处理部分,即EncoderLayer的输入处理部分。
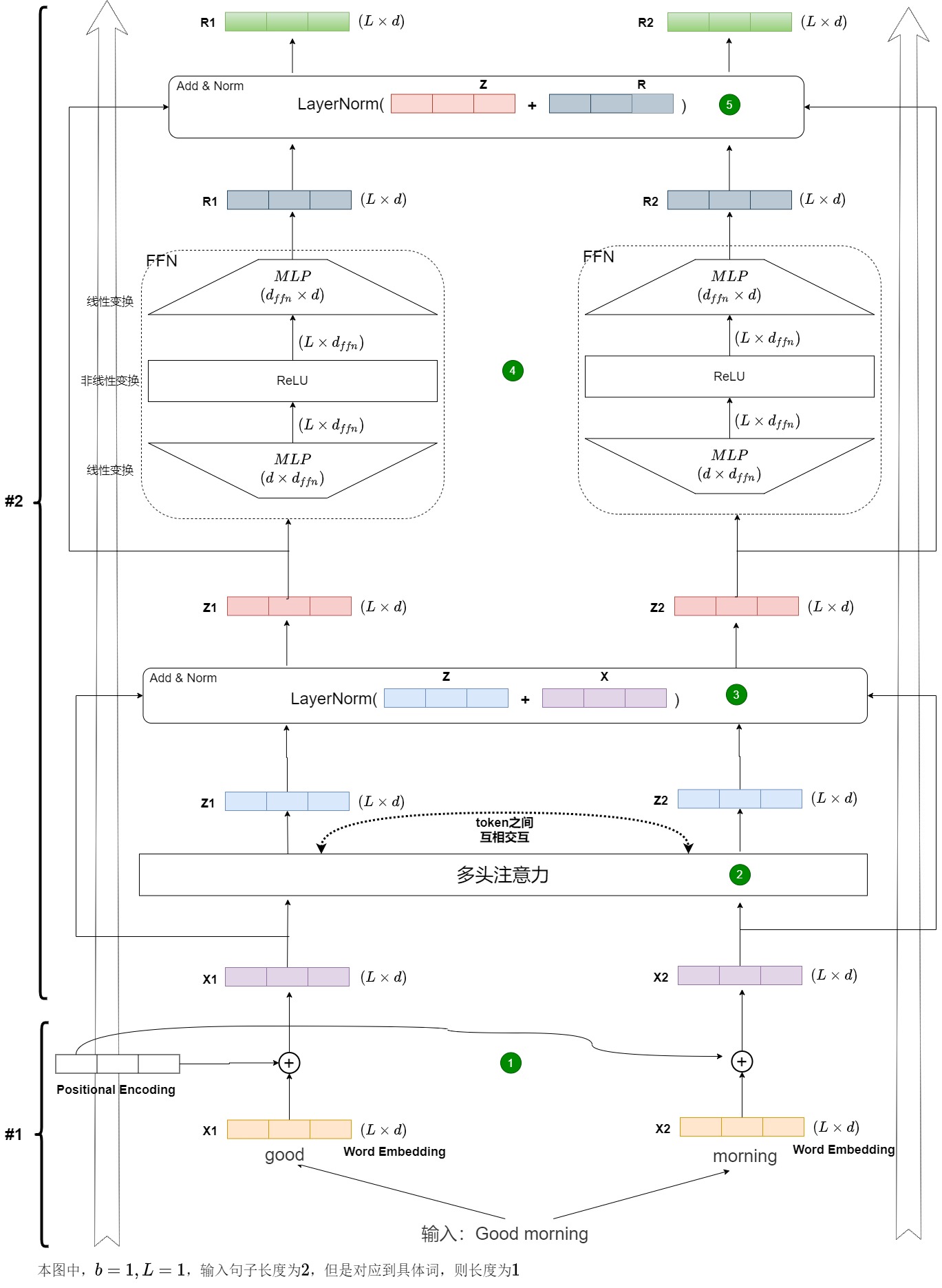
我们对上图流程分析如下。
- 第一步会用token embedding和位置编码来生成word embedding,对应图上圆形标号1。
- 第二步是自注意力机制,对应图上圆形标号2,具体操作是 s o f t m a x ( Q K T ) V softmax(QK^T)V softmax(QKT)V。所有的输入向量共同参与了这个过程,也就是说,X1和X2通过某种信息交换和杂糅,分别得到了中间变量Z1和Z2。自注意力机制就是句子中每个单词看看其它单词对自己的影响力有多大,本单词更应该关注在哪些单词上。在输入状态下,X1和X2互相不知道对方的信息,但因为在自注意力机制中发生了信息交换,所以Z1和Z2各自都有从X1和X2得来的信息。
- 第三步是残差连接和层归一化,对应图上圆形标号3。其具体操作是 N o r m ( x + S u b l a y e r ( x ) ) Norm(x+Sublayer(x)) Norm(x+Sublayer(x))。
- 第四步是FFN层,对应图上圆形标号4。对应操作是 m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 max(0, xW_1 + b_1)W_2 + b_2 max(0,xW1+b1)W2+b2,即两层线性映射并且中间使用激活函数来激活。因为FFN是割裂开的,所以Z1和Z2各自独立通过全连接神经网络,得到了R1和R2。
- 第五步是第二个残差连接和层归一化,对应图上圆形标号5。其具体操作是 N o r m ( x + S u b l a y e r ( x ) ) Norm(x+Sublayer(x)) Norm(x+Sublayer(x))。
至此,一个EncoderLayer就执行完毕,其输出可以作为下一个EncoderLayer的输入,然后重复2~5步骤,直至N个EncoderLayer都处理完毕。我们也可以看到,每个输出项的计算和其他项的计算是独立的,即每一层的EncoderLayer都对输入序列的所有位置同时进行操作,而不是像RNN那样逐个位置处理,这是Transformer模型高效并行处理的关键。
1.4 张量形状变化
我们来看看编码过程中的张量形状变化。编码器的输入是待推理的句子序列X: [batch_size, seq_len, d_model]。
注意:如果考虑到限制最大长度,则每次应该是[batch_size, max_seq_len, d_model],此处进行了简化。
编码器内部数据转换时候的张量形状变化如下表所示,对于输入X的Input Embedding张量来说,其形状在编码器内部始终保持不变,具体如下。
- 输入层中,在做embedding操作时,张量形状发生变化;在和位置编码相加时,张量形状保持不变。
- 在编码器层内部的流转过程中,张量形状保持不变。
- 在编码器内部,即多个编码器层之间交互的过程中,张量形状保持不变。
下表给出了详细的操作和张量形状。
| 视角 | 操作 | 操作结果张量的形状 |
|---|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









