






目录
1、Helloworld:
# 可以输出数值
print(10)
print(10.1)
# 可以输出字符串
print('Helloworld')
print("Helloworld")
# 将字符串输出到文件中
# 注意:所指定的盘符需存在 、使用参数file=fp
fp = open('D:/text.txt', 'a+')
# a+表示如果文件不存在就创建,存在就在文件后追加
print('helloworld', file=fp)
fp.close()
2、保留字:
import keyword
print(keyword.kwlist)
# 命名规则:
# -变量、函数、类、模块和其他对象的起名就叫标识符
# -规则:
# 字母、数字、下划线
# 不能以数字开头
# 不能是保留字
# 严格区分大小写
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
3、字符编码:
print(chr(0b100111001011000))
print(ord('乘'))
4、转义字符:
# 转义字符
print('hello\nworld')
print('hello\tworld')
# /t有四个指标位
#源字符,不希望字符串中的转义字符起作用,就使用源字符,就是在字符串之前加上r或者R
print(r'hello\nworld')
#注意最后一个字符不可以是反斜杠,但可以是两个
#print(r'hrllo\nworld\')
print(r'hrllo\nworld\\')
5、变量:
name='玛丽亚'
print(name)
print('标识:',id(name))
print('类型:',type(name))
print('值:',name)
#标识: 2519379989424
# 数据类型:
# 1、整数类型
# 英文为Integer,简写为int
# 整数的不同进制的表示方式:
# -十进制:默认的进制
# -二进制:以0b开头
# -八进制:以0o开头
# -十六进制:以0x开头
# 2、浮点类型
# 浮点类型由整数部分和小数部分组成
# 浮点数存储不精确性
# 使用浮点数进行计算时,可能会出现小数点位数不确定的情况
n1=1.1
n2=2.2
n3=2.1
print(n1+n3) #3.2
print(n1+n2) #3.3000000000000003
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))#3.3
# 3、布尔类型
# 用来表示真假true/flase
# true->1
# false->0
# 4、字符串
# 字符串又被称为不可变的字符序列
# 可以使用单引号、双引号、三引号来定义
# 单引号和双引号定义的字符串必须在同一行
# 三引号定义的字符串可以分布在连续的多行

print('---------------int转string-------------------')
age=18
print(type(name),type(age)) #说明两者类型不一样
#print('我叫'+name+'今年'+age+'岁')
#TypeError: can only concatenate str (not "int") to str
print('我叫'+name+'今年'+str(age)+'岁')
print('---------------str()将其他类型转换成str类型-------------------')
a=10
b=192.8
c=False
print(type(a),type(b),type(c))
print(str(a),str(b),str(c),type(str(a)),type(str(b)),type(str(c)))
print('---------------int()将其他类型转换为int类型-------------------')
s1='123'
f1=98.3
s2='76.77'
f2=True
s3='hello'
print(type(s1),type(f1),type(s2),type(f2),type(s3))
print(int(s1),type(int(s1))) #123
print(int(f1),type(int(f1))) #98
# print(int(s2),type(int(s2))) 将小数字符串转换为int 报错
# print(int(f2),type(int(f2))) 布尔类型转换为int 报错
# print(int(s3),type(int(s3))) 字符串转为int 报错 字符串为非数字字符串
print('----------------float()函数,将其他类型转为float类型--------------')
s1='123.23'
f1='98'
s2=76
f2=True
s3='hello'
print(type(s1),type(f1),type(s2),type(f2),type(s3))
# print(float(s1),type(int(s1)))
print(float(f1),type(int(f1))) #98.0
print(float(s2),type(int(s2))) #76.0
print(float(f2),type(int(f2))) #1.0
# print(float(s3),type(int(s3)))
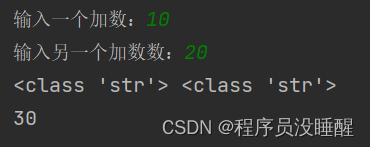
6、input() 输入函数:
使用input()函数,默认是字符类型,因此我们需要做类型转换
b=input("输入另一个加数数:")
print(type(a),type(b))
print(a+b)

7、运算符:
7.1算数运算符

7.2、赋值运算符
7.3、比较运算符
7.4、布尔运算符
7.5、位运算
7.6、运算符的优先级
8、列表:
print('------------append-------------')
lst=[10,20,30]
print('添加元素之前\n',lst,id(str))
lst.append(40)
print('添加元素之后\n',lst,id(str))
# 添加元素之前
# [10, 20, 30] 140736887016544
# 添加元素之后
# [10, 20, 30, 40] 140736887016544
print('--------------extend------------')
lst2=['hello','world']
# lst.append(lst2) # 将lst2作为一个元素添加到列表lst的末尾
# print(lst) #[10, 20, 30, 40, ['hello', 'world']]
lst.extend(lst2)
print(lst) #[10, 20, 30, 40, 'hello', 'world']
print('--------------insert-------------')
lst.insert(1,100)
print(lst)
print('-------------切片-----------------')
lst3=[True,False]
lst[1:]=lst3
print(lst)
# [10, 100, 20, 30, 40, 'hello', 'world'] --->[10, 100, 20, 30, 40, 'hello', 'world']
1、remove():一次删除一个元素、重复元素只删除第一个、元素不存在抛出ValueError
2、pop():删除一个指定索引位置上的元素、指定索引不存在抛出IndexError、不指定索引就删除列表中最后一个元素
# remove
lst=[1,5,2,3,4,5]
lst.remove(1) # [5, 2, 3, 4, 5]
lst.remove(5) # [1, 2, 3, 4, 5]
print(lst)
# pop
lst1=[1,2,3,4,5]
lst1.pop(1) # [1, 3, 4, 5]
lst1.pop() # [1, 2, 3, 4]
print(lst1)
# 切片
lst2=[1,2,3,4,5]
lst2_after=lst2[2:]
print(lst2_after) # [3, 4, 5]
# clear
lst3=[1,2,3,4,5]
lst3.clear()
print(lst3)
# del
lst4=[1,2,3,4,5]
del lst4
print(lst4) # NameError: name 'lst4' is not defined. Did you mean: 'lst'? --找不到了
调用sort()方法,列中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse=True,进行降序排序
调用内置函数sorted(),可以指定reverse=True,进行降序排序,原列表不发生改变
lst=[4,2,3,1]
lst.sort()
print(lst) # [1, 2, 3, 4]
lst.sort(reverse=True)
print(lst) # [4, 3, 2, 1]
lst=[4,2,3,1]
lst_after=sorted(lst)
print(lst_after) # [1, 2, 3, 4]
lst_desc=sorted(lst,reverse=True)
print(lst_desc) # [4, 3, 2, 1]
lst=[i for i in range(1,10) ] # [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(lst)
lst1=[i*i for i in range(1,10)] # [1, 4, 9, 16, 25, 36, 49, 64, 81]
print(lst1)
9、字典:
score={'张三':90,'李四':80}
print(score['张三'])
# print(score['陈六']) #keyError:‘陈六’
print(score.get('李四'))
# print(score['陈六']) #None
print(score.get('麻七',99)) # 99是在查找麻七所对的value不存在时,提供一个默认值
# key的判断
score={'张三':90,'李四':80,'王五':70}
print('张三' in score) # True
print('张三' not in score) # false
# 删除字典元素
del score['张三']
print(score) # {'李四': 80, '王五': 70}
score.clear()
print(score) #清空
# 添加元素
score['陈六']=60
print(score)
# 修改元素
score['陈六']=30
print(score)
score={'张三':90,'李四':80,'王五':70}
keys = score.keys()
print(keys)
print(type(keys))
print(list(keys))
# dict_keys(['张三', '李四', '王五'])
# <class 'dict_keys'>
# ['张三', '李四', '王五']
values = score.values()
print(values)
print(type(values))
print(list(values))
# dict_values([90, 80, 70])
# <class 'dict_values'>
# [90, 80, 70]
items = score.items()
print(items)
print(type(items))
print(list(items))
# dict_items([('张三', 90), ('李四', 80), ('王五', 70)])
# <class 'dict_items'>
# [('张三', 90), ('李四', 80), ('王五', 70)]
# 转换之后的队列元素时由元组组成
·字典中所有元素都是一个key-value对,key不允许重复,value可以重复
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表

items=['Fruits','Books','Others']
prices=[96,78,85]
d={item:price for item,price in zip(items,prices)}
print(d)
10、元组
# 方式1:
t=('Python','Hello',90)
print(t)
print(type(t))
# 只包含一个元组的元素需要使用小括号和逗号
t0=(12,)
print(t0)
print(type(t0))
# 方式2:
t1='Python','Hello',90
print(t1)
print(type(t1))
# 方式3:
t2=tuple(('Python','Hello',90))
print(t2)
print(type(t2))
# ('Python', 'Hello', 90)
# <class 'tuple'>
# (12,)
# <class 'tuple'>
# ('Python', 'Hello', 90)
# <class 'tuple'>
# ('Python', 'Hello', 90)
# <class 'tuple'>
#遍历
for item in t:
print(item)
11、集合:
'''集合的创建'''
t={1,2,3,4,5}
print(t,type(t)) # {1, 2, 3, 4, 5} <class 'set'>
t1=set((1,2,3,4,5))
print(t1,type(t1)) # {1, 2, 3, 4, 5} <class 'set'>
# 集合的特性:集合中的元素不能重复
t2={1,2,2,3,3,4,4}
print(t2) # {1, 2, 3, 4}
'''集合中元素的判断'''
print(1 in t) # True
'''创建空集合'''
# s={} 若直接使用花括号,其类型为dict
s={()}
print(type(s))
s1=set()
print(type(s1))
'''向集合中添加元素'''
s.add(1)
print(s) # {1, ()}
s1.add(1)
print(s1)# {1}
# add一次添加一个元素
s.clear()
s.update((1,2,3))
s.update([4,5,6])
s.update({7,8,9})
print(s,type(s))
# {1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
# update 一次至少添加一个元素
'''集合元素的删除操作'''
s.remove(1) # 一次删除一个指定元素,如果指定的元素不存在抛出KeyError
print(s)
s.pop() # 一次只删除一个任意元素
print(s)
s.discard(3) # 一次删除一个指定元素,如果指定的元素不存在不抛出异常
print(s)
s.clear() # 清空集合
print(s)

'''集合的数据操作'''
'''(1)交集'''
s1={1,2,3,4,5,6,7,8,9}
s2={4,5,6,7,8,9}
print(s1.intersection(s2))
# {4, 5, 6, 7, 8, 9}
print(s1 & s2)
# {4, 5, 6, 7, 8, 9}
# &和intersection类似,为交集操作
'''(2)并集操作'''
print(s1.union(s2)) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
print(s1 | s2) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
# |和union类似,为并集操作
'''(3)差集操作'''
print(s1.difference(s2)) # {1, 2, 3}
print(s1-s2) # {1, 2, 3}
# -和difference类似,为差集操作
'''(4)对称差集'''
print(s1.symmetric_difference(s2)) # {1, 2, 3}
print(s1 ^ s2) # {1, 2, 3}
# ^和symmetric_difference类似,为对称差集操作

12、字符串:
当需要值相同的字符串时,可以直接从字符串池中拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的
在需要进行字符串拼接时建议使用str类型的join方法,而非+,因为join()方法时先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率比+效率高
| 居中对其,第一个参数指定宽度,第二个参数指定填充符号,第二个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串 | ||
| 左对齐,第一个参数指定宽度,第二个参数指定填充符号,第二个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串 | ||
| 右对齐,第一个参数指定宽度,第二个参数指定填充符号,第二个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串 | ||
s='Hello'
print(s.center(20))
print(s.ljust(20,'*'))
print(s.rjust(20,'*'))
print(s.zfill(20))
# Hello
# Hello***************
# ***************Hello
# 000000000000000Hello
print(lst) #输出的结果为列表形式:切分后的结果类型为列表
s='hello|world|Python'
lst=s.split(sep='|',maxsplit=1)
print(lst)
# ['hello', 'world|Python']
# maxsplit参数代表切分次数,sep参数指定其分隔符
| 第一个参数指定被替换的子串,第二个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第三个参数来指定最大替换次数 | ||
s='hello Python Python Python'
print(s.replace('Python','Java'),2)
例如:'我的名字叫:%s,今年%d岁了' % (name,age)
例如:'我的名字叫{0},今年{1}岁了'.format(name,age)
s='天涯共此时'
# 编码
print(s.encode(encoding='GBK')) # 在GBK这种编码格式中,一个中文占两个字节
print(s.encode(encoding='UTF-8')) # 在UTF-8这种编码格式中,一个中文占三个字节
# 解码
# byte代表就是一个二进制数据(字节类型的数据)
byte=s.encode(encoding='GBK') # 编码
print(byte.decode(encoding='GBK')) # 解码
byte=s.encode(encoding='UTF-8') # 编码
print(byte.decode(encoding='UTF-8')) # 解码
13、函数
【1】、如果函数没有返回值【函数执行完毕后,不需要给调用处提供数据】return可以省略不写
【1】、定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
print(args)
fun(10)
fun(10,20,30)
【1】、定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
print(kwargs)
fun1(a=10)
fun1(a=10,b=20,c=30)
14、异常处理机制:
·try……except……else……finally结构:
n1=int(input('pleace input an number:'))
n2=int(input('pleace input anther number'))
print('it's always print whatever yes or no')
ZeroDivisionError:除(或取模)零(所有数据类型)

15、对象:
class Student:
native_pace = '吉林'
def __init__(self, name, age):
self.name = name
self.age = age
# 对象方法
def eat(self):
print('在吃饭ing')
# 定义静态方法
@staticmethod
def method():
print('我是使用了@staticmethod修饰,所以我是静态方法')
# 定义类方法
@classmethod
def cm(cls):
print('我使用@classmethod来修饰,所以我是类方法')
def drink():
print('我在喝水')
stu1 = Student('张三',20)
stu1.eat()
print(stu1.name)
print(stu1.age)
print('---------------------')
Student.eat(stu1) # 此行与二十九行的功能都是相同的,都是在调用eat()方法
# 类名.方法名(类的对象)-->实际上就是方法定义处的self
-类属性:类中方法外的变量称为类属性,被该类的所有对象所共享
-类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
-静态方法:使用@staticmethod修饰的方法,使用类名直接访问的方法
print(Student.native_place) # 访问类属性
def show():
print('定义在类之外的称为函数')
stu1.show = show
stu1.show()
15.1、面向对象的三大特征:
-封装:提高程序的安全性
-将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度
-在Python中没有专门的修饰符用于属性的私有,如果该属性不希望再类对象外部被访问,前边使用两个“_”
class People:
def __init__(self,name,age):
self.name=name
self.__age=age
def look(self):
print(self.name,self.__age)
peo=People('张三',20)
peo.look()
print(peo.name)
# 但是仍可以访问
print(peo._People__age)
-继承:提高代码复用性
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print('姓名:{0},年龄:{1}'.format(self.name,self.age))
class Student(Person):
def __init__(self,name,age,score):
super().__init__(name,age)
self.score=score
class Teacher(Person):
def __init__(self,name,age,teachyear):
super().__init__(name,age)
self.teachyear=teachyear
stu=Student('Jack',20,80)
tea=Teacher('Lihua',45,10)
stu.info()
tea.info()
-如果子类对继承父类的某个属性或方法不满意,可以在子类中对其(方法体)进行重新编写
-子类重写后的方法中可以通过super().xxx()调用父类中被重写的方法
def __init__(self,name,age,score):
super().__init__(name,age)
self.score=score
def info(self):
super().info() # 重写父类中的方法
print('成绩:{0}'.format(self.score))
-object类是所有类的父类,因此所有类都有object类的属性和方法。
-object有一个_str_()方法,用于返回一个对于“对象的描述”,对应于内置函数str()经常用于print()方法,帮我们查看对象的信息,所以我们经常会对_str_()进行重写
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self): # 重写方法,该方法原本是对对象的描述
return '我的名字是{0},今年{1}岁了'.format(self.name,self.age)
stu=Student('张三',20)
print(dir(stu))
print(stu)
print(object)

-简单的说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法
class Animal:
def eat(self):
print('吃')
class Dog(Animal): #继承
def eat(self): #方法重写
print('狗吃骨头')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person(Animal):
def eat(self):
print('人吃五谷杂粮')
def fun(obj):
obj.eat()
fun(Dog())
fun(Cat())
fun(Person())
-动态语言的多态崇尚“鸭子类型”当看到一只鸟走起来像鸭子、游泳起来也像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为。
15.2、特殊方法和特殊属性:
class Person(object):
def __new__(cls, *args, **kwargs):
print('__new__被调用执行了,cls的id值未{0}'.format(id(cls)))
obj=super().__new__(cls)
print('创建的对象的id为{0}'.format(obj))
return obj
def __init__(self,name,age):
print('__init__被调用了,self的id为{0}'.format(id(self)))
self.name=name
self.age=age
print('object这个类对象的id为{0}'.format(id(object)))
print('Person这个类对象的id为{0}'.format(id(Person)))
#创建Person类的实例对象
p1=Person('张三',20)
print('P1这个Person类的实例对象的id;{0}'.format(id(p1)))

Python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同。
print(disk)
computer2=copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)
16、模块
16.1、os模块的常用函数:
import os
os.system('notepad.exe') #打开系统记事本功能
os.system('calc.exe') #打开系统的计算器
#直接调用可执行文件
os.startfile('C:\\Program Files\\Tencent\QQ\Bin\\qq.exe')
print(os.path.abspath())
print(os.path.exists())
print(os.path.join())
print(os.path.splitext())
17、文件的读写
17.1、语法规则:

print(file.readlines())
file.close()
17.2、常见的文件打开模式:
17.2.1、文本文件:
存储的是普通“字符”文本,默认位unicode字符集,可以使用记事本程序打开
17.2.2、二进制文件:
把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开,举例:mp3音频文件、jpj图片、。doc文档等
lst=['hello\n','python\n','world\n']
f.writelines(lst)
f.close()
with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件的正确关闭,一次来达到释放资源的目的

class Mycontent(object):
def __enter__(self):
print('enter方法被调用了')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit方法被调用执行力')
def show(self):
print('show方法被调用执行了')
with Mycontent() as file:
file.show()

with open('a.png','rb') as src_file:
with open('b.png','wb') as target_file:
target_file.write(src_file.read())
18、学生信息管理系统:
18.1、需求分析:



18.2、需求实现:
import os.path
import os
filename='student.txt'
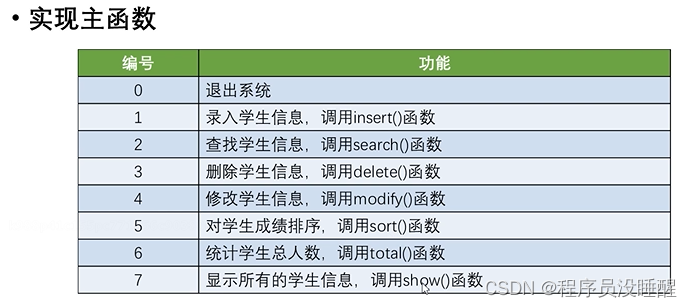
def main():
while True:
menum()
choice=int(input('请选择:'))
if choice in [1,2,3,4,5,6,7]:
if choice==0:
answer=input('您确定要退出系统吗?y/n')
if answer=='y' or answer=='Y':
print('谢谢您的使用!!!')
break
else:
continue
elif choice==1:
insert()
elif choice==2:
search()
elif choice==3:
delete()
elif choice==4:
modify()
elif choice==5:
sort()
elif choice==6:
total()
elif choice==7:
show()
def menum():
print('======================学生信息管理系统=====================')
print('-------------------------功能菜单-------------------------')
print('\t\t\t\t\t\t1、录入学生信息')
print('\t\t\t\t\t\t2、查找学生信息')
print('\t\t\t\t\t\t3、删除学生信息')
print('\t\t\t\t\t\t4、修改学生信息')
print('\t\t\t\t\t\t5、排序')
print('\t\t\t\t\t\t6、统计学生总人数')
print('\t\t\t\t\t\t7、显示所有学生信息')
print('\t\t\t\t\t\t0、退出')
print('---------------------------------------------------------')
def insert():
student_list=[]
while True:
id=input('请输入ID:')
if not id:
break
name=input('请输入姓名:')
if not name:
break
try:
english=int(input('请输入英语成绩:'))
python=int(input('请输入python成绩:'))
java=int(input('请输入java成绩:'))
except:
print('输入无效,请输入整数类型,请重新输入!!!')
continue
#将录入的学生信息保存到字典中
student={'id':id,'name':name,'english':english,'python':python,'java':java}
#将学生信息添加到列表中
student_list.append(student)
answar=input('是否继续添加?y/n:')
if answar=='y' or answar=='Y':
continue
else:
break
#调用save()函数
save(student_list)
print('学生信息录入成功!!!')
def save(lst):
try:
stu_txt=open(filename,'a',encoding='utf-8')
except:
stu_txt=open(filename,'w',encoding='utf-8')
for item in lst:
stu_txt.write(str(item)+'\n')
stu_txt.close()
def search():
student_query=[]
while True:
id=''
name=''
if os.path.exists(filename):
mode=input('按ID查找请输入1,按姓名查找请输入2:')
if mode=='1':
id=input('请输入学生ID:')
elif mode=='2':
name=input('请输入学生姓名:')
else:
print('您输入有误,请重新输入!!!')
search()
with open(filename,'r',encoding='utf-8') as rfile:
student=rfile.readlines()
for item in student:
d=dict(eval(item))
if id!='':
if d['id']==id:
student_query.append(d)
elif name!='':
if d['name']==name:
student_query.append(d)
#显示查询结果
show_student(student_query)
student_query.clear()
answer=input('是否继续查询y/n:')
if answer=='y' or answer=='Y':
search()
else:
break
def show_student(lst):
if len(lst)==0:
print('没有查询到学生信息,没有数据显示!!!')
return
#定义标题显示格式
format_title='{:^6}\t{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^8}'
print(format_title.format('ID','姓名','English成绩','Python成绩','JAVA成绩','总成绩'))
#定义内容的显示格式
format_data='{:^6}\t{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^8}'
for item in lst:
print(format_data.format(item.get('id'),
item.get('name'),
item.get('english'),
item.get('python'),
item.get('java'),
int(item.get('english')+item.get('python')+item.get('java'))))
def delete():
while True:
student_id=input('请输入需要删除的学生ID:')
if student_id!='':
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as file:
student_old=file.readlines()
else:
student_old=[]
flag=False # 标记是否删除
if student_old:
with open(filename,'w',encoding='utf-8') as wfile:
d={}
for item in student_old:
d=dict(eval(item)) # 将字符串转成字典
if d['id'] != student_id:
wfile.write(str(d)+'\n')
else:
flag=True
if flag:
print(f'id为{student_id}的生信息已被删除')
else:
print(f'id为{student_id}没有找到。')
else:
print('无学生信息')
break
show() # 删除之后要显示所有学生信息
answer=input('是否据徐删除?y/n:')
if answer=='y' or answer=='Y':
continue
else:
break
pass
def modify():
show()
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as rfile:
student_old=rfile.readlines()
else:
return
student_id=input('请输入学生ID:')
with open(filename,'w',encoding='utf-8') as wfile:
for item in student_old:
d=dict(eval(item))
if d['id']==student_id:
print('找到该学生,可以修改相关信息!!')
while True:
try:
d['english'] = int(input('请输入英语成绩:'))
d['python'] = int(input('请输入python成绩:'))
d['java'] = int(input('请输入java成绩:'))
except:
print('输入的类型有误,请输入整数!!!')
else:
break
wfile.write(str(d)+'\n')
print('修改完成!!!')
else:
wfile.write(str(d)+'\n')
answer=input('是否继续修改其他学生的成绩y/n')
if answer=='y' or answer=='Y':
modify()
def sort():
show()
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as rfile:
student_list=rfile.readlines()
student_new=[]
for item in student_list:
d=dict(eval(item))
student_new.append(d)
else:
return
asc_or_desc=input('请选择(0,升序 1,降序):')
if asc_or_desc=='0':
asc_or_desc_bool=False
elif asc_or_desc=='1':
asc_or_desc_bool=True
else:
print('你输入有误,请重新输入')
sort()
mode=input('请选择排序方式(1、按英语成绩排序 2、按python排序 3、按java排序 4、按总成绩排序)')
if mode==1:
student_new.sort(key=lambda x:int(x['english']),reverse=asc_or_desc_bool)
if mode==2:
student_new.sort(key=lambda x: int(x['python']), reverse=asc_or_desc_bool)
if mode==3:
student_new.sort(key=lambda x:int(x['java']),reverse=asc_or_desc_bool)
if mode==4:
student_new.sort(key=lambda x:int(x['english'])+int(x['python'])+int(x['java']),reverse=asc_or_desc_bool)
else:
print('您输入有误,请重新输入')
sort()
show_student(student_new)
def total():
student_query=[]
with open(filename,'r',encoding='utf-8') as rfile:
students=rfile.readlines()
for item in students:
student=dict(eval(item))
student_query.append(student)
if student_query:
print(f'一共有{len(student_query)}名学生')
else:
print('暂无学生信息')
def show():
student_list=[]
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as rfile:
students=rfile.readlines()
for item in students:
student_list.append(dict(eval(item)))
if student_list:
show_student(student_list)
else:
print('暂未获取学生信息')
if __name__ == '__main__':
main()
18.3、项目打包:
pyinstaller -F E:\Pycharm\PyCharm\WORK_FILE\学生管理系统\studentem.py

案例:
-水仙花:
#输出100到999之间的水仙花数
print("是水仙花数的有:")
for num in range(100,1000):
a = num // 100
b = num // 10 - a*10
c = num % 10
if num == a*a*a + b*b*b + c*c*c:
print(num)

-九九乘法表:
for i in range(1,10):
for j in range(1,i+1):
sum = i * j
print(str(i)+'*'+str(j)+'='+str(sum),end='\t') # 不换行输出
print()

-递归函数-阶乘:
c=a*b
return c
num=1
a=int(input("计算多少的阶乘"))
for i in range(1,a+1):
num=fun(num,i)
print(num)
if n==1:
return 1
else:
return n*fac(n-1)
print(fac(6))
-递归函数-斐波那契数列:
def fei(n):
if n == 1:
return 1
elif n == 2:
return 1
else:
return fei(n - 1) + fei(n - 2)
n = int(input("求前几位的斐波那契数:"))
for i in range(1, n + 1):
print(fei(i), end='\t')
def __init__(self,type,no):
self.type=type
self.no=no
def start(self):
pass
def stop(self):
pass
class Taxi(Car):
def __init__(self,type,no,company):
super().__init__(type,no)
self.company=company
def start(self):
print('乘客您好!')
print(f'我是{self.company}出租车公司的,我的车牌是{self.no},请问您要去哪里?')
def stop(self):
print('目的地到了,请您付款下车,欢迎再次乘坐')
class FamilyCar(Car):
def __init__(self,type,no,name):
super().__init__(type,no)
self.name=name
def stop(self):
print('目的地到了,我们去玩儿吧')
def start(self):
print(f'我是{self.name},我的汽车我做主')
if __name__ == '__main__':
taxi=Taxi('上海大众','京A9765','长城')
taxi.start()
taxi.stop()
print('-'*30)
familycar=FamilyCar('广汽丰田','京B88888','武大郎')
familycar.start()
familycar.stop()
-推算时间:
def inputdate():
indate=input('请输入开始日期:(20200808)后按回车:')
indate=indate.strip()
datestr=indate[0:4]+'-'+indate[4:6]+'-'+indate[6:]
return datetime.datetime.strptime(datestr,'%Y-%m-%d')
if __name__ == '__main__':
print('-----------------推算几天后的日期----------------------------')
sdate=inputdate()
in_num=int(input('请输入间隔天数:'))
fdate=sdate+datetime.timedelta(days=in_num)
print('您推算的日期是:'+str(fdate).split(' ')[0])
-模拟客服自动回复:
with open('replay.txt','r',encoding='gbk') as file:
while True:
line=file.readline()
if not line: #if line==''到文件末尾退出
break
#字符串的分割
keyword=line.split('|')[0]
reply=line.split('|')[1]
if keyword in question:
return reply
return False
if __name__ == '__main__':
question=input('Hi,您好,小蜜在此等主人很久了,有什么烦恼快和小蜜说吧')
while True:
if question=='bye':
break
#开始在文件中查找
replay=find_answer(question)
if not replay : #如果回复的是False , not False-->True
question=input('小蜜不知道你在说什么,您可以问一些关于订单、物流、账户、支付等问题,(退出请输入bye)')
else:
print(replay)
question=input('小主,你还可以继续问一些关于订单、物流、账户、支付等问题(退出请输bye)')
print('小主再见')
-定义一个圆类,计算器面积和周长:
class Circle(object):
def __init__(self,r):
self.r=r
def get_area(self):
return math.pi*math.pow(self.r,2)
def get_perimeter(self):
return 2*math.pi*self.r
if __name__ == '__main__':
r=int(input('请输入这个圆的半径'))
c=Circle(r)
print(f'圆的面积为:{c.get_area()}')
print(f'圆的周长为:{c.get_perimeter()}')
'''或'''
print('圆的面积为:{:.2f}'.format(c.get_area()))














 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









