







- 在原黑马点评基础上,新增以下功能:
- 完善用户退出登录
- 利用RocketMQ实现异步秒杀
- 利用ElasticSearch实现店铺按距离搜索,并解决深度分页性能问题
- 代码已上传gitee:https://gitee.com/l-jia-ying/hmdp
1. 黑马点评
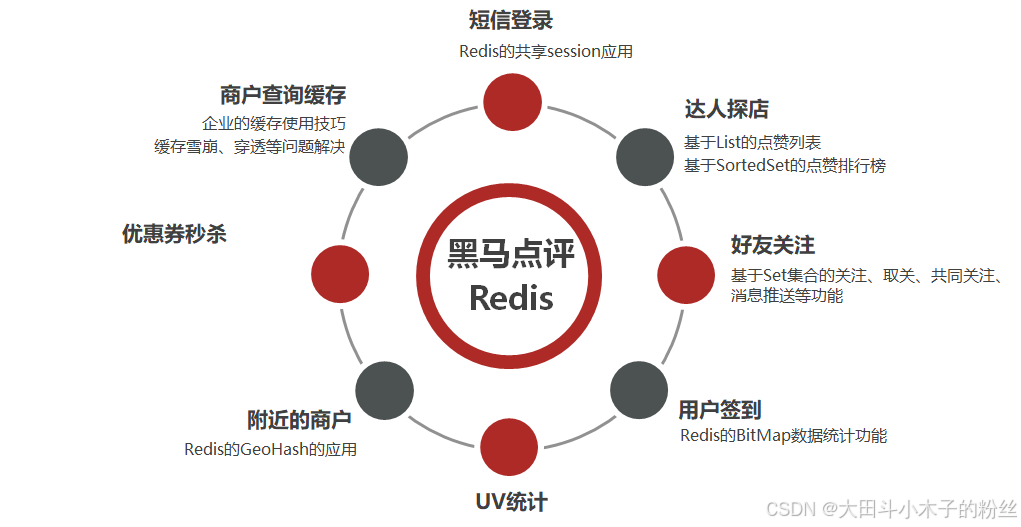
1.1 前置信息
1.1.1 数据库
- ltb_user:用户表
- ltb_user_info:用户详情表
- ltb_shop:商户信息表
- ltb_shop_type:商户类型表
- ltb_blog:用户日记表(达人探店日记)
- ltb_follow:用户关注表 ltb_voucher:优惠券
- ltb_voucher_order:优惠券的订单表
1.1.2 项目架构
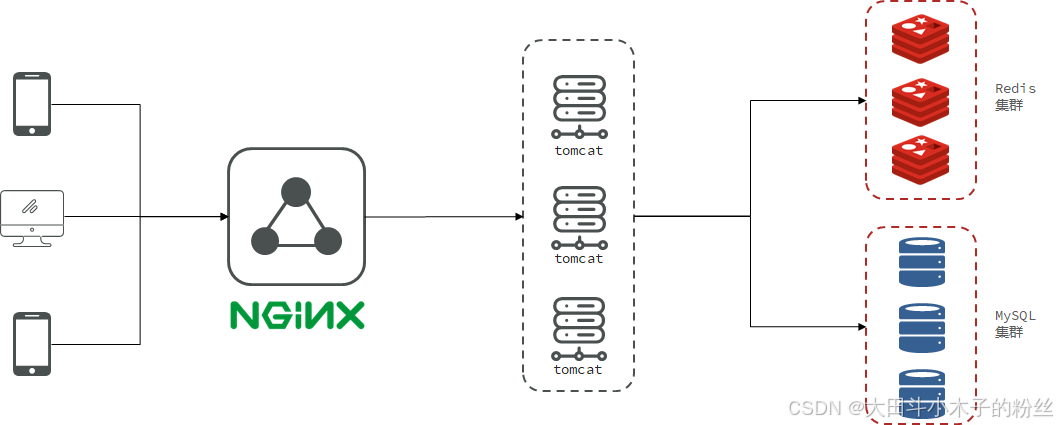
前端:8080
1.2 项目启动
1.2.1 启动项目报错
- 问题:NOGROUP No such key ‘stream.orders’ or consumer group ‘g1’ in XREADGROUP with GROUP option
XGROUP CREATE stream.orders g1 0 MKSTREAM - 问题:Error in execution; nested exception is io.lettuce.core.RedisCommandExecutionException: ERR unknown command
GEOSEARCH, with args beginning with:shop:geo:1,FROMLONLAT,120.149993,30.334229,BYRADIUS,5000.0,m,WITHDIST,COUNT,5,
需要redis版本在6.2以上,下载路径来源https://zhuanlan.zhihu.com/p/474260153
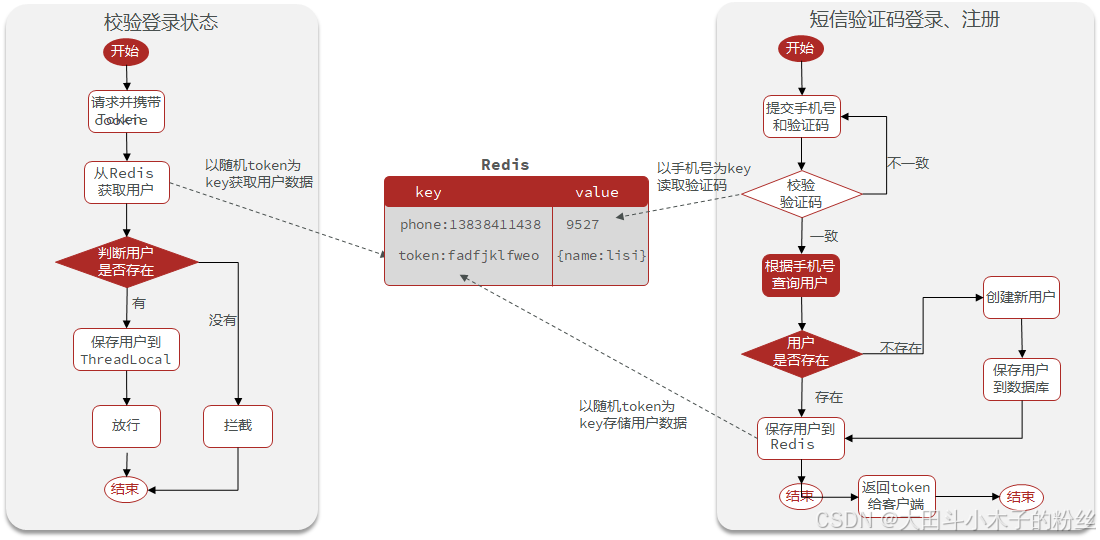
1.3 登录
1.3.1 基于session实现登录
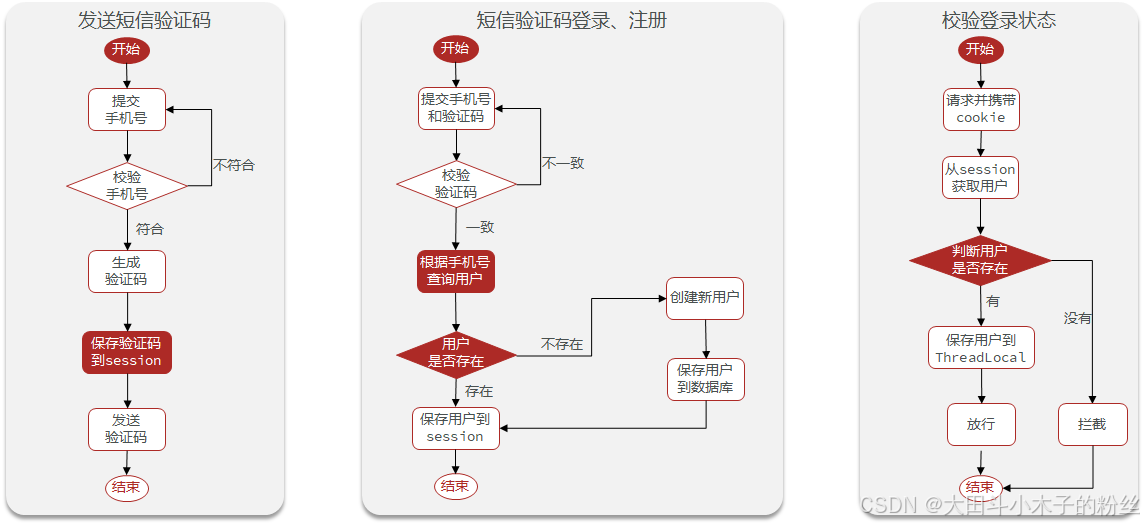
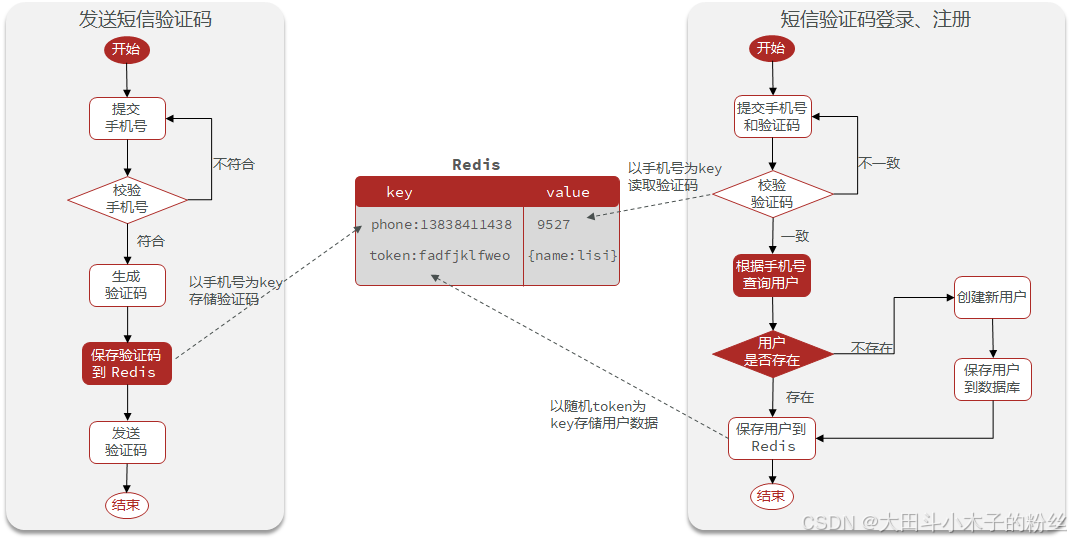
1.3.2 基于Redis实现短信登录
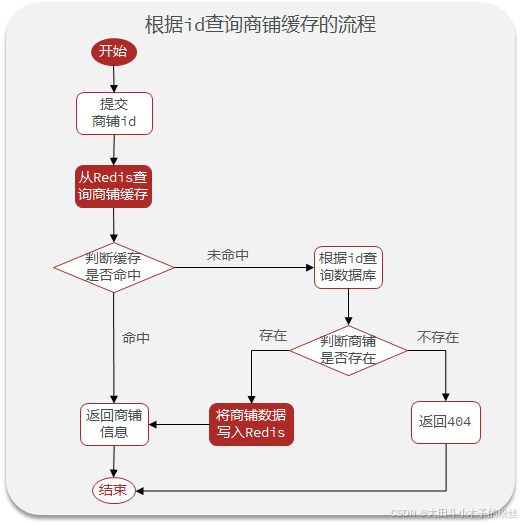
1.4 商户查询缓存
缓存:读写性能较高
1.4.1 添加Redis缓存
之前:20.94ms 之后:11.94ms
店铺缓存:string类型
店铺类型缓存:list类型
用户缓存:hash类型
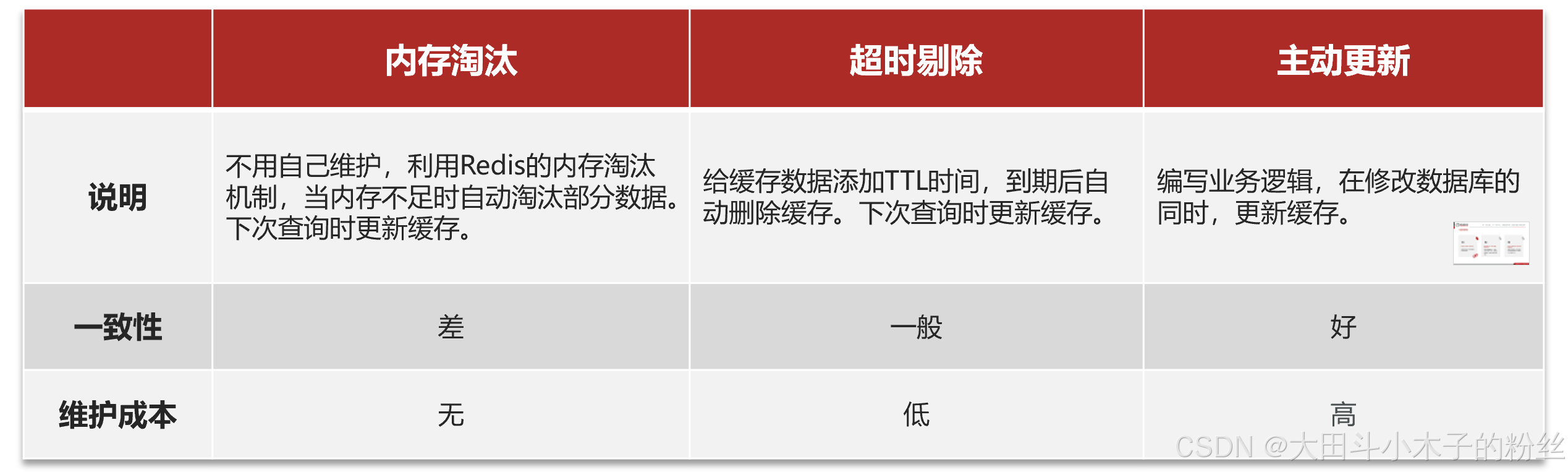
1.4.2 缓存更新策略
- 业务场景:
低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存
高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
1.4.2.1 主动更新策略
- 删除缓存还是更新缓存?
更新缓存:每次更新数据库都更新缓存,无效写操作较多
删除缓存:更新数据库时让缓存失效,查询时再更新缓存√ - 如何保证缓存与数据库的操作的同时成功或失败?
单体系统,将缓存与数据库操作放在一个事务
分布式系统,利用TCC等分布式事务方案 - 先操作缓存还是先操作数据库?(多线程并发)
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存
缓存更新策略的最佳实践方案:
- 低一致性需求:使用Redis自带的内存淘汰机制
- 高一致性需求:主动更新,并以超时剔除作为兜底方案
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,设定超时时间
- 写操作:
- 先写数据库,然后再删除缓存
- 要确保数据库与缓存操作的原子性
- 读操作:
1.4.3 缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
解决方案
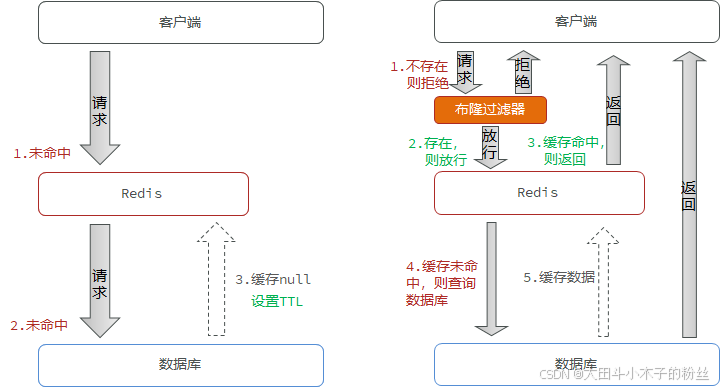
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:额外的内存消耗(设置短期TTL);可能造成短期的不一致
- 布隆过滤
- 保存二进制数据,不是百分百准确
- 优点:内存占用较少,没有多余key
- 缺点:实现复杂;存在误判可能
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
1.4.3.1 布隆过滤器实现
布隆过滤器的核心思想是存储的是元素的哈希值,可以快速判断一个元素是否可能存在,这样可以有效拦截非法请求,减少对数据库的直接访问。
| 操作 | 说明 |
|---|---|
| 可能存在 | 数据可能存在,但不能 100% 确定 |
| 一定不存在 | 该数据绝对不存在 |
- 引入 Guava 依赖
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.1-jre</version> <!-- 最新版本 --> </dependency> - 初始化布隆过滤器
@Component @Slf4j public class BloomFilterInitializer { private static BloomFilter<Long> bloomFilter; @Resource private ShopMapper shopMapper; @PostConstruct public void initBloomFilter() { //1.从数据库中加载所有存在的店铺ID List<Long> ids = shopMapper.selectObjs(Wrappers.<Shop>query().select("id") ) .stream() .map(obj -> ((Number) obj).longValue()) .collect(Collectors.toList()); //2. 初始化布隆过滤器(预计元素100万,误判率1%) bloomFilter = BloomFilter.create( Funnels.longFunnel(), 1_000_000L, 0.01 ); //3. 将数据库中的店铺id加入布隆过滤器 ids.forEach(bloomFilter::put); log.info("布隆过滤器初始化完成,共存入 {} 个店铺 ID", ids.size()); } public static BloomFilter<Long> getBloomFilter() { return bloomFilter; } } - 在查询逻辑中使用布隆过滤器
@Override public Result queryById(Long id) { // 使用布隆过滤器拦截不存在的ID if (!BloomFilterInitializer.getBloomFilter().mightContain(id)){ log.info("店铺不存在,id={}",id); return Result.fail("店铺不存在"); } String shopJson = stringRedisTemplate.opsForValue().get(RedisConstants.CACHE_SHOP_KEY + id); //缓存命中,直接返回 if (StrUtil.isNotBlank(shopJson)){ Shop shop = JSONUtil.toBean(shopJson, Shop.class); return Result.ok(shop); } // 缓存穿透,判断是否为空值 if(shopJson != null){ return Result.fail("店铺不存在"); } Shop shop = getById(id); if(shop == null){ stringRedisTemplate.opsForValue().set(RedisConstants.CACHE_SHOP_KEY+id,"",RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES); return Result.fail("店铺不存在"); } stringRedisTemplate.opsForValue().set(RedisConstants.CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shop),RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES); return Result.ok(shop); }
1.4.4 缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
- 解决方案
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性(解决宕机情况 Redis哨兵机制、主从机制)
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存(Nginx缓存…)
- 集成Caffine、Redis实现双重缓存
- https://blog.csdn.net/m0_52031708/article/details/142862864
1.4.5 缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击
-
常见解决方案
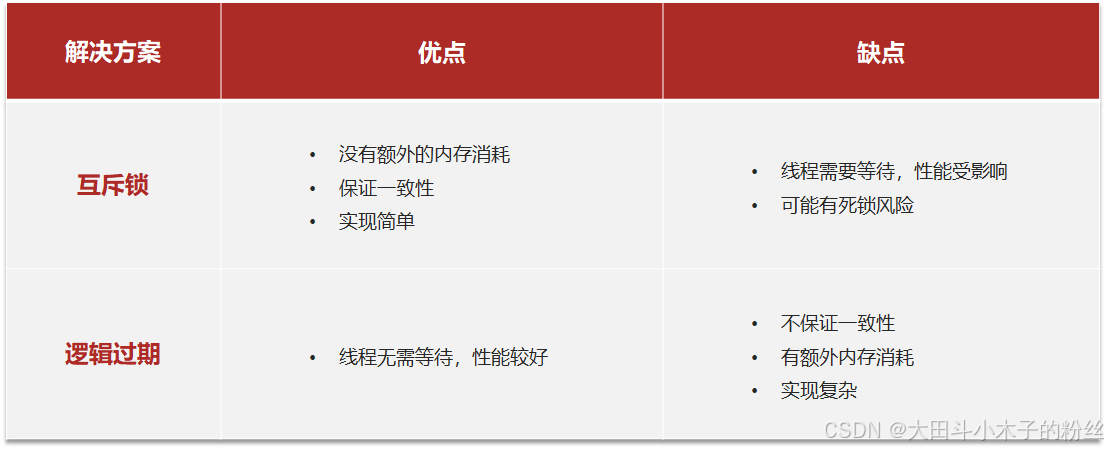
-
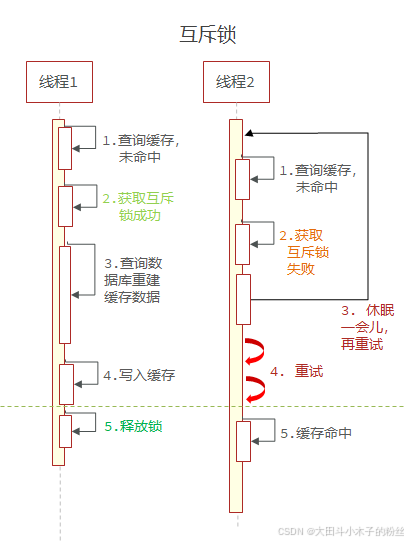
互斥锁
-
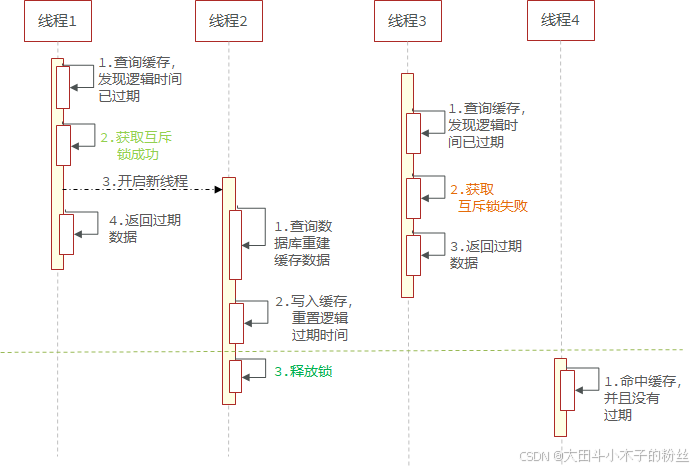
逻辑过期
不设置TTL,存储时添加过期时间信息
-
1.4.5.1 基于互斥锁方式解决缓存击穿问题
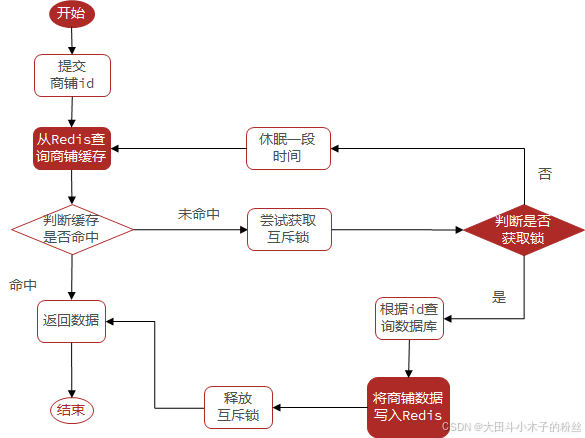
setnx 只有第一个可以写成功
设置5s启动1000个线程,吞吐量199.7
1.4.5.2 基于逻辑过期方式解决缓存击穿问题
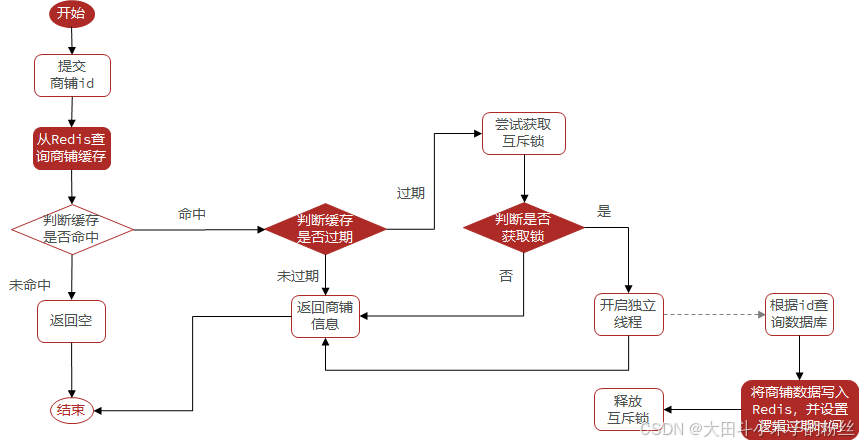
所有的热点key都会一直存在,直到活动结束
1.4.5 缓存工具封装
1.5 优惠券秒杀
1.5.1 全局唯一ID
当用户抢购时,会生成订单并保存到tb_voucher_order这张表中,订单如果使用数据库自增ID就存在一些问题:
- id规律性太明显
- 受单表数据量的限制
- 分布式存储,单表自增会出现id重复的问题
解决方案
- UUID(无法自增)
- Redis自增
- snowflake算法
- 数据库自增(单独维护一张表记录id)
1.5.1.1 全局ID生成器
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:唯一性、高可用、高性能、递增性、安全性
- Redis自增ID策略
- 每天一个key,方便统计订单量
- ID构造是 时间戳 + 计数器
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:

ID的组成部分:
- 符号位:1bit,永远为0
- 时间戳:31bit,以秒为单位,可以使用69年
- 序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
1.5.2 实现优惠券秒杀下单
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀采购
- tb_voucher:优惠券的基本信息,优惠金额、使用规则等
- tb_seckill_voucher:优惠券的库存、开始抢购时间,结束抢购时间。特价优惠券才需要填写这些信息
1.5.2.1 超卖问题
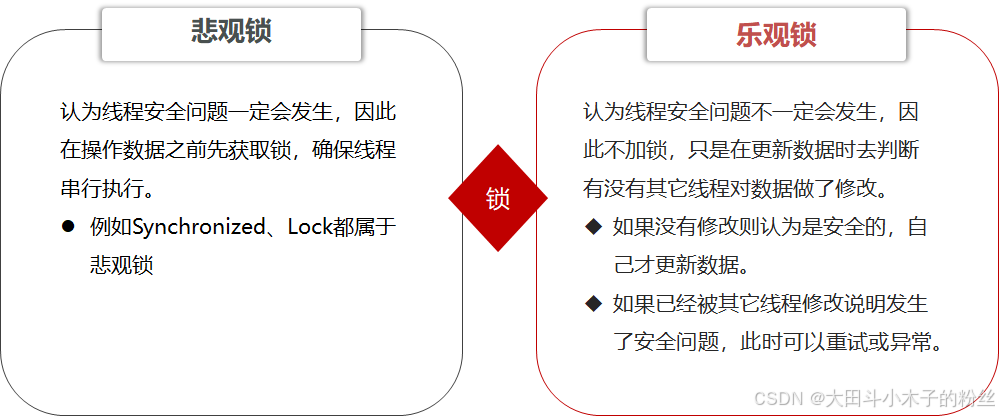
- 悲观锁:添加同步锁,让线程串行执行
- 优点:简单粗暴;缺点:性能一般
- 乐观锁:不加锁,在更新时判断是否有其他线程在修改
- 优点:性能好;缺点:存在成功率低的问题
- 分段锁:解决成功率低的问题
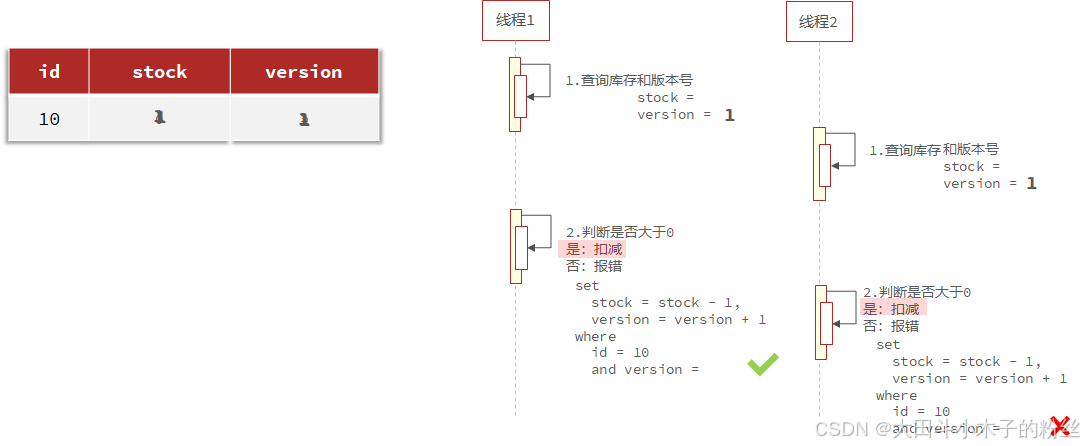
乐观锁的关键是判断之前查询到的数据是否被修改过,常见的方式有两种:
-
版本号法
-
CAS法(Compare and Set)
不需要version,比较stock值是否相同
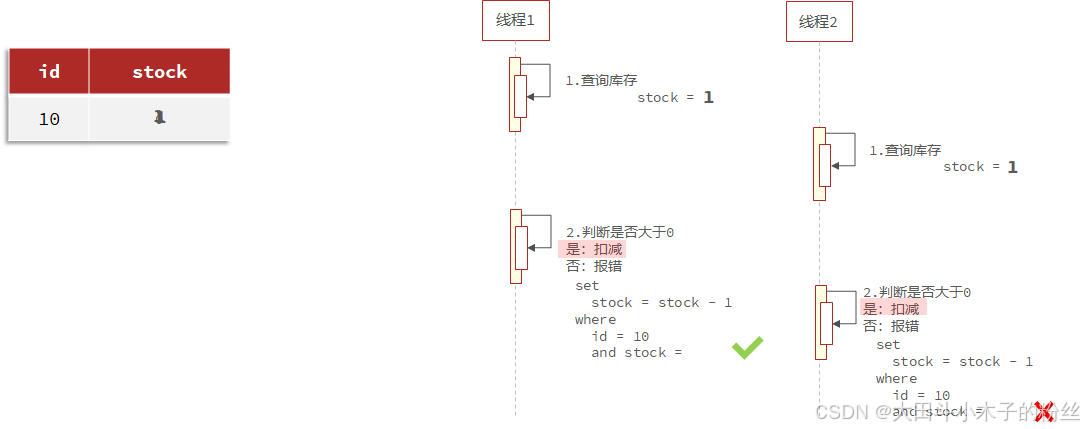
问题:没有超卖,但是没卖完。成功率太低
1.5.2.2 一人一单
根据优惠券id和用户id查询订单,判断订单是否已经存在
给用户id加锁,悲观锁
-
添加依赖
<dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> </dependency> -
启动类添加注解,暴露代理对象
@EnableAspectJAutoProxy(exposeProxy = true) -
实现
mysql默认采用可重复读,先开事务,线程A和线程B拿到的库存都是1000。如果在createVoucherOrder内部加锁,锁释放后,事务才会提交。当A线程释放锁,库存变为999,但事务还没提交时,此时B线程进入,库存仍为1000
方案一:在调用方法时加锁,问题:分布式场景下失效
方案二:使用mysql行锁,不适合用于并发量大的场景,会将压力都给数据库
方案三:使用redis分布式锁 setnx命令
```
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
// Voucher voucher = voucherMapper.selectById(voucherId);
SeckillVoucher seckillVoucher = seckillVoucherMapper.selectById(voucherId);
if (seckillVoucher==null){
return Result.fail(“没有该优惠券!”);
}
// 2.判断秒杀是否开始和结束
if(seckillVoucher.getBeginTime().isAfter(LocalDateTime.now())){
return Result.fail(“秒杀尚未开始!”);
}
if(seckillVoucher.getEndTime().isBefore(LocalDateTime.now())){
return Result.fail(“秒杀已经结束!”);
}
// 3.判断库存是否充足
if(seckillVoucher.getStock()<1){
return Result.fail(“库存不足!”);
}
Long userId = UserHolder.getUser().getId();
// 对单一用户加锁,同时保证先提交事务,再释放锁
synchronized (userId.toString().intern()){
//默认使用this调用,拿到的是当前的voucherOrderServiceImpl对象,而不是代理对象
//事务生效,是因为spring对当前类做了代理,拿到了代理对象,用代理对象做事务处理
//会导致spring事务失效
//拿到当前对象 IVocherOrderService 的代理对象
// 获取代理对象(事务)
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
}
}
// 锁不能直接加在方法上,要对单个用户加锁
@Transactional
public Result createVoucherOrder(Long voucherId) {
// 一人一单
Long userId = UserHolder.getUser().getId();
// 事务在锁结束之后才提交
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 判断用户是否已经购买过
if(count>0){
return Result.fail("不能重复下单!");
}
// 4.扣减库存
boolean success = seckillVoucherService.update().
setSql("stock=stock-1").
eq("voucher_id", voucherId).gt("stock",0).update();
if (!success){
return Result.fail("库存不足!");
}
long id = redisIdWorker.nexId("order");
VoucherOrder voucherOrder = new VoucherOrder();
voucherOrder.setId(id);
voucherOrder.setUserId(userId);
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
return Result.ok(id);
}
```
1.5.2.3 一人一单的并发安全问题
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了
锁的原理是在JVM内部维护一个锁监视器,userId在常量池里,id相同时是同一个锁,锁的监视器是同一个。当做集群部署时,有多套JVM,有各自的堆栈方法区,就会有新的锁监视器
产生安全问题原因:在集群模式下,或者有些是在分布式系统下,有多个JVM的存在,每个JVM内部都有自己的锁,导致每个锁都可以有一个线程获取,于是就出现并行运行,那么就可能出现安全问题
1.5.3 分布式锁
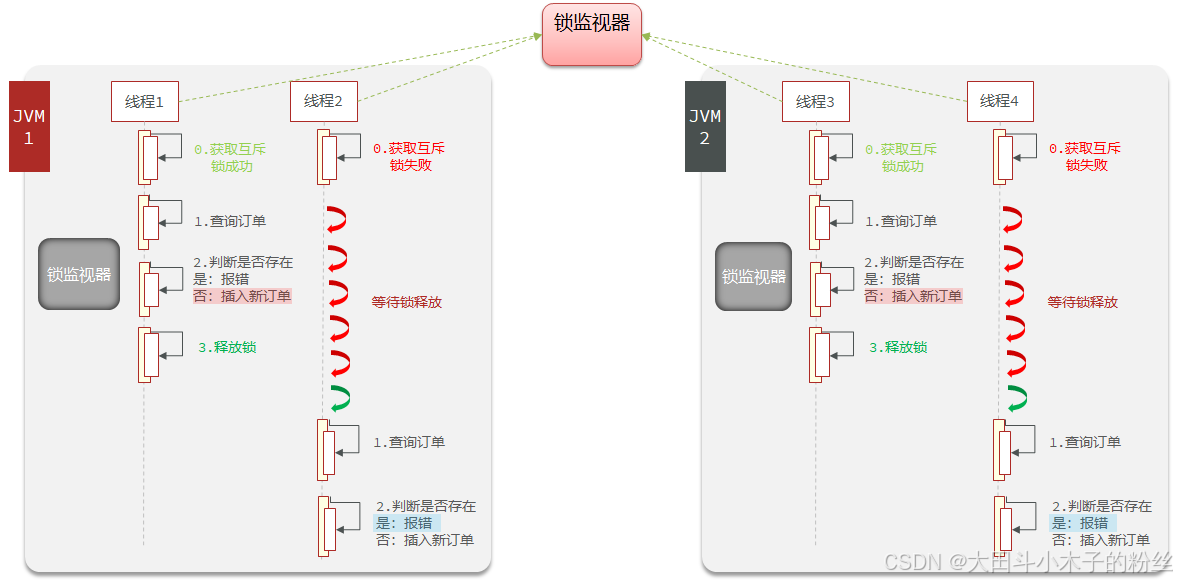
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁
- 分布式锁的实现
- MySQL:在业务执行前先去MySQL申请一个互斥锁,然后去执行业务,业务执行完之后再提交事务,释放锁。当操作异常时,触发回滚,锁自动释放
- Redis:利用setnx的互斥命令,只有数据不存在时才能成功
- Zookeeper:利用节点的唯一性和有序性实现互斥
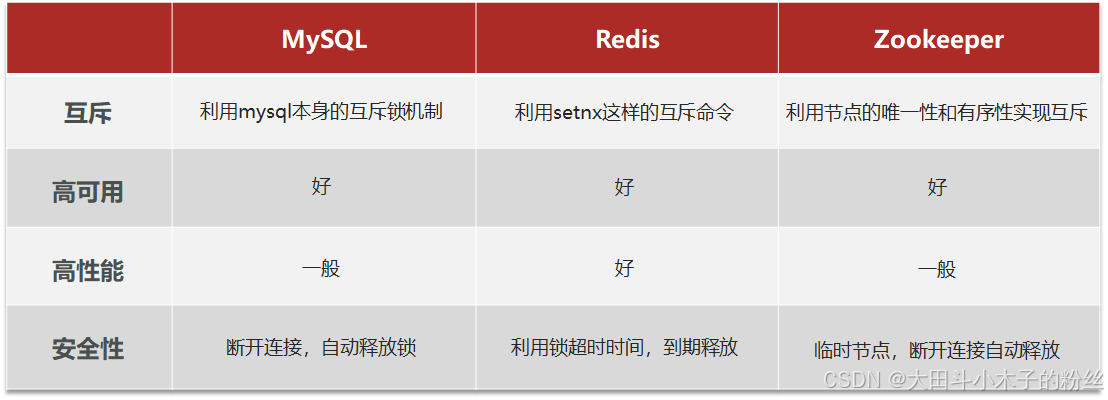
1.5.3.1 基于Redis的分布式锁
基于Redis的分布式锁实现思路:
- 利用set nx ex获取锁,并设置过期时间,保存线程标示
- 释放锁时先判断线程标示是否与自己一致,一致则删除锁
特性: - 利用set nx满足互斥性
- 利用set ex保证故障时锁依然能释放,避免死锁,提高安全性
- 利用Redis集群保证高可用和高并发特性
1.5.3.1.1 问题1:获取锁之后,服务宕机了,没有释放锁机制,会出现死锁
- 解决方法:添加超时释放,获取锁时添加一个超时时间。但是必须保证setnx和expire两个操作的原子性,
SET lock thread1 NX EX 10一条命令实现 - 如果获取失败,有两种方式:阻塞式(等待重试)和非阻塞式(直接返回)
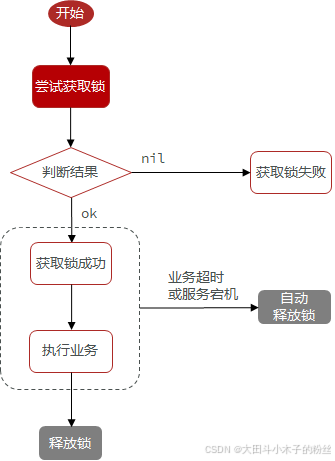
1.5.3.1.2 问题2:线程阻塞,会释放其他线程的锁
- 解决方法:利用锁标识判断是否一致。线程ID仅仅能用来区分同一JVM线程,UUID可以用来区分不同的JVM线程
- 在获取锁时存入线程标示(可以用UUID表示)(原来存的线程ID,线程ID在JVM是递增的,多个JVM可能会存在相同的线程ID)
- 在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致
- 如果一致则释放锁
- 如果不一致则不释放锁
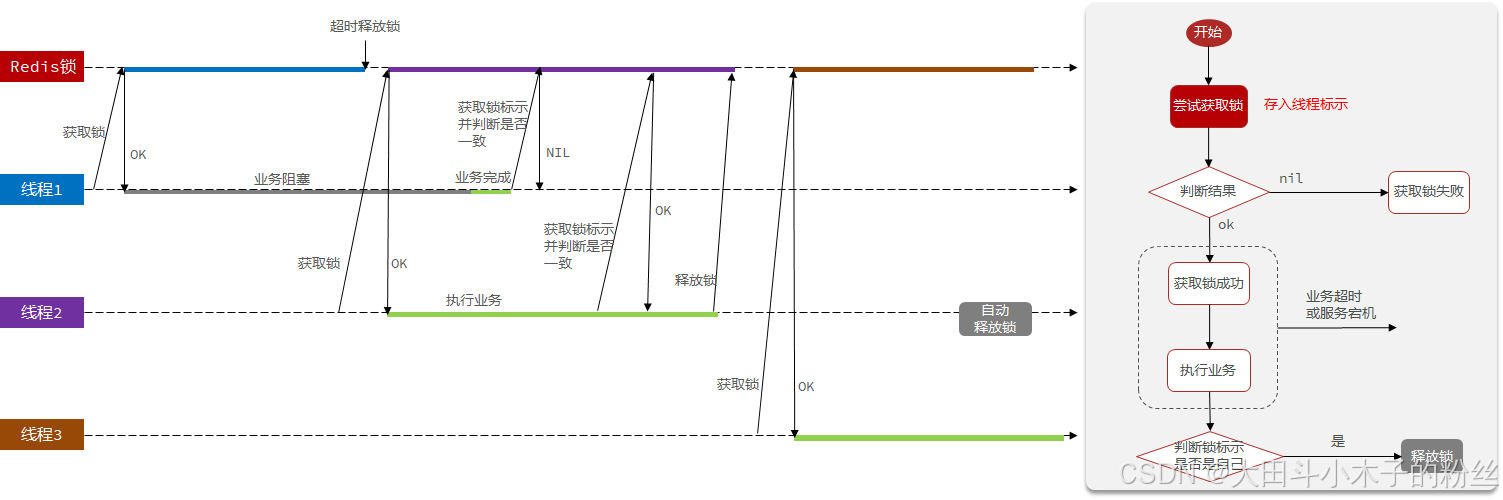
1.5.3.1.3 问题3:释放锁时发生阻塞,误删锁
在线程1要释放锁时发生阻塞(JVM垃圾回收,会阻塞所有代码),阻塞时间过长,超时释放锁,此时线程1判断已经通过,但如果已经有其他线程新加了自己的锁,线程1就会删掉线程2的锁
- 必须确保判断锁标识的操作和删除锁的操作是原子性操作
- Redis事务能够保证原子性,不能保证一致性,其实是批处理
- 利用Lua脚本,调用RedisTemplate execute命令
1.5.3.2 Lua脚本
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言
- Redis提供的调用函数:
如:# 执行redis命令 redis.call('命令名称', 'key', '其它参数', ...)# 执行 set name jack redis.call('set', 'name', 'jack')# 先执行 set name jack redis.call('set', 'name', 'jack') # 再执行 get name local name = redis.call('get', 'name') # 返回 return name - 调用脚本常见命令
例如,我们要执行 redis.call(‘set’, ‘name’, ‘jack’) 这个脚本,语法如下:

如果脚本中的key、value不想写死,可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数:

1.5.3.3 基于Redis的分布式锁优化
可重入:同一个线程可以多次获取同一把锁

要解决上述问题,实际操作很麻烦,考虑借助别的工具
- 分布式锁原理:
- 可重入:利用hash结构记录线程id和重入次数
- 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
- 超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
1.5.3.3.1 Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现
- 入门
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version> </dependency> - 配置Redisson客户端
@Configuration public class RedisConfig { @Bean public RedissonClient redissonClient() { // 配置类 Config config = new Config(); // 添加redis地址,这里添加了单点的地址,也可以使用config.useClusterServers()添加集群地址 config.useSingleServer().setAddress("redis://192.168.150.101:6379").setPassowrd("123321"); // 创建客户端 return Redisson.create(config); } } - 使用Redission的分布式锁
@Resource private RedissonClient redissonClient; @Test void testRedisson() throws InterruptedException { // 获取锁(可重入),指定锁的名称 RLock lock = redissonClient.getLock("anyLock"); // 尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位 boolean isLock = lock.tryLock(1, 10, TimeUnit.SECONDS); // 判断释放获取成功 if(isLock){ try { System.out.println("执行业务"); }finally { // 释放锁 lock.unlock(); } } }
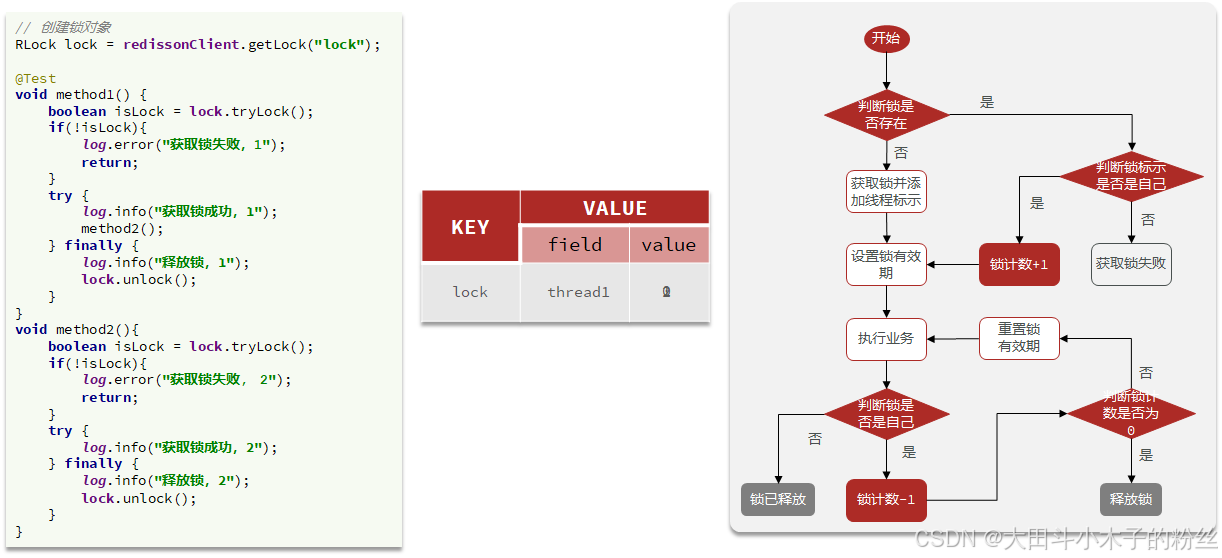
1.5.3.3.2 Redisson可重入锁原理
可重入:利用hash记录锁名称、获取锁的线程、重入次数
tryLock:判断是否有锁->线程标识是否一致->重入次数+1
unLock:释放一次,重入次数-1->判断是否为0->删除锁
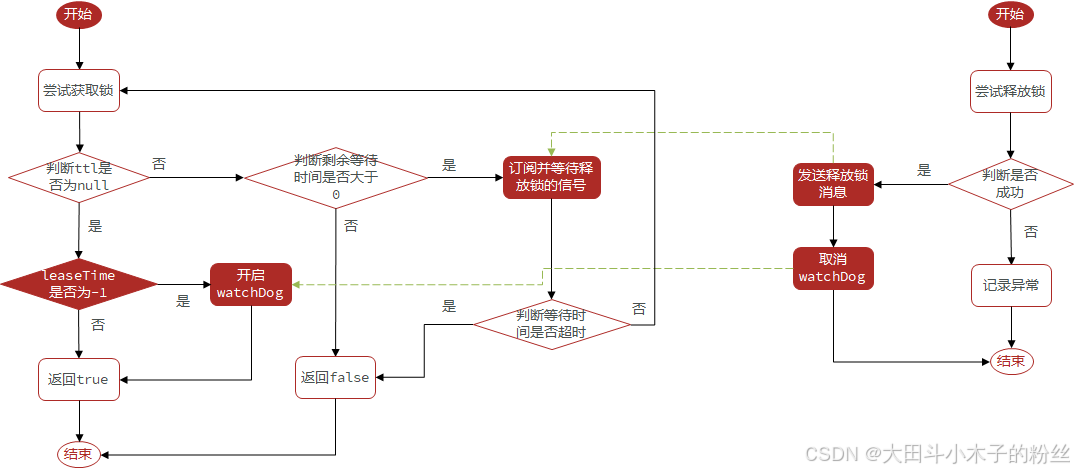
1.5.3.3.3 Redisson的锁重试和WatchDog机制
可重试:利用信号量和PubSub功能实现等待、唤醒、获取锁失败的重试机制
超时续约:利用watchDog,每隔一段时间(releaseTime/3),重置超时时间
自己设置有效期leaseTime了,就不会有看门狗;看门狗默认的锁释放时间是30s
对于源码中Lua脚本,获取锁成功会返回nil,更新有效期,只要持有锁的线程在,会一直不停的续期;获取锁失败,会返回锁剩余有效期
剩余有效期-操作的时间,时间有剩余,重试
订阅别人释放锁的信号,异步等待,等待时间为最大剩余时间
获取当前的最大剩余时间,开始重试
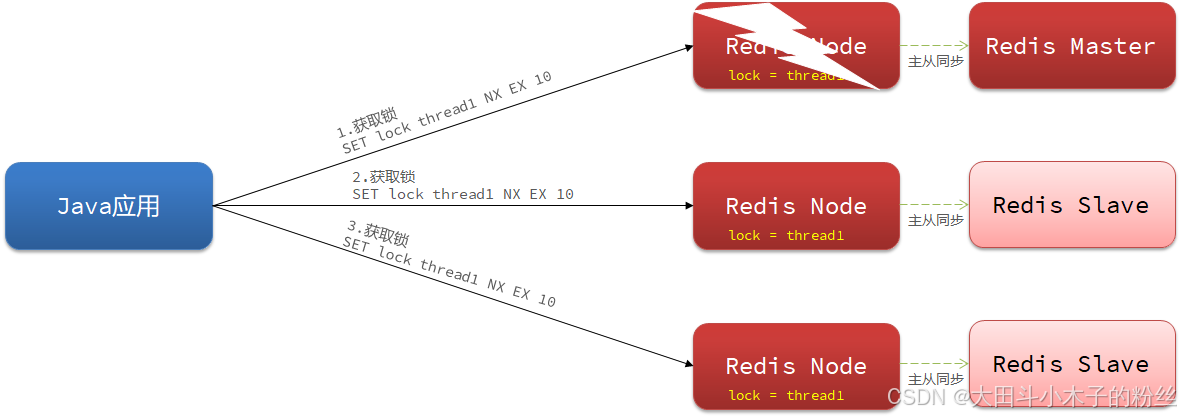
1.5.3.3.4 Redisson分布式锁主从一致性问题
搭建redis主从集群,主节点负责增删改、从节点负责读,主从节点数据要同步
问题描述:主节点写入锁,还没有同步到从节点时,主节点宕机。哨兵机制会在从节点中选出新的主节点,但新的主节点没有写入的锁信息,出现主从一致性问题
解决方法:多个redis都可以进行读写,在所有redis中都拿到锁才算成功
1.5.3.3.5 Redisson总结
- 不可重入Redis分布式锁:
- 原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判断线程标示
- 缺陷:不可重入、无法重试、锁超时失效
- 可重入的Redis分布式锁:
- 原理:利用hash结构,记录线程标示和重入次数;利用watchDog延续锁时间;利用信号量控制锁重试等待
- 缺陷:redis宕机引起锁失效问题
- Redisson的multiLock:
- 原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
- 缺陷:运维成本高、实现复杂
1.5.4 Redis秒杀优化
- 秒杀业务的优化思路是什么?
①先利用Redis完成库存余量、一人一单判断,完成抢单业务
②再将下单业务放入阻塞队列,利用独立线程异步下单 - 基于阻塞队列的异步秒杀存在哪些问题?
内存限制问题:JVM内存有限
数据安全问题:JVM内存没有持久化处理,重启或宕机会让订单任务丢失
在秒杀业务中,减库存和创建订单是对数据库的写操作,mysql处理并发的效率低
判断秒杀库存和校验一人一单是对数据库的读操作,为提高效率,将该操作在redis中进行
同步下单变异步下单
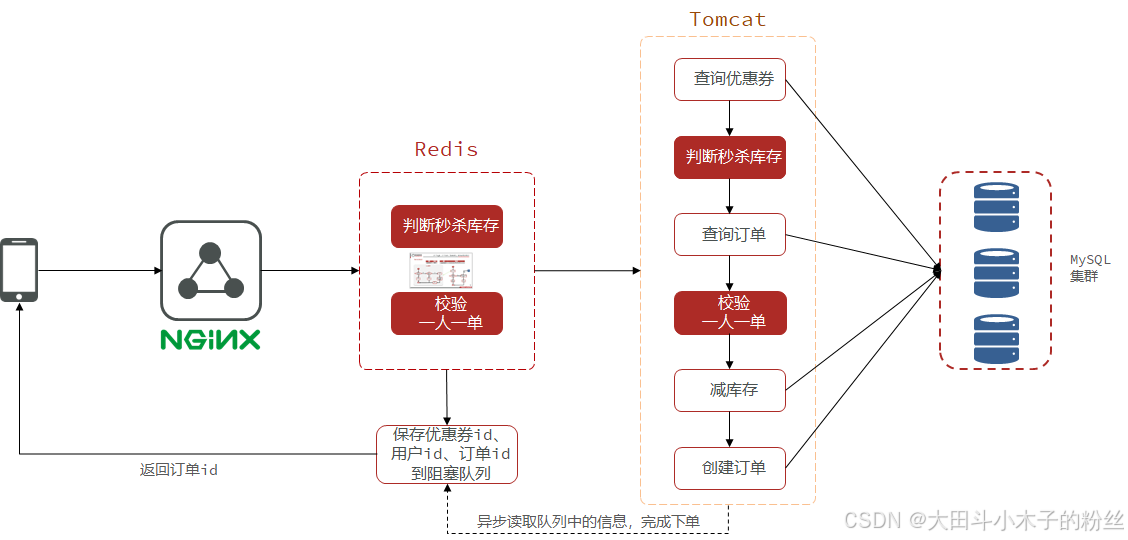
优惠券id:string存储
用户id:set存储。voucherID作为key,多个userId作为value(用户唯一)
0有资格购买、1库存不足、2重复下单
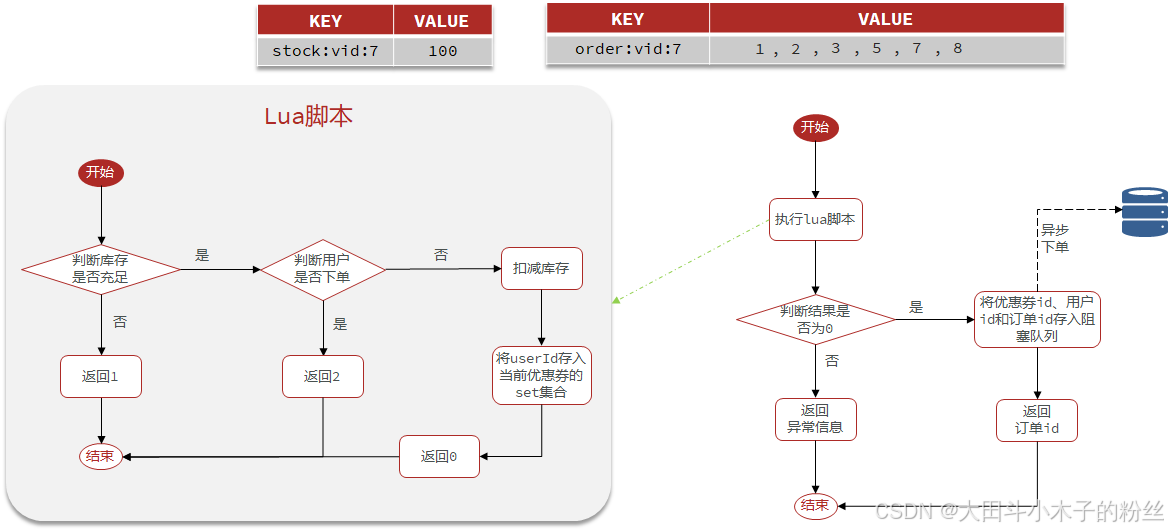
1.5.4.1 需求
①新增秒杀优惠券的同时,将优惠券信息保存到Redis中
②基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
③如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
④开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
阻塞队列就是可以阻塞线程的队列,当一个线程尝试从队列里获取元素时,如果没有元素,该线程会被阻塞,直到有元素,该线程才会被唤醒
- 将订单信息放入阻塞队列
private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024);orderTasks.add(voucherOrder); - 执行异步下单
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor(); //在当前类初始化之后就执行 @PostConstruct private void init(){ SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler()); } private class VoucherOrderHandler implements Runnable{ @Override public void run() { while (true){ try { //获取队列中的订单信息 VoucherOrder order = orderTasks.take(); //创建订单 handleVoucherOrder(order); } catch (InterruptedException e) { log.error("处理订单异常",e); } } } }
1.5.5 Redis消息队列实现异步秒杀
消息队列(Message Queue),字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
消息队列:存储和管理消息,也被称为消息代理(Message Broker)
生产者:发送消息到消息队列
消费者:从消息队列获取消息并处理消息
与阻塞队列区别:不依赖内存,不用担心内存不足;持久化保存,安全;进行消息确认;

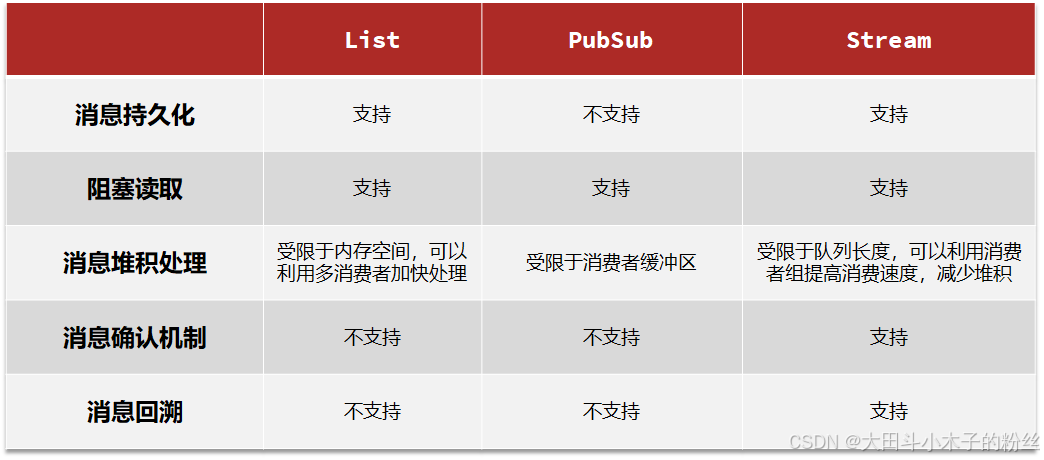
Redis提供了三种不同的方式来实现消息队列:
- list结构:基于List结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
1.5.5.1 基于List结构模拟消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。
- 优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
- 缺点:
- 无法避免消息丢失
- 只支持单消费者
1.5.5.2 基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发送消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
- 优点:
- 采用发布订阅模型,支持多生产、多消费
- 缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
1.5.5.3 基于Stream的消息队列
-
发送消息的命令——XADD


-
读取消息的方式之一——XREAD

-
使用方式
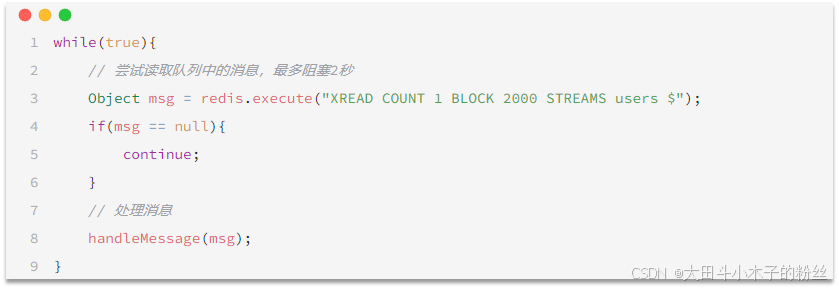
注意:当我们指定起始ID为$时,代表读取最新的消息,如果我们处理一条消息的过程中,又有超过1条以上的消息到达队列,则下次获取时也只能获取到最新的一条,会出现漏读消息的问题。
- STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
1.5.5.4 基于Stream的消息队列—消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:

-
创建消费者组
XGROUP CREATE key groupName ID [MKSTREAM]- key:队列名称
- groupName:消费者组名称
- ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
- MKSTREAM:队列不存在时自动创建队列
-
其他常见命令
# 删除指定的消费者组 XGROUP DESTROY key groupName # 给指定的消费者组添加消费者 XGROUP CREATECONSUMER key groupname consumername # 删除消费者组中的指定消费者 XGROUP DELCONSUMER key groupname consumername -
从消费者组读取消息
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK:milliseconds:当没有消息时最长等待时间
- NOACK:无需手动ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始ID:
- “>”:从下一个未消费的消息开始
- 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
-
消费者监听消息的基本思路

-
STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
-
缺点
- 基于Redis实现的持久化,不能完全安全
- 消息确认机制针对消费者,没有生产者的消息确认
- 事务机制、有序性
1.6 达人探店
1.6.1 发布探店笔记
换成minio
1.6.2 点赞

1.6.3 点赞排行榜
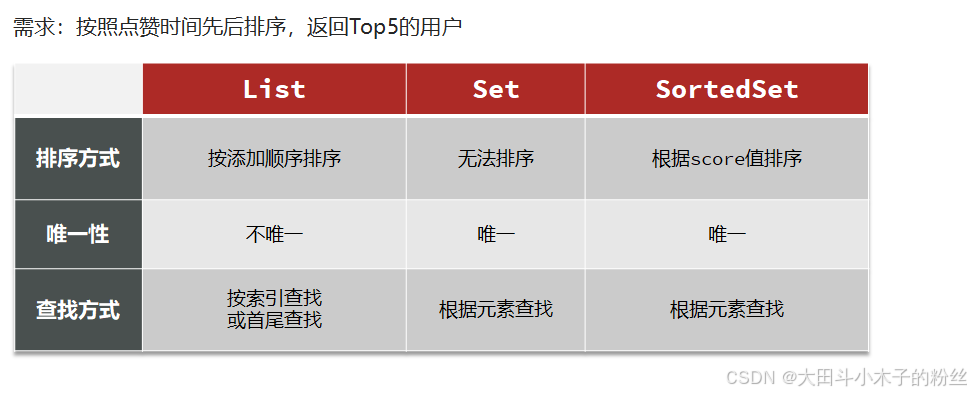
zscore:按照分数是否存在,
zrange
1.7 好友关注
1.7.1 关注和取关
关注:在redis sortedset中添加被关注人id,存入数据库
1.7.2 共同关注
zset intersect
1.7.3 关注推送
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
Feed流产品有两种常见模式:
- Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
- 智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
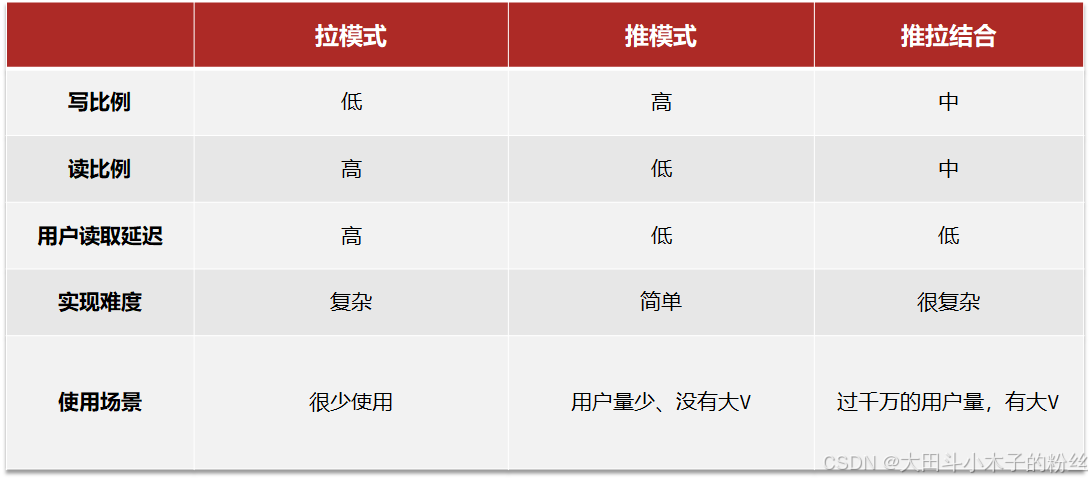
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
①拉模式
②推模式
③推拉结合
1.7.3.1 拉模式
拉模式:也叫做读扩散
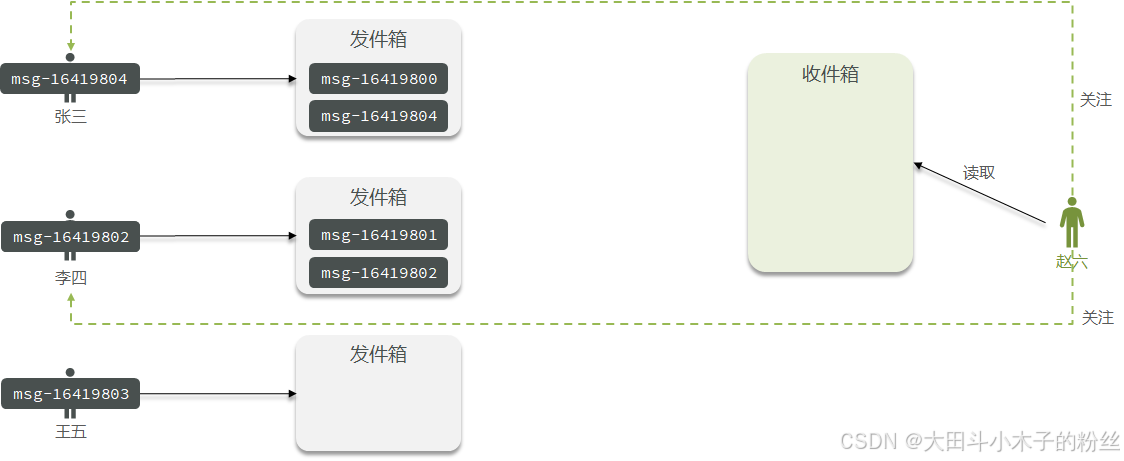
发件箱发消息同时带上时间戳
收件箱是空的,只有在读的时候才会去拉取消息,做消息排序
1.7.3.2 推模式
推模式:也叫写扩散
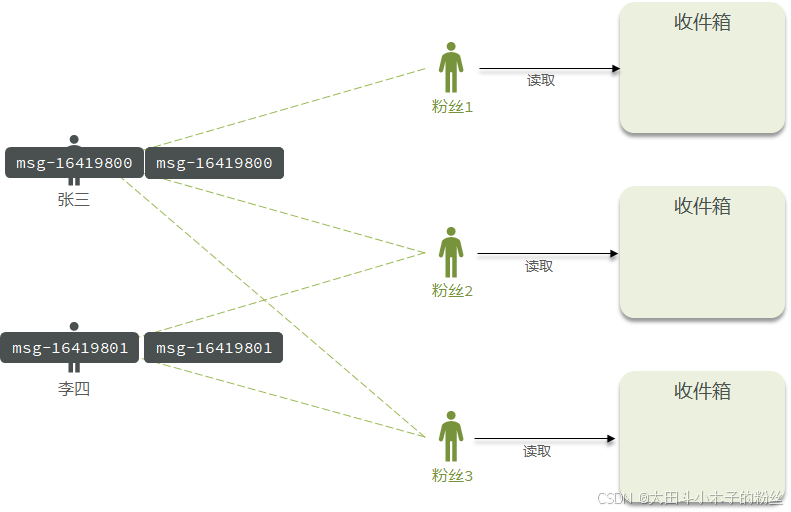
用户发消息时,会直接推送到所有粉丝的收件箱,收件箱的消息做一个排序
消息会发好几份,内存占用比较高
1.7.3.3 推拉结合模式
推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点。
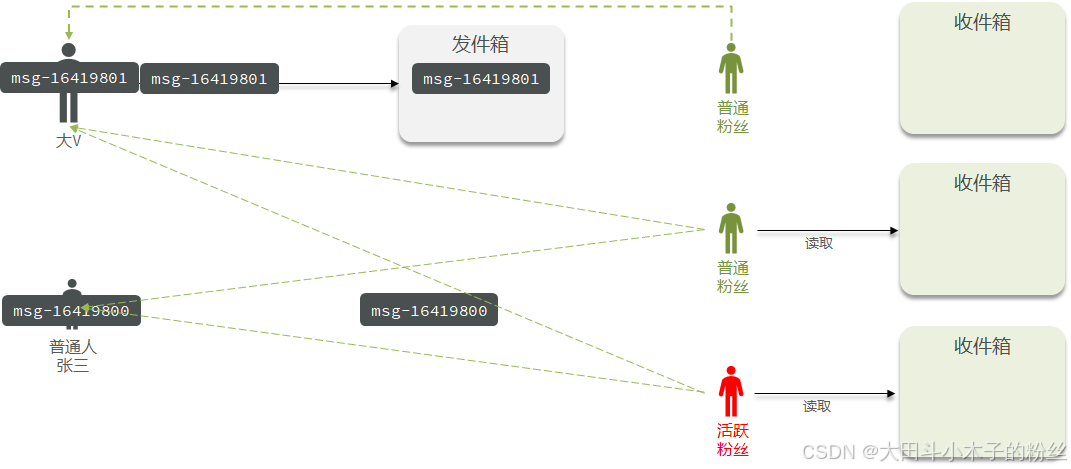
对于大V,活跃粉丝采用推模式、普通粉丝采用拉模式
对于普通用户,采用推模式
1.7.3.4 实际实现
①修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
②收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
③查询收件箱数据时,可以实现分页查询
1.7.3.4.1 Feed流的滚动分页
Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
- 推送:redis 以粉丝id为key,添加博客id
- 查询
按照score查询,score为时间戳
ZREVRANGEBYSCORE 分数最大值 分数最小值 偏移量 查询数量
分数最小值不需要管,查询数量不需要管
分数最大值:上一次查询出的最小的分数
偏移量:0是包含,1是从下一个开始。与上一次查询最小分数一样的值 - 滚动分页查询参数:
- max:第一次,当前时间戳 | 上一次查询的最小值
- min:0
- offset:第一次,0 | 上一次查询的结果中,与最小值相同的元素的个数
- count:3
1.8 附近商户
替换为es
1.8.1 GEO数据结构
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
[GEOADD](https://redis.io/commands/geoadd):添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
[GEODIST](https://redis.io/commands/geodist):计算指定的两个点之间的距离并返回
[GEOHASH](https://redis.io/commands/geohash):将指定member的坐标转为hash字符串形式并返回
[GEOPOS](https://redis.io/commands/geopos):返回指定member的坐标
[GEORADIUS](https://redis.io/commands/georadius):指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.2以后已废弃
[GEOSEARCH](https://redis.io/commands/geosearch):在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
[GEOSEARCHSTORE](https://redis.io/commands/geosearchstore):与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
底层用SortedSet
哈希降维:先将经纬度坐标值转换成二进制的数字,然后再利用特殊的编码转换成对应的字符串(转换成字符串后,占用的空间就会小一点,节省内存)。
1.8.2 附近商户搜索
考虑:附近舞室搜索
1.9 用户签到
1.9.1 BitMap用法
假如有1000万用户,平均每人每年签到次数为10次,则这张表一年的数据量为 1亿条
每签到一次需要使用(8 + 8 + 1 + 1 + 3 + 1)共22 字节的内存,一个月则最多需要600多字节
用二进制数据串表示,按月来统计用户签到信息,签到记录为1,未签到则记录为0。把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位。
- BitMap的操作命令有:
[SETBIT](https://redis.io/commands/setbit):向指定位置(offset)存入一个0或1 [GETBIT](https://redis.io/commands/getbit) :获取指定位置(offset)的bit值 [BITCOUNT](https://redis.io/commands/bitcount) :统计BitMap中值为1的bit位的数量 [BITFIELD](https://redis.io/commands/bitfield) :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值 [BITFIELD_RO](https://redis.io/commands/bitfield_ro) :获取BitMap中bit数组,并以十进制形式返回 [BITOP](https://redis.io/commands/bitop) :将多个BitMap的结果做位运算(与 、或、异或) [BITPOS](https://redis.io/commands/bitpos) :查找bit数组中指定范围内第一个0或1出现的位置
1.9.2 签到功能
1.9.3 签到统计
连续签到统计
- 问题1:如何得到本月到今天为止的所有签到数据?
BITFIELD key GET u[dayOfMonth] 0 - 问题2:如何从后向前遍历每个bit位?
与 1 做与运算,就能得到最后一个bit位。
随后右移1位,下一个bit位就成为了最后一个bit位。
1.10 UV统计
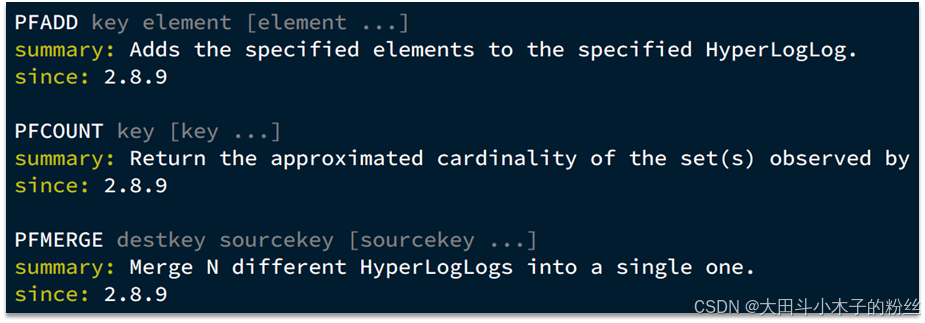
1.10.1 HyperLogLog用法
首先我们搞懂两个概念:
-
UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
-
PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。


















 3805
3805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











