







HashMap可以在O(1)的时间复杂度内完成查找,插入,删除操作
- 底层数据结构:
JDK7: 数组中每个元素是一个链表
JDK8:数组中每个元素是一个链表或者一棵红黑树,当数组长度>=64,而且链表长度到达8的时候,链表转化为红黑树,当链表长度降到6的时候,红黑树又会转化为链表
另外:七上八下,JDK7链表插入元素采用头插法,JDK8链表插入元素采用尾插法
(2)put进一条key-value的流程:
先根据插入的key-value中的key求出哈希值,然后哈希值再去对数组长度取余(但是不是采用hashcode%length的方式取余,而是采用hashcode&length-1的方式取余,因为与运算效率更高)来确定插入到数组的哪个位置
如果哈希值相同,还要调用equals方法,判断这两个key对应的对象到底是不是相同的对象,是相同的对象就要进行覆盖,不是相同的对象就产生哈希冲突,挂在链表或者红黑树上
(3)扩容机制:
初始数组长度为16,当数组中元素数量达到数组长度*0.75时,创建一个新的数组是原数组长度的2倍,原数组中的元素重新计算插入位置
加载因子为什么是0.75?
加载因子为0.5时,扩容很频繁,虽然不容易产生碰撞,因此不容易产生链表,所以查询的次数也更少,查询效率高,但是需要频繁进行扩容,空间利用率太低了。装填因子为1的话,扩容的频率降低了,会容易产生碰撞,所以很容易产生链表,这样要查询的次数就更多,所以查询的效率很低,因此折中一下,取平均值。
为什么数组长度需要是2的n次方?这样做是为了尽量减少哈希冲突,让数组元素分布更均匀,因为哈希值和length-1进行与操作,但length=2的n次方的时候,length-1就等于0111111111......,做与操作的时候不同哈希值得到的结果就不一样,如果length-1有很多位0,那不同的哈希值与操作的结果可能是一样的,容易发生哈希冲突
jkd1.7
HashMap的底层结构是数组+链表
将key-value中的key输入到哈希函数(hashcode()方法)里面得到hashcode哈希值
然后哈希值再去对数组长度进行取余,但是取余操作不如位运算高效,所以用hashcode&length-1
代替hashcode%length
总结:先根据key求出哈希值,然后哈希值再去对数组长度取余(但是不是采用hashcode%length的方式取余,而是采用hashcode&length-1的方式取余)
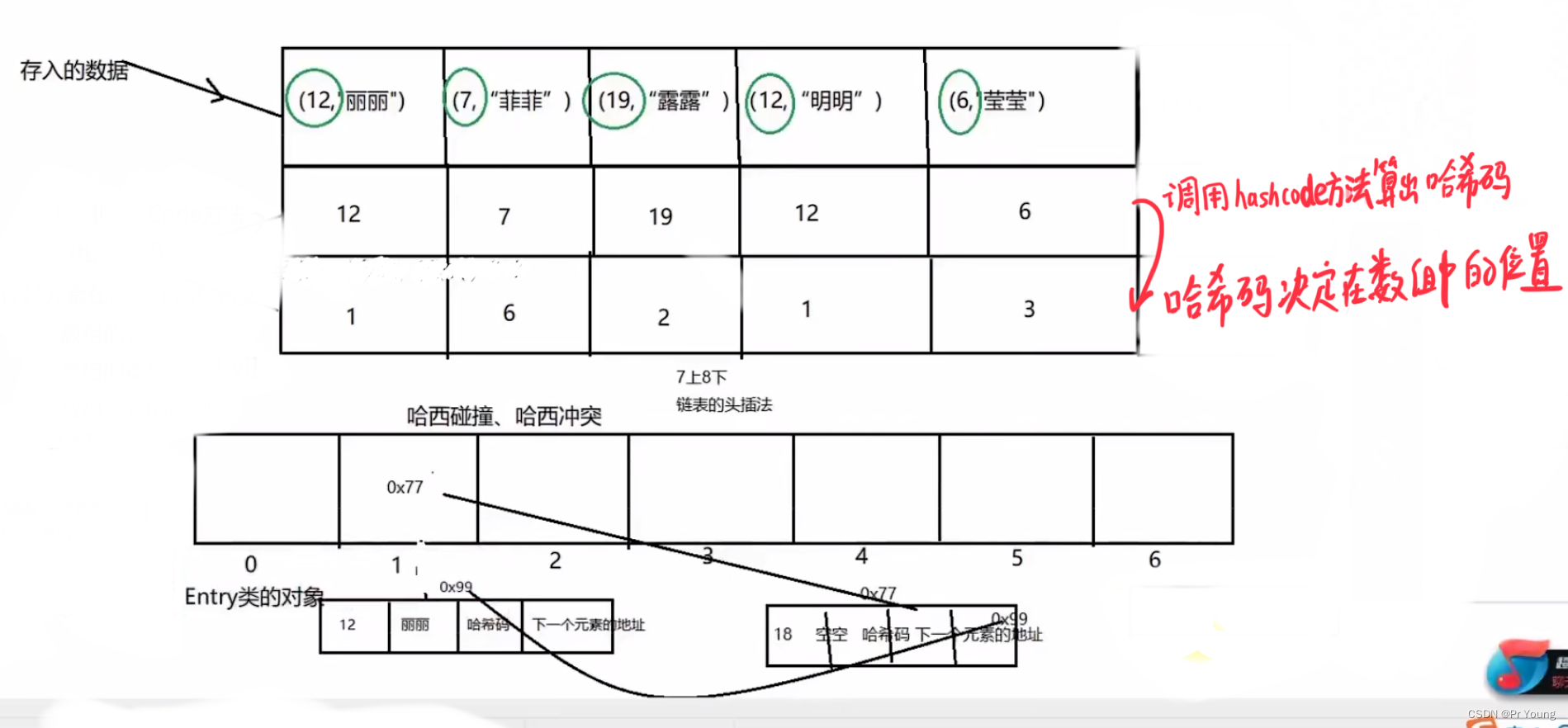
没有哈希冲突的元素放在数组里面, 哈希冲突的元素用链表串起来
再插入一个新的键值对(18,“莹莹”),得到哈希码的值为1,这时就产生了哈希冲突
七上八下,新的产生哈希冲突的元素,到底是插入到链表的头部还是链表的尾部,七上八下,如果是jdk1.7,就是头插法,jdk1.8就是尾插法
初始数组长度是16,对应源码:
static final int DEFAULT_INITIAL_CAPACITY=1;最大的容量为2的30次方,一个很大很大很大的数
还定义了一个负载因子下(加载因子):0.75
static final float DEFAULT_LOAD_FACTOR=0.75;当数组内元素数量超过阈值threshold(阈值=数组容量*加载因子)时,进行扩容 ,也就是说当插入第13个元素的时候,就会发生扩容
每次扩容后为当前数组容量的两倍(因此数组容量一定是2的n次方,16,32,64)
(1)为什么加载因子为0.75?
加载因子为0.5时,虽然不容易产生碰撞,因此不容易产生链表,所以查询的次数也更少,查询效率高,但是需要频繁进行扩容,空间利用率太低了
装填因子为1的话,会容易产生碰撞,所以很容易产生链表,这样要查询的次数就更多,所以查询的效率很低
因此折中一下,取平均值
(2)为什么扩容后数组的长度是2的n次方?降低哈希冲突,让数组元素分布更加均匀
hashcode值&length-1
当length=2的n次方时,n就是1000000000,2的n次方-1就是011111111111
如果不是2的n次方,对应的二进制至少有1位是0,这样不管hashcode值是多少,最终与出来的结果这一位一定是0,这样会使得数组元素分布不均与,有些位置永远用不到
举个具体的例子:
假如现在长度是14,那就是和13进行与操作,转化为二进制,1101
假如key是10,1010&1101=1000 也就是8的位置
如果key是8,1000&1101=1000 还是8的位置
现在长度16,那就是变成和15进行与操作,1111
假如key是10,1010&1111=1010 也就是10的位置
如果key是8,1000&1111=1000 是8的位置
也就是说,当length为2的n次方的时候,和length-1做与操作,可以使得哈希冲突大大降低,数组元素分布更加均匀
jdk1.8
hashmap的数据结构就变成数组+链表+红黑树
1.7 数组+链表时,顺着链表一个一个查的时间复杂度为O(n)
1.8,当数组容量扩大到大于等于64而且链表中的元素达到了 8 个时,会将链表转换为红黑树,查找的时间复杂度降为O(logN)(注意:链表长度大于8,但是数组容量没有扩充到64,链表不会变成红黑树,链表长度小于8,数组容量扩充到64以上,链表也是不会被转化成红黑树的),而且当红黑树的节点个数等于6的时候,又会退化成链表
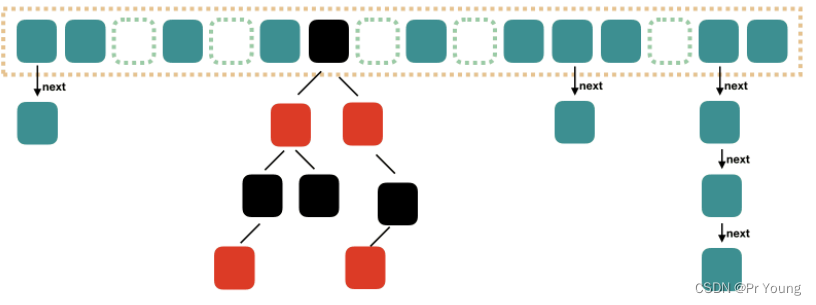
总结:数组长度>=64&&链表长度>8的时候从链表变成红黑树
链表长度降为6的时候,又退化成链表














 1675
1675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









