







类似于一个hase set 用来判断某个元素(key)是否存在于某个集合中
布隆过滤器说这个数据不存在,这个数据就一定不在
布隆过滤器说这个数据存在,这个数据也不一定就在,只是可能在
核心:使用一个数组,把关键词输入到几个哈希函数(不只是一个哈希函数,输入到一个哈希函数里面得到一个数,输入到多个哈希函数就得到一组数)里面,得到一组数,将数组上对应的位置改为1
是一个数据结构
用来判断某个元素是否在集合内
运行快速,内存占用小
但是高效插入和查询的代价就是:这是一个基于概率的数据结构,它只能告诉我们一个元素绝对不再集合内,或者可能在集合内 (也就是说,布隆过滤器判断不存在,数据库中一定不存在,布隆过滤器中判断存在,只能说明可能存在)
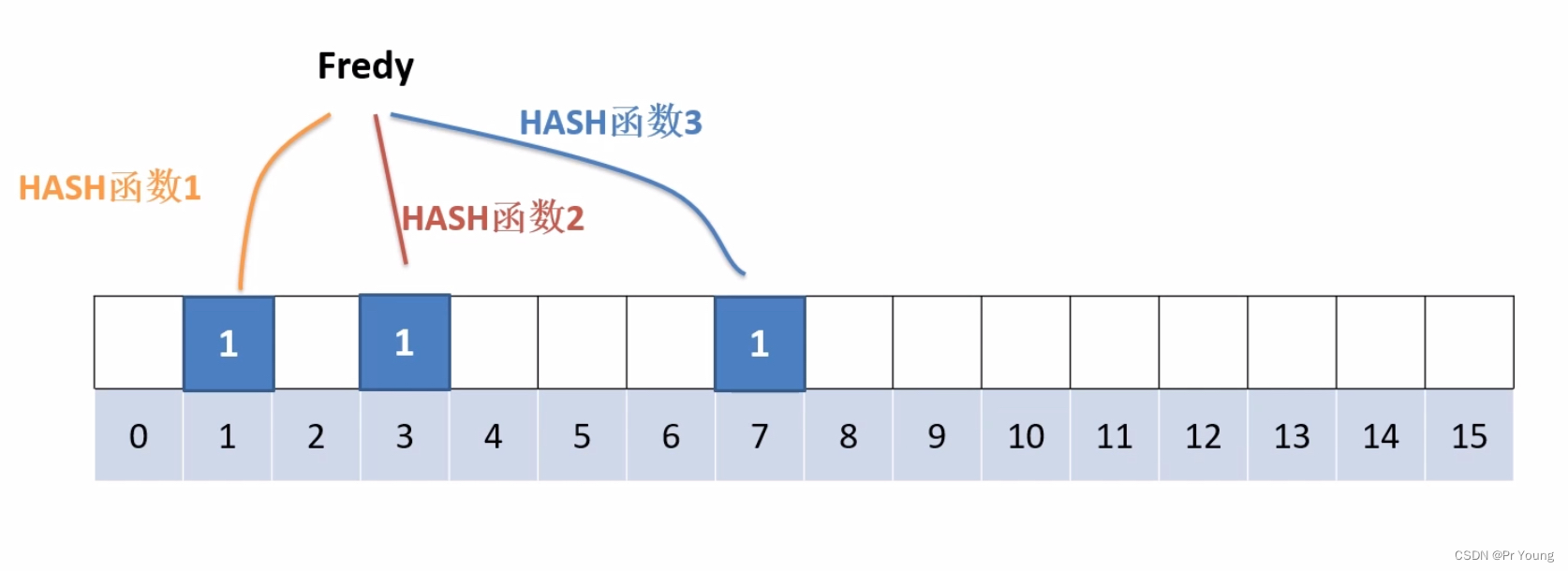
布隆过滤器的基础结构就是一个wait数组,假设这个数组大小为16,每个位置默认起始为0
将Fredy这个key写入数据库
假设这个布隆过滤器有3个哈希函数,将Fredy输入到这三个哈希函数,分别得到三个值1,3,7
将这三个位置上的值置为1
此时,我们又把Eli录入数据库,将Eli输入到这三个哈希函数,分别得到三个值10,12,15
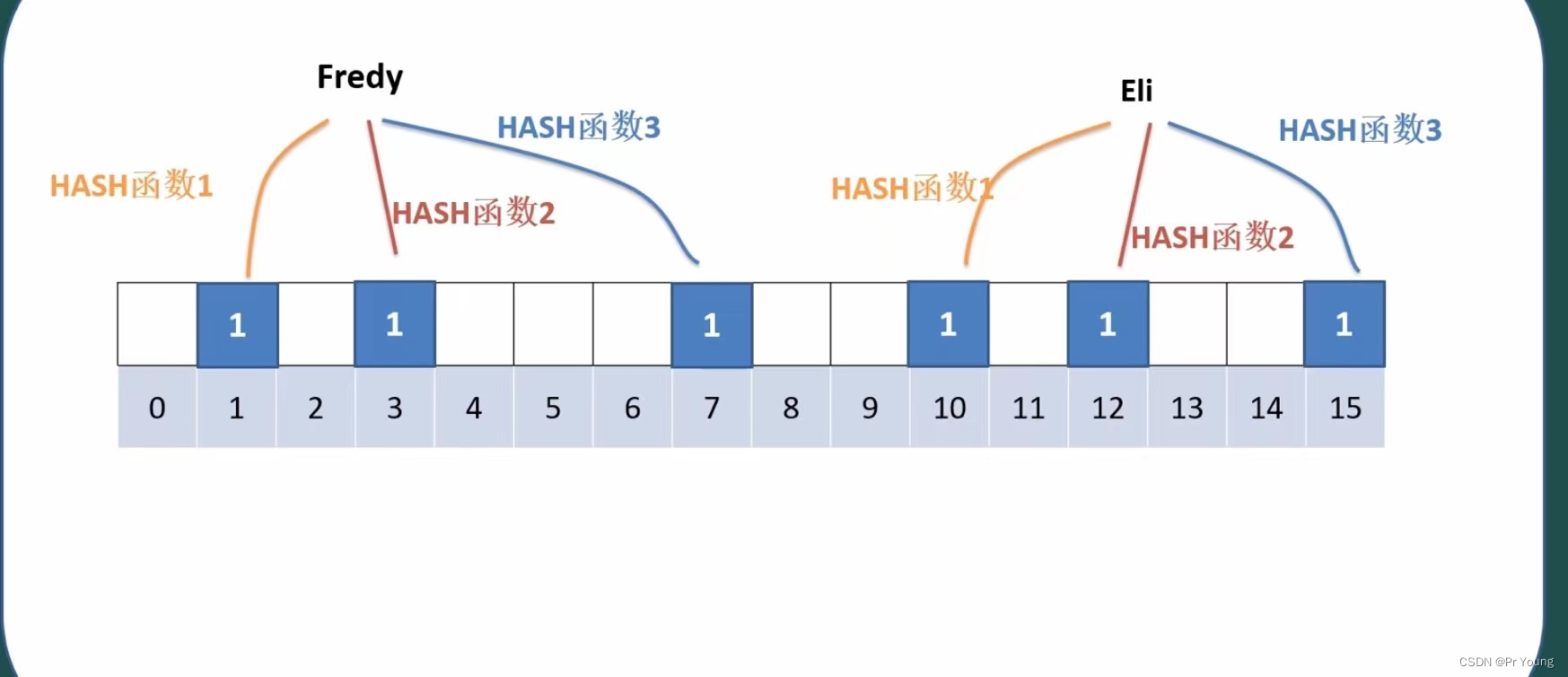
现在查询Tom这个词在不在数据库里面:
将tom这个词输入到三个哈希函数里面,得到0,2,5,发现数组中这三个位置都是0,不是1,说明数据库中不含有tom这个词
如果查询Lily,将Lily这个词输入到三个哈希函数里面,得到7,12,15,这三个位置上都是1,但是数据库中其实并没有Lily这个词
java中使用布隆过滤器:
先引入redisson组件的依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-all</artifactId>
<version>3.16.0</version>
</dependency>public class Test
{
public static void main(String[] args)
{
//连接redis数据库
Config config=new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson= Redisson.create(config);
//给这个布隆过滤器起个名字
RBloomFilter<String> bloomFilter=redisson.getBloomFilter("test");
//初始化这个布隆过滤器,预计里面装100 0000L一百万个数据
//误判率为1%(最大允许为1%,这个数值如果设置的太小,虽然会降低误判率,但是会产生更多次的哈希操作,降低系统性能)
bloomFilter.tryInit(1000000L,0.01);
//增加一个字符串进入布隆过滤器
bloomFilter.add("ouyangshuiming");
System.out.println(bloomFilter.contains("ouyangshuiming")); //输出true
System.out.println(bloomFilter.contains("zhangsan")); //输出false
}
}这里误判率为1%,表示最大允许误判1%,这个数值如果设置的太小,虽然会降低误判率,但是会产生更多次的哈希操作,降低系统性能
也就是说:布隆过滤器认为这个元素不存在,一定不存在,布隆过滤器认为这个元素存在,有1%的概率错误判断















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









