







以下文章转载或借鉴vue源码社区,仅供个人学习使用,如有文章涉及侵权及其他问题,请及时联系作者修改或删除,感谢!!!
vue源码中文社区:https://vue-js.com/learn-vue/
一、object变化侦测篇
1.通过Object.defineProperty()改造属性
let car = {}
let val = 3000
Object.defineProperty(car, 'price', {
enumerable: true,
configurable: true,
get(){
console.log('price属性被读取了')
return val
},
set(newVal){
console.log('price属性被修改了')
val = newVal
}
})
源码位置:src/core/observer/index.js
/**
1. Observer类会通过递归的方式把一个对象的所有属性都转化成可观测对象
*/
export class Observer {
value: any;
dep: Dep;
vmCount: number;
constructor (value: any) {
this.value = value
// 实例化一个依赖管理器
this.dep = new Dep()
this.vmCount = 0
// 给value新增一个__ob__属性,值为该value的Observer实例
// 相当于为value打上标记,表示它已经被转化成响应式了,避免重复操作
def(value, '__ob__', this)
// 当value为数组时
if (Array.isArray(value)) {
// hasProto = '__proto__' in {} 判断hasProto是否可用,有 些浏览器不支持该属性
if (hasProto) {
// const arrayProto = Array.prototype
// export const arrayMethods = Object.create(arrayProto)
// function protoAugment (target, src: Object) {
// target.__proto__ = src
// }
// 覆盖__proto__,拦截器挂载
protoAugment(value, arrayMethods)
} else {
// 获取arrayMethods的所有属性
// const arrayKeys = Object.getOwnPropertyNames(arrayMethods)
// function copyAugment (target: Object, src: Object, keys: Array<string>) {
// for (let i = 0, l = keys.length; i < l; i++) {
// const key = keys[i]
// 间接挂载
// def(target, key, src[key])
// }
// }
copyAugment(value, arrayMethods, arrayKeys)
}
// 把数组中的每一项转换为可观测属性
this.observeArray(value)
} else {
// 把对象的每一项转换为可观测属性
this.walk(value)
}
}
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i])
}
}
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}
/**
2. 使一个对象转化成可观测对象
3. @param { Object } obj 对象
4. @param { String } key 对象的key
5. @param { Any } val 对象的某个key的值
*/
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
// 生成依赖管理器
const dep = new Dep()
// 定义获取指定对象的自身属性描述符
const property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
const getter = property && property.get
const setter = property && property.set
// 如果只传了obj和key,那么val = obj[key]
if ((!getter || setter) && arguments.length === 2) {
val = obj[key]
}
let childOb = !shallow && observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
// 依赖收集
dep.depend()
if (childOb) {
childOb.dep.depend()
// 如果为数组递归遍历收集依赖
if (Array.isArray(value)) {
dependArray(value)
}
}
}
return value
},
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
if (getter && !setter) return
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = !shallow && observe(newVal)
// 依赖更新
dep.notify()
}
})
}
小结:定义observer类,它用来将一个正常的object转换成可观测的object。并且给value新增一个__ob__属性,值为该value的Observer实例。这个操作相当于为value打上标记,表示它已经被转化成响应式了,避免重复操作。
只有object类型的数据才会调用walk将每一个属性转换成getter/setter的形式来侦测变化。 最后,在defineReactive中当传入的属性值还是一个object时使用new observer(val)来递归子属性,这样我们就可以把obj中的所有属性(包括子属性)都转换成getter/seter的形式来侦测变化。 也就是说,只要我们将一个object传到observer中,那么这个object就会变成可观测的、响应式的object。
2.依赖收集(依赖管理器)
在getter中收集依赖,在setter中通知依赖更新。
// 源码位置:src/core/observer/dep.js
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor() {
this.id = uid++;
this.subs = [];
}
addSub(sub: Watcher) {
this.subs.push(sub);
}
removeSub(sub: Watcher) {
remove(this.subs, sub);
}
// 收集依赖
depend() {
if (Dep.target) {
Dep.target.addDep(this);
}
}
// 通知所有依赖更新
notify() {
const subs = this.subs.slice();
if (process.env.NODE_ENV !== "production" && !config.async) {
subs.sort((a, b) => a.id - b.id);
}
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update();
}
}
}
3.Watcher 类
作用:在之后数据变化时,不直接去通知依赖更新,而是通知依赖对应的Watch实例,由Watcher实例去通知真正的视图,可以理解成watch类就代表这个依赖。
// watch类大概实现
export default class Watcher {
constructor (vm,expOrFn,cb) {
this.vm = vm;
this.cb = cb;
this.getter = parsePath(expOrFn)
this.value = this.get()
}
get () {
window.target = this;
const vm = this.vm
let value = this.getter.call(vm, vm)
window.target = undefined;
return value
}
update () {
const oldValue = this.value
this.value = this.get()
this.cb.call(this.vm, this.value, oldValue)
}
}
watch类解析:谁用到了数据,谁就是依赖,我们就为谁创建一个Watcher实例,在创建Watcher实例的过程中会自动的把自己添加到这个数据对应的依赖管理器中,以后这个Watcher实例就代表这个依赖,当数据变化时,我们就通知Watcher实例,由Watcher实例再去通知真正的依赖。
当实例化Watcher类时,会先执行其构造函数;
1. 在构造函数中调用了this.get()实例方法;
2. 在get()方法中,首先通过window.target = this把实例自身赋给了全局的一个唯一对象window.target上,然后通过let value = this.getter.call(vm, vm)获取一下被依赖的数据,获取被依赖数据的目的是触发该数据上面的getter,上文我们说过,在getter里会调用dep.depend()收集依赖,而在dep.depend()中取到挂载window.target上的值并将其存入依赖数组中,在get()方法最后将window.target释放掉。
3. 而当数据变化时,会触发数据的setter,在setter中调用了dep.notify()方法,在dep.notify()方法中,遍历所有依赖(即watcher实例),执行依赖的update()方法,也就是Watcher类中的update()实例方法,在update()方法中调用数据变化的更新回调函数,从而更新视图。
总结:Watcher先把自己设置到全局唯一的指定位置(window.target),然后读取数据。因为读取了数据,所以会触发这个数据的getter。接着,在getter中就会从全局唯一的那个位置读取当前正在读取数据的Watcher,并把这个watcher收集到Dep中去。收集好之后,当数据发生变化时,会向Dep中的每个Watcher发送通知。通过这样的方式,Watcher可以主动去订阅任意一个数据的变化。
object侦测总结:
1.Data通过observer转换成了getter/setter的形式来追踪变化。
当外界通过Watcher读取数据时,会触发getter从而将Watcher添加到依赖中。
2.当数据发生了变化时,会触发setter,从而向Dep中的依赖(即Watcher)发送通知。
3.Watcher接收到通知后,会向外界发送通知,变化通知到外界后可能会触发视图更新,也有可能触发用户的某个回调函数等。
二、Array变化侦测
1.Array型数据的set get
get
array不存在对象的Object.defineProperty方法,get操作是通过如下形式实现的:
data(){
return {
arr:[1,2,3]
}
}
每次获取数据的时候都是通过this.arr获取的,每当通过this.属性获取时,就会触发的array的get属性,收集依赖等。
set
let arr = [1,2,3]
arr.push(4)
Array.prototype.newPush = function(val){
console.log('arr被修改了')
this.push(val)
}
arr.newPush(4)
通过拟定array的push方法,达到可以监听改变的目的。
数组的setget方法如上生成。
array的方法拦截器
// 源码位置:/src/core/observer/array.js
const arrayProto = Array.prototype
// 创建一个新的数组,原型为Array.prototype
export const arrayMethods = Object.create(arrayProto)
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
// 把methodsToPatch数组内的方法指向mutator方法
methodsToPatch.forEach(function (method) {
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// 通知更新
ob.dep.notify()
return result
})
})
// def 转化为defineProperty
export function def (obj: Object, key: string, val: any, enumerable?: boolean) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true
})
}
解析: 当调用methodsToPatch数组中的方法时,实际都会指向mutator方法,在mutator方法中执行通知更新操作,而mutator函数内部执行了original函数,这个original函数就是Array.prototype上对应的原生方法。
拦截器挂载
Observer类如下,挂载数组拦截器
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
if (hasProto) {
// target.__proto__ = src 直接挂载
protoAugment(value, arrayMethods)
} else {
// 把数组的方法全部挂到value上
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {
this.walk(value)
}
}
function protoAugment (target, src: Object) {
target.__proto__ = src
}
function copyAugment (target: Object, src: Object, keys: Array<string>) {
for (let i = 0, l = keys.length; i < l; i++) {
const key = keys[i]
def(target, key, src[key])
}
}
解析: 首先判断当前浏览器是否支持__proto__ ,如果支持直接把__proto__ 重定向为arrayMethods对象,如果不支持,则是需要把拦截器中重写的7个方法循环加入到value上。
2.array依赖收集
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
const dep = new Dep()
// 返回一个属性在此对象上的操作符
const property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
const getter = property && property.get
const setter = property && property.set
if ((!getter || setter) && arguments.length === 2) {
val = obj[key]
}
// observe 判断val是否转换为可观测的属性,如果不是就转换,是就返回__ob__
let childOb = !shallow && observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
// 待明确此处收集是什么内容
dep.depend()
if (childOb) {
// 依赖收集
childOb.dep.depend()
if (Array.isArray(value)) {
dependArray(value)
}
}
}
return value
},
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
// #7981: for accessor properties without setter
if (getter && !setter) return
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = !shallow && observe(newVal)
// 在setter中通知依赖更新
dep.notify()
}
})
}
三、虚拟dom
1.虚拟DOM简介
所谓虚拟DOM,就是用一个JS对象来描述一个DOM节点,像如下示例:
<div class="a" id="b">我是内容</div>
{
tag:'div', // 元素标签
attrs:{ // 属性
class:'a',
id:'b'
},
text:'我是内容', // 文本内容
children:[] // 子元素
}
为什么要有虚拟DOM?
Vue是数据驱动视图的,数据发生变化视图就要随之更新,在更新视图的时候难免要操作DOM,而操作真实DOM又是非常耗费性能的。
通过JS的计算性能来换取操作DOM所消耗的性能
2.vnode类
// 源码位置:src/core/vdom/vnode.js
export default class VNode {
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
this.tag = tag // 当前节点的标签名
this.data = data // 当前节点对应的对象,包含了具体的一些数据信息,是一个VNodeData类型,可以参考VNodeData类型中的数据信息
this.children = children // 当前节点的子节点,是一个数组
this.text = text // 当前节点的子节点,是一个数组
this.elm = elm // 当前虚拟节点对应的真实dom节点
this.ns = undefined // 当前节点的名字空间
this.context = context // 当前组件节点对应的Vue实例
this.fnContext = undefined // 函数式组件对应的Vue实例
this.fnOptions = undefined
this.fnScopeId = undefined
this.key = data && data.key // 节点的key属性,被当作节点的标志,用以优化
this.componentOptions = componentOptions // 组件的option选项
this.componentInstance = undefined // 当前节点对应的组件的实例
this.parent = undefined // 当前节点的父节点
this.raw = false // 简而言之就是是否为原生HTML或只是普通文本,innerHTML的时候为true,textContent的时候为false
this.isStatic = false // 静态节点标志
this.isRootInsert = true // 是否作为跟节点插入
this.isComment = false // 是否为注释节点
this.isCloned = false // 是否为克隆节点
this.isOnce = false // 是否有v-once指令
this.asyncFactory = asyncFactory
this.asyncMeta = undefined
this.isAsyncPlaceholder = false
}
get child (): Component | void {
return this.componentInstance
}
}
3.VNode的类型
共有六种节点类型,区别:只是在实例化传入的参数不同
注释节点
文本节点
元素节点
组件节点
函数式组件节点
克隆节点
源码位置:src/core/vdom/vnode.js
- 注释节点
// 创建注释节点
export const createEmptyVNode = (text: string = '') => {
const node = new VNode()
// 具体的注释信息
node.text = text
// isComment 用来标识一个节点是否是注释节点
node.isComment = true
return node
}
- 文本节点
// 创建文本节点
export function createTextVNode (val: string | number) {
// text属性,用来表示具体的文本信息
return new VNode(undefined, undefined, undefined, String(val))
}
- 元素节点
- 组件节点
组件节点除了有元素节点具有的属性之外,它还有两个特有的属性
componentOptions :组件的option选项,如组件的props等
componentInstance :当前组件节点对应的Vue实例 - 函数式组件节点
函数式组件节点相较于组件节点,它又有两个特有的属性:
fnContext:函数式组件对应的Vue实例
fnOptions: 组件的option选项 - 克隆节点
// 创建克隆节点
// 把一个已经存在的节点复制一份出来,它主要是为了做模板编译优化时使用
export function cloneVNode (vnode: VNode): VNode {
const cloned = new VNode(
vnode.tag,
vnode.data,
vnode.children,
vnode.text,
vnode.elm,
vnode.context,
vnode.componentOptions,
vnode.asyncFactory
)
cloned.ns = vnode.ns
cloned.isStatic = vnode.isStatic
cloned.key = vnode.key
cloned.isComment = vnode.isComment
cloned.fnContext = vnode.fnContext
cloned.fnOptions = vnode.fnOptions
cloned.fnScopeId = vnode.fnScopeId
cloned.asyncMeta = vnode.asyncMeta
cloned.isCloned = true
return cloned
}
vnode的作用
在视图渲染之前,把写好的template模板编译成vnode并缓存下来,等数据发生变化时,对比上一次的vnode,找出差异,然后有差异的VNode对应的真实DOM节点就是需要重新渲染的节点,最后根据有差异的VNode创建出真实的DOM节点再插入到视图中,最终完成一次视图更新
4.DOM-Diff
4.1.patch过程
patch简介:在vue中,把DOM-Diff过程叫做patch过程,patch译为补丁的意思,即对旧的vnode进行修补。
绑定旧的vnode之后,更新之后只会通过对比更新旧的vnode,不会直接用新的Vnode直接替换旧的Vnode
patch需要做的事情
- 创建节点:新的Vnode中有而旧的oldVNode中没有,就在旧的中创建
- 删除节点:新的Vnode中没有而旧的oldVNode中有,在旧的中删除
- 更新节点:如果新的旧的都有。则以新的vnode中的为准,更新旧的oldVNode
4.2 创建节点
Vnode类可以创建6种类型的节点,只有元素节点、注释节点、文本节点可以被插入到DOM中
// 源码位置: /src/core/vdom/patch.js
function createElm (vnode, parentElm, refElm) {
const data = vnode.data
const children = vnode.children
const tag = vnode.tag
if (isDef(tag)) {
vnode.elm = nodeOps.createElement(tag, vnode) // 创建元素节点
createChildren(vnode, children, insertedVnodeQueue) // 创建元素节点的子节点
insert(parentElm, vnode.elm, refElm) // 插入到DOM中
} else if (isTrue(vnode.isComment)) {
vnode.elm = nodeOps.createComment(vnode.text) // 创建注释节点
insert(parentElm, vnode.elm, refElm) // 插入到DOM中
} else {
vnode.elm = nodeOps.createTextNode(vnode.text) // 创建文本节点
insert(parentElm, vnode.elm, refElm) // 插入到DOM中
}
}
- 判断是否为元素节点只需判断该VNode节点是否有tag标签即可。如果有tag属性即认为是元素节点,则调用createElement方法创建元素节点,通常元素节点还会有子节点,那就递归遍历创建所有子节点,将所有子节点创建好之后insert插入到当前元素节点里面,最后把当前元素节点插入到DOM中。
- 判断是否为注释节点,只需判断VNode的isComment属性是否为true即可,若为true则为注释节点,则调用createComment方法创建注释节点,再插入到DOM中。
- 如果既不是元素节点,也不是注释节点,那就认为是文本节点,则调用createTextNode方法创建文本节点,再插入到DOM中。

4.3 删除节点
如果某些节点再新的VNode中没有而在旧的oldVNode中有,那么就需要把这些节点从旧的oldVNode中删除。删除节点非常简单,只需在要删除节点的父元素上调用removeChild方法即可。源码如下:
function removeNode (el) {
const parent = nodeOps.parentNode(el) // 获取父节点
if (isDef(parent)) {
nodeOps.removeChild(parent, el) // 调用父节点的removeChild方法
}
}
4.4 更新节点
更新节点就是在新旧vnode都存在的情况下,对比新旧vnode找出差异,并且更新旧的vnode的操作
静态节点:只包含纯文本的节点为静态节点,例:
<p>我是静态节点</p>
分为以下3种情况
1.新旧vnode都是静态节点
不管数据如何变化,静态节点不变,静态节点直接跳过
2. 新vnode是文本节点
如果VNode是文本节点即表示这个节点内只包含纯文本,那么只需看oldVNode是否也是文本节点,如果是,那就比较两个文本是否不同,如果不同则把oldVNode里的文本改成跟VNode的文本一样。如果oldVNode不是文本节点,那么不论它是什么,直接调用setTextNode方法把它改成文本节点,并且文本内容跟VNode相同。
3. 都是元素节点
分为以下两种情况
3.1. 新VNode节点包含子节点
如果旧的vnode包含子节点,需要递归逐层遍历子节点是否相同,更新子节点;
如果旧的vnode不包含子节点,则可能是空节点或文本节点,无论是哪种形式,则都需要根据新的vnode创建一份子节点结合插入到旧的节点中。
3.2. 新VNode节点不包含子节点
如果该节点不包含子节点,同时它又不是文本节点,那就说明该节点是个空节点,那就好办了,不管旧节点之前里面都有啥,直接清空即可。
源码,文件位置:src/core/vdom/patch.js
function patchVnode (
oldVnode,
vnode,
insertedVnodeQueue,
ownerArray,
index,
removeOnly
) {
// 判断新旧vnode是否相等
if (oldVnode === vnode) {
return
}
// isDef判断是否为null或undefined
// elm为vnode中实际dom元素
if (isDef(vnode.elm) && isDef(ownerArray)) {
// clone reused vnode
vnode = ownerArray[index] = cloneVNode(vnode)
}
const elm = vnode.elm = oldVnode.elm
if (isTrue(oldVnode.isAsyncPlaceholder)) {
if (isDef(vnode.asyncFactory.resolved)) {
hydrate(oldVnode.elm, vnode, insertedVnodeQueue)
} else {
vnode.isAsyncPlaceholder = true
}
return
}
// 判断新旧vnode是否为静态节点 以及判断是否为克隆节点和是否存在v-once指令
if (isTrue(vnode.isStatic) &&
isTrue(oldVnode.isStatic) &&
vnode.key === oldVnode.key &&
(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))
) {
// 把旧的vnode的当前组件节点对应的Vue实例赋值给新vnode
vnode.componentInstance = oldVnode.componentInstance
return
}
let i
// vnode.data是当前节点对应的对象,包含了具体的一些数据信息,是一个VNodeData类型
const data = vnode.data
if (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) {
i(oldVnode, vnode)
}
const oldCh = oldVnode.children
const ch = vnode.children
if (isDef(data) && isPatchable(vnode)) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode)
}
// vnode是否有text属性
if (isUndef(vnode.text)) {
// vnode的子节点与oldVnode的子节点是否都存在
if (isDef(oldCh) && isDef(ch)) {
// 若都存在,判断子节点是否相同,不同则更新子节点
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
// 若只有vnode的子节点存在
// 如果不是生产环境则检查是否存在相同得key,如果存在则报警告 Duplicate keys detected
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(ch)
}
// 判断oldVnode是否有文本
// 若没有,则把vnode的子节点添加到真实DOM中
// 若有,则清空Dom中的文本,再把vnode的子节点添加到真实DOM中
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 若只有oldnode的子节点存在
// 清空DOM中的子节点
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// 若vnode和oldnode都没有子节点,但是oldnode中有文本
// 清空oldnode文本
nodeOps.setTextContent(elm, '')
}
// 如果vnode中既没有text,也没有子节点,那么对应的oldnode中有什么就清空什么
} else if (oldVnode.text !== vnode.text) {
// vnode的text属性与oldVnode的text属性是否相同
// 若不相同:则用vnode的text替换真实DOM的文本
nodeOps.setTextContent(elm, vnode.text)
}
if (isDef(data)) {
if (isDef(i = data.hook) && isDef(i = i.postpatch)) i(oldVnode, vnode)
}
}
节点更新流程:

四、模板编译
编译流程

1.流程解析
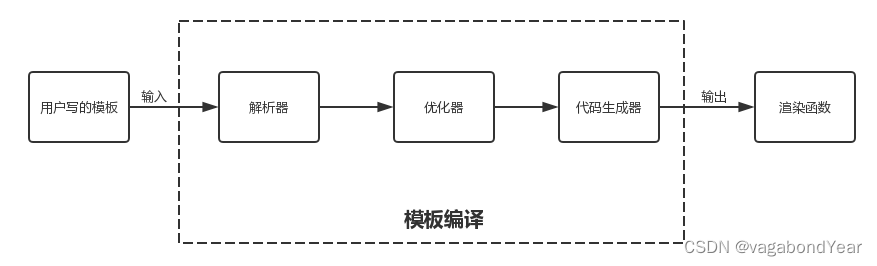
- 模板解析阶段:将一堆模板字符串用正则等方式解析成抽象语法树AST;源码路径:src/compiler/parser/index.js;
- 优化阶段:遍历AST,找出其中的静态节点,并打上标记;
- 代码生成阶段:将AST转换成渲染函数;
// 源码位置:src/compiler/index.js
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
// 模板解析阶段:用正则等方式解析 template 模板中的指令、class、style等数据,形成AST
const ast = parse(template.trim(), options)
if (options.optimize !== false) {
optimize(ast, options)
}
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})
AST语法树
在计算机科学中,抽象语法树(AbstractSyntaxTree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于if-condition-then这样的条件跳转语句,可以使用带有两个分支的节点来表示。——来自百度百科

1.1 模板解析
模板字符串包含的节点类型
1. 文本
2. HTML注释,例如<!-- 我是注释 -->
3. 条件注释,例如<!-- [if !IE]> -->我是注释<!--< ![endif] -->
4. DOCTYPE,例如<!DOCTYPE html>
5. 开始标签,例如<div>
6. 结束标签,例如</div>
构建AST流程
- 将一个HTML标签分解为startTag,endTag和文本内容三部分对待;
- 创建一个栈结构,用来存放startTag;
- 遇到起始标签时入栈,遇到结束标签时出栈。每插入一个起始标签,都会以栈中上一个标签当作父节点;
- 对自闭合标签做特殊处理;
- 若出现嵌套问题,即结束标签与栈顶标签对应不上,则从栈顶一直循环出栈,直到找到相匹配的起始标签,并抛出错误;
例子:
<div>
<div>123</div>
<span></span>
</div>
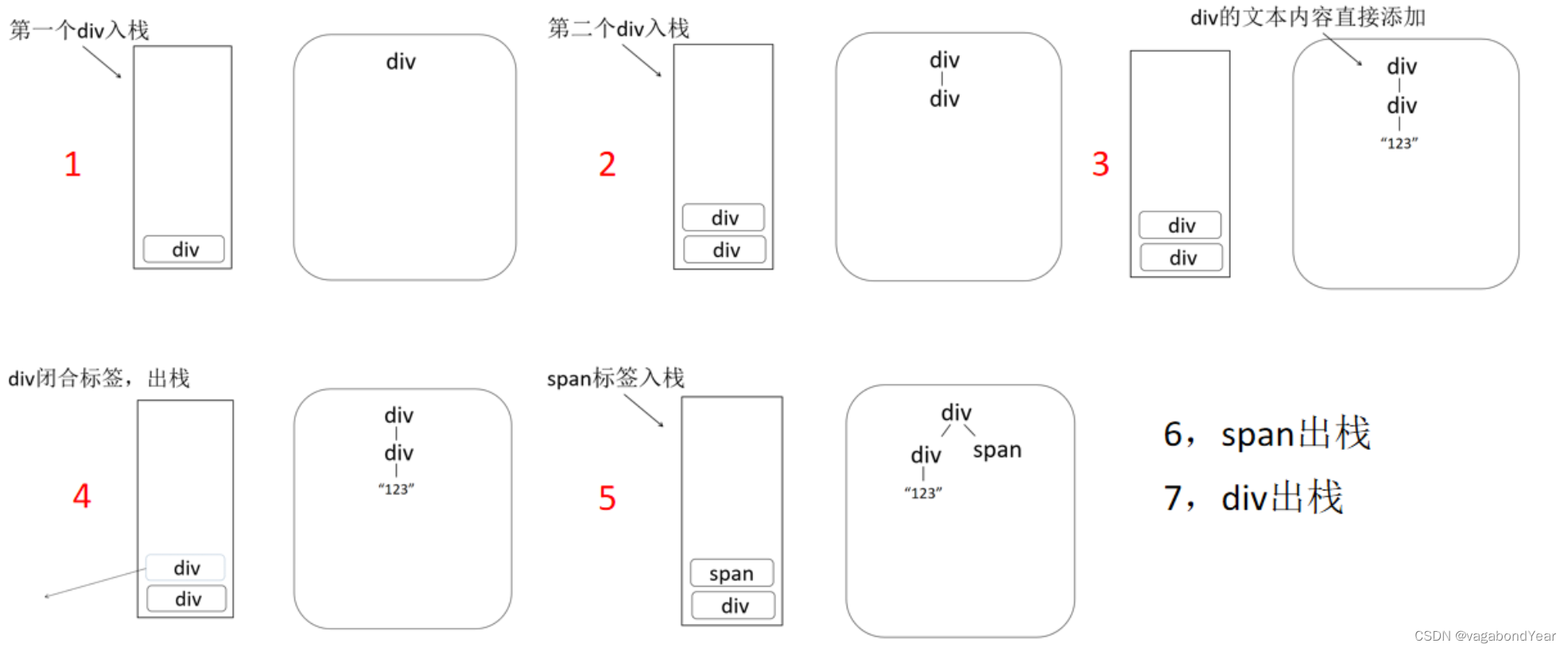
源码解析:
parse方法的主函数:
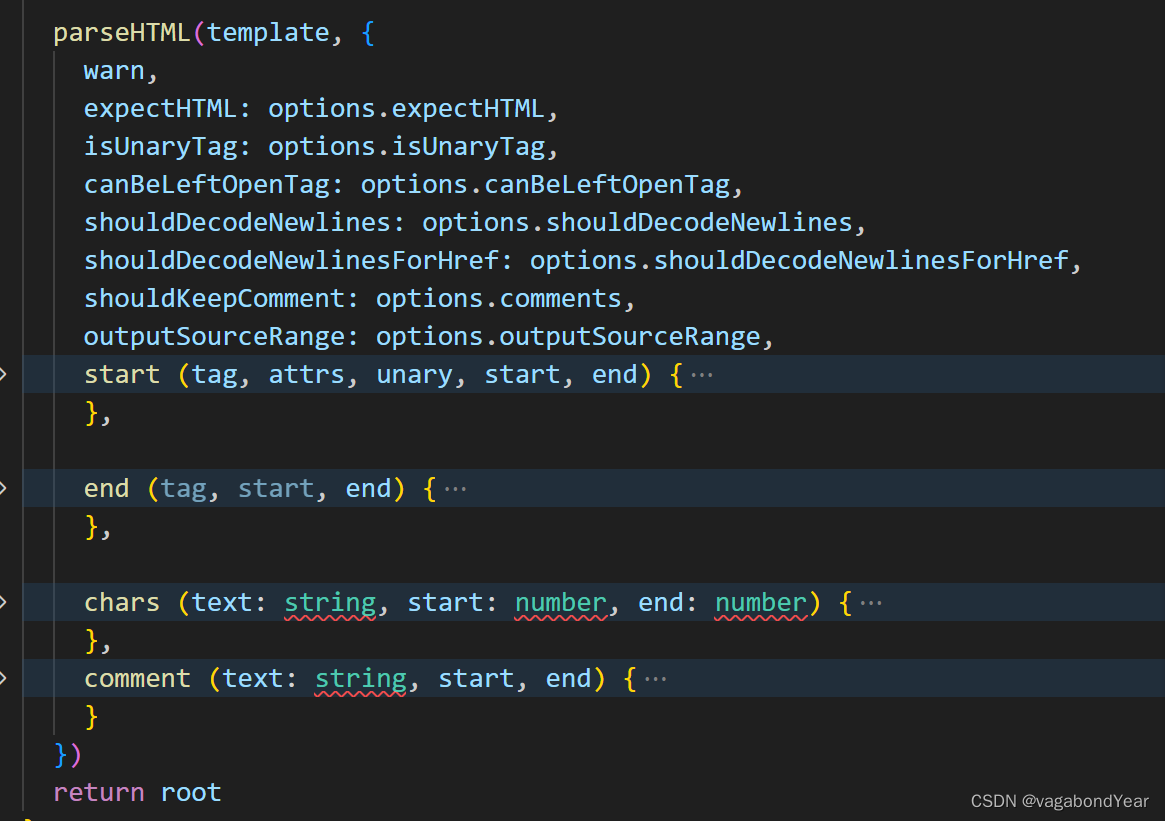
parseHTML方法作用
7. 从头开始解析html字符串,并逐渐截取掉已解析的html字符串,直到html字符串为空,也就代表整个html都解析完成;
8. 通过正则表达式去匹配标签
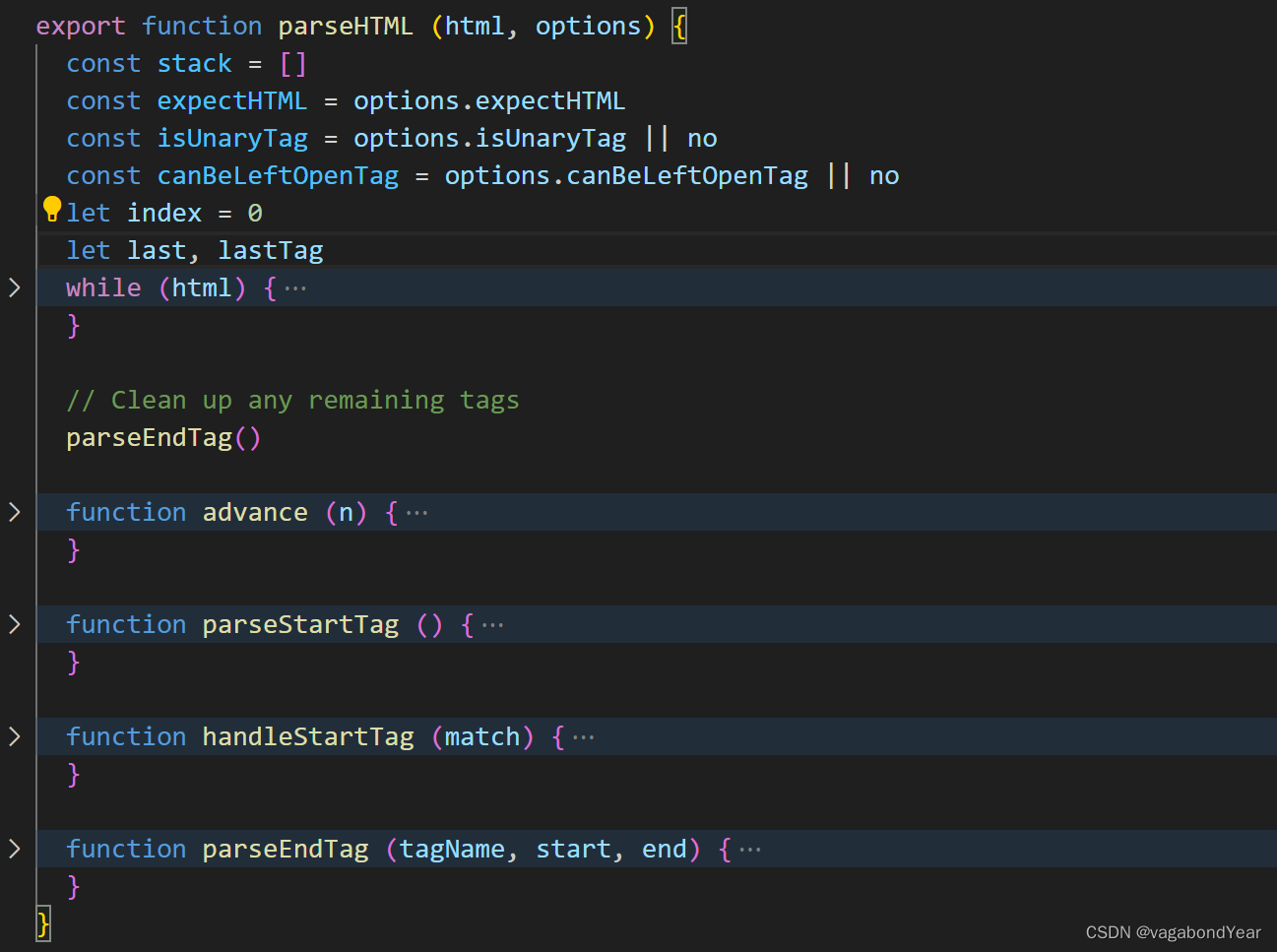
parseHTML源码
function parseHTML(html, options) {
var stack = []; // 维护AST节点层级的栈
var expectHTML = options.expectHTML; /
var isUnaryTag$$1 = options.isUnaryTag || no;
var canBeLeftOpenTag$$1 = options.canBeLeftOpenTag || no; /用来检测一个标签是否是可以省略闭合标签的非自闭合标签
var index = 0; //解析游标,标识当前从何处开始解析模板字符串
var last, // 存储剩余还未解析的模板字符串
lastTag; // 存储着位于 stack 栈顶的元素
// 开启一个 while 循环,循环结束的条件是 html 为空,即 html 被 parse 完毕
while (html) {
last = html;
// 确保即将 parse 的内容不是在纯文本标签里 (script,style,textarea)
// !lastTag即表示当前html字符串没有父节点
// isPlainTextElement(lastTag) 是检测 lastTag 是否为是那三个纯文本标签之一
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
/**
* 如果html字符串是以'<'开头,则有以下几种可能
* 开始标签:<div>
* 结束标签:</div>
* 注释:<!-- 我是注释 -->
* 条件注释:<!-- [if !IE] --> <!-- [endif] -->
* DOCTYPE:<!DOCTYPE html>
* 需要一一去匹配尝试
*/
if (textEnd === 0) {
// 解析是否是注释
if (comment.test(html)) {
}
// 解析是否是条件注释
if (conditionalComment.test(html)) {
}
// 解析是否是DOCTYPE
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
}
// 解析是否是结束标签
const endTagMatch = html.match(endTag)
if (endTagMatch) {
}
// 匹配是否是开始标签
const startTagMatch = parseStartTag()
if (startTagMatch) {
}
}
// 如果html字符串不是以'<'开头,则解析文本类型
let text, rest, next
if (textEnd >= 0) {
}
// 如果在html字符串中没有找到'<',表示这一段html字符串都是纯文本
if (textEnd < 0) {
text = html
html = ''
}
// 把截取出来的text转化成textAST
if (options.chars && text) {
options.chars(text)
}
} else {
// 父元素为script、style、textarea时,其内部的内容全部当做纯文本处理
}
//将整个字符串作为文本对待
if (html === last) {
options.chars && options.chars(html);
//创建文本类型的AST节点的时候如果抛出异常如下:模板字符串中标签格式有误
if (!stack.length && options.warn) {
options.warn(("Mal-formatted tag at end of template: \"" + html + "\""));
}
break
}
}
// Clean up any remaining tags
parseEndTag();
//parse 开始标签
function parseStartTag() {
}
//处理 parseStartTag 的结果
function handleStartTag(match) {
}
//parse 结束标签
function parseEndTag(tagName, start, end) {
}
}
startTag开始标签匹配:
// Start tag: 起始节点
const startTagMatch = parseStartTag()
if (startTagMatch) {
handleStartTag(startTagMatch)
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1)
}
continue
}
function parseStartTag () {
// 匹配正则表达式,如果能成功匹配,则该正则还会捕获tagName信息
const start = html.match(startTagOpen)
if (start) {
// 创建一个match字面量对象,先给tagName和start属性赋值。tagName就为正则所匹配的tagName,也就是当前匹配的标签名。而index即为当前标签处于html字符串的下标位置
const match = {
tagName: start[1],
attrs: [],
start: index
}
// advance更改index的位置以及从index处截取html字符串
advance(start[0].length)
let end, attr
// 对截取过后的html字符串,再做一个标签内部的while循环。而该循环的作用,简单来说,
// 就是获取起始标签结束之前的所有属性内容(在起始标签的匹配中,也是分为了三部分:
// 起始标签的开始startTagOpen,标签内的属性attribute,起始标签的结束startTagClose);
while (!(end = html.match(startTagClose)) && (attr = html.match(dynamicArgAttribute) || html.match(attribute))) {
// 在标签内部的循环中,会通过正则获取到属性的信息,
// 并将这些信息统统push到match对象的attr数组中。
// 匹配的过程与主循环类似,都是匹配、捕获、截取(html前进)。直到匹配到startTagClose,退出标签的内部循环
attr.start = index
advance(attr[0].length)
attr.end = index
match.attrs.push(attr)
}
// 退出parseStartTag函数,并返回match对象。需要做advance将html截取掉解析的部分。
// 而在此给match对象添加上的unarySlash属性,即为通过startTagClose捕获到的 > 之前的 / 。
// 如果该值为 / ,则代表标签自闭合,否则则代表为普通标签。
if (end) {
match.unarySlash = end[1]
advance(end[0].length)
match.end = index
return match
}
}
}
返回的match对象示例
<div id="app">test</div>
{
"tagName": "div",
"attrs": [
[
" id=\"app\"",
"id",
"=",
"app",
null,
null
]
],
"start": 0,
"unarySlash": "",
"end": 14
}
最终返回的AST树形结构
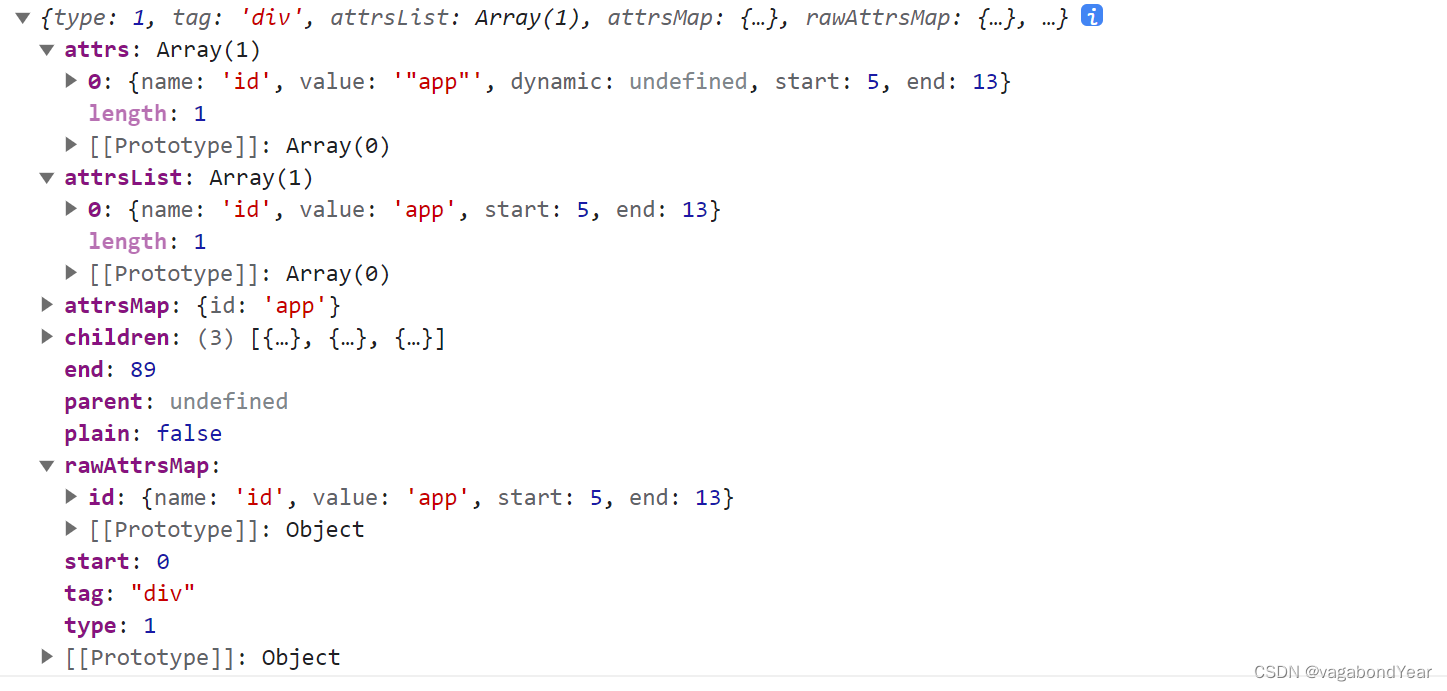
vue中匹配标签正则表达式:
// 匹配开始标签的正则表达式:
const startTagOpen = /^<((?:[a-zA-Z_][\\-\\.0-9_a-zA-Za-zA-Z\\u00B7\\u00C0-\\u00D6\\u00D8-\\u00F6\\u00F8-\\u037D\\u037F-\\u1FFF\\u200C-\\u200D\\u203F-\\u2040\\u2070-\\u218F\\u2C00-\\u2FEF\\u3001-\\uD7FF\\uF900-\\uFDCF\\uFDF0-\\uFFFD]*\\:)?[a-zA-Z_][\\-\\.0-9_a-zA-Za-zA-Z\\u00B7\\u00C0-\\u00D6\\u00D8-\\u00F6\\u00F8-\\u037D\\u037F-\\u1FFF\\u200C-\\u200D\\u203F-\\u2040\\u2070-\\u218F\\u2C00-\\u2FEF\\u3001-\\uD7FF\\uF900-\\uFDCF\\uFDF0-\\uFFFD]*)/
// 匹配标签后的 >或 />
const startTagClose = /^\s*(\/?)>/
// 匹配标签中属性表达式
const dynamicArgAttribute = /^\s*((?:v-[\w-]+:|@|:|#)\[[^=]+?\][^\s"'<>\/=]*)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
// 匹配html的注释节点
const comment = /^<!\--/
// 匹配<! 开头的节点 例如:<!DOCTYPE html>
const conditionalComment = /^<!\[/
// 匹配结束标签 例子:</div>
const endTag=/^<\\/((?:[a-zA-Z_][\\-\\.0-9_a-zA-Za-zA-Z\\u00B7\\u00C0-\\u00D6\\u00D8-\\u00F6\\u00F8-\\u037D\\u037F-\\u1FFF\\u200C-\\u200D\\u203F-\\u2040\\u2070-\\u218F\\u2C00-\\u2FEF\\u3001-\\uD7FF\\uF900-\\uFDCF\\uFDF0-\\uFFFD]*\\:)?[a-zA-Z_][\\-\\.0-9_a-zA-Za-zA-Z\\u00B7\\u00C0-\\u00D6\\u00D8-\\u00F6\\u00F8-\\u037D\\u037F-\\u1FFF\\u200C-\\u200D\\u203F-\\u2040\\u2070-\\u218F\\u2C00-\\u2FEF\\u3001-\\uD7FF\\uF900-\\uFDCF\\uFDF0-\\uFFFD]*)[^>]*>/
1.1.1 注释节点解析(html)
const comment = /^<!\--/
if (comment.test(html)) {
// 若为注释,则继续查找是否存在'-->'
const commentEnd = html.indexOf('-->')
if (commentEnd >= 0) {
// 若存在 '-->',继续判断options中是否保留注释
if (options.shouldKeepComment) {
// 若保留注释,则把注释截取出来传给options.comment,创建注释类型的AST节点
options.comment(html.substring(4, commentEnd))
}
// 若不保留注释,则将游标移动到'-->'之后,继续向后解析
advance(commentEnd + 3)
continue
}
}
如果模板字符串html符合注释开始的正则,那么就继续向后查找是否存在–>,若存在,则把html从第4位(" 处,截取得到的内容就是注释的真实内容,然后调用4个钩子函数中的comment函数,将真实的注释内容传进去,创建注释类型的AST节点。
1.1.2 条件注释解析(html)
由于条件注释不存在于真正的DOM树中,所以不需要调用钩子函数创建AST节点。代码如下:
// 解析是否是条件注释
const conditionalComment = /^<!\[/
if (conditionalComment.test(html)) {
// 若为条件注释,则继续查找是否存在']>'
const conditionalEnd = html.indexOf(']>')
if (conditionalEnd >= 0) {
// 若存在 ']>',则从原本的html字符串中把条件注释截掉,
// 把剩下的内容重新赋给html,继续向后匹配
advance(conditionalEnd + 2)
continue
}
}
1.1.3 DOCTYPE解析
const doctype = /^<!DOCTYPE [^>]+>/i
// 解析是否是DOCTYPE
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
advance(doctypeMatch[0].length)
continue
}
1.1.4 开始标签解析
/**
* 匹配开始标签的正则
*/
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
const start = html.match(startTagOpen)
if (start) {
const match = {
tagName: start[1],
attrs: [],
start: index
}
}
// 以开始标签开始的模板:
'<div></div>'.match(startTagOpen) => ['<div','div',index:0,input:'<div></div>']
匹配标签属性
标签属性可能存在存个,需要循环进行匹配
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
const startTagClose = /^\s*(\/?)>/
const match = {
tagName: start[1],
attrs: [],
start: index
}
// 只有当字符串为 > 或者 \> 开头时才认为当前标签结束
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length)
match.attrs.push(attr)
}
自闭合标签
使用开始标签的正则进行匹配,根据匹配结果的第二项判断是否为自闭合标签
const startTagClose = /^\s*(\/?)>/
let end = html.match(startTagClose)
'></div>'.match(startTagClose) // [">", "", index: 0, input: "></div>", groups: undefined]
'/>'.match(startTagClose) // ["/>", "/", index: 0, input: "/><div></div>", groups: undefined]
handleStartTag
解析出来的标签再执行handleStartTag方法,其主要作用就是:
- 将attrs数组的每一项处理为更规范的name、value形式;
- 通过判断是否为自闭合标签,决定是否将标签添加至stack栈(因为自闭合标签不需要入栈,其不会有内容,也不会有结束标签);
- 调用start,也就是parse函数传递过来的函数钩子。
function handleStartTag (match) {
const tagName = match.tagName // 开始标签的标签名
const unarySlash = match.unarySlash // 是否为自闭合标签的标志,自闭合为"",非自闭合为"/"
if (expectHTML) {
if (lastTag === 'p' && isNonPhrasingTag(tagName)) {
parseEndTag(lastTag)
}
if (canBeLeftOpenTag(tagName) && lastTag === tagName) {
parseEndTag(tagName)
}
}
const unary = isUnaryTag(tagName) || !!unarySlash // 布尔值,标志是否为自闭合标签
const l = match.attrs.length // match.attrs 数组的长度
const attrs = new Array(l) // 一个与match.attrs数组长度相等的数组
// attrs数据结构:["class="a"", "class", "=", "a", undefined, undefined, index: 0, input: "class="a" id="b"></div>", groups: undefined]
for (let i = 0; i < l; i++) {
const args = match.attrs[i]
const value = args[3] || args[4] || args[5] || ''
// shouldDecodeNewlines 这个常量主要是做一些兼容性处理
// 如果 shouldDecodeNewlines 为 true,意味着 Vue 在编译模板的时候,要对属性值中的换行符或制表符做兼容处理。
// shouldDecodeNewlinesForHref为true 意味着Vue在编译模板的时候,要对a标签的 href属性值中的换行符或制表符做兼容处理
const shouldDecodeNewlines = tagName === 'a' && args[1] === 'href'
? options.shouldDecodeNewlinesForHref
: options.shouldDecodeNewlines
attrs[i] = {
name: args[1],
value: decodeAttr(value, shouldDecodeNewlines)
}
if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {
attrs[i].start = args.start + args[0].match(/^\s*/).length
attrs[i].end = args.end
}
}
// 如果该标签是非自闭合标签,则将标签推入栈中
if (!unary) {
stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs, start: match.start, end: match.end })
lastTag = tagName
}
// 如果该标签是自闭合标签,现在就可以调用start钩子函数并传入处理好的参数来创建AST节点了
if (options.start) {
options.start(tagName, attrs, unary, match.start, match.end)
}
}
1.1.5 结束标签解析
结束标签正则:
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`)
const endTagMatch = html.match(endTag)
// 如果模板字符串符合结束标签的特征,则会获得匹配结果数组;如果不合符,则得到null
'</div>'.match(endTag) // ["</div>", "div", index: 0, input: "</div>", groups: undefined]
1.1.6 文本解析
流程:
- 通过正则查找第一个
<出现在什么位置 - 如果出现在开头,则认为是其它5种类型;
- 如果不是出现在开头或者不存的话则为文本
let textEnd = html.indexOf('<')
// '<' 在第一个位置,为其余5种类型
if (textEnd === 0) {
// ...
}
// '<' 不在第一个位置,文本开头
if (textEnd >= 0) {
// 如果html字符串不是以'<'开头,说明'<'前面的都是纯文本,无需处理
// 那就把'<'以后的内容拿出来赋给rest
rest = html.slice(textEnd)
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as text
/**
* 用'<'以后的内容rest去匹配endTag、startTagOpen、comment、conditionalComment
* 如果都匹配不上,表示'<'是属于文本本身的内容
*/
// 在'<'之后查找是否还有'<'
next = rest.indexOf('<', 1)
// 如果没有了,表示'<'后面也是文本
if (next < 0) break
// 如果还有,表示'<'是文本中的一个字符
textEnd += next
// 那就把next之后的内容截出来继续下一轮循环匹配
rest = html.slice(textEnd)
}
// '<'是结束标签的开始 ,说明从开始到'<'都是文本,截取出来
text = html.substring(0, textEnd)
advance(textEnd)
}
// 整个模板字符串里没有找到`<`,说明整个模板字符串都是文本
if (textEnd < 0) {
text = html
html = ''
}
// 把截取出来的text转化成textAST
if (options.chars && text) {
options.chars(text)
}
1.2 文本解析
// 当解析到标签的文本时,触发chars
chars (text) {
if(res = parseText(text)){
// 包含变量的文本
let element = {
type: 2,
expression: res.expression,
tokens: res.tokens,
text
}
} else {
// 不包含变量的文本
let element = {
type: 3,
text
}
}
}
parseText返回值示例
let text = "我叫{{name}},我今年{{age}}岁了"
let res = parseText(text)
res = {
expression:"我叫"+_s(name)+",我今年"+_s(age)+"岁了",
tokens:[
"我叫",
{'@binding': name },
",我今年"
{'@binding': age },
"岁了"
]
}
文本解析器流程
- 判断传入的文本是否包含变量
- 构造expression
- 构造tokens
















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











