






Learning Roadmap:
Section 1: Intro to Parallel Programming & MUSA
- Deep Learning Ecosystem(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/20)
- Ubuntu+Driver+Toolkit+conda+pytorch+torch_musa环境安装(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/24-CSDN博客)
- C/C++ Review(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/22-CSDN博客)
- GPU intros(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/25-CSDN博客)
- GPU硬件架构 (摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/26-CSDN博客)
- Write First Kernels (Here)
- MUSA API
- Faster Matrix Multiplication
- Triton
- Pytorch Extensions(摩尔线程国产显卡 MUSA 并行编程学习笔记-2024/11/21-CSDN博客)
- MNIST Multilayer Perceptron
Section 2: Parallel Programming & MUSA in Depth
- Analyzing Parallel Program Performance on a Quad-Core CPU
- Scheduling Task Graphs on a Multi-Core CPU
- A Simple Renderer in MUSA
- Optimizing DNN Performance on DNN Accelerator Hardware
- llm.c
Ref:
https://www.youtube.com/watch?v=86FAWCzIe_4&t=1012s
https://www.youtube.com/watch?v=V1tINV2-9p4
https://gfxcourses.stanford.edu/cs149/fall24
线程层级
Ref:MUSA基础编程 | 摩尔学院 - MUSA基础编程 | High-Performance Computing with GPUs
一个典型的异构编程流程(Host:CPU,Device:GPU)
-
分配Host Memory,并进行数据初始化;
-
分配Device Memory,并将数据从Host Memory拷贝到Device Memory上;
-
调用kernel函数,在Device上执行指定的任务;
-
将Device Memory中的结果拷贝回Host Memory;
-
释放Device和Host上分配的Memory。
Kernels
functions run on GPU
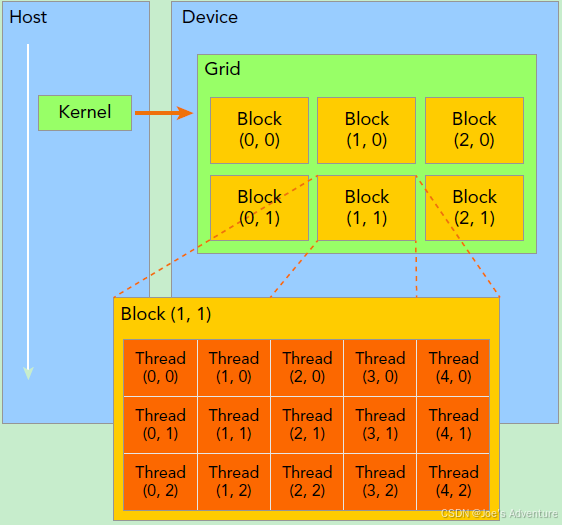
Thread(线程)
-
线程是GPU编程模型中执行计算或访存最底层的抽象
-
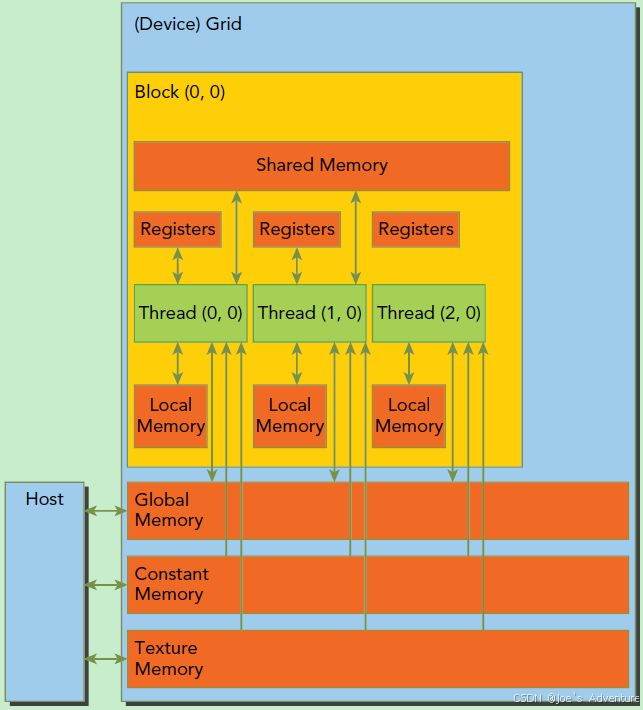
每个Thread有自己的local memory 和Registers
Block(线程块)
-
Thread被Group到一个三维的Block中
-
同一block内的线程可以利用shared memory进行数据共享
-
同一个block通常被用来执行相同的kernels on different data
-
blockDim:线程块的维度
-
ThreadIdx:Thread在block中的唯一标识
Grid(网格)
-
Block被Group到一个Grid中
-
Grid中的Block中的Thread都可以访问global memory
-
MUSA中还存在两个只读的内存空间可供所有线程访问:constant memory和texture memory。global memory、constant memory和texture memory三个内存空间针对不同的内存使用进行了优化,texture memory还可以为某些特定数据格式提供不同的寻址模式以及数据过滤,在实际使用中可以根据需求选择不同内存空间来实现任务需求。
Wrap(线程束)
-
每个内核通过线程束在block中管理线程
-
线程束内所有线程在同一时间会执行相同指令,所以当它们拥有相同的执行路径时效率最高


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









