









记录一下scrapy实现分布式爬虫:
所用版本:
pip install scrapy==2.5.1
pip install scrapy-redis==0.7.2
开始先记录遇到的问题,方便读者解决:
问题一、
版本问题,有的版本过高会导致scrapy-redis无法正常使用,这边建议卸载,再重新安装指定版本,可以参考安装和我一样版本的,卸载安装过的库只需要执行命令pip uninstall scrapy即可卸载其他同理。
问题二、
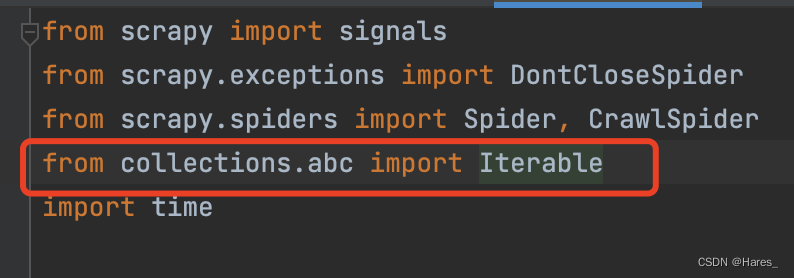
报错:from collections import Iterable ImportError: cannot import name 'Iterable' from 'collections'

这是因为python版本过高的问题所导致未能正常导包,解决方法点击链接,接着进入spiders文件中,将代码改为下图红色框一至即可解决
接着再次运行又会出现新报错:odule 'OpenSSL.SSL' has no attribute 'SSLv3_METHOD'
这里只需要安装对应的库即可:pip install pyOpenSSL==22.0.0 接着就能成功运行。
问题三、
另起终端进入当前文件夹后python3.10 runner.py 却出现报错的情况:No model named ‘scrapy_redis‘
原因是因为,终端所执行的环境与pycharm所在的环境不一样,所以报错,解决方法有两个
方法1:
将终端环境安装与pycharm相同的库
方法2:
进入项目的虚拟环境中,再执行代码
mac系统:
1.找到当前项目的venv的文件夹开启终端接着cd进入bin
2.接着执行source activate即可看见出现(venv)的标志说明进入成功
win系统:
1.pycharm每创建一个新项目就会创建一个虚拟环境,位于项目下venv下Script
2.cd进入位置后输入activate回车即可进入(venv)中
先捋一下运作原理:
1. 某个爬虫从redis_key获取到起始url. 传递给引擎, 到调度器. 然后把起始url直接丢到redis的请求队列里. 开始了scrapy的爬虫抓取工作.
2. 如果抓取过程中产生了新的请求. 不论是哪个节点产生的, 最终都会到redis的去重集合中进行判定是否抓取过.
3. 如果抓取过. 直接就放弃该请求. 如果没有抓取过. 自动丢到redis请求队列中.
4. 调度器继续从redis请求队列里获取要进行抓取的请求. 完成爬虫后续的工作.
实现代码:
一切爬取编写方式正常,但是继承的累需要换成 RedisSpider
接着将初始链接改为redis_keyx写法
from scrapy_redis.spiders import RedisSpider
from scrapy import Request,Selector
from scrapy.http import HtmlResponse
class LianjiaScrapySpider(RedisSpider):
name = 'lianjia'
allowed_domains = ['lianjia.com']
redis_key = "lianjia:urls"设置setting:(配置信息是固定的)
SCHEDULER_PERSIST = True # 如果为真. 在关闭时自动保存请求信息, 如果为假, 则不保存请求信息。
管道用不上时候索引掉
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_DB = 0
REDIS_PARAMS = {
"password":"xxxx"
}
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 去重的逻辑. 要用redis的
ITEM_PIPELINES = {
'lianjia.pipelines.lianjiaPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 301 # 配置redis的pipeline
}
编写启动文件:
#方式一:
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(__file__))
execute(["scrapy","crawl","lianjia"])
#方式二:
from scrapy.cmdline import execute
if __name__ == '__main__':
execute("scrapy crawl lianjia".split())
接着运行代码,将会停留没有内容出现,pycharm处就比作一个服务器,另外再开启一个终端,就等于是两个服务器
终端进入当前项目环境:
1.找到当前项目的venv的文件夹开启终端接着cd进入bin
2.接着执行source activate即可看见出现(venv)的标志说明进入成功
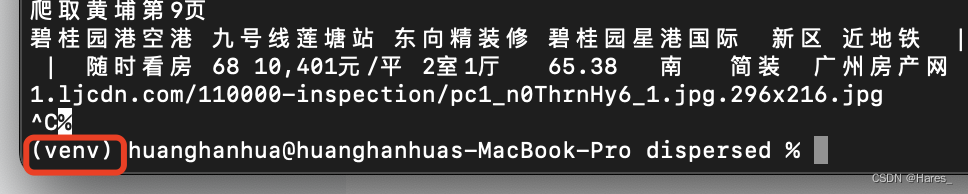
3.cd进入运行的py文件中,执行python xxx.py即可运行(同样会进入等待无显示状态)
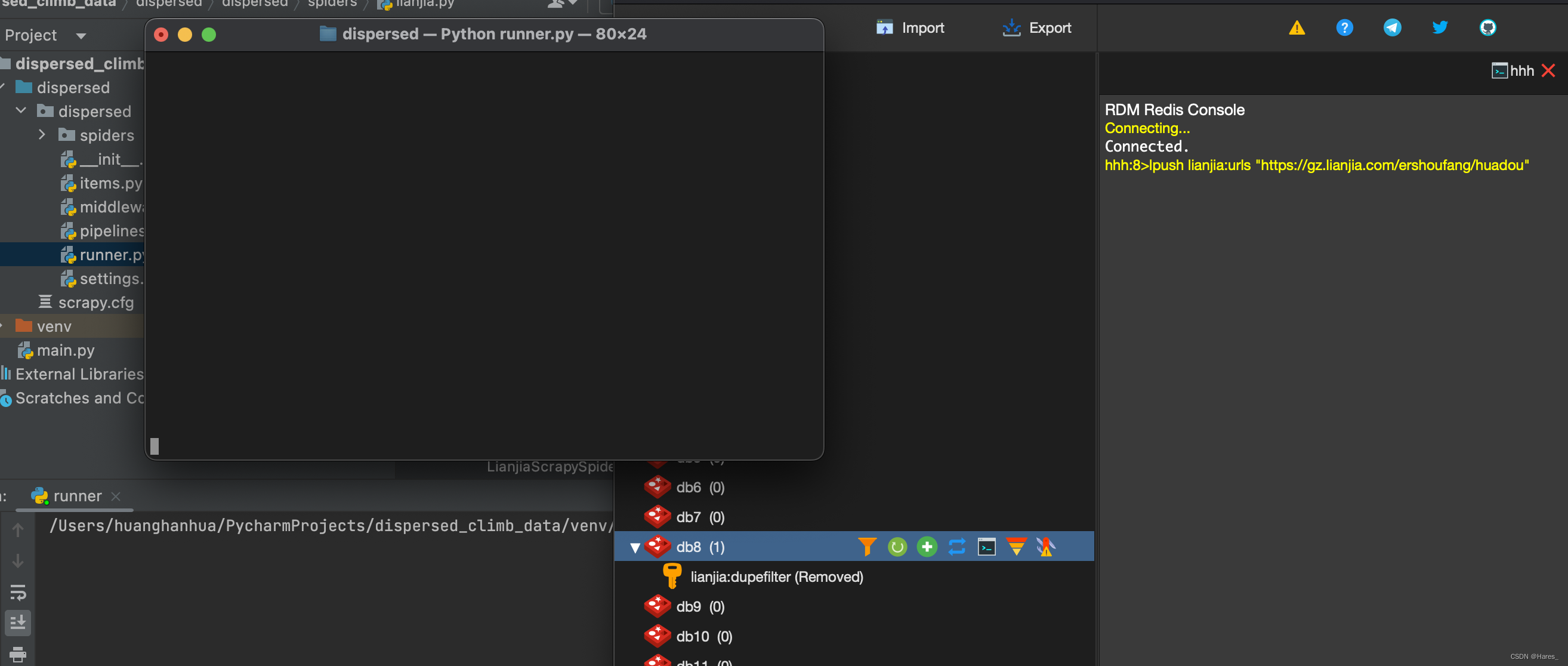
操作完后状态如上图,接着进入redis进入你指定库终端输入命令:(放入初始地址)
lpush lianjiaurls "https://gz.lianjia.com/ershoufang/huadou"接着可以看到有一个终端想运行起来,接着接收到新的url后,底层会进行去重然后再分配给其他终端,接着两个终端一起运行起来
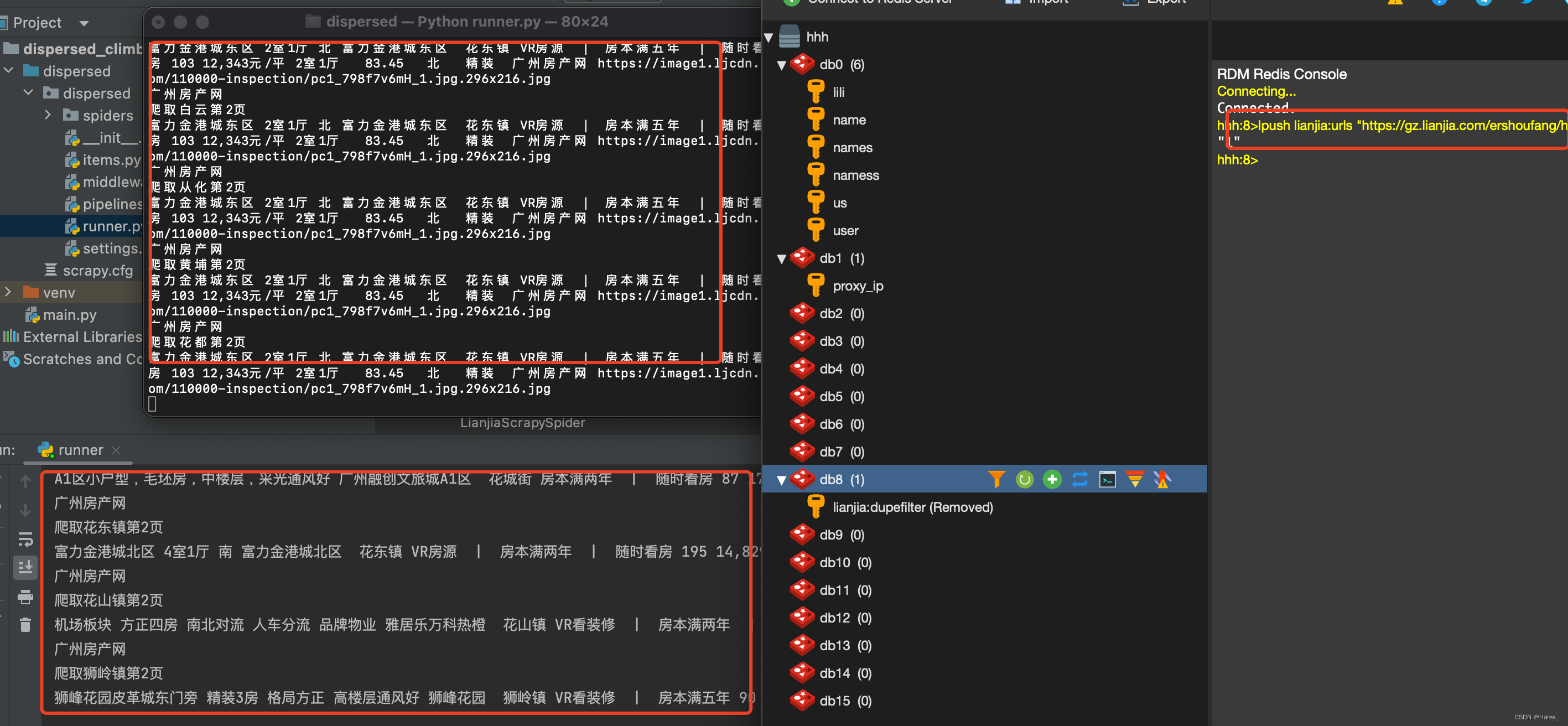
这个时候运行成功!至于未完成爬取想停止下来的话就只能ctrl+c停止,如果想自动停止就需要设置监听了
布隆过滤器:
数据过于庞大时候,越庞大效果越明显
# 安装布隆过滤器
pip install scrapy_redis_bloomfilter
# 去重类,要使用 BloomFilter 请替换 DUPEFILTER_CLASS
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# 哈希函数的个数,默认为 6,可以自行修改
BLOOMFILTER_HASH_NUMBER = 6
# BloomFilter 的 bit 参数,默认 30,占用 128MB 空间
BLOOMFILTER_BIT = 30 这个简单替换后就能使用
















 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











