







聚合结果写入Kafka
概述
- 大家在使用Flink Sql,并将聚合数据写入Kafka的时候,肯定遇到过这样的报错
Exception in thread "main" org.apache.flink.table.api.TableException: AppendStreamTableSink requires that Table has only insert changes. at org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.scala:123) at org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.scala:48) at org.apache.flink.table.planner.plan.nodes.exec.ExecNode$class.translateToPlan(ExecNode.scala:58) at org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToPlan(StreamExecSink.scala:48) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$translateToPlan$1.apply(StreamPlanner.scala:60) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$translateToPlan$1.apply(StreamPlanner.scala:59) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:59) at org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:153) at org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:682) at org.apache.flink.table.api.internal.TableEnvironmentImpl.sqlUpdate(TableEnvironmentImpl.java:495) at tutorial.FlinkSql07.main(FlinkSql07.java:85) - 大家最开始的时候看到这个报错一定是一脸懵逼,这个报错是什么意思?什么叫
AppendStreamTableSink requires that Table has only insert changes. - 于是大家开始面向百度、谷歌开始编程,找到了答案:原来是只支持将
append流数据写入Kafka;那么,append流又是个什么鬼?贴一张官网的图

- 看完之后

这又是什么鬼呢?用微信聊天来给大家解释一下
 像这种就叫做
像这种就叫做append流,消息一直在追加
 我先给对方发送了个
我先给对方发送了个1,然后又撤回发了个2,又撤回,又发送,一直到发送到5,这就叫Retract流
 你以为我只发送了
你以为我只发送了5,其实我1~4都发过,只是我黑了你的手机,把那几条消息都删除了,只剩最后的5,这叫Upsert流 - 几种类型的流说过了,那么为什么只支持将
append流数据写入Kafka呢? - 因为Kafka只支持追加写入操作,不支持更新或者删除操作,就像Hive一样,只能
insert into,不能执行update或者delete语句 - 那么,如何解呢?如果是Java代码的方式可以这样
tEnv.toRetractStream(table, Row.class).flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, Row>() { @Override public void flatMap(Tuple2<Boolean, Row> tuple, Collector<Row> collector) throws Exception { if (tuple.f0) { collector.collect(tuple.f1); } } }); //下面再执行输出到Kafka的操作 - 如果是纯Sql的环境,或者是Zeppelin,那又如何操作呢?
- 这种就只能够通过修改Flink源码的方式,来支持我们的操作了
源码修改
clone的时候,要找到对应版本的源码,不要找错了,这里可以找到所有release的Flink版本,下载的时候一定要看好文件名,要带着src的字眼。- 将我git仓库里面这两个类
KafkaTableSinkBase和KafkaTableSourceSinkFactoryBase
替换源码里面对应的类,具体如何改动我在代码里有注释,这里就不展开说了,篇幅太长 - 再将
flink-connector-kafka-base这个包重新打包mvn clean install -Dcheckstyle.skip=true -Dmaven.test.skip=true -Drat.skip=true -Pscala-2.11,
替换Jar包
- 因为我们最终目的还是要在Zeppelin中跑通我们的代码的,所以要将Zeppelin中,下载的Jar替换成我们的版本
- 打开Zeppelin,来到
Flink Interpreters的配置页面,点击Repository,查看我们依赖下载的位置
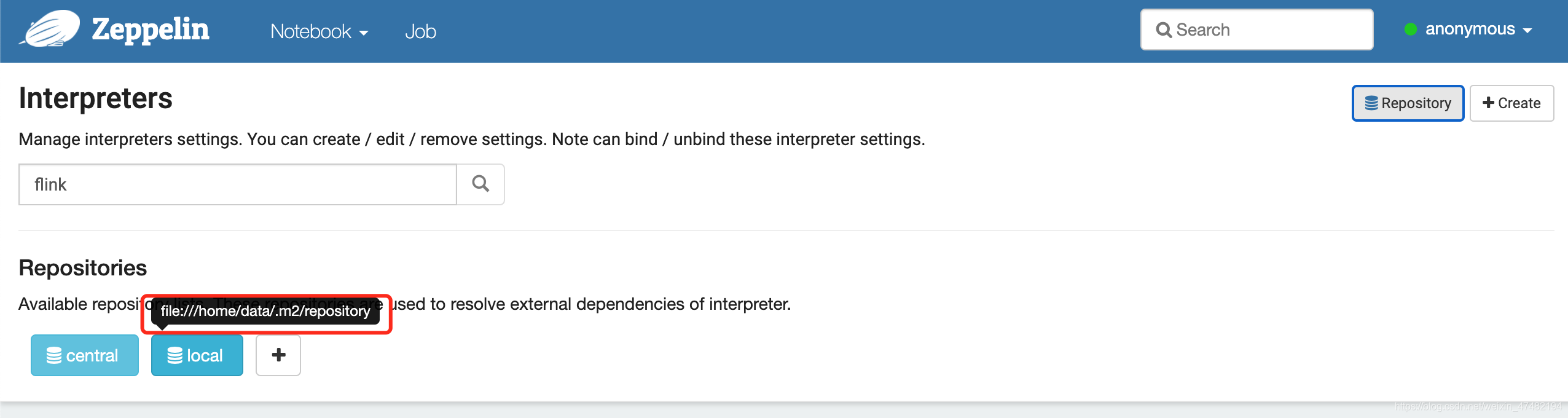
- 将目录
.ivy2/cache/org.apache.flink/flink-connector-kafka-base_2.11/jars下的flink-connector-kafka-base_2.11-1.10.0.jar替换成我们编译后的Jar包 - 将目录
/home/data/.ivy2/jars下的org.apache.flink_flink-connector-kafka-base_2.11-1.10.0.jar删除,将我们的flink-connector-kafka-base_2.11-1.10.0.jar丢到这里,并将名字改成刚才删除的文件名 - 这么如果用的不是
flink.execution.packages方式引入的包,而是flink.execution.jars方式,那么就将对应位置的Jar包替换
运行测试
- 导入配置和建表的语句想必大家已经是轻车熟路了,就不再演示了,贴一下重点代码吧
%flink.ssql -- 插入语句 insert into t2 select behavior , count(distinct user_id) from t1 group by behavior%flink.ssql(type=update) -- 查看数据 select * from t2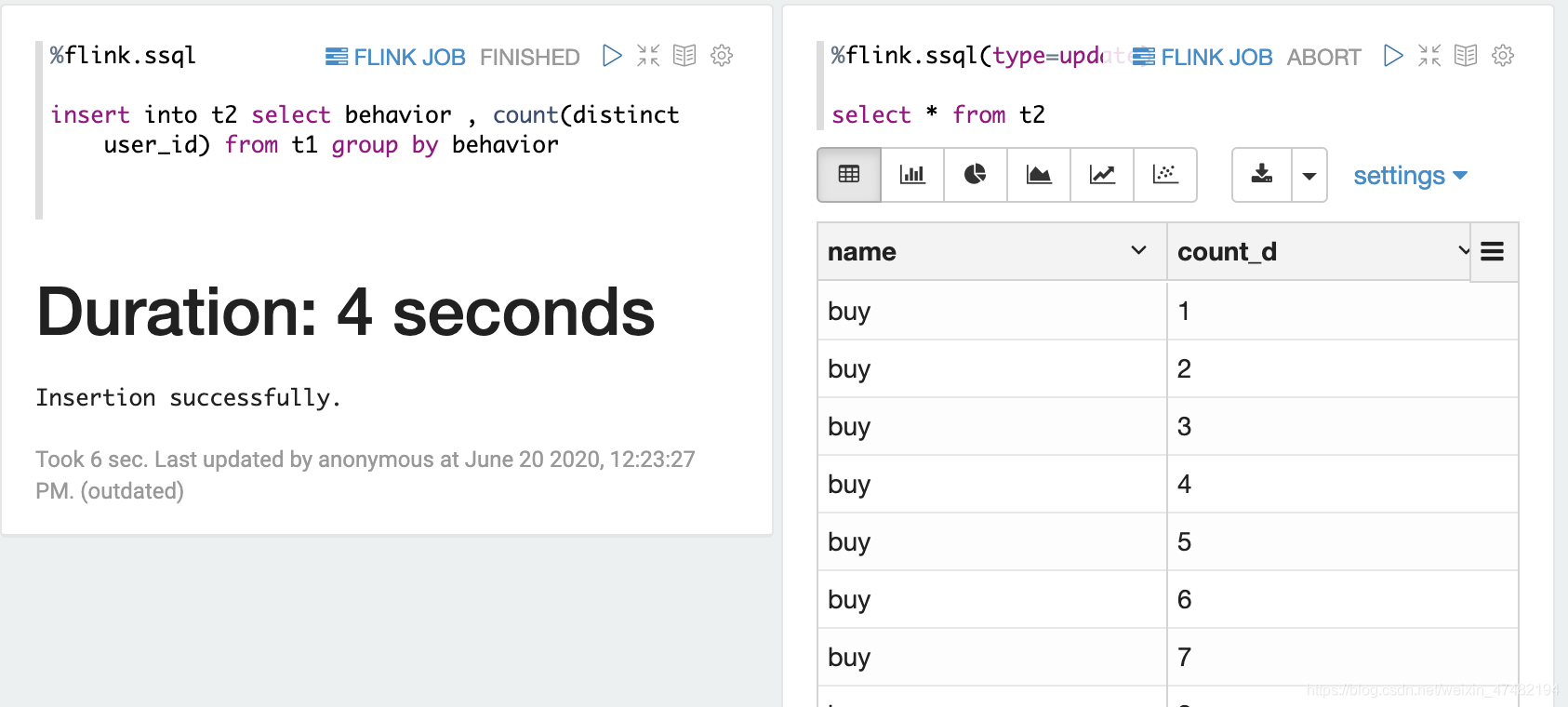
- 可以很明显的看到,我们成功的将
Group By之后的数据插入到了Kafka中 - 因为Kafka只支持追加插入操作,不支持更新和删除操作,所以同样的Key有多条记录,我们需要在下游任务进行对数据的去重,这里就不演示了,去重相关可以看我之前的博客Flink 精准去重
写在最后
- 如果用了类似于
insert into t2 select a.behavior , 10000 from t1 a left join t1 b on a.behavior = b.behavior这样会产生撤回流而且并没有主键的语句,请用Group By+last_value()来强行生成一个主键,否则会报错
这个问题会在1.11支持在DDL中定义UpsertStreamTableSink requires that Table has a full primary keys if it is updated.Primary Key来解决 - 上周末听了
之信大佬分享的关于Flink 1.11的Table部分改进,很多痛点终于得到解决,我已经把1.11的snapshot版本编译完毕,之后会出一篇Flink 1.11的超前点映版本,也是通过Zeppelin来执行Flink Sql代码,感谢Zeppelin的社区工作者这么快支持了Flink 1.11。不过由于Zeppelin 0.9尚未发布,大家可以扫最后的钉钉二维码加入我们的群,下载简峰大佬提供的预览版 - 不过Flink 1.11中还是未能支持将Update数据写入Kafka,
之信大佬说是来不及做了,目前只完成了接口部分,Flink 1.12中会彻底完善。不过可以自己实现,之后我也会发一版Flink 1.11的实现方式,敬请期待吧 - 如果大家偷懒不想自己编译的话,可以点我下载
最后,向大家宣传一下Flink on Zeppelin 的钉钉群,大家有问题可以在里面讨论,简锋大佬也在里面,有问题直接提问就好
















 1978
1978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









