







CNN(卷积神经网络)常被用在影像处理上,可以简化网络的架构
输入是一张用像素表示出来的图片
使用CNN处理图像识别的原因
1.一个特征对于整个图像来说可能很小,因此只要看图片的一部分即可
2.同样的特征可能出现在图片的不同部分,因为他们想实现的功能都相同,因此可以使用相同的参数,尽管是识别在不同位置上的特征(pattern)
3.对图片进行下采样(subsample)不会改变辨识的对象,而能使图片变小,可减少使用的参数
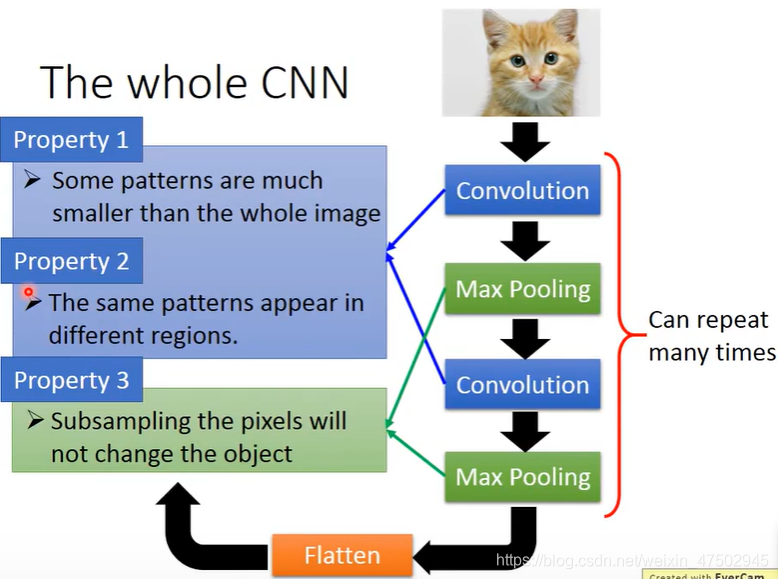
CNN的整体架构
input--convolution--max pooling--convolution--max pooling (可重复数次,重复几次需事先决定)--flatten--将flatten的输出扔到fully connected feedforward network中--最终得到影像辨识的结果
1、2特点可用convolution来解决
第3个特点可以用max pooling来解决
Convolution 卷积层
假设有一个6*6像素的filter,和一个3*3的filter,filter里的参数是由机器学习出来的,不是人为设定的
先将filter放在左上角,计算出filter中的9个值和image左上角9个值的内积,图中filter在左上角时计算出的结果是3
将filter挪动一定的距离,挪动的距离是自己设的,距离叫stride
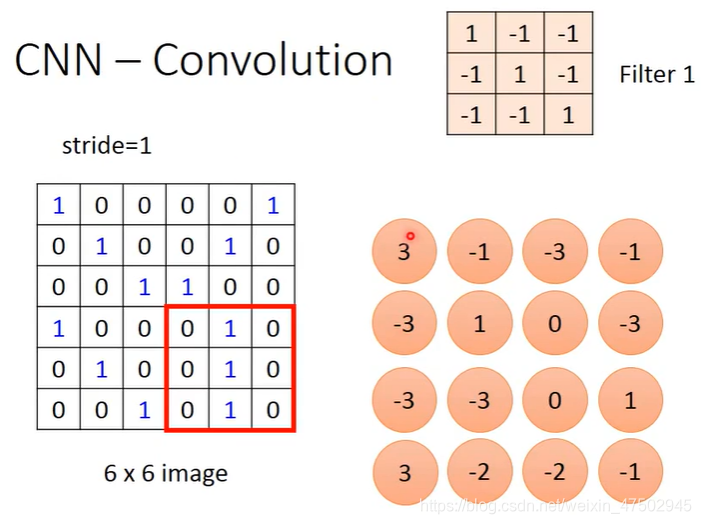
convolution后变成4*4的矩阵,做的工作就是侦测有没有某一个pattern(filter1要找的pattern就是左上到右下三个格子都是1的这种)
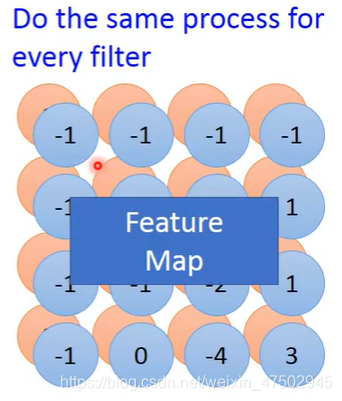
都使用filter1就可以侦测出来,不用使用多个filter,如特点2所述。

用filter2重复上述步骤,红色和蓝色合起来就是feature map
彩色的图像由RGB组成,是由多个矩阵堆叠组成,3原色表示一个像素(一个像素由由3个值组成)
Convolution 与 fully connected 的区别
Convolution 就是 fully connected 拿掉一些weight的结果
一共有36个input,只有其中9个连接到了filter1,filter只有9个weight,因为要侦测一个pattern只要看其中9个就够了,不用看全部的36个
Filter1和filter2有shared weight,因此需要的参数就更少
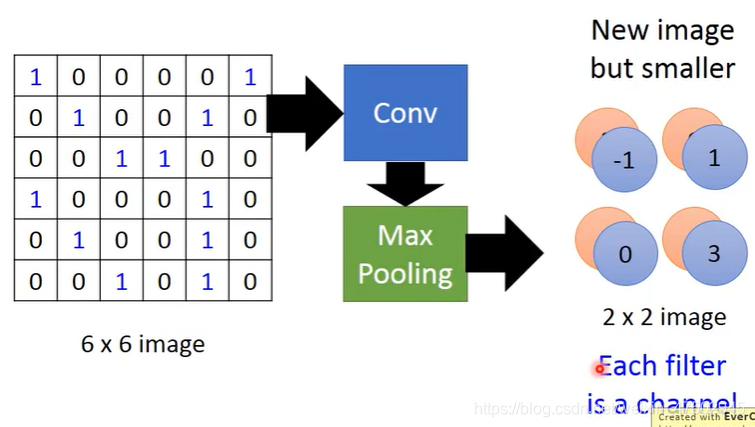
Max pooling
由filter1 得到一个4*4的矩阵,分成4个部分,
由filter2 得到一个4*4的矩阵,分成4个部分,
每个部分可采用取最大值、取平均等方法,将每一部分用一个数表示

上图,留下每个部分的最大值
做完一次conv+一次max pooling将将原来的6*6的图像,变成了新的比较小的2*2的图像
Keras实操
参数解释
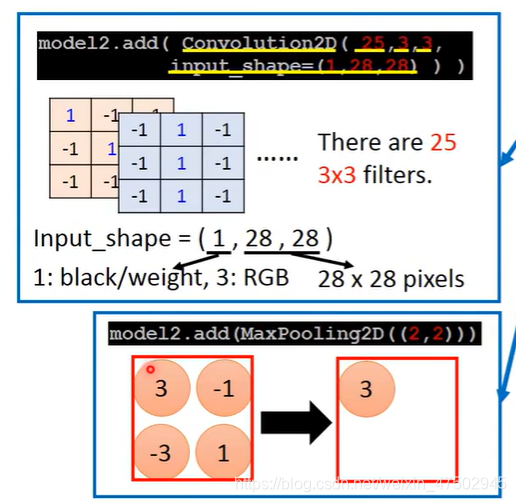
Flatten 就是feature map拉直以后扔到 fully connected feedforward netword 进行训练
如歌分析理解第二次的conv+max polling
1、取出第k个filter 经过第二次conv后输出的一个11*11的矩阵
其中的每一个元素就用a上标k,下标ij表示
2、定义一个值,第k个filter有多被activate(现在的输入和第K个filter有多匹配)
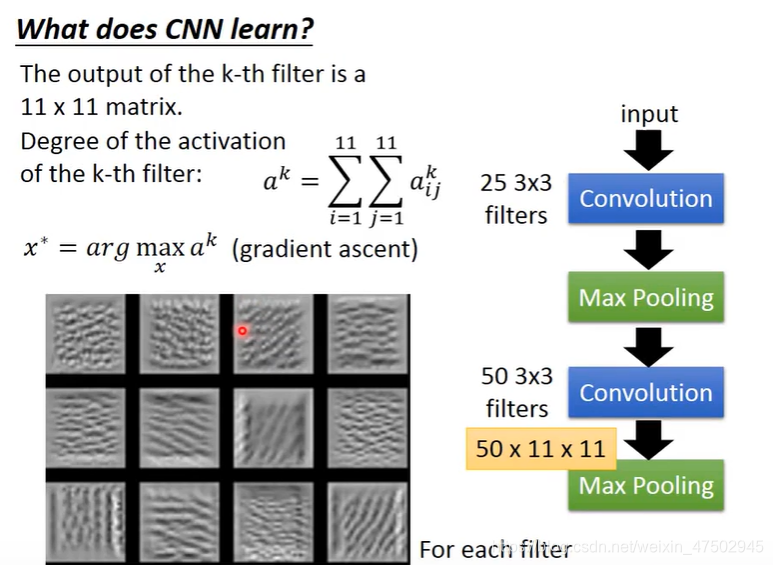
每个filter考虑的都是图上一个小小的范围,如果图上所有部分都出现斜条纹,如第三个filter ,那第三个filter的degree of the activation最大
flatten后,每个neuron的工作是看整张图,侦测的是比较大的pattern
现在的neuron network训练出来的东西可能和人类认知不一样
让图更像数字
对x做出限制,告诉机器有些x能使y很大,但不是数字
假设图像中的每个像素都用xij来表示,我们希望在找一个x可以使yi最大的同时,同时要使Σ|xij|最小(这能使空白区域尽可能多,与尝试相同)

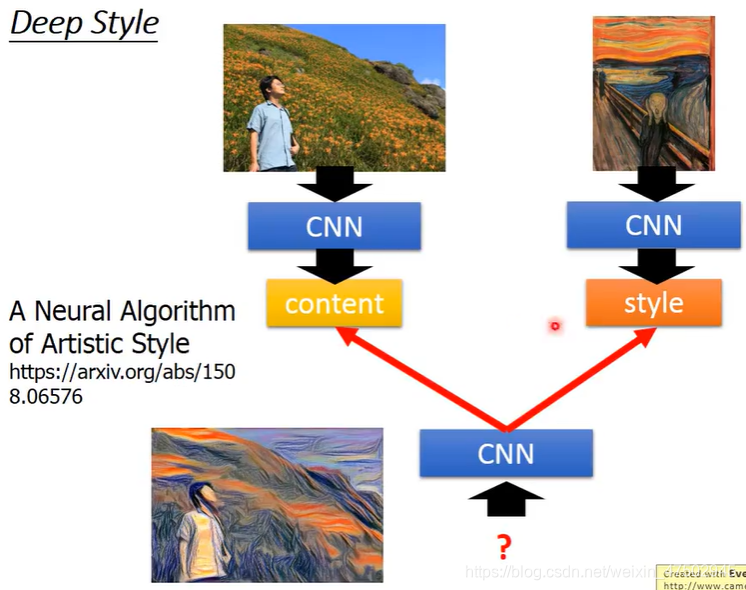
Deep style
输入一张图,使机器去修改这张图,使这张图有另一张图的风格

做法的精神:
将原来的图像丢给cnn,得到cnn的filter的output,cnn的filter的output代表这张图中有什么内容,再将要模仿风格的照片(如:呐喊)也丢到cnn中得到filter的output,得到filter的output,但并不是要关注output的绝对值,而是关注filter之间的correlation,这代表了这张图的风格,
用同一个cnn找一个图片,这个图片的内容像左边的图片,风格像右边的图片(风格像指的是输出的filter之间的correlation),
即找一张图能maximize左边的content和右边的style
什么时候使用cnn
当具有开头所说的3个特性的时候,使用cnn效果更好















 1986
1986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









