







1 实现思路
lab1基于RPC调用
由一个coordinator与一个或者多个Worker构成,下图中的Master由coordinator替代
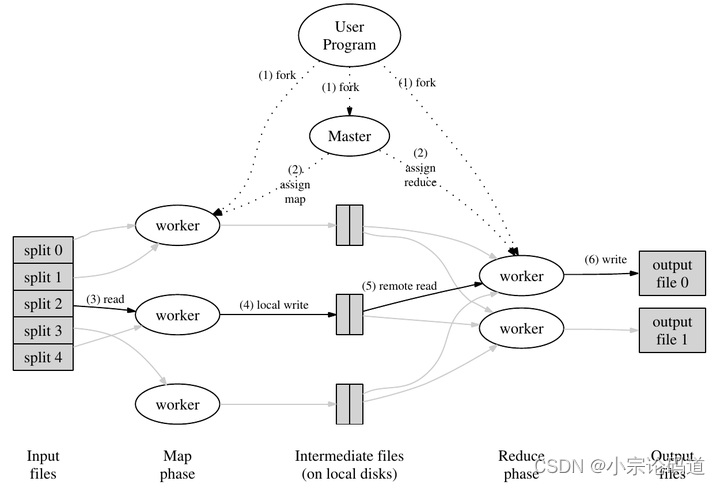
lab1中的worker是一个个独立的进程,这些进程轮询调用coordinator从而获取任务。
由于并未区分Mapper和Reducer所以我们的策略是,先将所有的Map任务全部进行完,进行最终的归约(Reduce)
2 实现难点
- coordinator需要实现超时控制
- 保证线程安全
- 对性能的优化
3 难点攻坚
对于难点1我的实现思路是当coordinator分配任务的时候,开一个go routine负责监听,在go routine当中使用select case监听一个chan
worker任务结束后会请求coordinator的一个方法告知coordinator任务已经完成,在方法当中向chan中传一个消息(Msg) 告知go routine任务完成而go routine可以监听在固定时间内是否接受到信息如果超时(本lab为10s),可触发time.After()处理相关逻辑,比如将任务重新放回分配队列当中
难点1有个地方需要考虑,就是如果go routine认为已经超时,将任务重新放到可分配队列当中
而在这之后,worker才告知coordinator任务完成,这时候如何处理?
我的策略是,所有的task(map和reduce)都维护一个TaskId,map和reduce都维护一个HashSet(哈希表),用来标记这个TaskId是否超时,超时则不处理
难点2 加锁
难点3 见代码,使用队列,以及归并的思路统计数据
代码实现
这里给出rpc.go worker.go coordinator.go的代码
rpc.go
package mr
//
// RPC definitions.
//
// remember to capitalize all names.
//
import (
"os"
"strconv"
)
//
// example to show how to declare the arguments
// and reply for an RPC.
//
type ExampleArgs struct {
X int
}
type ExampleReply struct {
Y int
}
// Add your RPC definitions here.
type TaskArgs struct {
}
type TaskReply struct {
TaskType int // 0 是map任务 1是reduce任务
MapFilename string
ReduceTaskNum int
TaskId int
NReduce int
HasFinished bool
Rejested bool
}
type ReduceMsgArgs struct {
ReduceId int
TaskId int
}
type ReduceMsgReply struct {
Flag bool
}
type MapMsgArgs struct {
Filename string
TaskId int
}
type MapMsgReply struct {
Flag bool
}
// Cook up a unique-ish UNIX-domain socket name
// in /var/tmp, for the coordinator.
// Can't use the current directory since
// Athena AFS doesn't support UNIX-domain sockets.
func coordinatorSock() string {
s := "/var/tmp/5840-mr-"
s += strconv.Itoa(os.Getuid())
return s
}
worker.go
package mr
import (
"encoding/json"
"errors"
"fmt"
"hash/fnv"
"io/ioutil"
"log"
"net/rpc"
"os"
"regexp"
"sort"
"strconv"
"strings"
"time"
)
// for sorting by key.
type ByKey []KeyValue
// for sorting by key.
func (a ByKey) Len() int {
return len(a) }
func (a ByKey) Swap(i, j int) {
a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool {
return a[i].Key < a[j].Key }
//
// Map functions return a slice of KeyValue.
//
type KeyValue struct {
Key string
Value string
}
//
// use ihash(key) % NReduce to choose the reduce
// task number for each KeyValue emitted by Map.
// 通过该方法将一个 key val 映射到相应的reduce服务
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
// 将mapper和reducer抽象成两个结构体
// type Handler interface {
// Handle()
// }
// type MapHandler struct {
// }
// func (m *MapHandler) Handle() {
// }
// type ReduceHandler struct {
// }
// func (r *ReduceHandler) Handle() {
// }
func ReduceHandle(reduceTaskNum int, taskId int, reducef func(string, []string) string) {
// Reduce任务
// 读取所有的以reduceTaskNum 结尾的中间文件
files, err := ioutil.ReadDir(".")
if err != nil {
log.Fatalf("cannot open cur file")
}
re := regexp.MustCompile(`^mr.*\d+$`)
// 用切片记录所有的kv
// kva := make([]KeyValue, 0) 不能全放到一个集合里
// 应该设计数据结构如下
// 每个文件对应一个集合
kva := make(map[string][]KeyValue)
ids := make(map[string]int) // 指针集合,用来遍历所有的kv集合
for _, f := range files {
fileName := f.Name()
if !re.MatchString(fileName) {
continue
}
// 匹配的
parts := strings.Split(fileName, "-")
reduceId, _ := strconv.Atoi(parts[len(parts)-1])
if reduceId != reduceTaskNum {
continue
}
file, err := os.Open(fileName)
if err != nil {
fmt.Println("can not open file %v here", fileName)
}
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
// 如果这个filename对应的切片没有创建这里需要进行创建
if kva[fileName] == nil {
kva[fileName] = make([]KeyValue, 0)
}
kva[fileName] = append(kva[fileName], kv)
}
ids[fileName] = 0 // 遍历从0开始
}
// kva全部找出来了
// 第一步先归并 每个filename对应的集合,需要一个指针,来标记当前记录到哪里了
fileSize := len(kva)
successFile := 0
hasSuccess := make(map[string]bool)
kvs := make([]KeyValue, 0) // 最终大集合
// 需要归并,将key一样的放到一块
for successFile < fileSize {
// 需要变量标记是否是字典序最小的
miniStr := "zzzzzzzzzzzzzzzz"
miniFile := ""
for k, v := range kva {
if hasSuccess[k] {
continue
}
// 遍历所有的集合
index := ids[k]
// 判断这个index是否超出了范围
n := len(v)
if index == n {
// 说明这个文件的数据完成了
successFile++ // 只在第一次触发
hasSuccess[k] = true
continue
}
// v 是这个file的所有KeyValue Key是字符串 Value是1
tmpStr := v[index].Key
if tmpStr < miniStr {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









