










重中之重的并发的入门篇
前言
之前在引入篇就提到过,高并发是java生存根基中的重中之重领域。可以说如果你把高并发玩不明白,你就不会明白所有架构的真谛和意义。你将永远只是一个没有入门的小菜鸟。同理,如果你深入理解了高并发。你将可以做到横跨所有语言和架构。届时你将游刃有余的处理一切核心问题。
当然在初级入门的课程中不会讲的特别深,我会尽可能的阐述更符合实际场景的内容来试图让你先明白它们,等我引导你到-已经可以知道在什么场景用什么的时候。我将一步步给你讲解所有架构和技术的原理。
数组
它是一组相同类型(基础类型&其它类类型)的数据通过某种顺序的排列组合。可以是任意类型,并非字面意义只能表达数字。
基本类型数组
数组语法:String[] strs = new String[]{} 和 String[] strs = new String[4]。=前面的[]代表了定义的是一个数组类型,而=后面的要么是只写new [正整数]设定它的初始大小。要么是new String[]{在这里初始化内容} 比如整数型new int[]{12,3,4}; 字符串型new String[]{"","",""};。{}里的内容代表了初始几个该类型的值,多个用,逗号分开。
数组是一串连续的,固定长度的内存地址空间,所以你在使用new初始化它使它变成一个真正的实例(分配了地址空间的实例)时,必须要设定它的大小或者输入你初始的参数具体内容(你输入了几个,那它就会知道该长度是多少)。也就是说它的长度是不可变的。
package Lesson3;
public class ArrayTest {
public static void main(String[] args) {
int[] i1 = new int[]{12,3,4};
int[] i2 = new int[4];
String[] s1 = new String[]{"a","b","c"};
}
}
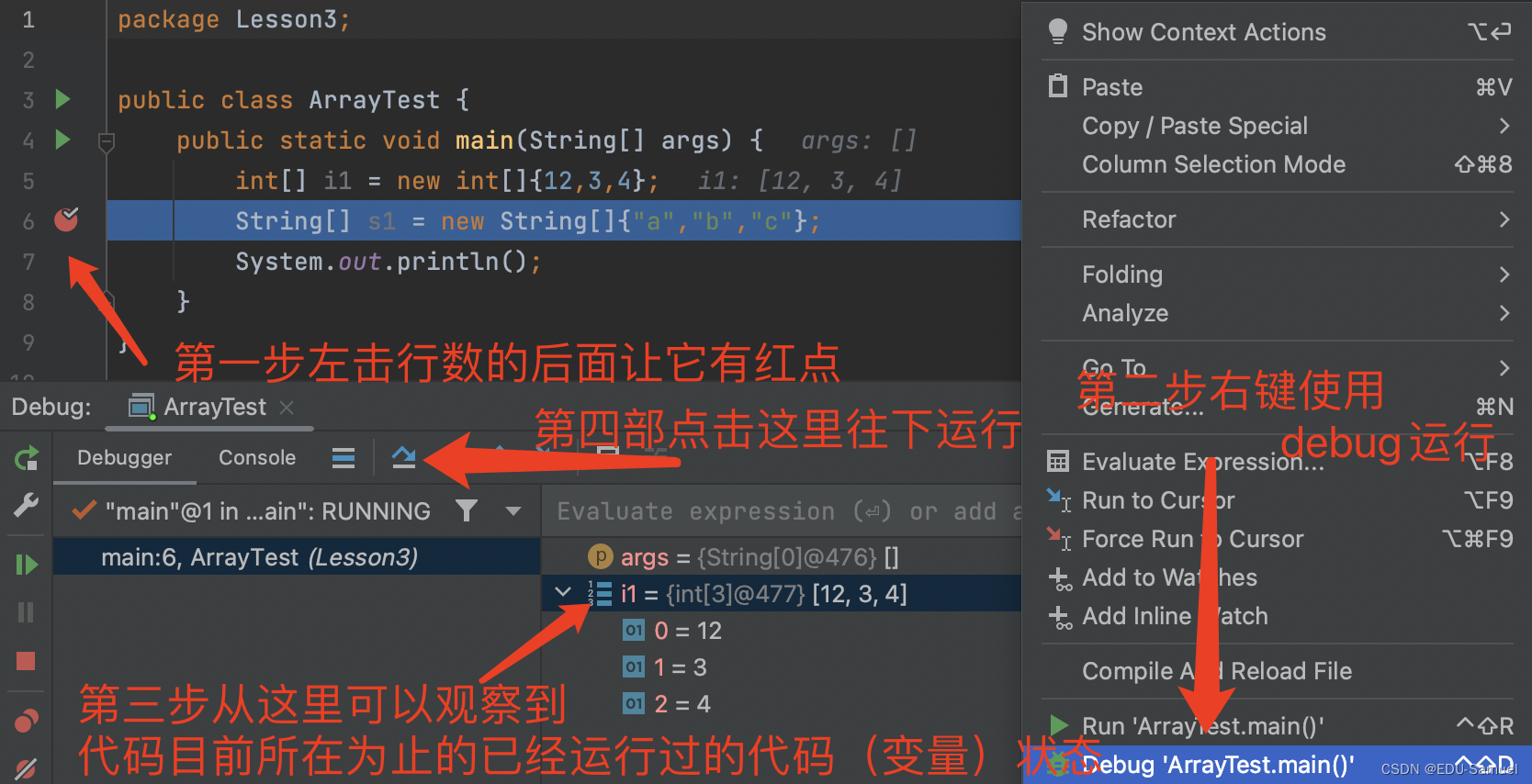
老样子,先新建一个专门用于熟悉与测试运用数组的类,并且加入
主函数入口。我们运行调试它:(图片中第一步的红点叫断点)
可以看到i1变量已经初始化了三个整型为一组,此时它的长度为3,但是在程序中java记录它的顺序的方式是0开始。也就是说当前最后一个值在2的位置。但是数组总长度为3。可以关注到调试界面中的{int[3]@477}3就是长度,@477就是它的内存地址(你现在没有必要去深究它)。
代码示例中通过System.out.println()在命令行中输出了i1数组的索引为[0]的值,通常这里的0,1,2,在java里面叫下标或索引(就是你在字典中查字的拼音笔画部分,这样使得你不需要从头到尾的去翻这个字,耗费大量时间)。
在现实场景中,数组内的值的定义,很有可能是通过其它地方的输入(你并不知道它是什么值)。现在我们可以尝试着解释main函数中的String[] args的意义:它是用于通过程序外部执行时传参来控制程序的走向。这里我们并没有给它传参,也不依赖它去处理。所以并没有解读它而已。
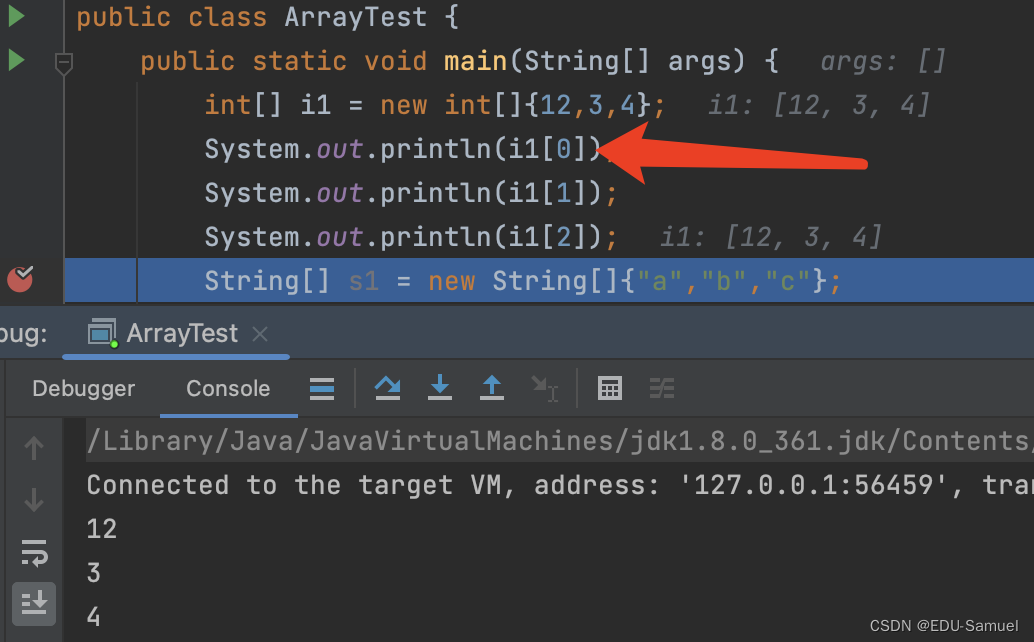
除了直接通过下标的访问方式之外,还可以通过for循环来遍历它。上一课中我们提到了for(;;){}循环,但是那只是它的使用方法之一。
它的两个;在语法中是为了分割三个值(循环代码块中定义一个变量;每循环一次后判断继续循环的条件;每循环一次后做的处理),你可以使用这样的方式来调试它:
- 在for循环代码块中定义了一个
int i = 0的变量;i < i1.length(数组i1的总长度)时则继续循环- 每循环一次则执行一次
i++(加一的语法)- 每次循环都输出
i1[i]的内容,i就是每次循环所代表的值。- 建议反复执行反复思考直到清楚为止

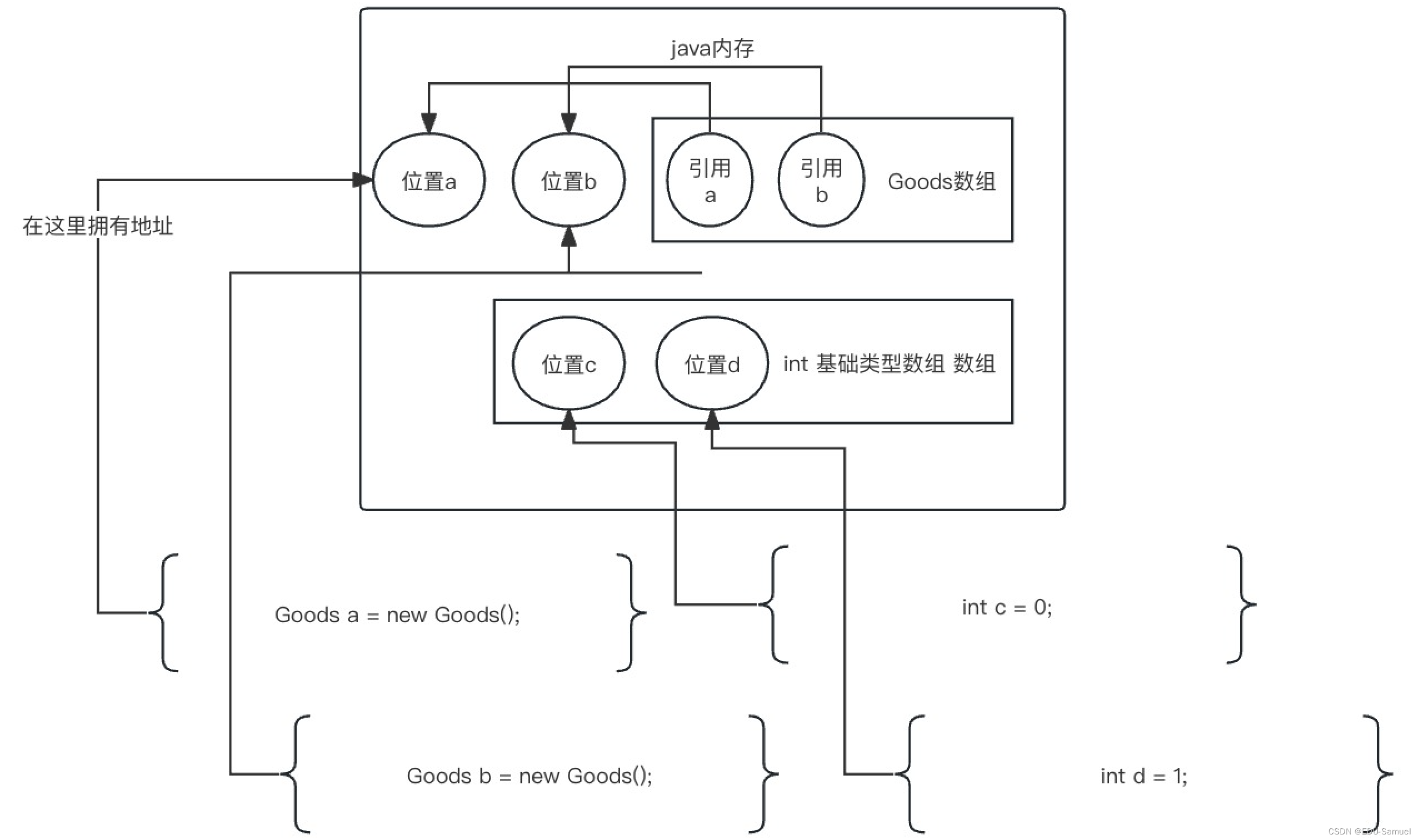
对象类型数组
所有类型的数组语法都一样,String类型就是一个对象数组(前面说过String是一个类,它的语法赋值不同)
如图:
1. 如果是基础类型的数组,它们需要的内存地址是固定的。一个int,一个double,一个String,它们都是固定的大小。
2. 如果是类(引用类型),一个类中包含多少个属性是不固定的。而如果只是单纯的int类型,那么它只需要确定有多少个32位(4字节)即可。(在java中无论32位系统还是64位系统都是32位4字节)
3. 所以对象类型(和引用类型是一回事,叫法不同意义一样),在数组中存的是引用的内存地址(你可以理解为它是一个String变量,所以它是固定长度的)。
4. 而基础类型的数组它们真正切切的存在于数组的连续内存地址当中。
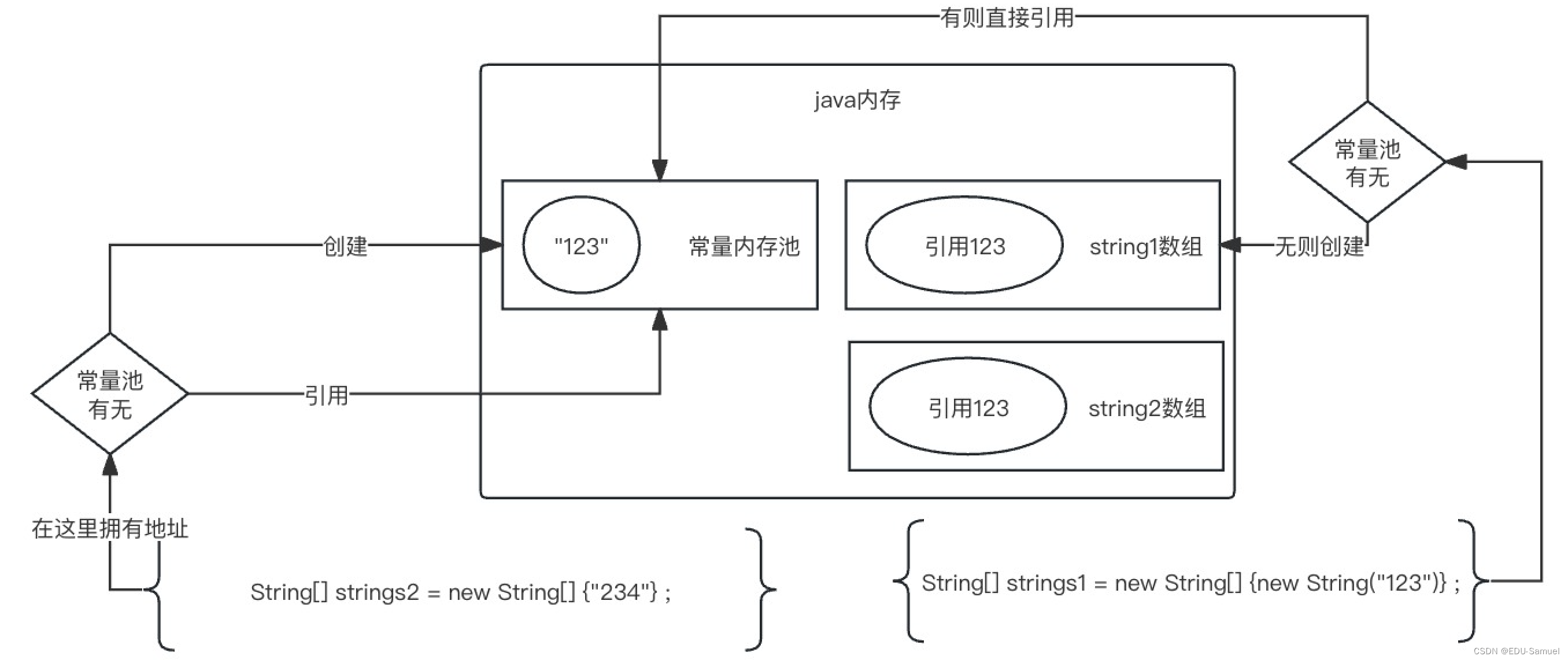
所以其它类型(自定义类等)除外,基于特殊的String类型不同的两种定义变量方式,在定义数组时,也就可以写成这样:
package Lesson3;
public class ArrayTest {
public static void main(String[] args) {
String[] strings1 = new String[] {new String("123")} ;
String[] strings2 = new String[] {"234} ;
}
}
两者是截然不同的:
1.通过new创建的strings1的123一定会在堆内存(公用内存)中新建一个对象,同时也会判断常量池中是否存在。
2. 通过=创建的字符串只会在常量池中新建和引用。
3. 其它类型的对象参考new方式。
4. 再次强调,String在java中是特殊的存在。
通过泛型与定义数组
泛型:不确定的类型。这是进一步加深程序动态性的特性,加强了类的灵活性和封装性。
灵活性:同样对类的操作,原本只能用来操作某一个类。这里新建一个类,添加了一个用于把
String[]类型数组的某个i下标的值删除。
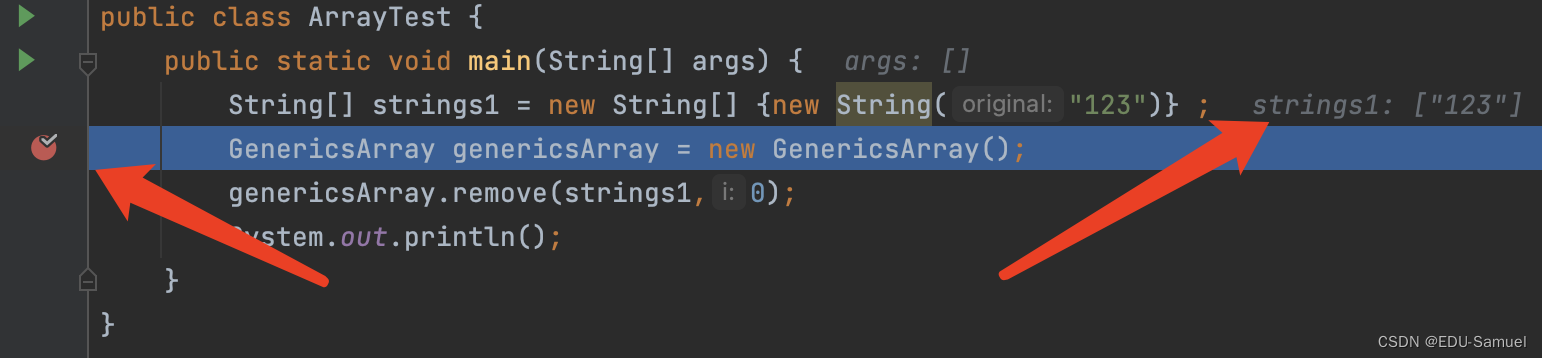
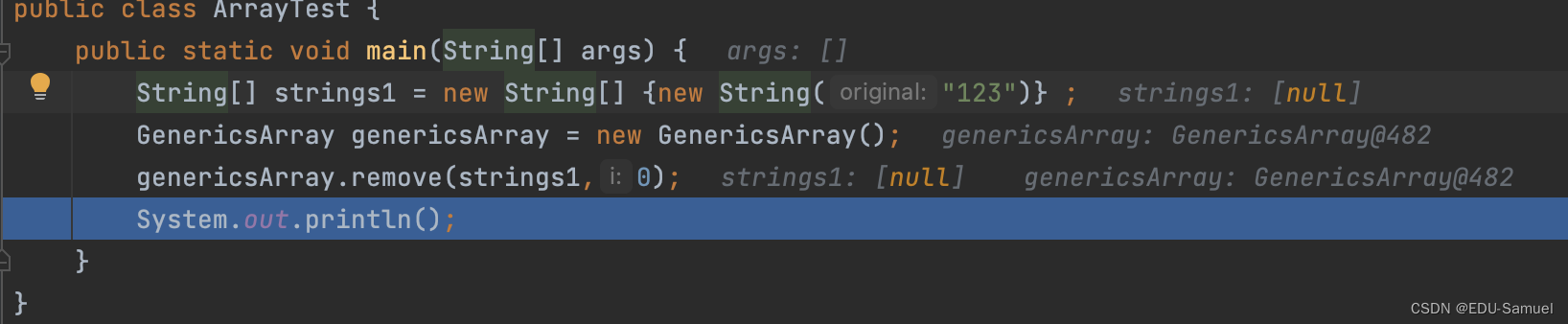
然后我们调试测试它,并且注意我的断点位置:
而后我们将它执行到最后的位置,可以发现数组中的值已经被设定为了null,

泛型的语法
remove函数这样的操作其实可以适用于任何类型的数组的。那么此时此刻我们可以将程序,使用泛型的写法修改为:package Lesson3; public class GenericsArray<T> { public void remove (T[] strings,int i) { strings[i] = null; } }语法中
T是自定义名字的,大小写都可以支持,和变量名一样。但是在实际中通常使用单字母的大写。
然后我们将测试类修改为:package Lesson3; public class ArrayTest { public static void main(String[] args) { String[] strings1 = new String[] {new String("123")} ; GenericsArray<String> genericsArray = new GenericsArray(); genericsArray.remove(strings1,0); System.out.println(); } }
- 在调用时可以在
类声明时在类后追加<类型>来进行明确具体的类型。- 此时这个函数被赋予了可以操作任何类型的能力。
- 在使用时这个类型也是可以不声明的,JAVA能够自动识别。
- 但是如果某些操作完成后需要返回值时,需要多一步强制转换,此时我们添加一个get方法,用于返回泛型数组的某个下标的值。
package Lesson3; public class GenericsArray<T> { public void remove (T[] ts,int i) { ts[i] = null; } public T get (T[] ts,int i) { return ts[i]; } }
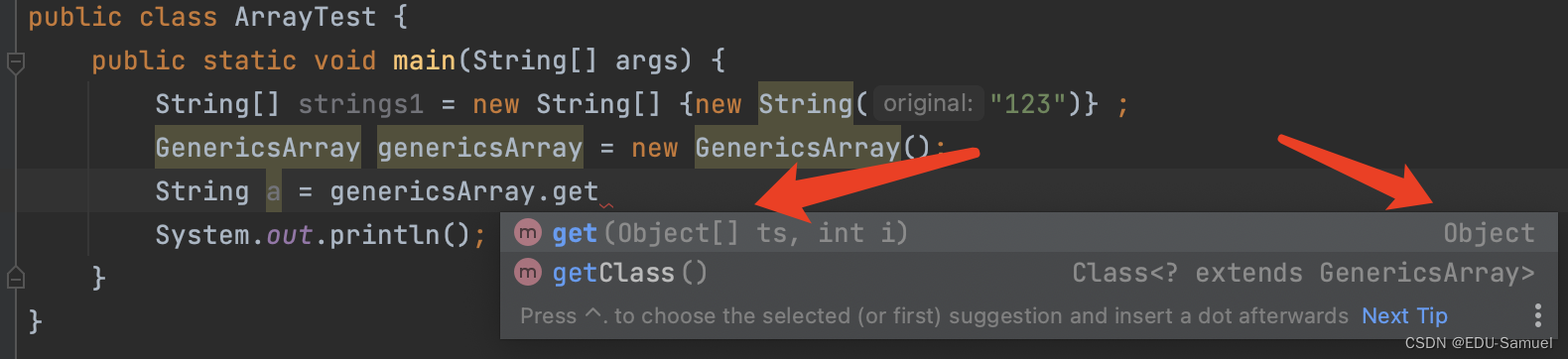
- 此时我们在调用如果不声明泛型类型时,
get函数时需要通过(String)来强制转换package Lesson3; public class ArrayTest { public static void main(String[] args) { String[] strings1 = new String[] {new String("123")} ; GenericsArray genericsArray = new GenericsArray(); String a = (String) genericsArray.get(strings1,0); System.out.println(); } }
- 通过写代码时idea给的提示我们就可以发现,此时它是一个
Object类型,虽然你明白你传入的是什么类型,但是java是无法解释的。所以此时需要强制转换成你输入进去的对的类型。

Object类型
Object类位于java.lang包下,是所有java类的父类。前面我们讲继承说到过,继承的部分意义。java默认为所有的类继承了Object类,从而来实现对所有类的默认&基础操作。
同时也就意味着Object可以用于定义任何类,如果只是调用Object类中自带的功能则不需要强制转换。反之如需使用你实例化的确定的某个类型的功能,则需要强制转换后使用。(前面讲过多态),是一样的:
package Lesson3;
public class ObjectTest {
public static void main(String[] args) {
Object o1 = new GenericsArray();
Object o2 = new GenericsClass();
o1.toString();//调用Object自带的toString()函数
((GenericsArray)o1).toString();//调用GenericsArray的toString()函数
}
}
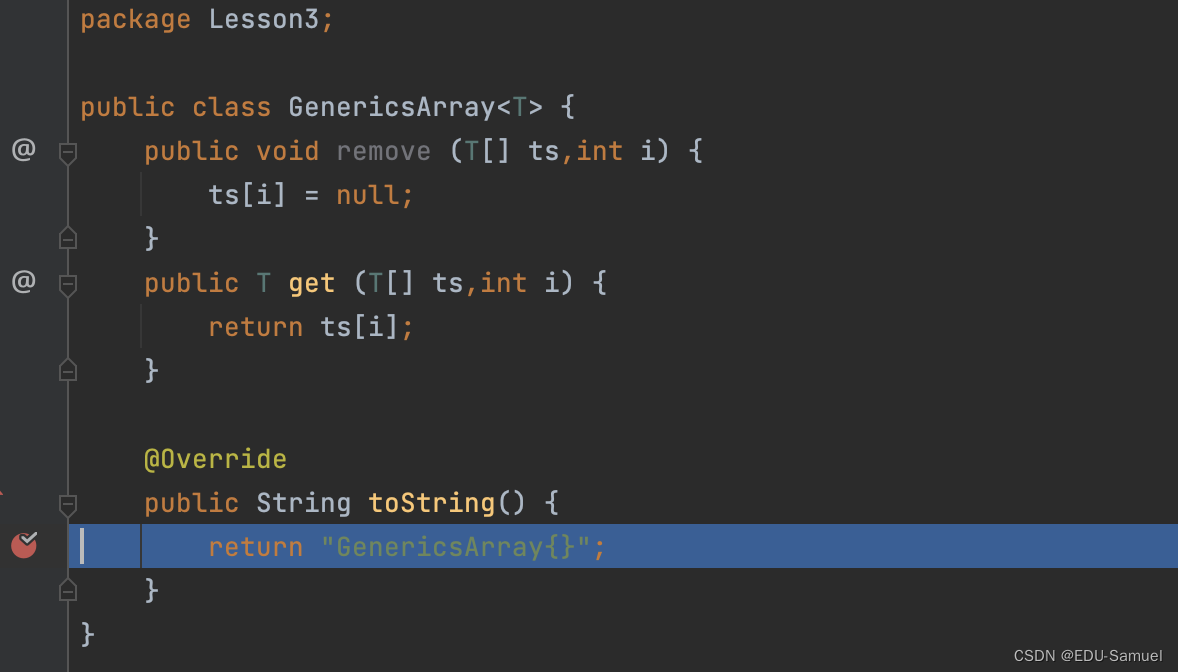
此时通过断点的方式可以发现
((GenericsArray)o1).toString();时调用的是GenericsArray的toString()函数
类型的强制转换
((GenericsArray)o1).toString();的解释:使用()将(GenericsArray)o1的结果包起来,语义是使用强制转换后的对象实例来调用toString()函数。
可以想象一下加减乘除的计算,如果需要使用+后之后在做乘法计算,因为乘法优先,所以需要通过()包起来。
而代码String a = (String) genericsArray.get(strings1,0);里和((GenericsArray)o1).toString();的区别是
前者是向前做赋值的值转换,genericsArray.get(strings1,0);的结果再转换。
后者是需要向后继续调用,((GenericsArray)o1)将具体实例转换后调用转换后的实例方法函数。
集合
集合与数组的意义是一样的,只不过数组是最基础(不是最简单而是最根基)。数组是集合的根基,集合是功能更强大的数组。底层就是通过数组来实现的。但是目前为止我们还不能讲底层。
数组是不可变的,固定长度的。集合就是将数组动态化,也就是实现了可动态化伸缩的,更多丰富的使用方法的。
ArrayList
语法:ArrayList<String> list = new ArrayList<>();,它是一个类,位于java.util包下。换句话来说,如果你想,也可以自己实现并加强它的功能。
package Lesson3;
import java.util.ArrayList;
public class ListTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
System.out.println(list.get(0));
list.remove("a");
list.remove(0);
}
}
代码中:
-
声明了一个泛型是
String类型的ArrayList类,并且我们不需要指定它的长度。当然也是可以指定初始长度的。 -
而后
ArrayList通过无参构造函数new ArrayList()中的定义,来初始化了一个空数组。 -
通过调用
list.add("a")这个函数往该ArrayList对象中的内置的数组变量中,往里面添加了一个字符串"a"; -
list.get(0)通过ArrayList类中的get函数入参下标访问了内置的数组变量中下标为0的值,也就是"a"。(此时字符串a下标为0,字符串b为1); -
也就是说往集合里添加值时,它默认把
新的值追加到尾部 长度和下标都+1。 -
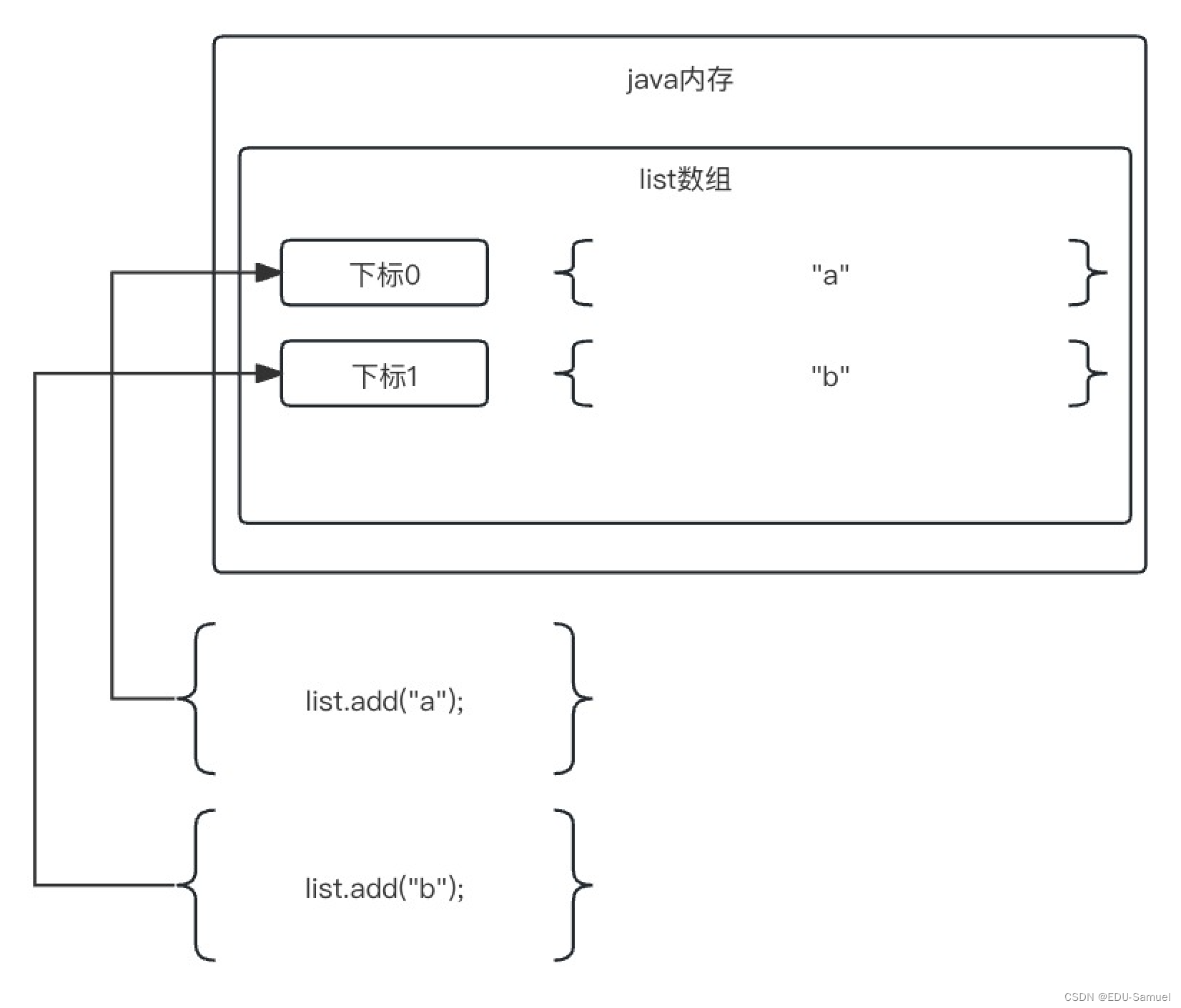
-
往集合里通过
remove删除值值时,它删除你指定值后从当前位置后的值都往前挪然后长度和下标都-1。以确保数组中的下标是连续的。 -
以下图示可以自行代码调试。

循环访问:
- 代码中通过
list.size()的内置方法获取了当前list的长度。 - 通过
list.get(i)的方式访问了数组中每一个下标的字符串元素。
package Lesson3;
import java.util.ArrayList;
public class ListTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
HashMap
键key值value对集合,在使用数组或list的使用中,我们无法通过很直观的方式来访问元素,我们只知道012345的数字下标。如果我们需要实现通过名字就能得到性别的功能。是数组和集合所不能满足的。
与ArrayList集合一样,它也同样支持泛型。但它需要两个泛型<K,V> 对应着 <键,值>。
代码中:
- 通过
put函数新增了一个键值对hashMap.put("周杰伦","男");- 通过
hashMap.get("周杰伦")该方法在代码中真实返回值是"男"。- 通过最后面的
for (String s : strings)示例中我们可以意识到,这种for循环的写法是通过String s在代码块中声明一个用于接收的变量,通过:指向了String[]类型的strings数组对象。- 再回头来看
for (String s : hashMap.keySet())和String v : hashMap.values()你就可以知道,hashMap.keySet()与hashMap.values()都是返回的数组类型。hashMap.keySet()返回的是所有键组成的数组"周杰伦","蔡依林"hashMap.values()返回的是所有值组成的数组"男","女"- 同时也证明了,目前可以简单的理解为HashMap底层通过多层数组来实现了
键值对集合的功能。
package Lesson3;
import java.util.HashMap;
public class HashMapTest {
public static void main(String[] args) {
HashMap<String,String> hashMap = new HashMap<>();
hashMap.put("周杰伦","男");
hashMap.put("蔡依林","女");
System.out.println(hashMap.get("周杰伦"));
//遍历所有key 并且同时遍历了该key所对应的value
for (String s : hashMap.keySet()) {
System.out.println(s);
//可以用key来访问value
System.out.println(hashMap.get(s));
}
//无法通过value来访问key,只能直接遍历所有value
for (String v : hashMap.values()) {
System.out.println(v);
}
String[] strings = new String[]{"解释for循环的另外一种使用"};
for (String s : strings) {
System.out.println(s);
}
}
}
高并发基础
通过对ArrayList HashMap这样的"可一直自动增大"数组的了解,我们应当意识到一个问题,在现实的情况中所面对的绝对不是:某个变量、或者某几个少量的数组而已。
之所以把它设计为可变长度大小的,证明现实情况中大多数我们需要处理的数据是不确定量的。所以我们需要灵活的判断,小数据量与大数据量合适的方案。如果你打算从事java这一领域,或者至少深挖学习这个领域。这两个问题将永远环绕你。
CPU 的核
它是CPU中的可并行计算的数量。你在使用电脑的过程中,你可以启动很多个应用程序比如9个,但是你得CPU只有8核。它们其实并没有真正的并行。它们是交替执行。
CPU是通过总线来控制并交替执行的。也就是说它们都被分配了不同的时间片。从而达到均衡的执行效果。比如你打游戏卡顿了但是又马上恢复了。就是你当前的这个进程暂时丧失了CPU的使用权,使用权被交替出去了。所以在玩游戏的时候就算你得CPU再牛逼也尽量少开一些软件的道理在这里。
进程与线程
CPU中的核就是针对进程来说的。进程与进程之间独立的交替的使用内核。你也可以理解为它是一个独立程序的概念。
主要概念
进程主要概念:
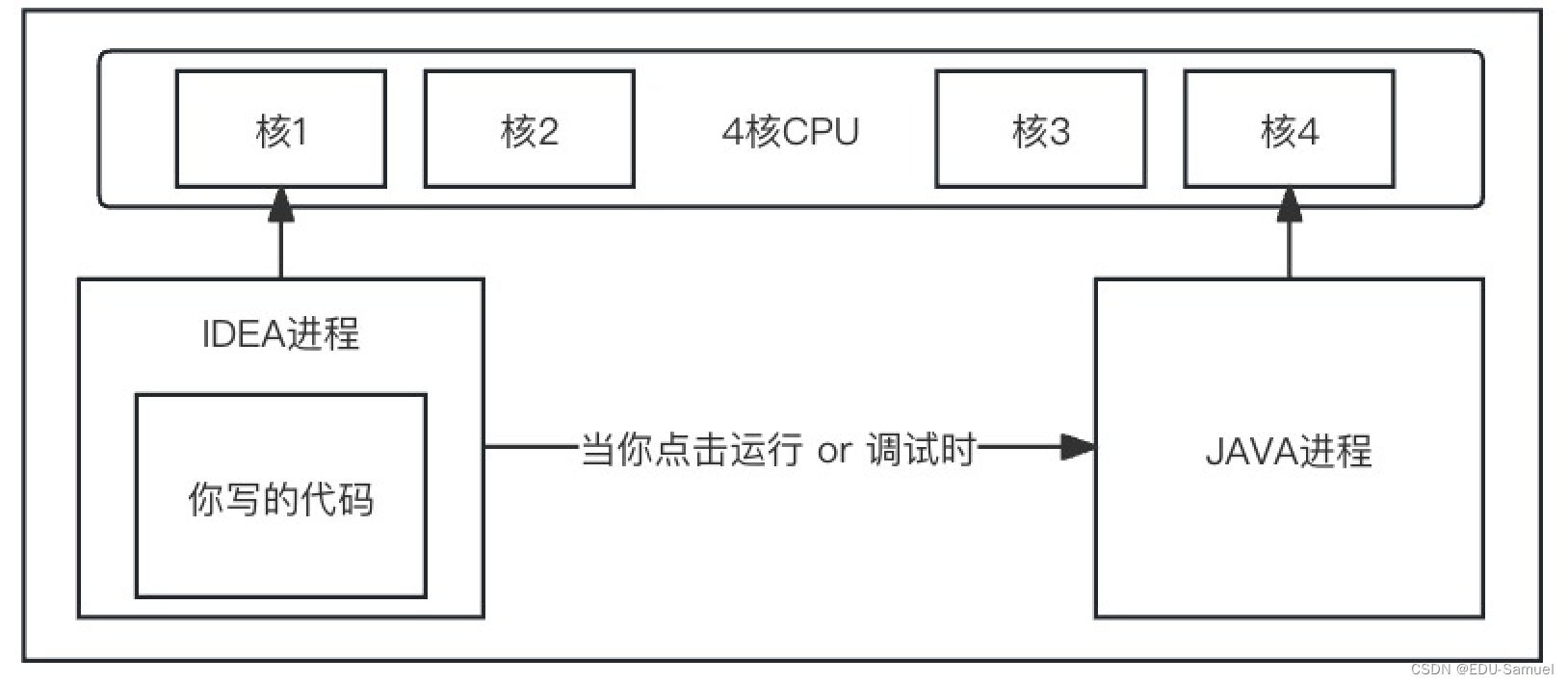
- 以IDEA工具为例,IDEA独立的运行在一个核上。
- 当你运行写的代码实际上并不是在IDEA中运行,而是启动了一个JAVA进程。这个JAVA进程和IDEA进程分别
拥有独立的空间,CPU的时间片切换也是以进程为维度。- IDEA中的调试等功能,则是在IDEA进程资源范围内中完成。
- JAVA进程同理。
- 它们之间的运行互不干扰。
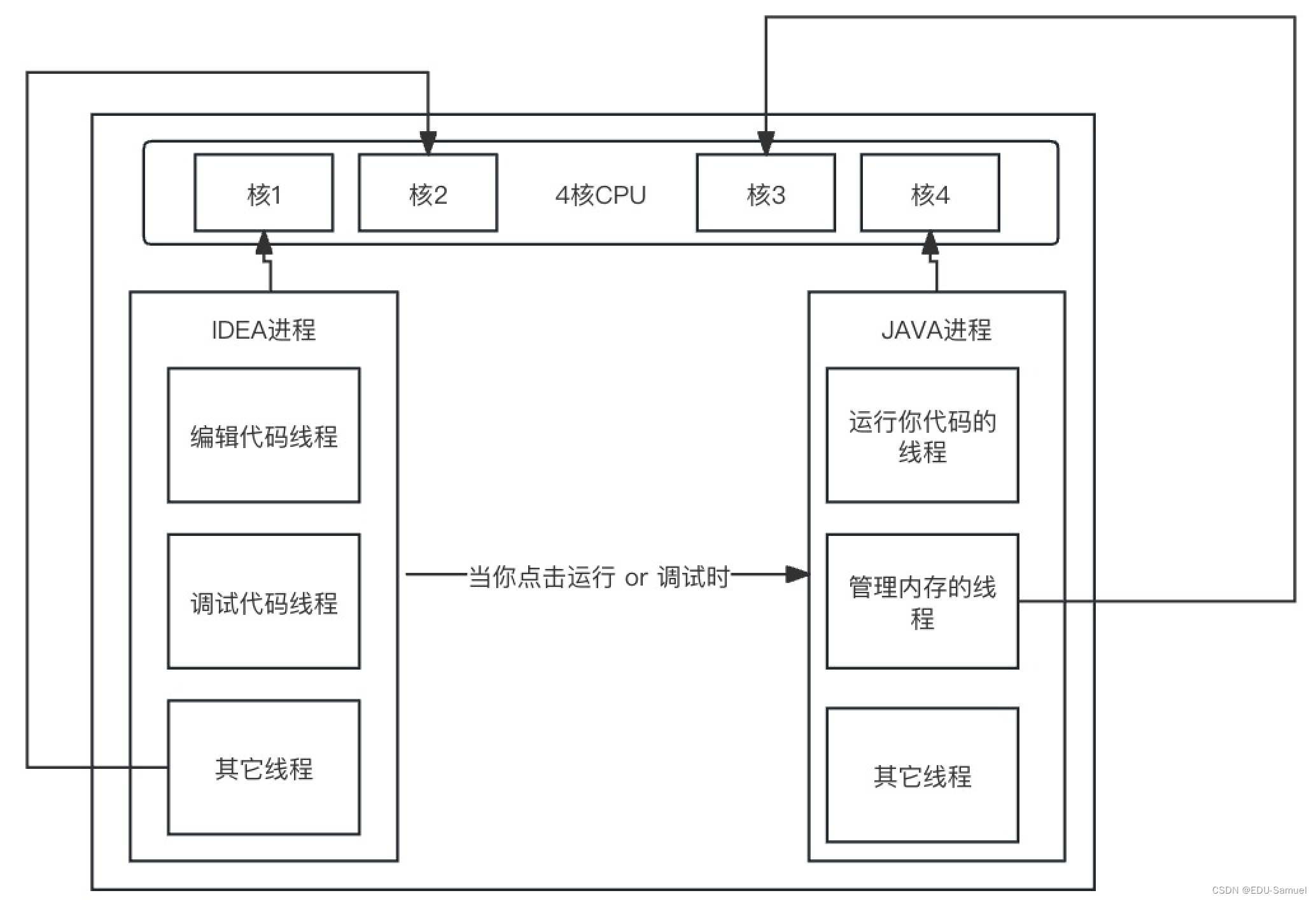
线程主要概念与和进程的区别:
- 线程与线程之间
共享进程的资源,比如申请的内存。- CPU
切换时间片是以进程为单位。也就是说只有一个核时,IDEA分到了时间片则IDEA进程中的所有线程可以执行。此时JAVA中所有线程休眠。- 如果IDEA进程分到了
cpu时间片则IDEA中的多线程(不同线程使用不同核直到时间片完为止)使用多核CPU,反之JAVA同理。
进程和线程的区别与意义
- 进程是基础单位,它和线程本质上没有区别。
但是区别的意义是为了从CPU的角度更好的管理多进程并发或并行。 - 切换线程而后又恢复执行需要
保存状态。CPU切换时间片时是以进程为维度来保存进程的执行状态。 - 进程是接近CPU的概念,但是我们是java高级语言,我们无法针对CPU进行开发。同时我们又有并行执行的需求。所以在语言设计时加入了
多线程。
并发与并行
- 前者更注重
交替运行的能力,也就是说CPU发现有多个任务需要交替执行。当只有单核CPU的时候,CPU就需要提前做交替运行的准备。 - 后者注重的是
一起执行,并行。也就是说单核CPU是没有办法达到进程之间的并行的。 - 当进程CPU有8个核,IDEA进程和JAVA进程分别有4个线程来
并发,由于CPU的数量和他们线程数量一致,那么它们可以同时分配到时间片从而达到并行。
Java中的线程
java是高级语言,无法直面CPU来新建一个线程。所以java为我们封装了底层的新建线程的方法。
单线程的使用
新建一个类,继承Thread类,重写run方法,示例化一个Thread对象,并且示例化一个继承并重写了Thread类的run()函数的类的示例作为构造函数的参数输入进去,此时这个线程已经被新建。还需要调用thread.start()来执行。
package Lesson3;
public class ThreadTest extends Thread {
@Override
public void run() {
System.out.println("输出完这句话线程就结束了");
}
public static void main(String[] args) {
Thread thread = new Thread(new ThreadTest());
thread.start();
}
}
上例中,我们通过继承Thread并重写run函数,定义了这个线程需要执行的内容。new Thread()是新建一个线程,而new ThreadTest()只是为了定义我们要执行的内容。
继承的内容我们说过,要想动态的执行运行时的代码需要通过继承的多态。这也就是ThreadTest extends Thread的意义。Thread内部通过继承多态的特性,来知道你要执行的真正内容。
多线程不停地执行
我们模拟一个线程与main函数不停的执行某个内容:
package Lesson3;
public class ThreadTest extends Thread {
@Override
public void run() {
for (;;) {
System.out.println("分支线程");
}
}
public static void main(String[] args) {
Thread thread = new Thread(new ThreadTest());
thread.start();
for (;;) {
System.out.println("主程序线程");
}
}
}
这个程序你会发现它正在交替着运行。因为
主程序线程和支线程都在反复的、不停地、交替着循环着(它们并不是你一次我一次,也就是上面所提到的时间片)。前面也提到过往往这种情况才更符合实际运用场景。
多线程间隔的执行
这里我们分别新建两个类都继承Thread并重写run方法。也就是两种实现。并在ThreadTest中实例化它们并调用:
- 在程序中,我使用了
Thread.sleep(1000);,调用此方法的含义是睡眠1000毫秒之后再执行。 try { } catch (InterruptedException e) { }是异常捕捉,try {}代码块中的内容包含着可能会发生异常的代码。catch (InterruptedException e) { 此代码块中编写你希望发生问题后如何处理 },java中Throwable类是所有异常类的父类,它有两个子类分别代表着1、Error(程序无法处理的错误),2、Exception(可处理的异常)。这里定义的InterruptedException e变量就是Exception的子类(也就是可以使用Exception e接收一切Exception)。- 说处理了这个
可处理的异常后,程序是可以继续执行的。但是Error发生时通常程序就崩溃了。 e.printStackTrace();是程序发生错误的Stack栈的Trace追踪信息。也就是程序发生错误的位置的前后信息。调用后会打印到命令行。
package Lesson3;
public class Thread1 extends Thread{
@Override
public void run() {
for (;;) {
System.out.println("Thread1在说话");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package Lesson3;
public class Thread2 extends Thread {
@Override
public void run () {
for (;;) {
System.out.println("Thread2在说话");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package Lesson3;
public class ThreadTest {
public static void main(String[] args) {
Thread thread1 = new Thread(new Thread1());
Thread thread2 = new Thread(new Thread2());
thread1.start();
thread2.start();
}
}
这个代码运行的结果需要小心,它的打印信息会一定程度的迷惑你,让你感觉它们正在交替的执行。但是在你多观察一会之后你会发现:
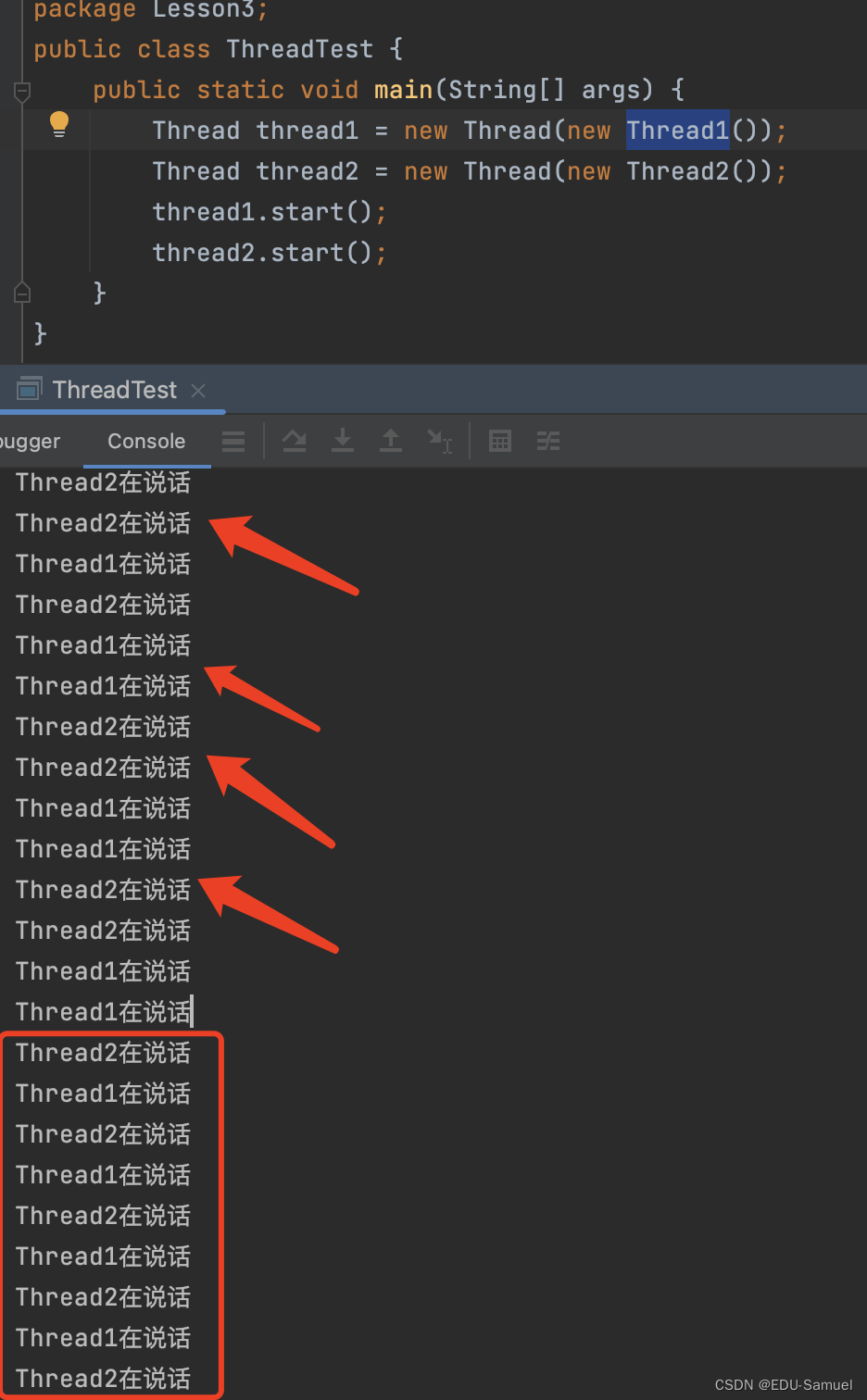
多线程同时操作一个变量
- 线程之间共享在一个进程的内存空间中,所以它们之间可以进行变量共享。
- 在多个类之间实现共享变量需要使用
引用类型(对象) - 共享相同对象,如果针对两个不同的对象它们的
内存地址是不同的。
//共享对象
package Lesson3;
public class ThreadShare {
public int i = 0;
}
//通过构造函数将 同一个对象实例threadShare 传递到Thread1
package Lesson3;
public class Thread1 extends Thread{
ThreadShare threadShare;
public Thread1 (ThreadShare threadShare) {
this.threadShare = threadShare;
}
@Override
public void run() {
for (int j = 0; j < 100000 ; j++ ) {
threadShare.i = threadShare.i + 1;
System.out.println("Thread1的threadShare.i="+threadShare.i);
}
}
}
//通过构造函数将 同一个对象实例threadShare 传递到Thread2
package Lesson3;
public class Thread2 extends Thread {
ThreadShare threadShare;
public Thread2 (ThreadShare threadShare) {
this.threadShare = threadShare;
}
@Override
public void run () {
for (int j = 0; j < 100000 ; j++ ) {
threadShare.i = threadShare.i + 1;
System.out.println("Thread2的threadShare.i="+threadShare.i);
}
}
}
//新建一个共享变量threadShare,并且通过Thread1,Thread2的构造函数输入
package Lesson3;
public class ThreadTest {
public static void main(String[] args) {
ThreadShare threadShare = new ThreadShare();
Thread thread1 = new Thread(new Thread1(threadShare));
Thread thread2 = new Thread(new Thread2(threadShare));
thread1.start();
thread2.start();
}
}
注意分别观察执行结果的:
- 单个线程持续输出的值
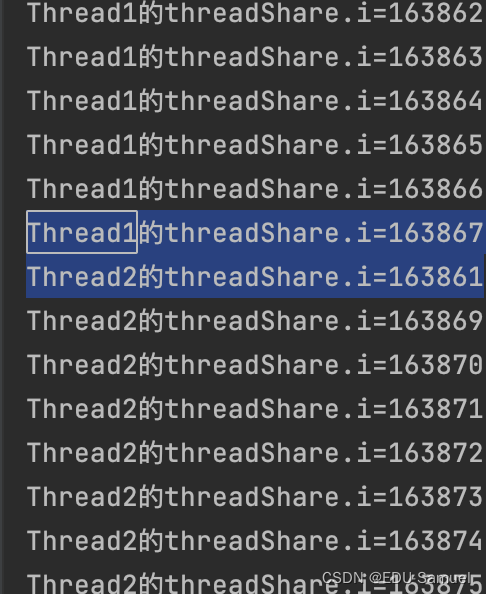
- 两个线程输出的交接之间:
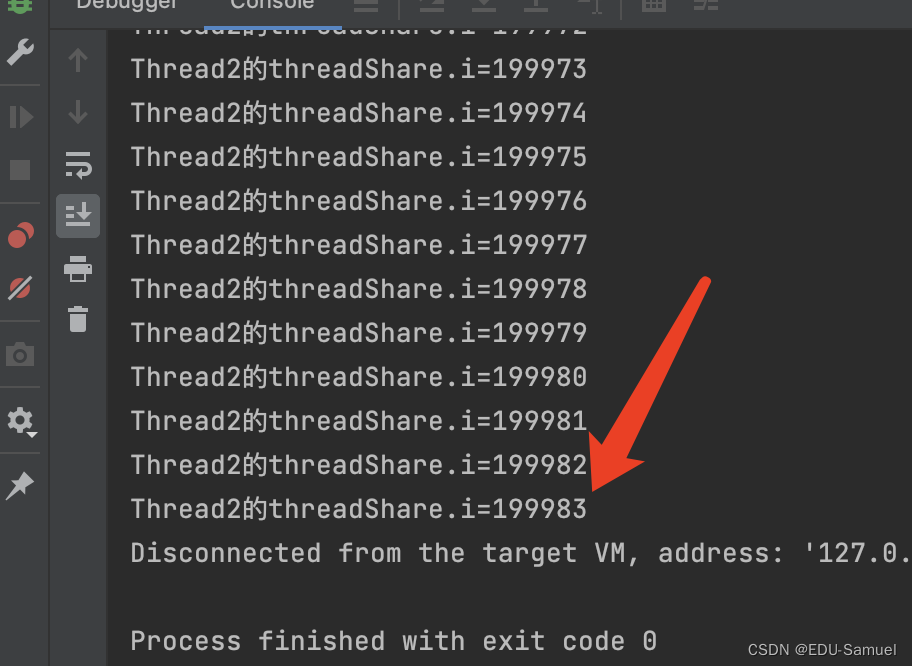
- 最终的结果(可以试着多执行几次,可以发现它们的执行每次都不同)
以上的输出结果有三个点证明了:线程与线程之间虽然存在于同一进程内存空间,线程之间可以共享变量,但是也同时意味着,它们需要考虑线程安全。
- Thread1的输出之所以
有时能连续,体现的是Thread2在那段时间没有获得执行时间片,- Thread1
163867与Thread2163861交界处。线程如果真正的并行时,它们拿到的那个值并不是最新的。也就是Tread已经加到了163867,Thread2拿到的仍然还是163861。- 最终的执行结果并不是每次都是200000。一定是小于等于200000的,如果你的计算机空闲的CPU核越多,这个值也就离200000越远。
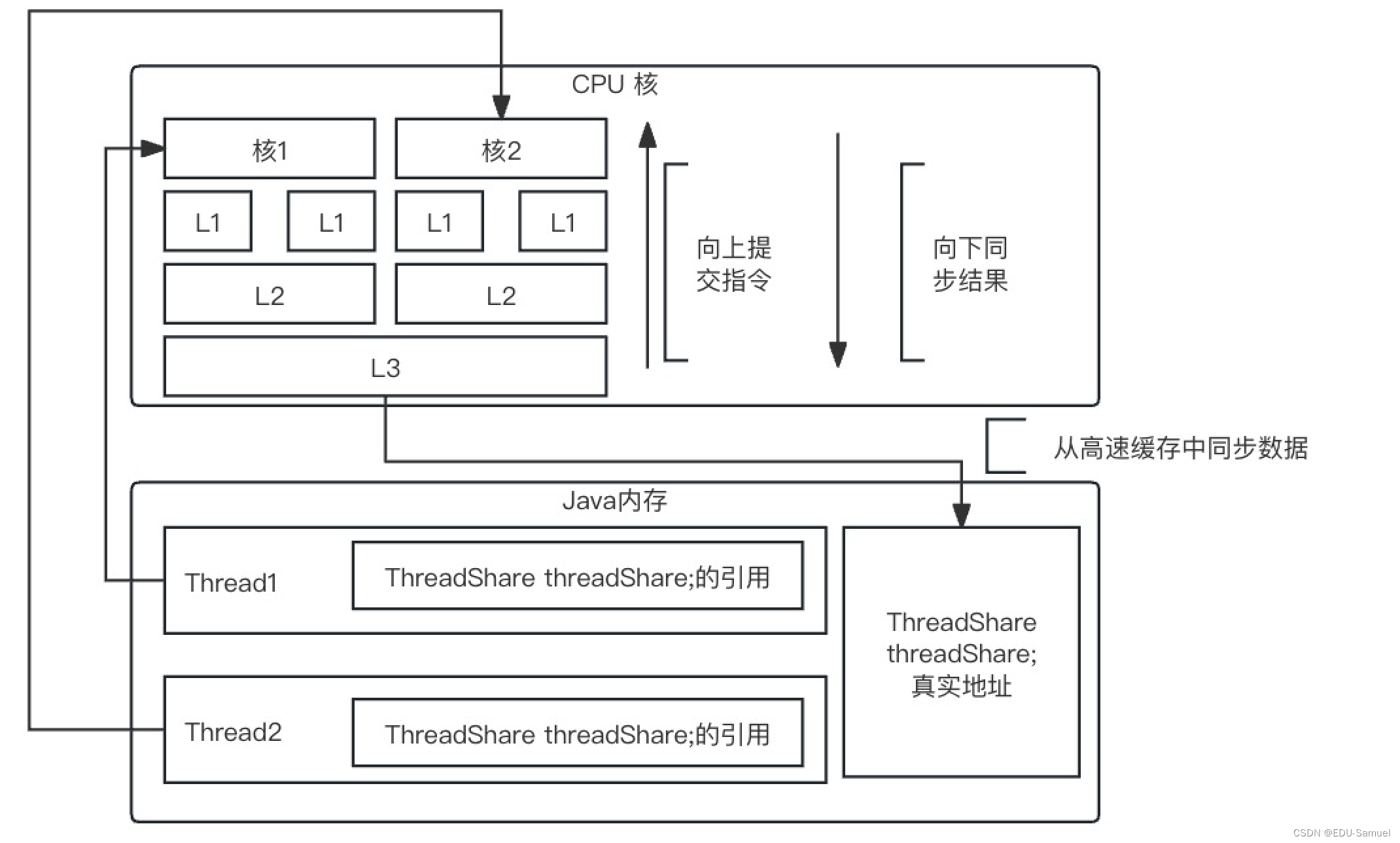
我们通过图例来了解整个过程:
- Thread在不同核上针对相同的变量操作时,CPU并不是直接操作你的内存地址空间。而是操作属于它的
真正的高速缓存,并且这个缓存要比你常见内存条贵的多。氛围三层L1,L2,L3,越接近CPU的缓存越小,越贵。在L3级缓存所有核的共享数据,在L2级拿到自己核需要处理的数据,在L1核把指令与数据区分后处理。- 也就是说所有CPU核会有一个共享空间,操作完成之后才同步到属于你得内存空间。
- 此时它们即使是交替的在运行,它们很有可能拿到的
数据副本是不一样的。- 而如果他们拿到的
数据副本是一致的,但是他们同时又面临共同修改一个结果的冲突。
所以,在线程与线程之间的
安全问题上要考虑的关键问题:
- JAVA要保证线程拿到的变量副本是最新的。
- CPU要保证它们的改动是顺序执行的(排队)
锁
计算机通过计算机总线来调和CPU,内存,磁盘,外设之间的沟通交流。它提供了缓存一致性协议MESI来保证你获取到的变量副本是最新的。
而线程与线程之间的在修改同一变量的交替运行,则需要在程序中实现。
在上面的示例程序中,我们需要找到它交替的点,也就是操作
threadShare.i的点。对它来进行线程并行执行的交替执行转换。
我们做几个修改:
ThreadShare修改为右方
Thread1修改为右方Thread2修改为右方ThreadTest无需修改



现在如果你反复的执行,它们的结果就会一致了而且没有错误
上面的修改中通过synchronized关键字实现了刚才提出的两点。
第一、java中的synchronized关键字帮我们完成了多线程之间的交替运行。
第二、synchronized隐式的实现了缓存一致性协议MESI,在该代码块中使用的变量在执行时获取到的就是最新的副本。PS:这也是为什么get方法也要添加synchronized关键字。
多线程的思考!
刚在我们在get方法中也加入了
synchronized关键字,而这个关键字帮助我们完成了两件事情:
- 线程交替运行
- 获取到最新的副本
我们的程序如果十个线程执行一千万次,其中只有几十次在修改数据,其它都是在读数据。也就是说只有那么几十次需要使用到
交替执行的功能,其它的只需要获取到最新的变量即可。所以除了那几十次之外,根本就没有必要交替的执行,因为不修改数据。就会造成很大程度上的浪费。
但是由于目前还是很基础的阶段,了解并清楚基础的问题即可,感兴趣可以自己先研究起来,懒的话就跟着我一步步来就好。
封装的进一步补充 public private
上面修改ThreadShare后的最终例子中,进一步的体验了封装的意义:
- 它的意义是我们在有些时候并不希望程序直接的访问类的变量
get和set方法是所有框架和开源社区都默认的封装变量方法。未来在框架的学习会大量使用到。- set就是设定值通过传参并且限制操作变量的操作,比如上述的加入了
synchronized。 - get就是限制或进一步处理当前变量并返回。
- 命名方法就是将变量名
骆驼峰命名并且将首字母大写追加到get,set之后比如getThreadShare() setThreadShare(ThreadShare hreadShare)
线程池
应用场景
前面提到过,真实的场景的确需要多线程的去执行,但是多到什么程度,也就是具体有多少个线程。
- 每次新建线程都需要花费一定的代价,需要思考怎么去管理它们。
- 管理时,需要动态的扩容和缩容这个池,在需要的时候达到最大化支持,在空闲的时候释放它们。
- 当任务饱和时,超过了能并行处理的任务数,如何处理(排队?)。
- 排队也是有上线的(你的计算机内存是有限的)。到达那个上限怎么处理?
参数说明
到目前为止,咱们在使用一个
类的时候,应该学会去看它的构造函数了(这也是学会看代码源码的第一步),比如我们先把new这个类的代码语法写出来,然后control 或则 command(mac),在这个界面可以看到大概需要的参数如:
如果我们进一步点进去:
简介部分,创建一个新的ThreadPoolExecutor对象,并给定初始值与默认的factory参数以及默认的handler方法。使用Executors工厂类创建可能更为方便(PS:但是这个类有BUG)。

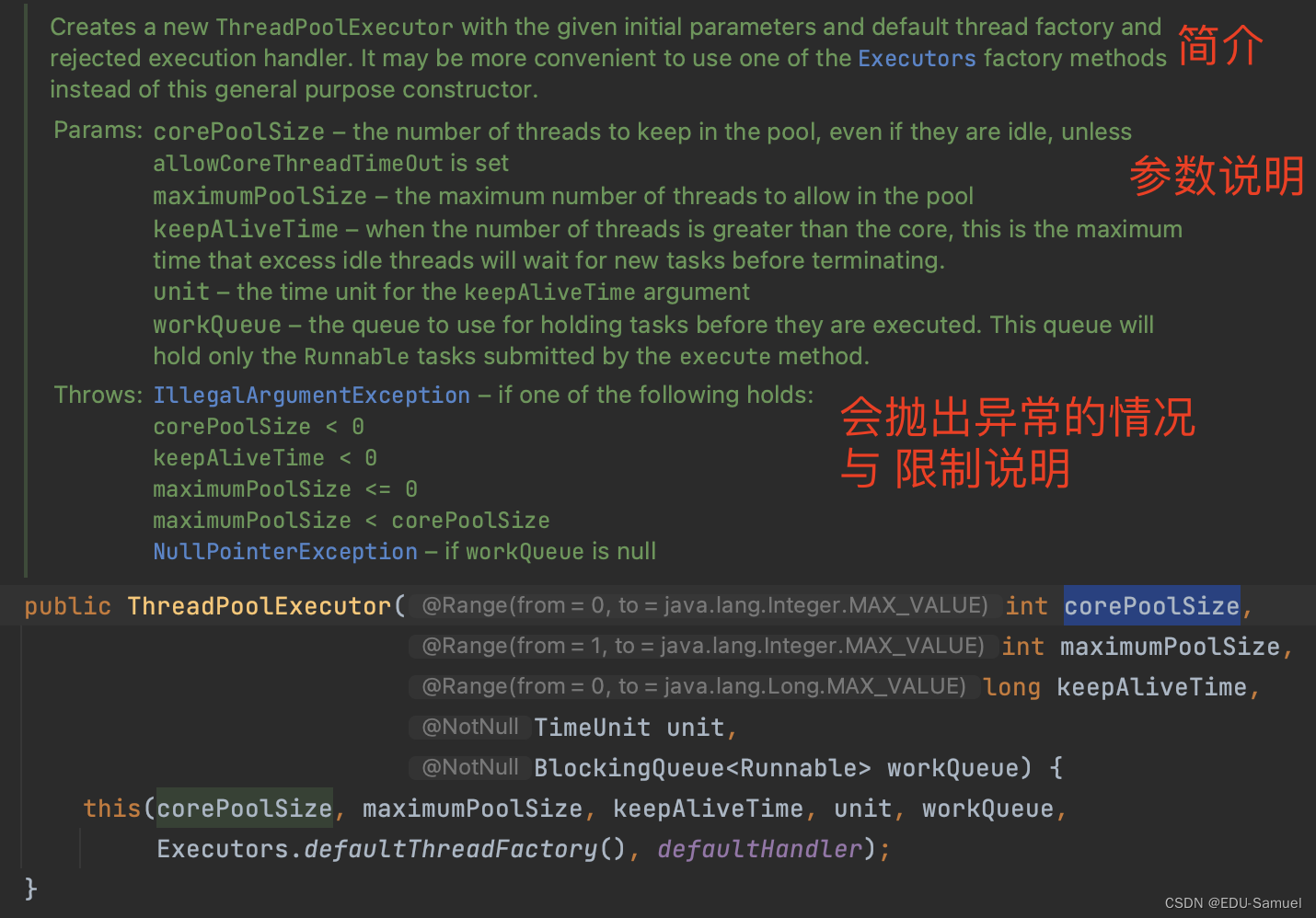
参数说明:
- corePoolSize:设定核心线程数的数量而且这些线程将一直保持在池中,即使他们是闲置的,除非设定了allowCoreThreadTimeOut(允许 核心 线程 闲置)这个参数。
- maximumPoolSize:线程池中允许的最大线程数。
- keepAliveTime:当线程数超过了核心线程数的数量,将以这个变量为线程空闲终止的最大等待时间。
- unit:设定keepAliveTime数值的单位
- workQueue:在任务执行之前将会首先保存在这个任务队列之中。
今天的内容只解读到这里,是我们的核心内容。
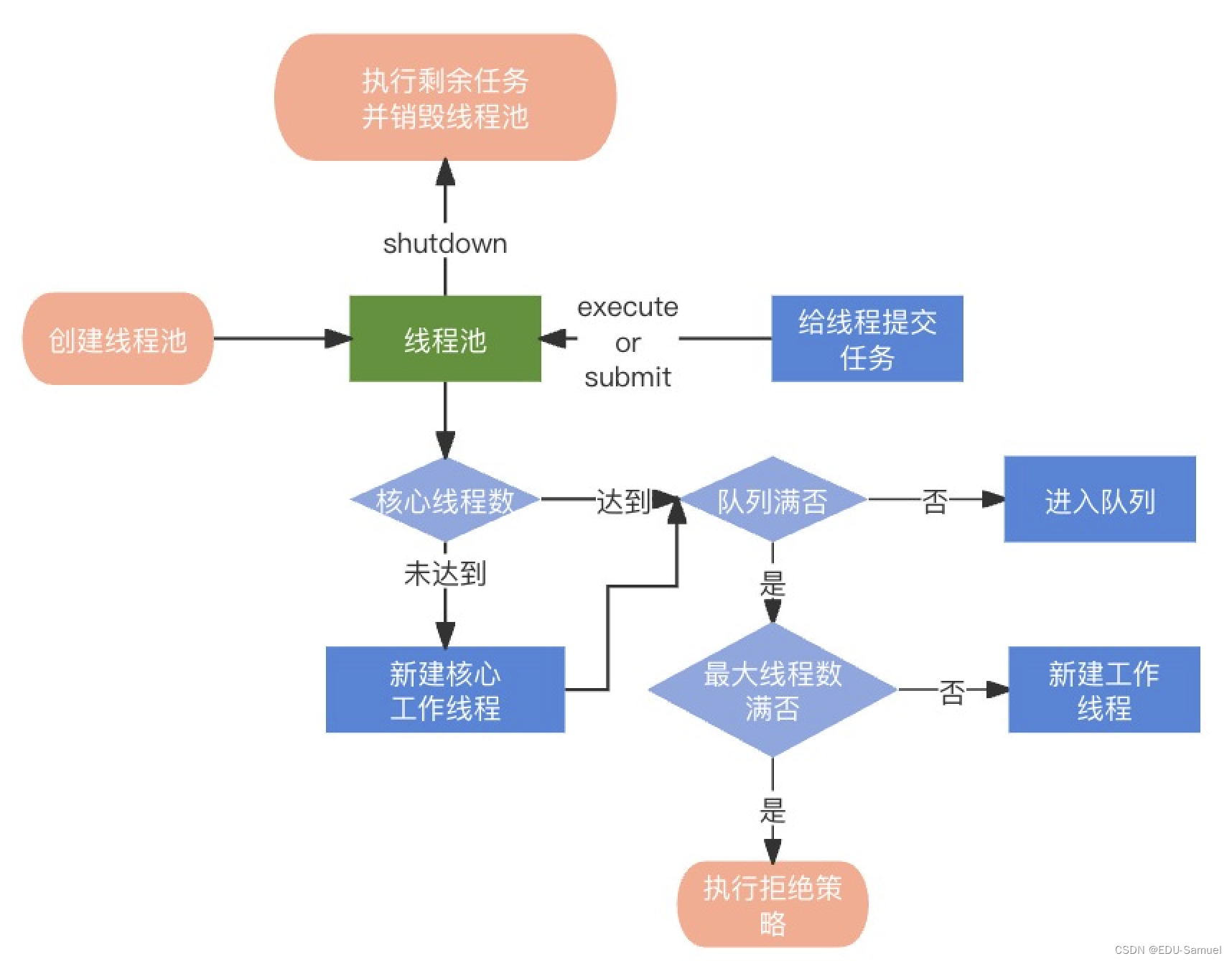
流程演示
流程图示例:
上代码
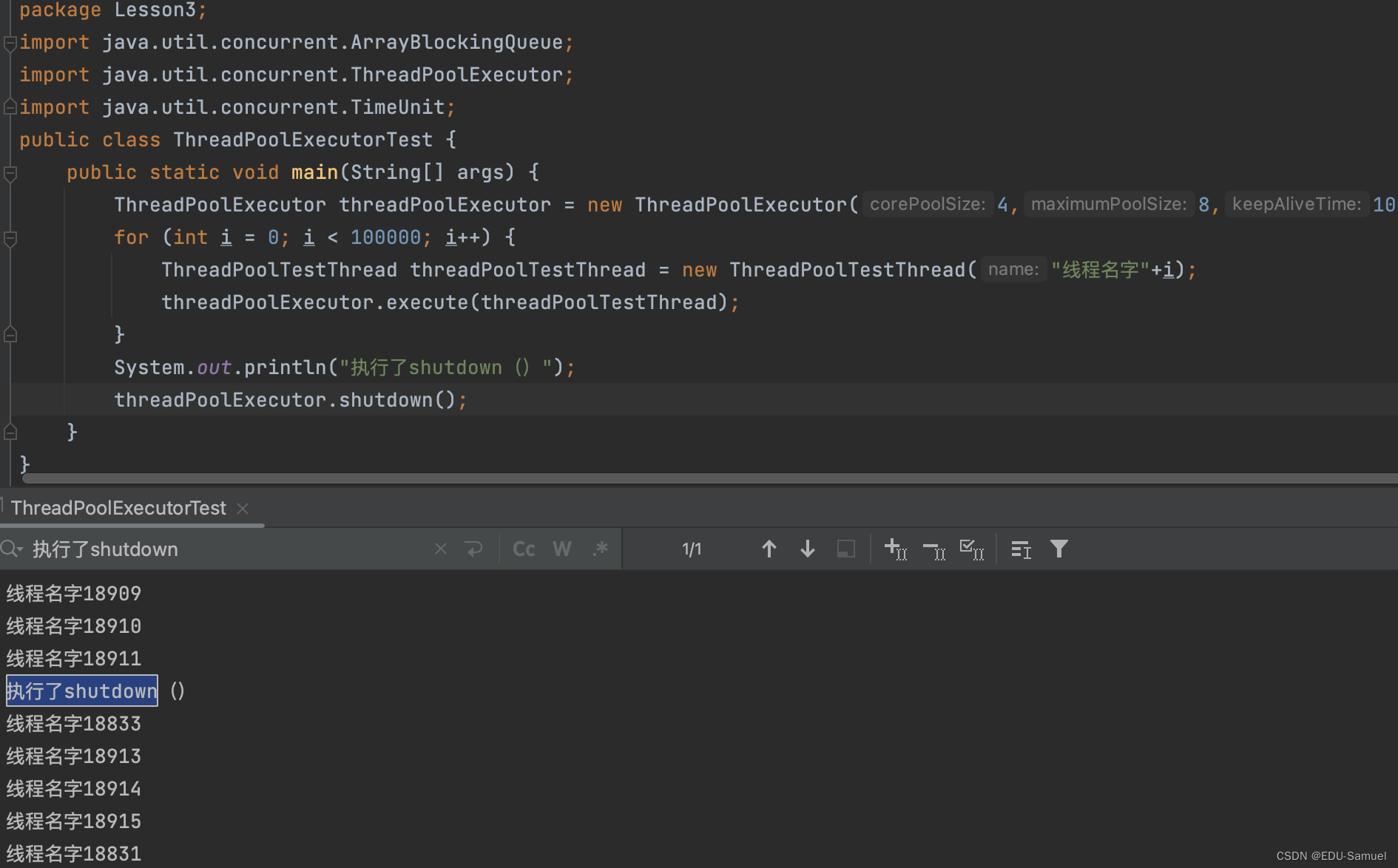
代码示例:
- 在代码中新建了
ThreadPoolTestThread类,并且输入一个name标识它的不同。 - 通过
new ThreadPoolExecutor(4,8,1000, TimeUnit.MILLISECONDS,new ArrayBlockingQueue<>(1000000));新建了一个核心线程数为:4,最大线程数为:8,设定了闲置时间的单位为TimeUnit.MILLISECONDS毫秒,所以这里是1000毫秒,也就是一秒。设定了长度为1000000的队列。 - 通过循环的方式为线程池添加了100000个线程任务。
package Lesson3;
public class ThreadPoolTestThread extends Thread{
private String name ;
public ThreadPoolTestThread(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(name);
}
}
package Lesson3;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(4,8,1000, TimeUnit.MILLISECONDS,new ArrayBlockingQueue<>(1000000));
for (int i = 0; i < 100000; i++) {
ThreadPoolTestThread threadPoolTestThread = new ThreadPoolTestThread("线程名字"+i);
threadPoolExecutor.execute(threadPoolTestThread);
}
System.out.println("执行了shutdown()");
threadPoolExecutor.shutdown();
}
}
值得注意的是:threadPoolExecutor.shutdown();,它在执行了shutdown之后仍然继续执行完成了任务。
线程池的意义:
- 反复的新建线程将造成很多不必要的浪费。
尽管我们这里演示的是ThreadPoolTestThread threadPoolTestThread = new ThreadPoolTestThread("线程名字"+i);新建了很多线程然后提交到线程池任务中,这里是错误的演示,线程的实现方法还可以通过接口的方式。只不过我打算放到设计模式时才讲。- 大多数时候我们并不需要非常多的线程来完成任务,需要恒定的几个就好了,因为前面说过,只有那几个CPU核心线程多了也无益。
- 更好的保障了我们在任务处理中对数据的安全处理
消息队列,拒绝策略。
什么时候应当设定超过CPU核心的线程数
在使用线程有两个很重要的场景:
- 计算型:它将一直占用CPU的算力
- 操作型:比如操作文件,前面提到过
系统总线,也就是说当你调用磁盘时,此时你的总线将操作发送到了磁盘并不是CPU。所以并不占用算力。这个时候可以超过CPU的核心线程数去设定线程池。
并发包
全部都是线程安全的类的java.util.concurrent包。在这个包中,提供了一系列帮助我们完成线程并发安全场景的类:
以ConcurrentHashMap为例,它和我们之前学过的HashMap在使用上没有区别,但在多线程共享它的时候,它已经帮我们完成或实现了线程安全的操作。
package Lesson3;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest {
public static void main(String[] args) {
ConcurrentHashMap<String,String> concurrentHashMap = new ConcurrentHashMap();
concurrentHashMap.put("周杰伦","男");
concurrentHashMap.get("周杰伦");
for (String s : concurrentHashMap.keySet()) {
System.out.println(s);
}
}
}
队列
今天我们只讲这个包下的ArrayBlockingQueue,它在线程池的内容中出现过,也是未来在高并发领域中最常见的模式。
- 它底层也是用数组来实现的。
- 我们在使用线程池中也给它设定了初始大小。是不可变的。也就是有上限的。线程池在使用它做队列时就需要做拒绝策略。当然也可以选择无界队列
LinkedBlockingQueue但是在实际场景中绝对不允许这么做。 - 它是线程安全的。
使用场景
- 生产(用户a) -> 数据 -> 消费(用户b),请求的人(用户a)并不关心你怎么处理,并且希望丢到数据缓冲区就直接返回了。处理的人(用户b)并不需要关心谁会来什么时候来,有数据就处理就对了。
- 希望先进来的数据先处理,排队场景总是先来的先处理。
- 但是计算机的内存都是有限的,所以需要有界限的队列。(不像买奶茶你排多少都可以)
- 线程在没有数据处理时,需要一直等待数据。你并不知道什么时候数据会过来。
- 当队列满时写入数据,此时你并不希望把数据扔掉,而是等他处理完之后写入。
- 线程安全,你并不希望多线程处理时造成数据的准确性等问题。
代码示例:
在代码中,我已添加了足够多了注释。调试&观察这部分代码将是你得作业之一。
package Lesson3;
import java.util.concurrent.ArrayBlockingQueue;
public class ArrayBlockingQueueTest {
public static void main(String[] args) throws InterruptedException {
// 创建容量为10的ArrayBlockingQueue对象
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
// 向队列添加元素
for (int i = 0; i < 20; i++) {
//插入队尾,如果已满抛出异常。
queue.add(i);
//插入队尾,如果已满返回 false。
queue.offer(i);
//插入队尾,如果已满则阻塞直到可插入。
queue.put(i);
}
// 从队列获取元素
while (!queue.isEmpty()) {
//移除并返回队首元素,如果队列为空则阻塞直到有元素。
int element1 = queue.take();
//移除并返回队首元素,如果队列为空则返回 null。
int element2 = queue.poll();
}
}
}
作业
- 使用多线程&线程池操作
CurrentHashMap,提示:用一部分线程操作写入,一部分操作读取和删除。 - 使用多线程&线程池操作
ArrayBlockingQueue,提示:用一部分线程操作写入,一部分线程操作消费。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









