






分布式事务如何运用首先要知道什么是分布式事务
本地事务和分布式事务的区别
本地事务和分布式事务都是事务管理的一种形式,用于确保数据一致性和完整性,但它们的适用场景和处理方式有显著的区别。
1. 本地事务 (Local Transaction)
本地事务是指在单个数据库或系统内部进行的事务。它仅涉及到单一的数据源,比如单个数据库或一个表。
特点:
- 单一数据源:本地事务仅作用于一个数据库或者一个资源。
- ACID 属性:本地事务遵循传统的ACID(原子性、一致性、隔离性、持久性)属性,保证在事务提交之前,所有操作都能够恢复到一致的状态。
- 操作范围:涉及的数据操作通常是简单的数据库增、删、改等操作。
- 处理机制:事务通常通过数据库管理系统(DBMS)来管理,由数据库本身提供事务支持(例如 MySQL、PostgreSQL 等数据库提供的事务机制)。
举例:
假设你在一个数据库表中插入数据,所有的增删改操作都发生在这个表中,这个事务是本地事务。如果操作成功,则提交,否则会回滚,确保数据的一致性和完整性。
优点:
- 实现简单:事务管理只涉及一个数据库,容易实现。
- 性能较好:因为没有涉及到网络或跨多个系统的协调,性能相对较高。
缺点:
- 只能用于单一的数据源,不能跨多个系统或数据库进行事务管理。
2. 分布式事务 (Distributed Transaction)
分布式事务是指跨多个数据库、服务或系统的事务。在微服务架构或者多数据库环境中,数据和操作可能分布在不同的服务或数据库上,此时需要处理分布式事务。
特点:
- 多个数据源:分布式事务涉及到多个数据源,可能包括不同的数据库、消息队列、缓存等资源。
- 协调机制:由于事务操作跨多个系统,需要使用专门的事务协调机制来确保数据一致性。常见的协调协议包括两阶段提交(2PC)、**三阶段提交(3PC)**等。
- 一致性保证:分布式事务的核心目标是保证多个系统之间的数据一致性,可能需要进行补偿机制和事务回滚。
- 网络开销:由于涉及跨系统的通信,分布式事务往往存在较高的网络延迟和处理开销。
举例:
假设你有一个电商系统,订单服务和库存服务分别使用不同的数据库。在用户下单时,需要在订单数据库中插入一条订单记录,同时在库存数据库中减少相应的商品库存。这时,需要跨数据库的事务管理,确保订单创建和库存扣减都成功或都回滚,这就是分布式事务。
优点:
- 跨系统操作:能够保证在多个服务或数据库之间的数据一致性。
- 灵活性高:适用于微服务架构、多数据库系统等场景。
缺点:
- 复杂性高:需要实现事务的分布式协调,增加了系统的复杂性。
- 性能开销大:涉及网络、多个系统的交互,可能导致较高的性能开销。
- 故障处理复杂:如果一个系统出现故障,恢复机制更为复杂,可能需要进行补偿事务或其他的处理。
3. 本地事务与分布式事务的比较
| 特性 | 本地事务 | 分布式事务 |
|---|---|---|
| 事务范围 | 单一数据源(数据库) | 跨多个数据源或服务 |
| 实现难度 | 简单 | 复杂 |
| 事务管理 | 由单一数据库管理 | 需要分布式协调机制(如 2PC、TCC) |
| 一致性保证 | ACID 保证 | 最终一致性、CAP 定理、分布式一致性 |
| 性能 | 高,受限于单一系统性能 | 较低,涉及多个系统、网络通信 |
| 适用场景 | 单一数据库应用 | 微服务架构、跨系统操作 |
4. 常见的分布式事务解决方案
- 两阶段提交协议(2PC):两阶段提交是最常见的分布式事务解决方案,分为“准备阶段”和“提交阶段”。所有参与者先准备好提交事务,协调者确认后执行提交。
- 三阶段提交协议(3PC):相比 2PC,3PC 增加了一个“预提交”阶段,旨在减少网络延迟和节点故障的影响。
- TCC(Try-Confirm/Cancel):分布式事务的一种补偿机制,适用于需要做补偿的业务场景,尤其在微服务架构中非常流行。
结论:
- 本地事务适用于单一数据库或系统的场景,简单高效,符合 ACID 属性。
- 分布式事务适用于跨多个数据库或服务的场景,虽然实现复杂,性能开销大,但能够保证系统间的数据一致性和完整性。
Seata
Seata(简写为“Seata”)是一个开源的分布式事务解决方案,旨在为微服务架构中的分布式事务提供一致性保证。Seata 提供了一种可靠的方式来管理跨多个服务和数据库的数据一致性,特别是在涉及多个数据库操作、服务调用时,能够保证事务的一致性和可靠性。
Seata 的核心目标是为微服务提供一个简单、易用、可扩展的分布式事务解决方案,避免分布式事务中可能出现的常见问题,如数据不一致、事务丢失等。
Seata 的特点:
- 高效和轻量:
- Seata 设计简洁,性能优良,能够在微服务架构中高效地执行事务,避免不必要的开销。
- 支持多种事务模式:
- Seata 支持两种常见的分布式事务模式:
- AT(Automatic Transaction)模式:自动事务模式,适用于需要数据库支持的场景,Seata 会自动在数据库上创建保存点,进行事务的回滚和提交。
- TCC(Try-Confirm/Cancel)模式:尝试、确认、取消模式,适用于更加复杂的分布式事务场景,尤其是微服务间调用,支持补偿机制。
- SAGA(Long-running Transactions)模式:分布式长事务,适用于长时间运行的事务场景。
- Seata 支持两种常见的分布式事务模式:
- 分布式事务管理:
- Seata 提供了分布式事务的管理功能,通过全局事务协调器(TC,Transaction Coordinator)来管理跨多个微服务和数据库的事务。
- 支持多种数据库:
- Seata 支持多种数据库管理系统(如 MySQL、PostgreSQL 等),以及其他数据库类型的事务管理。
- 与微服务框架的集成:
- Seata 可以与多种主流的微服务框架集成,如 Spring Cloud、Dubbo、Spring Boot 等。它提供了易于集成的 SDK,开发者可以快速将 Seata 集成到现有的微服务架构中。
Seata 的组件
Seata 主要由以下几个组件组成:
- Transaction Coordinator (TC):
- TC 是 Seata 的核心,负责全局事务的协调管理。它接受并处理从不同服务发出的事务请求,协调不同资源的提交和回滚。
- Transaction Manager ™:
- TM 是客户端组件,负责发起全局事务。它会向 TC 注册事务,管理全局事务的开始、提交和回滚。
- Resource Manager (RM):
- RM 负责管理各个资源的事务,如数据库、消息队列等。它协调资源在分布式事务中的提交和回滚,确保资源的一致性。
- Seata Server:
- Seata Server 包含 TC 和 RM,运行在集群模式下,为分布式事务提供高可用性和负载均衡。
Seata 工作流程
- 全局事务发起:
- 客户端应用通过 TM 发起一个全局事务。这个全局事务由 TC 管理,并且每个参与的资源(如数据库或服务)会被标记为该事务的参与者。
- 资源操作:
- 在全局事务内,应用执行操作(如数据库增删改)时,这些操作会由各个 RM 管理,RM 会在数据库中执行操作,并在 Seata 中登记。
- 事务提交/回滚:
- 当所有操作都完成后,TM 会请求 TC 提交或回滚全局事务。TC 会根据各个参与者的状态来决定是否提交或者回滚。如果某个操作失败,TC 会协调回滚,确保数据一致性。
Seata 的优点:
- 简化了分布式事务管理:
- Seata 提供了开箱即用的分布式事务管理功能,开发者不需要重新发明轮子,可以直接使用 Seata 来管理分布式事务。
- 支持多种事务模型:
- 支持 AT、TCC、SAGA 等不同类型的事务模型,适用于不同的业务需求,灵活性较高。
- 与微服务框架的良好集成:
- Seata 与主流的微服务框架(如 Spring Cloud、Dubbo 等)集成良好,可以无缝地集成到现有的微服务架构中。
- 高可用与高性能:
- Seata 通过分布式协调器和资源管理器提供高可用性,并且具备较高的性能,适用于高并发场景。
Seata 的缺点:
- 系统复杂性增加:
- 尽管 Seata 提供了简化的分布式事务管理,但它也引入了额外的组件和依赖,如事务协调器和资源管理器。这些组件可能会增加系统的复杂性。
- 性能开销:
- 虽然 Seata 设计高效,但在一些高并发场景下,分布式事务的协调和网络通信可能会导致性能开销,尤其是在事务复杂度较高时。
总结
Seata 是一个功能强大且灵活的分布式事务解决方案,适用于现代微服务架构中,能够解决分布式系统中的事务一致性问题。它支持多种事务模型(如 AT、TCC、SAGA),并且能够与常见的微服务框架无缝集成。通过 Seata,开发者可以简化分布式事务的管理,并确保在复杂系统中的数据一致性。
AT模式原理
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源(1.解析sql,获取到查询前镜像 2.将前后镜像的数据插入到undo_log 表中 3.根据主键值向TC申请全局锁 4.根据主键,获取到查询后镜像 5.本地事务提交【当前操作 + undo_log 表】 6.将提交结果上报给TC)二阶段:有两种结果要么提交要么回滚 提交:提交异步化,非常快速地完成(异步提交 并立刻返回结果,删除undo_log 表) 回滚:回滚通过一阶段的回滚日志进行反向补偿(开启本地事务,根据全局事务Id [xid] 和 分支Id branchId 获取undo_log 记录,获取undo_log 后镜像数据与当前数据比较 true: 没有被修改 false: 被修改了,需要人工处理,根据前镜像与undo_log 日志生成回滚语句)
Seata环境搭建
1.解压到d盘
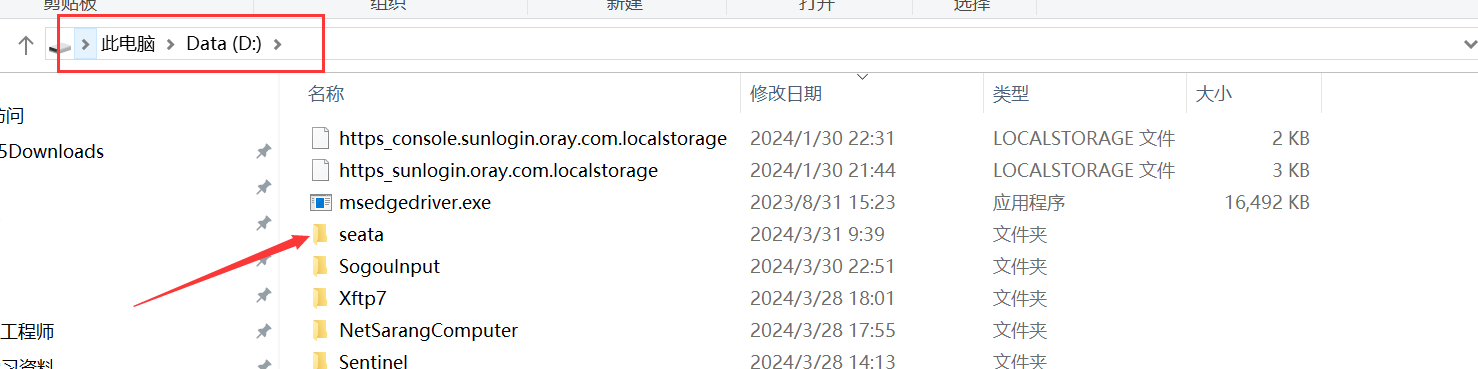
2.修改D:\seata\conf\file.conf文件
1.修改事务组

2.修改日志存储模式为db

3.修改数据库(MySQL5.7)连接信息
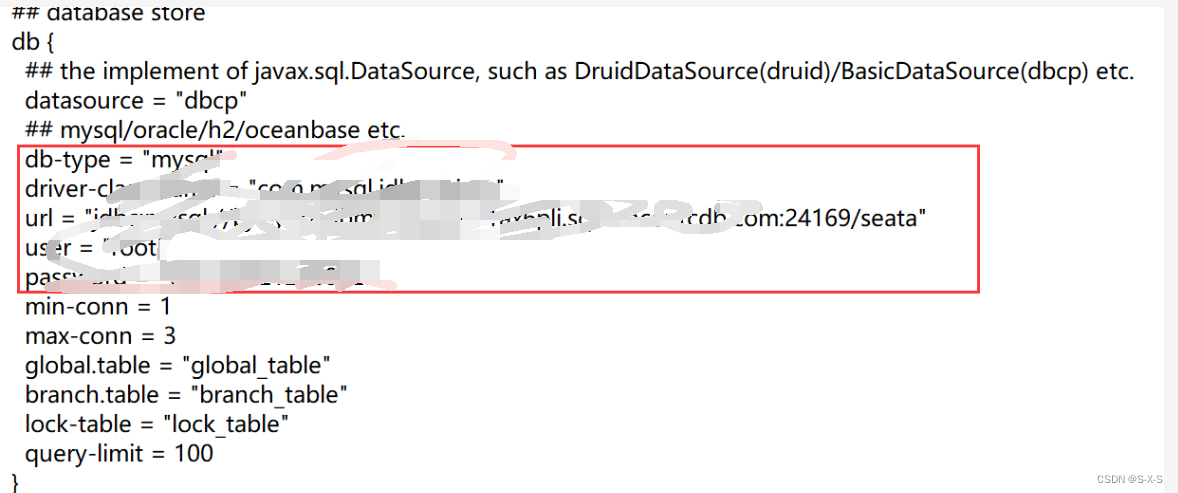
4.创建seata数据库 根据5.创建数据库
5.创建表https://github.com/seata/seata/blob/1.5.2/script/server/db/mysql.sql
6.修改registry.conf 配置注册中心nacos
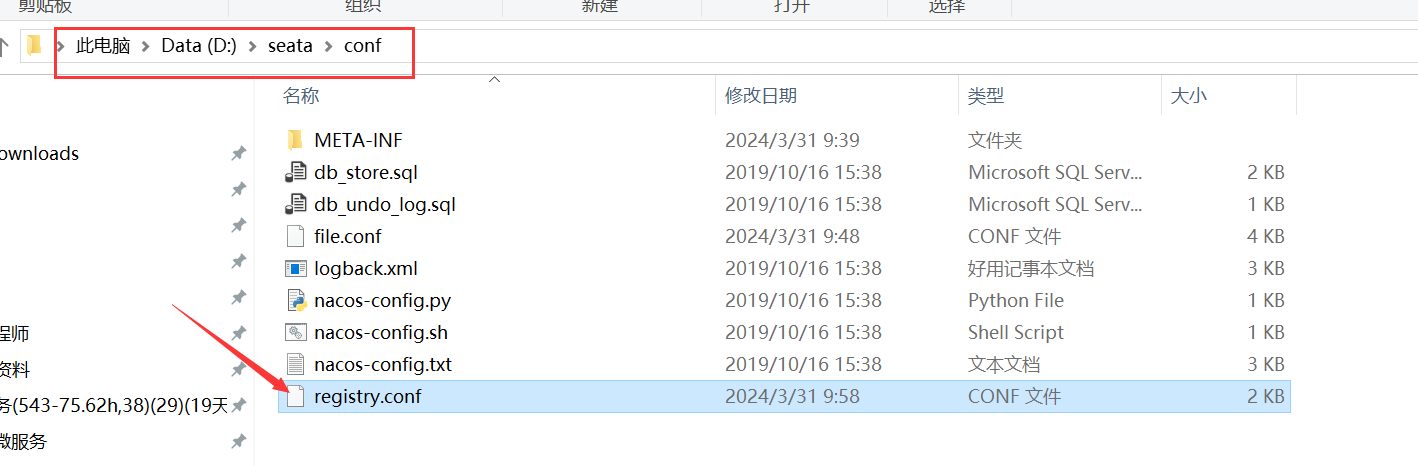
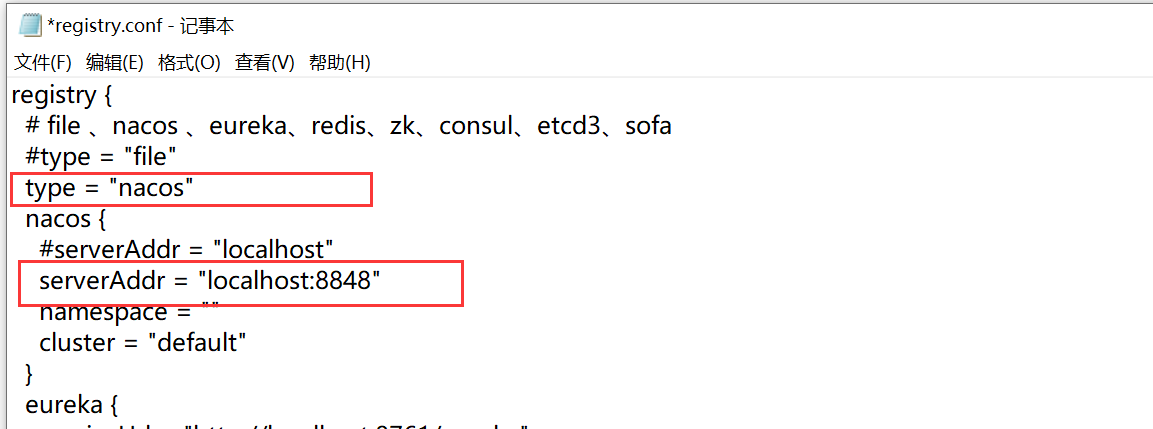
整合项目
添加依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.7.1</version>
</dependency>
增加配置文件在这里插入代码片
seata:
enabled: true
tx-service-group: ${spring.application.name}-group # 事务组名称
service:
vgroup-mapping:
#指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致
service-order-group: default
registry:
type: nacos # 使用nacos作为注册中心
nacos:
server-addr: 192.168.200.130:8848 # nacos服务地址
group: DEFAULT_GROUP # 默认服务分组
namespace: "" # 默认命名空间
cluster: default # 默认TC集群名称

















 4068
4068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









