






1. 跳转指令
Riscv64中的跳转指令分为绝对跳转和分支跳转(以下指令只针对于Riscv64基础指令,其他类型跳转指令原理类似)。
1、绝对跳转有j、jal、jalr、jr
Jal指令格式为:

其中j是jal的伪指令:j offset等同于jal x0, offset
Jalr指令格式为:
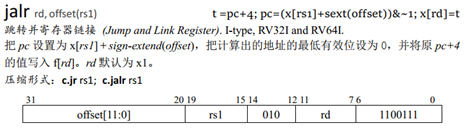
其中jr是jalr的伪指令:jr rs1等同于jalr x0, 0(rs1)
2、分支跳转有beq、bne、blt、bge、bltu、bgeu
以beq的指令格式为例:
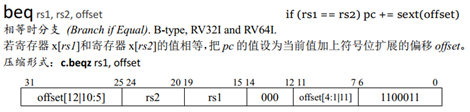
从以上指令中offset的位宽可以看出不同指令的跳转范围,将Riscv64与不同架构的跳转指令对比如下表所示:
| X86 | Arm64 | Mips64r6 | Riscv64 | Mips64r2 |
|---|---|---|---|---|
| Jmp:±2GB | B/BL:±128MB | BC:±128MB | JAL:±1MB | B:±128KB |
| B.EQ:±1MB | BEQ:±32KB | BEQ:±4096B | BEQ:±32KB |
不论绝对跳转还是条件跳转,都分为backward jump(后向跳转)和forward jump(前向跳转),根据指令跳转范围又分为BranchLong(长跳转)和BranchShort(短跳转)。
如例程1所示(例程调试方法见第3章),其中Branch(&onef)在bind(&onef)之前编译,此时label onef地址未决(label 与pc值未绑定),所以这种情况称为forward jump;相反,Branch(&oneb)在bind(&oneb)之后,这种情况称为backward jump。
// 例程1
Label oneb, onef, exit;
__ mv(a1, zero_reg);
__ bind(&oneb);
__ addi(a1, a1, 1);
__ Branch(&exit, eq, a1, Operand(4));
__ Branch(&onef); // not_bound
__ addi(a1, a1, 3);
__ bind(&onef);
__ addi(a1, a1, 2);
__ Branch(&oneb); // is_bound
__ bind(&exit);
__ jr(ra);
将例程1编译机器指令反汇编为:
Instructions (size = 36)
0x5ed8743060 0 00000593 mv a1, zero_reg
0x5ed8743064 4 00158593 addi a1, a1, 1
0x5ed8743068 8 00400e13 li t3, 4
0x5ed874306c c 01c58a63 beq a1, t3, 20 -> 0x5ed8743080 <+0x20>
0x5ed8743070 10 0080006f j 8 -> 0x5ed8743078 <+0x18>
0x5ed8743074 14 00358593 addi a1, a1, 3
0x5ed8743078 18 00258593 addi a1, a1, 2
0x5ed874307c 1c fe9ff06f j -24 -> 0x5ed8743064 <+0x4>
0x5ed8743080 20 00008067 ret
对以上总结为:
1)Label代表pc地址,可以表示已知或未知的pc地址;
2)在v8中,通过Assembler::bind(Label* L)将L绑定到当前pc,一个label只能绑定一次;
3)在v8中,Label分为三种状态:bound、link、unbound。
2. 后向跳转
2.1 短跳转
例程1中,Branch(&oneb)即为backward jump,因为TurboFan对macro assembler的编译是一条一条按顺序进行的,label oneb在Branch(&oneb)之前已经由bind(&oneb)编译绑定。
bind(&oneb)通过间接调用Label::bind_to(int pos)完成label的绑定:
void bind_to(int pos) {
pos_ = -pos - 1;
DCHECK(is_bound());
}
int pos值为当前label所在的pc值相对于存放机器指令buffer的起始位置之间的偏移:
int pc_offset() const {
return static_cast<int>(pc_ - buffer_start_);
}
此时已经完成对label oneb的绑定,当编译至Branch(&oneb)指令时,会对label的状态进行判断。对于例程1而言,label oneb已绑定,并且没有超过kJumpOffsetBits(21),所以会进入BranchShort(L)处理函数。
void TurboAssembler::Branch(Label* L) {
if (L->is_bound()) {
if (is_near(L)) {
BranchShort(L);
} else {
BranchLong(L);
}
} else {
if (is_trampoline_emitted()) {
BranchLong(L);
} else {
BranchShort(L);
}
}
}
BranchShort(L)通过调用BranchShortHelper(int32_t offset, Label* L)生成***j(offset)***机器码:
void TurboAssembler::BranchShortHelper(int32_t offset, Label* L) {
DCHECK(L == nullptr || offset == 0);
offset = GetOffset(offset, L, OffsetSize::kOffset21);
j(offset);
}
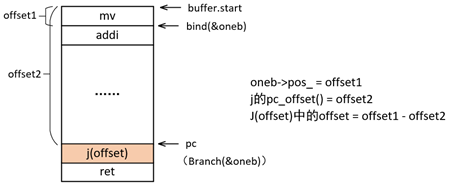
关于offset的获得,通过间接调用Assembler::branch_offset_helper(Label* L, OffsetSize bits)完成。相对于前向跳转,后向跳转逻辑简单,offset的值就是此处j指令的pc与绑定label的pos_(position)之间的offset。如图2.1所示:
2.2 长跳转
如前节,当编译进行至Branch(&oneb)时,会在Branch函数中对跳转距离进行判断,跳转距离在kJumpOffsetBits(21)范围内时为短跳转(BranchShort),如果超过跳转范围会执行长跳转(BranchLong),那BranchLong会怎么执行?
对例程1修改如下,在bind(&oneb)和Branch(&oneb)之间插入足够多的指令为了触发BranchLong:
// 例程2
__ mv(a1, zero_reg);
__ bind(&oneb);
__ addi(a1, a1, 1);
for (int i=0;i<262144;i++){
__ addi(zero_reg, zero_reg, 0);
}
__ Branch(&exit, eq, a1, Operand(2));
__ Branch(&oneb); // is_bound
__ bind(&exit);
__ jr(ra);
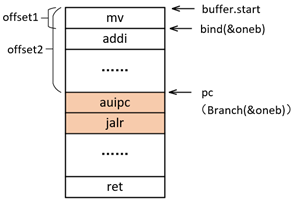
此时Branch(&oneb)会触发长跳转,在BranchLong函数中,会首先获得Branch(&oneb)与bind(&oneb)之间的offset,类似于图2.1的流程。但offset已经超出了j指令的跳转范围,所以不会像BranchShort那样生成j(offset),而是生成RISC-V中的***auipc***和***jalr***两条指令:
int64_t imm64;
imm64 = branch_long_offset(L);
DCHECK(is_int32(imm64));
int32_t Hi20 = (((int32_t)imm64 + 0x800) >> 12);
int32_t Lo12 = (int32_t)imm64 << 20 >> 20;
auipc(scratch, Hi20); // Read PC + Hi20 into scratch.
jr(scratch, Lo12); // jump PC + Hi20 + Lo12
代码中Hi20中+0x800操作是因为,如果offset第12位为1(负数),则负数在右移过程中高位会补1,这样Lo12与Hi20位组合时会造成进位影响,所以为了消除进位影响采用了+0x800操作。
BranchLong跳转指令如图2.2所示:
3. 前向跳转
3.1 短跳转
例程1中,Branch(&onef)为forward jump,同样会进入BranchShort(L)处理函数:
void TurboAssembler::Branch(Label* L) {
if (L->is_bound()) {
if (is_near(L)) {
BranchShort(L);
} else {
BranchLong(L);
}
} else {
if (is_trampoline_emitted()) {
BranchLong(L);
} else {
BranchShort(L);
}
}
}
但此时Label onef是未绑定的,所以会进入is_trampoline_emitted()的判断,简单来讲,v8中的trampoline是为前向长跳转准备的,详细介绍见3.3节,而且trampoline只会生成一次, 当buffer_offset达到一定值之后会自动生成, 例程1机器码较少,不足以生成trampoline,所以Branch(&onef)同样会进入BranchShort(L) ,关于offset的获得,也是通过间接调用Assembler::branch_offset_helper(Label* L, OffsetSize bits)完成,只不过此时Label onef未绑定(L->is_bound() = false)也未链接(L->is_linked() = false),接下来会对Label onef进行link操作:
L->link_to(pc_offset());
if (!trampoline_emitted_) {
unbound_labels_count_++;
next_buffer_check_ -= kTrampolineSlotsSize;
}
DEBUG_PRINTF("\tstarted link\n");
return kEndOfJumpChain;
link操作是将label onef的pc值暂时设置为Branch(&onef)的pc值+1,并更新未绑定的label数量以及next_buffer_check_的值。
由于这是label onef的第一次link操作,所以Branch(&onef)是这条JumpChain的结束位置,返回kEndOfJumpChain = 0。
编译完Branch(&onef)后,会生成机器码j(0),offset为0是因为 branch_offset_helper(L, bits)的返回值为kEndOfJumpChain。
直到编译至bind(&onef),机器码j(0)的offset才在Assembler::bind_to函数中得到修复,修复过程如下(例程1):
1)fixup_pos = L->pos(); 即fixup_pos 为 机器码j(0)的pc值;
2)dist = pos - fixup_pos; 即bind(&onef)处pc与fixup_pos之间的距离;
3)获取fix_up处的instruction并判断类型,此处为jal类型;
4)在target_at_put中根据dist重新生成跳转指令的偏移并重新插入到buffer中的原位置;
机器码的修复示意图如下所示:

3.2 JumpChain
如前节所述,Label存在link状态,在forward jump中,如果有多个Branch跳转到同一个Label,此时会产生一条JumpChain。为了更好的理解,构造测试用例如下:
// 例程3
__ addi(zero_reg, zero_reg, 1);
__ Branch(&onef); // Branch1: not_bound
__ addi(zero_reg, zero_reg, 2);
__ Branch(&onef); // Branch2: not_bound
__ addi(zero_reg, zero_reg, 3);
__ Branch(&onef); // Branch3: not_bound
__ bind(&onef);
__ jr(ra);
Branch1、2、3同样会进入Assembler::branch_offset_helper函数,三者的处理结果概括为:
1)Branch1此时处于no_bound和no_linked状态,各变量更新状态为:
Label onef → pos_ = pc_offset(Branch1)
j(offset) = j(0)
2)Branch2此时处于no_bound和is_linked状态:
Label onef → pos_ = pc_offset(Branch2)
j(offset) = j(pc_offset(Branch1) - pc_offset(Branch2))
3)Branch3此时处于no_bound和is_linked状态:
Label onef → pos_ = pc_offset(Branch3)
j(offset) = j(pc_offset(Branch2) - pc_offset(Branch3))

以上就是所有的Branch形成的JumpChain,当运行至Label onef真正的位置时,跳转指令修复的详细操作和3.1节中的短跳转一致,只不过是按照链的从头(Branch3)到尾(Branch1)顺序修复。
while (L->is_linked()) {
int fixup_pos = L->pos();
int dist = pos - fixup_pos;
is_internal = is_internal_reference(L);
next(L, is_internal); // Call next before overwriting link with target
// at fixup_pos.
Instr instr = instr_at(fixup_pos);
DEBUG_PRINTF("\tfixup: %d to %d\n", fixup_pos, dist);
if (is_internal) {
target_at_put(fixup_pos, pos, is_internal);
} else {
if (IsBranch(instr)) {
……
} else if (IsJal(instr)) {
if (dist > kMaxJumpOffset) {
if (trampoline_pos == kInvalidSlotPos) {
trampoline_pos = get_trampoline_entry(fixup_pos);
CHECK_NE(trampoline_pos, kInvalidSlotPos);
}
CHECK((trampoline_pos - fixup_pos) <= kMaxJumpOffset);
DEBUG_PRINTF("\t\ttrampolining: %d\n", trampoline_pos);
target_at_put(fixup_pos, trampoline_pos, false);
fixup_pos = trampoline_pos;
}
target_at_put(fixup_pos, pos, false);
} else {
target_at_put(fixup_pos, pos, false);
}
}
}
在bind_to函数中,通过while判断对JumpChain中的跳转指令进行逐一修复,在链的形成过程中,Label onef的最后链接位置为Branch3的pc_offset,所以首先修复Branch3处的跳转指令,然后通过next函数将Label onef链接至JumpChain的下一个跳转指令,进行循环修复。
void Assembler::next(Label* L, bool is_internal) {
DCHECK(L->is_linked());
int link = target_at(L->pos(), is_internal);
if (link == kEndOfChain) {
L->Unuse();
} else {
DCHECK_GT(link, 0);
DEBUG_PRINTF("next: %p to %p (%d)\n", L,
reinterpret_cast<Instr*>(buffer_start_ + link), link);
L->link_to(link);
}
}
当修复至JumpChain的底部,即Branch1时,因为跳转指令的offset = 0(kEndOfJumpChain),所以退出循环,修复结束。
3.3 长跳转
Label未决的长跳转依赖于trampoline,并且在一个buffer里面只会生成一次trampoline。在3.1节中简单介绍过trampoline的生成条件, 当机器码buffer空间达到branch跳转范围时,会自动生成,Riscv64架构下,这个阈值为3967Byte:
// We leave space (16 * kTrampolineSlotsSize)
// for BlockTrampolinePoolScope buffer.
next_buffer_check_ = FLAG_force_long_branches
? kMaxInt
: kMaxBranchOffset - kTrampolineSlotsSize * 16;
// Max offset for b instructions with 12-bit offset field (multiple of 2)
static constexpr int kMaxBranchOffset = (1 << (13 - 1)) - 1;
// Max offset for jal instruction with 20-bit offset field (multiple of 2)
static constexpr int kMaxJumpOffset = (1 << (21 - 1)) - 1;
static constexpr int kTrampolineSlotsSize = 2 * kInstrSize;
以一个例子来说明trampoline的生成过程,例程4中,在Branch和bind之间插入足够多的指令保证调用j指令的长跳转:
// 例程4
__ addi(zero_reg, zero_reg, 0);
__ Branch(&onef); // not_bound
for (int i=0;i<262144;i++){
__ addi(zero_reg, zero_reg, 0);
}
__ bind(&onef);
__ jr(ra);
通过反汇编可以看到例程4运行的机器码以及trampoline对应的机器码如下所示:

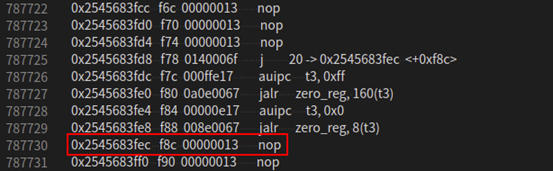
我们可以看到在生成红框标记位置的nop指令时,插入了trampoline,此时的buffer.offset = f78(3960),而next_buffer_check_ = 3959(label未决时进行link操作,link操作会将next_buffer_check_ - 8),满足trampoline生成条件。
L->link_to(pc_offset());
if (!trampoline_emitted_) {
unbound_labels_count_++;
next_buffer_check_ -= kTrampolineSlotsSize; // 更新next_buffer_check的值
}
DEBUG_PRINTF("\tstarted link\n");
return kEndOfJumpChain;
此处有一个现象是例程4只有一个forward jump,而生成的trampoline中却多了一条j指令以及一组auipc+jalr,接下来看trampoline的具体生成过程。
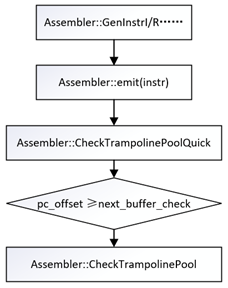
生成trampoline的具体函数为Assembler::CheckTrampolinePool:
if (unbound_labels_count_ > 0) {
// First we emit jump, then we emit trampoline pool.
{
DEBUG_PRINTF("inserting trampoline pool at %p (%d)\n",
reinterpret_cast<Instr*>(buffer_start_ + pc_offset()),
pc_offset());
UseScratchRegisterScope temps(this);
BlockTrampolinePoolScope block_trampoline_pool(this);
Register scratch = temps.Acquire();
Label after_pool;
j(&after_pool);
int pool_start = pc_offset();
for (int i = 0; i < unbound_labels_count_; i++) {
int64_t imm64;
imm64 = branch_long_offset(&after_pool);
DCHECK(is_int32(imm64));
int32_t Hi20 = (((int32_t)imm64 + 0x800) >> 12);
int32_t Lo12 = (int32_t)imm64 << 20 >> 20;
auipc(scratch, Hi20); // Read PC + Hi20 into t5.
jr(scratch, Lo12); // jump PC + Hi20 + Lo12
}
// If unbound_labels_count_ is big enough, label after_pool will
// need a trampoline too, so we must create the trampoline before
// the bind operation to make sure function 'bind' can get this
// information.
trampoline_ = Trampoline(pool_start, unbound_labels_count_);
bind(&after_pool);
trampoline_emitted_ = true;
// As we are only going to emit trampoline once, we need to prevent any
// further emission.
next_buffer_check_ = kMaxInt;
}
} else {
// Number of branches to unbound label at this point is zero, so we can
// move next buffer check to maximum.
next_buffer_check_ =
pc_offset() + kMaxBranchOffset - kTrampolineSlotsSize * 16;
}
从以上代码可以看出,当满足条件进入此函数后,会判断未绑定label的数量unbound_labels_count_,若在此buffer范围内(MaxBranchOffset)并未有label未决的jump(unbound_labels_count_ = 0),则重新设置next_buffer_check_ =pc_offset() + kMaxBranchOffset - kTrampolineSlotsSize * 16,即此次虽然满足阈值条件,但并未有label未决的jump,所以不产生trampoline,并从当前pc位置重新叠加buffer空间等待下一次trampoline的产生。
当满足阈值条件,并且unbound_labels_count_大于0,首先会生成一条j指令,j指令的作用是跳过trampoline(trampoline属于插入操作,不能影响程序的正常顺序执行);随后在for循环中为所有label未决的jump生成auipc+jalr长跳转指令组合。
上述现象trampoline中auipc+jalr多了一组,即为j指令准备的,此处的j指令也属于label未决的跳转,并且存在trampoline大小超过j指令跳转范围的情况。如图3.4所示,j指令和最后一组auipc+jalr的作用都是跳过trampoline。
当trampoline生成后,重新设置next_buffer_check_ = kMaxInt。

当存在trampoline时,会为每一条label未决的跳转指令生成一组auipc+jalr,在运行至label位置时,需要进行绑定修复操作(如3.1节),此时会进行判定,若跳转距离未超过跳转指令范围时,会进行3.1节的修复过程,auipc+jalr指令组合不会被运用(闲置);若跳转距离超过跳转指令范围时,会进行两次修复过程:
1)修复跳转指令至trampoline;
2)修复trampoline至label位置;
if (dist > kMaxJumpOffset) {
if (trampoline_pos == kInvalidSlotPos) {
trampoline_pos = get_trampoline_entry(fixup_pos);
CHECK_NE(trampoline_pos, kInvalidSlotPos);
}
CHECK((trampoline_pos - fixup_pos) <= kMaxJumpOffset);
DEBUG_PRINTF("\t\ttrampolining: %d\n", trampoline_pos);
target_at_put(fixup_pos, trampoline_pos, false);
fixup_pos = trampoline_pos;
}
target_at_put(fixup_pos, pos, false);
以上为trampoline的生成以及运用原理。在生成一次trampoline后,所有新的label未决的跳转都会走3.1节中的BranchLong路径,即全部运用auipc+jr指令组合。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









