






免责声明:本文仅作学习和交流用,无任何商业用途及其他非法用途。若涉及侵权,请尽快联系作者修改或删除。
爬虫是一种自动化程序,它可以模拟人类在互联网上浏览网页的行为,从而获取网页上的信息。通常,爬虫通过网络协议和编程语言进行编写和操作,可以在互联网上搜索并下载网页的HTML、CSS、JavaScript等内容,并从中提取出所需要的数据。爬虫广泛应用于搜索引擎、数据挖掘、舆情监测、竞品分析等领域,可以大大提高人们获取信息的效率和准确性。同时,爬虫使用需要遵守相关法律法规,尊重网站的隐私和使用协议,不得进行恶意攻击或侵犯他人利益等违法行为。
本文旨在对现今主流爬虫技术进行总结和归纳,如有不正确或其他情况还望私聊批评指正。
文章目录
0 爬虫预备知识
0.1 爬虫是什么?
Web crawler:A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering)
网络爬虫:网络爬虫,有时称为爬虫或爬虫机器人,通常简称为爬虫,是一种系统地浏览万维网的互联网机器人,通常由搜索引擎操作,用于网络索引(网络爬虫)。
——来自维基百科
0.2 爬虫可以做什么?
爬虫是最高效的收集二手信息的工具,信息就是资产,资产用于创造财富,因此爬虫作为信息与数据收集必不可或缺的工具,在数据时代必须学会。
爬虫经典案例1:豆瓣电影TOP250爬虫
爬虫经典案例2:京东商品信息爬虫
爬虫经典案例3:上市公司财务财务信息爬虫
爬虫经典案例4:爬取科研数据
爬虫场景汇总:爬虫常见场景汇总
0.3 爬虫任何网站都可以爬取吗?
显然不是,理论上所有网站都是可以进行爬取的 ,但是现实存在法律的约束以及反爬机制的约束,使得并非所有网站都可以进行自由的爬取。
一、Robot协议
robots协议,就是告诉搜索引擎,可以爬取收录什么页面,不可以爬取和收录那些页面。robots很好的控制网站那些页面可以被爬取,那些页面不可以被爬取。
Robot协议可以通过修改爬虫ROBOTSTXT_OBEY = False参数,从而让爬虫不遵循Robot协议。
二、反爬机制
反爬机制是较Robot协议是更加高端的限制(禁止)爬虫的机制,反爬策略种类繁多,技术难度较大。不建议刚开始学习爬虫的同学学习,容易劝退。下面仅列举了部分常见的反爬机制,并且暂不进行展开。以下分享链接由上至下难度主键加大,法律风险也逐渐加大。
常见反爬机制及解决方案blog1
常见反爬机制及解决方案blog2
实习僧字体反爬
知乎反爬
知网反爬
1. user-agent字段反爬
2. 代理ip反爬
3. cookies反爬
4. 验证码反爬
5. 动态页面的反爬
6. 字体反爬
1 HTTP和HTTPS
2 常见爬虫手段
从此处开始介绍常见爬虫手段,难度逐渐增加,建议按顺序进行阅读。
2.1 urllib
urllib是Python中内置的一个HTTP请求库。它包含四个模块,分别是urllib.request、urllib.parse、urllib.error和urllib.robotparser。
- urllib.request模块提供了最基本的HTTP请求功能,可以发送GET、POST、PUT等请求,并支持设置请求头、代理等功能
- urllib.parse模块用于处理URL,可以将URL解析成各个组成部分
- urllib.error模块用于处理异常
- urllib.robotparser模块用于解析robots.txt文件,帮助爬虫遵守爬取规则。
2.2 request+BeautifulSoup(更适合新手)
request+BeautifulSoup(bs4) = 请求+解码
requests:封装了HTTP请求的各种操作(但没有封装解码),可以用于发送HTTP请求、处理响应和操作URL等。它支持多种HTTP请求方法,包括GET、POST、PUT等,可以设置请求头、代理、cookies等,还提供了方便的方法来解析响应内容,如JSON、XML、图片等。
BeautifulSoup:,用于解析HTML和XML文档。它可以将HTML和XML文档解析成Python对象,提供了一种Pythonic的方式来搜索、遍历和修改文档树,能够轻松地提取所需的数据。
BeautifulSoup支持多种解析器,包括Python自带的html.parser、lxml、html5lib等,可以根据不同的需求选择不同的解析器。
2.3 selenium(自动化爬取)
selenium是一个自动化测试工具,也可以用于爬虫。它可以模拟用户在浏览器上的行为,可以自动化地打开网页、填写表单、点击按钮等操作,并获取网页上的数据。selenium支持多种浏览器,包括Chrome、Firefox、IE等,可以根据需要选择不同的浏览器进行操作。selenium的优势在于可以处理JavaScript渲染、动态网页等问题,适用于一些需要模拟用户交互的场景。
3 Scrapy框架
在介绍本框架的同时,以一个实际爬虫项目为案例进行讨论。
Scrapy的优势:处理复杂的爬取逻辑和数据处理,适用于大规模、高效的爬虫任务。
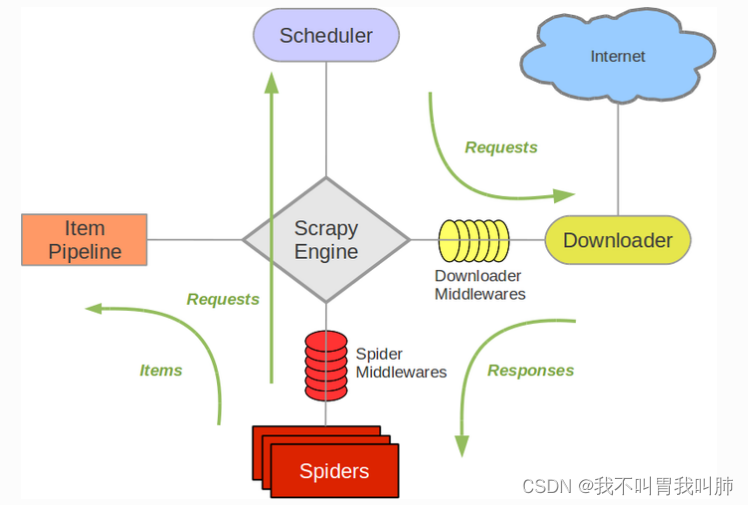
Scrapy是一个Python爬虫框架,可以用于快速构建和部署爬虫。它提供了一套基于Twisted的异步网络框架,可以高效地处理大量请求和响应,支持多种数据存储格式,如JSON、CSV、MySQL、MongoDB等。Scrapy还提供了强大的调度器、去重器、下载器等组件,方便爬虫的编写和调试。下面依次介绍Scrapy框架的组件。
下图展示了Scrapy架构的构件,下文将从每个构件进行详细介绍。
 参考博客1:Scrapy爬虫框架,入门案例(非常详细)
参考博客1:Scrapy爬虫框架,入门案例(非常详细)
参考博客2:【Python爬虫必备—>Scrapy框架快速入门篇——上】
3.1 Srapy Engine(爬虫引擎)
3.2 Spider(爬虫程序)
3.3 Downloader(下载器)
3.4 Item Pipeline(数据管道 / 数据通道)
3.5 Settings(设置)
3.6 其他组件
3.7 BAT文件实现多个爬虫一键实现
——————
未完待续…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









