






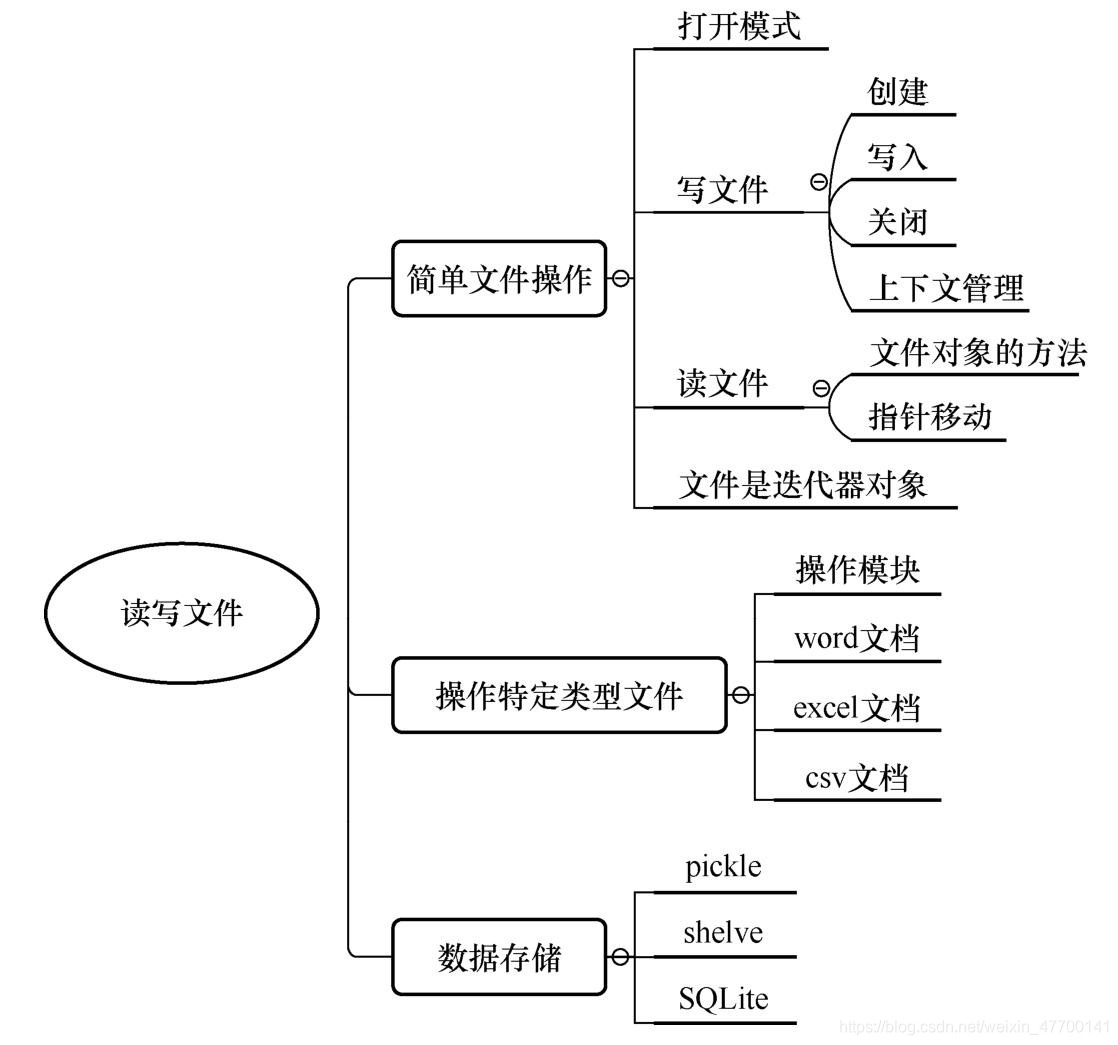
知识技能导图
# -------------------------------- 简单文件操作 ------------------------------------#
# -------------------------------- 新建文件 ------------------------------------#
import os
os.getcwd()
# '/Users/apple/PycharmProjects'
# 进入到交互模式中,先明确当前的工作目录。然后按照下面的操作,在当前的工作目录中创建一个新的文件,并写入内容。
f = open("warning.txt","w") #1
f.write("To review for the exam soon!") #2
# 28
f.close() #3
# 创建、写入和关闭文件的三个步骤如下。
# 第一步:使用open()打开(新建)文件。open()是内置函数,可以用help()查看帮助文档,其完整格式是:

# 参数file是文件名,在#1中没有写路径,表示是在当前工作目录创建了该文件。
# 参数mode表示打开方式,#1中的打开方式是"w"。下表列出了常用的文件打开方式及其含义。
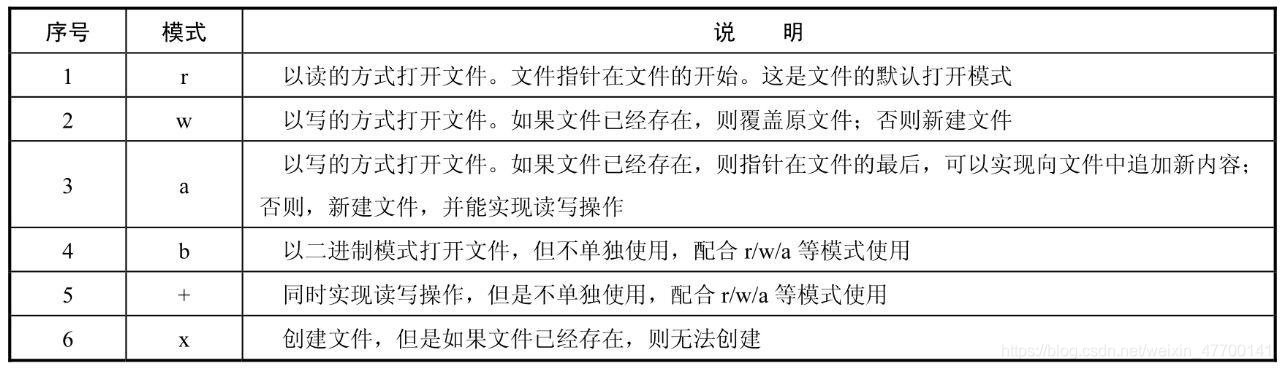
常用文件打开方式
# 以上打开模式还可以组合使用,如"rb"表示打开二进制只读文件;"r+"表示打开一个可以读、写的文件;"wb+"表示打开一个可读、写的二进制文件,并且如果文件已存在,会覆盖它,否则新建。
#1 以"w"模式打开文件,在当前工作目录中没有这个文件,则创建了名为"warning.txt"的文件。之后,#2实现了对文件的写入操作。
# open()返回的是一个对象,这个对象的write()方法实现向文件中写入字符串功能。
# 写入之后,一定要进行#3操作,否则前述操作内容没有保存到硬盘中。
os.listdir()
# ['.DS_Store', 'warning.txt', 'pythonProject', 'pythonProject1', 'pythonProject2', 'pythonProject3', '.idea']
# 工作目录中的确存在刚才新建的文件。
# 那么,文件内容是什么?#2中写入的内容是否在里面了?
# -------------------------------- 简单文件操作 ------------------------------------#
# -------------------------------- 读文件 ------------------------------------#
# 要想读文件,也要利用open函数,只不过所采用的打开模式与#1不同。
f = open("warning.txt") #4
f.read()
# 'To review for the exam soon!'
#4 没有为open函数提供打开模式,使用了默认的模式"r",也可以写成open("warning.txt","r")。
# 利用所得到的对象的read方法,可以读出文件中的所有内容。结果显示,这个文件已经保存了#2所写入的内容。
# 这就是读文件的最简单方式。
# 不管是#1还是#4,open函数返回的对象是什么类型?有什么特点?
type(f)
# <class '_io.TextIOWrapper'>
# 显然,f是某个类的实例,只不过这个类的名称长了一些。先要从I/O说起。所谓"I/O",就是"Input/Output"。其实以往使用的print函数也属于I/O,只不过是输出在控制台界面罢了。文件是另一种形式的I/O。
# python的标准库中有针对I/O的模块,即io。对于I/O而言,所有的输入、输出内容都可以看作数据流。
# 总结:#4得到的对象,是io模块的TextIOWrapper类的实例对象--可称之为"文件对象"。
dir(f)
# ['_CHUNK_SIZE', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_finalizing', 'buffer', 'close', 'closed', 'detach', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'line_buffering', 'mode', 'name', 'newlines', 'read', 'readable', 'readline', 'readlines', 'reconfigure', 'seek', 'seekable', 'tell', 'truncate', 'writable', 'write', 'write_through', 'writelines']
# 请认真地读一读上述返回结果,会发现其中包括了"__iter__"、"__next__"这些有特殊含义的方法,说明文件对象是一个迭代器。既然如此,就可以针对它使用for循环了。
# 为了明显地看到循环效果,再向文件中增加几行内容。
with open("warning.txt","a") as f : #5
f.write("so I can stand on mountains.\nYou raise me up to walk on stormy seas.\nI am strong when I am on your shoulders.\nYou raise me up to more than I can be.")
# ...
# 148
# 再次向已有文件中增加内容,使用的是#5,这种以with开头的语句称为"上下文管理器"。其任务是在代码执行之前做好准备———打开文件,代码执行之后收拾残局———关闭文件,等效于#3的作用。
f = open("warning.txt")
for line in f:
print(line,end='')
# ...
# To review for the exam soon!so I can stand on mountains.
# You raise me up to walk on stormy seas.
# I am strong when I am on your shoulders.
# You raise me up to more than I can be.>>>
# 既然文件是迭代器,那么,在for循环的过程中,"指针"也随着向下移动。当循环结束,指针移到了文件的最后。如果试图再次读取内容,返回是就是空了。
f.read()
# ''
# 在文件对象的方法中提供了移动指针的方法seek,能够将指针移动到文件指定位置。
# 用help函数查看其文档(help(f.seek)),可知其基本调用方式是:
# seek(cookie, whence=0, /)
# 其中,whence用于定义指针移动的"参照物",默认为0,表示相对文件的开始,移动量应该是非负整数;1表示相对当前位置移动,移动量可以是负整数;2表示相对文件的末端移动,移动量通常是负整数。
f.seek(0)
# 0
# 这表示指针已经移动到了文件的最开始,返回值表示当前指针相对文件开始的绝对位置。
f.read(3)
# 'To '
# 如果在read方法中指定了参数,则意味着只读取指定个数的字符。
f.readline()
# 'review for the exam soon!so I can stand on mountains.\n'
# 方法readline的作用是从指针所在位置开始,读到本行结束,返回字符串。
f.readlines()
# ['You raise me up to walk on stormy seas.\n', 'I am strong when I am on your shoulders.\n', 'You raise me up to more than I can be.']
# 方法readlines会从指针所在位置开始,逐行读取,并返回列表,每行作为列表中的一个元素。
# 文件对象还有其他方法。同学们可以使用反复提及的方法———dir和help函数,能够知道如何使用。
# -------------------------------- 读写特定类型文件 ------------------------------------#
# -------------------------------- Word文档 ------------------------------------#
# 首先安装它
# $ pip3 install python-docx
# 安装完毕,用它来创建一个word文件,操作如下:
from docx import Document #1
d = Document() #2
d.add_paragraph("Life is short, You need python.") #3
d.save("python.docx") #4
# 以上操作是创建和保存word文档的基本步骤
#1 从docx包中引入Dodument类
#2 实例化该类,即创建文档对象。
#3 应用文档对象d的方法add_paragraph向文档中增加一个段落,同时增加该段落的内容。
#4 将文档对象保存为word文件,存储到硬盘中。注意,没有注明路径,意味着保存到了当前交互模式的工作目录中。
os.getcwd()
os.listdir()
# 虽然这里看到了文件名,还是要到硬盘中找到它,用Office工具打开它,看看用程序写的word文档到底什么样。
para = d.add_paragraph("Amazing Grace, How sweet the sound.")
before_para = para.insert_parogranph_before("You raise me up, so I can stand on mountains.") #5
d.save("python.docx")
# 以上完成两段内容的插入,第一段是执行了文件对象d的add_paragraph方法,在文件对象d的已有内容后面增加了一段内容"Amazing Grace, How sweet the sound."。并且这段内容以对象形式返回,用变量para引用它。
#5 则是在para所引用的段落对象之前插入一个段落,其内容是#5中参数所示内容。
# 最后保存文件
# 再次查看操作效果(重新打开该word文件)。

# word文档通常包含图,文档对象也提供了增加图的方法。
d.add_picture("python-book.png")
d.save("python.docx")
# 上述操作中所添加的图片没有做宽度和高度的设置,如果有必要,可以在add_picture方法中增加width和height参数。
# 除了可以实现图文输入,python-docx还能创建表格。同学们可以阅读官方文档或使用dir和help函数查看帮助文档。
# -------------------------------- 读写特定类型文件 ------------------------------------#
# -------------------------------- Excel文档 ------------------------------------#
# 在python中有很多操作Excel的第三方包,此处仅以OpenPyXL为例。
# $ pip3 install openpyxl
# 安装成功之后,就可以在交互模式中应用包中的模块了。
from openpyxl import Workbook
wb = Workbook() #6
#6 实现了在内存中创建"工作簿"对象。Excel的组成部分包括"工作簿"、"工作表"、"单元格",工作簿中包含若干工作表,工作表中包含若干单元格。
# 每个工作簿中至少有一个工作表,可以用下面的方式获得当前工作表。
ws = wb.active
ws.title
# 'Sheet'
# 此时,这个工作表的名称默认为"Sheet",可以修改工作表名称。
ws.title = 'python'
ws.title
# 'python'
# 还可以继续增加工作表。
ws1 = wb.create_sheet("Rust") #7
ws2 = wb.create_sheet("BASIC",0) #8
#7 在已有工作表ws后面追加了一个工作表
#8 在ws工作表前面插入了一个工作表,并且#7和#8对两个工作表都做了新的命名。工作表是工作簿的元素,类似列表中的元素,也是从0开始索引的。
wb.sheetnames
# ['BASIC', 'python', 'Rust']
# 这样,在工作簿wb中已经有了3个工作表,并且3个工作表的名称和次序依此'BASIC', 'python', 'Rust',工作簿的属性sheetnames返回的结果显示了该工作簿下的所有工作表名称和顺序。
for s in wb:
print(s)
# <Worksheet "BASIC">
# <Worksheet "python">
# <Worksheet "Rust">
# 其实,工作簿是一个可迭代对象。
ws3 = wb['python'] #9
# 工作表名称可以作为工作簿的键,从而得到该工作表。
ws
# <Worksheet "python">
ws3
# <Worksheet "python">
ws is ws3
# True
# -----------------------------------------------------------------------------------#
# 在Excel的工作表中,由行列组成了单元格,行的索引是从1开始,到65536;列的索引是从A开始,到IV。每个单元格用列和行的索引标识,如A3、B2等,都可以看成相应单元格的名称。

# 通过工作表对象,以单元格名称为键,可以得到该单元格对象--类似#9的操作。
ws['E1'] = 123
# 在单元格E1中填入数字123。此外,工作表对象的cell方法提供了按照函数形式写入数据的方法。
ws.cell(row=2,column=2,value=111)
# <Cell 'python'.B2>
# 从返回值可以看出,数据111写入了工作表python中的B2单元格。
# 做过上述操作,如果要看看最终效果,就要将所有内容保存到Excel文件中。
wb.save("example.xlsx")

# 在某种情况下,可能准备了比较多的数据,要写入到Excel表格中,使用循环语句是一种方,比如:
for r in range(4):
for c in range(5):
ws.cell(row=r,column=c,value=3.14)
# Traceback (most recent call last):
# File "<stdin>", line 3, in <module>
# File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/openpyxl/worksheet/worksheet.py", line 238, in cell
# raise ValueError("Row or column values must be at least 1")
# ValueError: Row or column values must be at least 1
# 这个报错信息非常重要,在python中已经习惯了从0开始计数,但是在Excel的工作表中,是从1开始计数的。
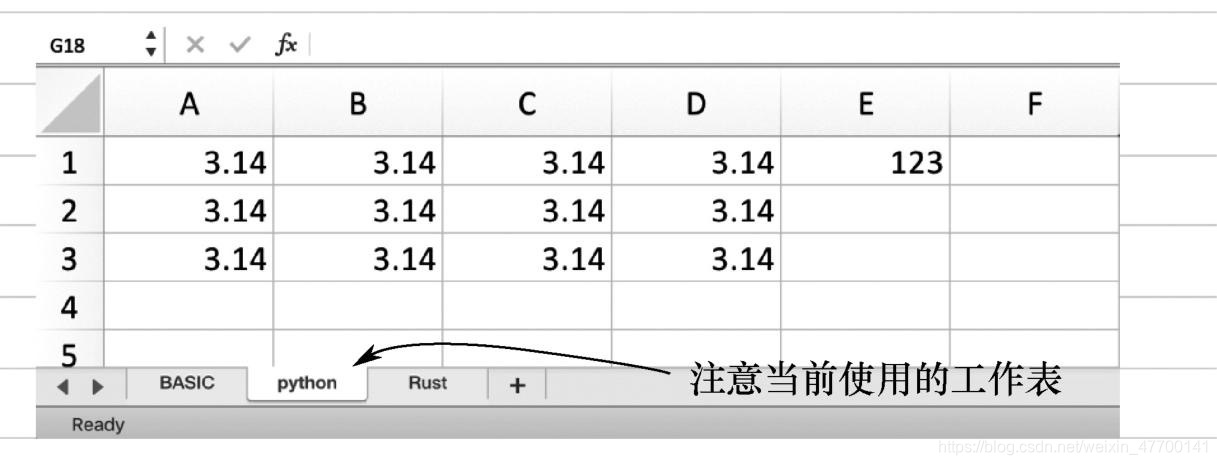
for r in range(1,4):
for c in range(1,5):
ws.cell(row=r,column=c,value=3.14)
# ... ws.cell(row=r,column=c,value=3.14)
# ...
# <Cell 'python'.A1>
# <Cell 'python'.B1>
# <Cell 'python'.C1>
# <Cell 'python'.D1>
# <Cell 'python'.A2>
# <Cell 'python'.B2>
# <Cell 'python'.C2>
# <Cell 'python'.D2>
# <Cell 'python'.A3>
# <Cell 'python'.B3>
# <Cell 'python'.C3>
# <Cell 'python'.D3>
# 循环语句操作的返回结果,显示了所使用的工作表和写入数据的单元格。保存文件之后,可以看到最终结果。
# 除了上述方法,还可以利用工作表的append方法实现多行数据的写入。
from openpyxl import compat
for row in range(1,9):
basic.append(compat,range(100))
# 工作表的append方法能够实现在当前工作表的最后以行为单位追加数据。
# 除了直接操作Excel文档,OpenPyXL还能够与数据分析的著名工具NumPy和Pandas联合使用。
# -------------------------------- 读写特定类型文件 ------------------------------------#
# -------------------------------- CSV文档 ------------------------------------#
# CSV,中文译为"逗号分隔值",其文件以纯文本形式存储表格数据。通常,在Excel中可以将当前文件保存为".csv"格式。所有的CSV文件也可以用电子表格软件打开。但是CSV文档与Excel文档有很多不同之处,比如:CSV文档中的值没有类型,所有值都是字符串;不能进行图文编辑,因为它是一个纯文本文件。
# python的标准库中有专门操作CSV文档的模块。
import csv
datas = [['name','number'],['python',111],['java',222],['c++',333]]
with open("csvfile.csv",'w') as f: #10
writer = csv.writer(f) #11
writer.writerow(datas) #12
# 上述操作实现了CSV文档的创建和内容的写入操作。#10与之前学过的创建文件方式相同。#11利用文件对象f创建CSV文档的写入对象,然后通过writer的方法writerows实现多行写入操作(即#12)。
# 在python中读取CSV文件的内容,可以按照如下演示操作:
f = open("csvfile.csv")
reader = csv.reader(f) #13
for row in reader:
print(row)
# ["['name', 'number']", "['python', 111]", "['java', 222]", "['c++', 333]"]
# 利用csv.reader方法将文件对象转化为CSV可迭代对象(如#13),然后通过for循环完成对每行数据的读取。
# 以上实现了CSV文档的读写操作。另外,在标准库csv中还有DictReader和DictWriter两个方法,它们的作用是将CSV文档转换为类字典对象,通过类字典的操作实现数据读写。















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











