






先啃文档
1.模式和被搜索的字符串既可以是 Unicode 字符串 (str) ,也可以是8位字节串 (bytes),也就是说,不能用bytes模式匹配 Unicode 字符串,反之亦然;同理,替换操作时,替换字符串的类型也必须与所用的模式和搜索字符串的类型一致。
2.关于反斜杠字符 (‘’) :要匹配一个反斜杠字面值,用户将必须写成 ‘\\’ 因为正则表达式必须为 \,而每个反斜杠在普通 Python 字符串字面值中又必须表示为 \。
3.在带有 ‘r’ 前缀的字符串字面值中,反斜杠不必做任何特殊处理。 因此 r"\n" 表示包含 ‘’ 和 ‘n’ 两个字符的字符串,而 “\n” 则表示只包含一个换行符的字符串。 模式在 Python 代码中通常都使用原始字符串表示法
4.正则表达式可以包含普通或者特殊字符
普通字符,比如 ‘A’, ‘a’, 或者 ‘0’,都是最简单的正则表达式。它们就匹配自身。你可以拼接普通字符
特殊字符既可以表示它的普通含义, 也可以影响它旁边的正则表达式的解释比如 ‘|’ 或者 ‘(’,属于特殊字符
重复运算符或数量限定符 (, +, ?, {m,n} 等) 不能被直接嵌套。 这避免了非贪婪修饰符后缀 ? 的歧义,也避免了其他实现中其他修饰符的歧义。 要将第二层重复应用到内层的重复中,可以使用圆括号。 例如,表达式 (?:a{6}) 将匹配六个 ‘a’ 字符的任意多次重复。
“.” : (点号) 在默认模式下,匹配除换行符以外的任意字符。 如果指定了旗标 DOTALL ,它将匹配包括换行符在内的任意字符。
****?, +?, ??
'', ‘+’ 和 ‘?’ 数量限定符都是 贪婪的;它们会匹配尽可能多的文本。 有时这种行为并不被需要;如果 RE <.> 针对 ‘ b ’ 进行匹配,它将匹配整个字符串,而不只是 ‘’。 在数量限定符之后添加 ? 将使其以 非贪婪 或 最小 风格来执行匹配;也就是将匹配数量尽可能 少的 字符。 使用 RE <.*?> 将只匹配 ‘’.
*+, ++, ?+
类似于 '', ‘+’ 和 ‘?’ 数量限定符,添加了 ‘+’ 的形式也将匹配尽可能多的次数,这些形式在之后的表达式匹配失败时不允许反向追溯,这些形式被称为 占有型 数量限定符.aa 将匹配 ‘aaaa’ 因为 a* 将匹配所有的 4 个 ‘a’,但是,当遇到最后一个 ‘a’ 时,表达式将执行反向追溯以便最终 a* 最后变为匹配总计 3 个 ‘a’,而第四个 ‘a’ 将由最后一个 ‘a’ 来匹配。 然而,当使用 a*+a 时如果要匹配 ‘aaaa’,a*+ 将匹配所有的 4 个 ‘a’,但是在最后一个 ‘a’ 无法找到更多字符来匹配时,表达式将无法被反向追溯并将因此匹配失败. x*+, x++ 和 x?+ 分别等价于 (?>x*), (?>x+) 和 (?>x?)。
{m,n}?
将导致结果 RE 匹配之前 RE 的 m 至 n 次重复,尝试匹配尽可能 少的 重复次数。 这是之前数量限定符的非贪婪版本。 例如,在 6 个字符的字符串 ‘aaaaaa’ 上,a{3,5} 将匹配 5 个 ‘a’ 字符,而 a{3,5}? 将只匹配 3 个字符
{m,n}+
将导致结果 RE 匹配之前 RE 的 m 至 n 次重复,尝试匹配尽可能多的重复而 不会 建立任何反向追溯点。 这是上述数量限定符的占有型版本。 例如,在 6 个字符的字符串 ‘aaaaaa’ 上,a{3,5}+aa 将尝试匹配 5 个 ‘a’ 字符,然后,要求再有 2 个 ‘a’,这将需要比可用的更多的字符因而会失败,而 a{3,5}aa 的匹配将使 a{3,5} 先捕获 5 个,然后通过反向追溯再匹配 4 个 ‘a’,然后用模式中最后的 aa 来匹配最后的 2 个 ‘a’。 x{m,n}+ 就等同于 (?>x{m,n})。
\
转义特殊字符(允许你匹配 ‘*’, ‘?’, 或者此类其他),或者表示一个特殊序列;特殊序列之后进行讨论。
如果你没有使用原始字符串( r’raw’ )来表达样式,要牢记Python也使用反斜杠作为转义序列;如果转义序列不被Python的分析器识别,反斜杠和字符才能出现在字符串中。如果Python可以识别这个序列,那么反斜杠就应该重复两次。这将导致理解障碍,所以高度推荐,就算是最简单的表达式,也要使用原始字符串。
(…)
(组合),匹配括号内的任意正则表达式,并标识出组合的开始和结尾。匹配完成后,组合的内容可以被获取,并可以在之后用 \number 转义序列进行再次匹配,之后进行详细说明。要匹配字符 ‘(’ 或者 ‘)’, 用 ( 或 ), 或者把它们包含在字符集合里: [(], [)].
(?…)
这是个扩展标记法 (一个 ‘?’ 跟随 ‘(’ 并无含义)。 ‘?’ 后面的第一个字符决定了这个构建采用什么样的语法。这种扩展通常并不创建新的组合; (?P…) 是唯一的例外。 以下是目前支持的扩展。
(?aiLmsux)
( ‘a’, ‘i’, ‘L’, ‘m’, ‘s’, ‘u’, ‘x’ 中的一个或多个) 这个组合匹配一个空字符串;这些字符对正则表达式设置以下标记 re.A (只匹配ASCII字符), re.I (忽略大小写), re.L (语言依赖), re.M (多行模式), re.S (点dot匹配全部字符), re.U (Unicode匹配), and re.X (冗长模式)。 (这些标记在 模块内容 中描述) 如果你想将这些标记包含在正则表达式中,这个方法就很有用,免去了在 re.compile() 中传递 flag 参数。标记应该在表达式字符串首位表示在 3.11 版更改: 此构造只能在表达式的开头使用。
(?:…)
正则括号的非捕获版本。 匹配在括号内的任何正则表达式,但该分组所匹配的子字符串 不能 在执行匹配后被获取或是之后在模式中被引用
(?aiLmsux-imsx:…)
(‘a’, ‘i’, ‘L’, ‘m’, ‘s’, ‘u’, ‘x’ 中的0或者多个, 之后可选跟随 ‘-’ 在后面跟随 ‘i’ , ‘m’ , ‘s’ , ‘x’ 中的一到多个 .) 这些字符为表达式的其中一部分 设置 或者 去除 相应标记 re.A (只匹配ASCII), re.I (忽略大小写), re.L (语言依赖), re.M (多行), re.S (点匹配所有字符), re.U (Unicode匹配), and re.X (冗长模式)。(标记描述在 模块内容 .)
(?>…)
尝试匹配 … 就像它是一个单独的正则表达式,如果匹配成功,则继续匹配在它之后的剩余表达式。 如果之后的表达式匹配失败,则栈只能回溯到 (?>…) 之前 的点,因为一旦退出,这个被称为 原子化分组 的表达式将会丢弃其自身所有的栈点位。 因此,(?>.). 将永远不会匹配任何东西因为首先 . 将匹配所有可能的字符,然后,由于没有任何剩余的字符可供匹配,最后的 . 将匹配失败。 由于原子化分组中没有保存任何栈点位,并且在它之前也没有任何栈点位,因此整个表达式将匹配失
(?P…)
与常规的圆括号类似,但分组所匹配到了子字符串可通过符号分组名称 name 来访问。 分组名称必须是有效的 Python 标识符,并且在 bytes 模式中它们只能包含 ASCII 范围内的字节值。 每个分组名称在一个正则表达式中只能定义一次。 一个符号分组同时也是一个编号分组,就像这个分组没有被命名过一样。
命名组合可以在三种上下文中引用。如果样式是 (?P['"]).*?(?P=quote) (也就是说,匹配单引号或者双引号括起来的字符串):
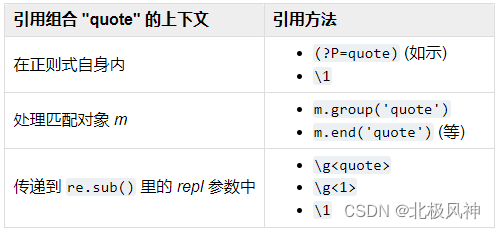
(?P=name)
反向引用一个命名组合;它匹配前面那个叫 name 的命名组中匹配到的串同样的字串
(?#…)
注释;里面的内容会被忽略。
(?=…)
当 … 匹配时,匹配成功,但不消耗字符串中的任何字符。这个叫做 前视断言 (lookahead assertion)。比如, Isaac (?=Asimov) 将会匹配 'Isaac ’ ,仅当其后紧跟 ‘Asimov’
re.findall( "Isaac(?=Asimov)","IsaacAsimov")
['Isaac']
re.findall( "Isaac(?=Asimov)","Isaacsimov")
[]
re.findall( "Isaac(?=Asimov)","Isaac")
[]
(?!…)
当 … 不匹配时,匹配成功。这个叫 否定型前视断言 (negative lookahead assertion)。例如, Isaac (?!Asimov) 将会匹配 'Isaac ’ ,仅当它后面 不是 ‘Asimov’ 。
re.findall( "Isaac(?!Asimov)","Isaac")
['Isaac']
re.findall( "Isaac(?!Asimov)","Isaac123456")
['Isaac']
re.findall( "Isaac(?!Asimov)","IsaacAsimov")
[]
``
# (?<=…)
如果 ... 的匹配内容出现在当前位置的左侧,则匹配。这叫做 肯定型后视断言 (positive lookbehind assertion)。 (?<=abc)def 将会在 'abcdef' 中找到一个匹配,因为后视会回退3个字符并检查内部表达式是否匹配。内部表达式(匹配的内容)必须是固定长度的,意思就是 abc 或 a|b 是允许的,但是 a* 和 a{3,4} 不可以。注意,以肯定型后视断言开头的正则表达式,匹配项一般不会位于搜索字符串的开头。很可能你应该使用 search() 函数,而不是 match() 函数:
```python
import re
m = re.search('(?<=abc)def', 'abcdef')
m.group(0)
'def'
这个例子搜索一个跟随在连字符后的单词:
>>>
m = re.search(r'(?<=-)\w+', 'spam-egg')
m.group(0)
'egg'
(?<!…)
如果 … 的匹配内容没有出现在当前位置的左侧,则匹配。这个叫做 否定型后视断言 (negative lookbehind assertion)。类似于肯定型后视断言,内部表达式(匹配的内容)必须是固定长度的。以否定型后视断言开头的正则表达式,匹配项可能位于搜索字符串的开头。
(?(id/name)yes-pattern|no-pattern)
如果给定的 id 或 name 存在,将会尝试匹配 yes-pattern ,否则就尝试匹配 no-pattern,no-pattern 可选,也可以被忽略。比如, (<)?(\w+@\w+(?:.\w+)+)(?(1)>|$) 是一个email样式匹配,将匹配 ‘user@host.com’ 或 ‘user@host.com’ ,但不会匹配 ‘<user@host.com’ ,也不会匹配 ‘user@host.com>’
在 3.12 版更改: 分组 id 只能包含 ASCII 数码。 在 bytes 模式中,分组 name 只能包含 ASCII 范围内的字节值 (b’\x00’-b’\x7f’)
由 ‘’ 和一个字符组成的特殊序列在以下列出。 如果普通字符不是ASCII数位或者ASCII字母,那么正则样式将匹配第二个字符。比如,$ 匹配字符 ‘$’.
\number
匹配数字代表的组合。每个括号是一个组合,组合从1开始编号。比如 (.+) \1 匹配 ‘the the’ 或者 ‘55 55’, 但不会匹配 ‘thethe’ (注意组合后面的空格)。这个特殊序列只能用于匹配前面99个组合。如果 number 的第一个数位是0, 或者 number 是三个八进制数,它将不会被看作是一个组合,而是八进制的数字值。在 ‘[’ 和 ‘]’ 字符集合内,任何数字转义都被看作是字符。
\A
只匹配字符串开始
\b
匹配空字符串,但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的序列。注意,通常 \b 定义为 \w 和 \W 字符之间,或者 \w 和字符串开始/结尾的边界, 意思就是 r’\bfoo\b’ 匹配 ‘foo’, ‘foo.’, ‘(foo)’, ‘bar foo baz’ 但不匹配 ‘foobar’ 或者 ‘foo3’
\B
匹配空字符串,但 不 能在词的开头或者结尾。意思就是 r’py\B’ 匹配 ‘python’, ‘py3’, ‘py2’, 但不匹配 ‘py’, ‘py.’, 或者 ‘py!’. \B 是 \b 的取非,所以Unicode样式的词语是由Unicode字母,数字或下划线构成的,虽然可以用 ASCII 标志来改变。如果使用了 LOCALE 标志,则词的边界由当前语言区域设置。
\Z
只匹配字符串尾
Python 字符串字面值支持的大多数 转义序列 也被正则表达式解析器所接受:
\a \b \f \n
\N \r \t \u
\U \v \x \
(注意 \b 被用于表示词语的边界,它只在字符集合内表示退格,比如 [\b] 。)
‘\u’, ‘\U’ 和 ‘\N’ 转义序列只在 Unicode 模式中可被识别。 在 bytes 模式中它们会导致错误。 未知的 ASCII 字母转义序列保留在未来使用,会被当作错误来处理。
八进制转义包含为一个有限形式。如果首位数字是 0, 或者有三个八进制数位,那么就认为它是八进制转义。其他的情况,就看作是组引用。对于字符串文本,八进制转义最多有三个数位长。
在 3.3 版更改: 增加了 ‘\u’ 和 ‘\U’ 转义序列。
在 3.6 版更改: 由 ‘’ 和一个ASCII字符组成的未知转义会被看成错误。
在 3.8 版更改: 增加了 ‘\N{name}’ 转义序列。 与在字符串字面值中一样,它扩展了指定的 Unicode 字符 (例如 ‘\N{EM DASH}’)。















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









