







因为这几天要进行一个医保基金飞行检查,今天接到一个任务,需要分析一个16万6千数据的表格。
表格如下:
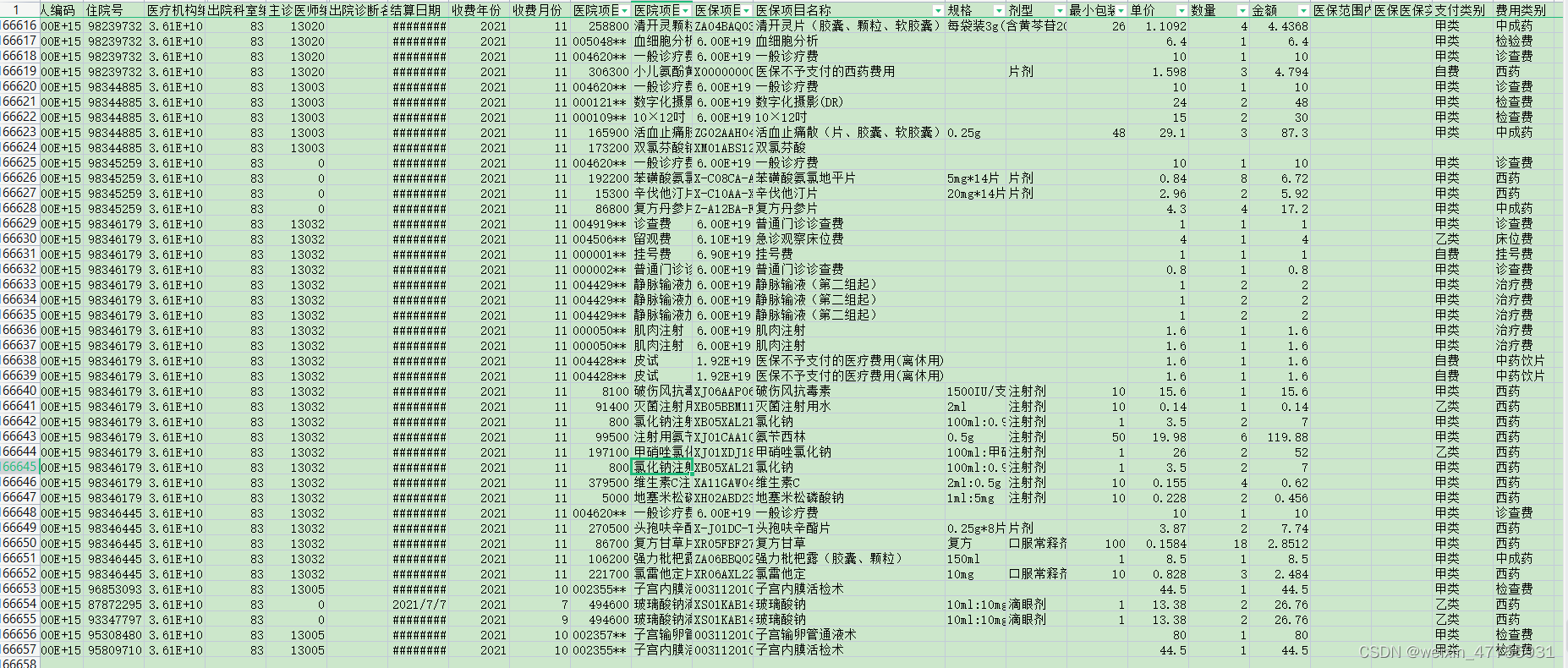
任务要求:相同医保项目名称和单价的,汇总数量和金额。(注意相同名称不同单价的另算一组数据)
因为一个名称可能有多个单价,第一次碰到这种判断条件有两个的数据分析,想到要用字典来处理。经过思考,决定使用{(医保名,单价):[汇总数量,汇总金额]}的方式来储存数据。
代码如下:
import pandas as pd
import os
def total(path):
# {(医保名,单价):[汇总数量,汇总金额]}---数据存储类型,字典嵌套元组和列表
df1 = pd.read_excel(path, sheet_name=1)
namelist = []
pricelist = []
frequencylist = []
amountlist = []
dict1 = {}
price_col = df1.columns.get_loc('单价')
frequency_col = df1.columns.get_loc('数量')
name_col = df1.columns.get_loc('医保项目名称')
amount_col = df1.columns.get_loc('金额')
save_path = os.path.split(path)[0] # 获取原文件的路径
filename = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









