






ZooKeeper是什么
ZooKeeper是一种分布式协调服务的开源框架,主要用来解决分布式集群中的一致性问题,ZooKeeper本质是一种分布式的小文件存储系统,使用的是类似文件目录树的存储结构,并且可以对节点进行有效管理,达到维护和监控节点存储节点数据的变化。
ZooKeeper存储结构
ZooKeeper是一个目录树结构,node节点可以存储1MB的数据,节点可以分为持久节点、临时节点(与session绑定,客户端断开连接时会自动删除)、序列节点(同名节点会在后面加上序号),这几个节点可以实现统一配置管理(1MB的数据)、分组管理(path路径结构)、统一命名(序列节点)、同步(临时节点)临时节点可以做分布式锁。
ZooKeeper特征与保障
- 顺序一致性:客户端的更新将按发送顺序应用
- 原子性:更新成功或失败,没有部分结果
- 统一视图:无论连接到哪一个服务器,客户端都是看到相同的服务视图
- 可靠性:一旦应用了更新 ,他将从那时起持续到客户端覆盖更新
- 及时性:系统的客户视图保证在特定时间范围内是最新的
- ZooKeeper会有两端口,如3888,2888.一个用于选主投票用,一个用于leader接受write请求
Zookeeper的扩展性
ZooKeeper角色:Leader、Follower、Observer
Observer只是用来读写分离,放大查询的能力,只有Follower才可以选举
Zookeeper的节点元数据
创建ID czid=ox20000002(0000002是事务的创建事务的ID由主机来记录,2表示主机的纪元,主机换了就开始新的纪元,然后开始新的事务ID递增)
修改ID mzxid
pxid=当前节点下创建最后一个节点的事务ID号
ephemeralOwner=临时节点持有者
统一视图操作和删除操作都会有事务ID
Zookeeper怎样保证数据一致性
通过ZAB原子广播协议保证数据的一致性
原子:只有成功和失败,没有中间状态(通过队列和两阶段提交来保证)
广播:分布式多节点,全部都知道(过半成功)
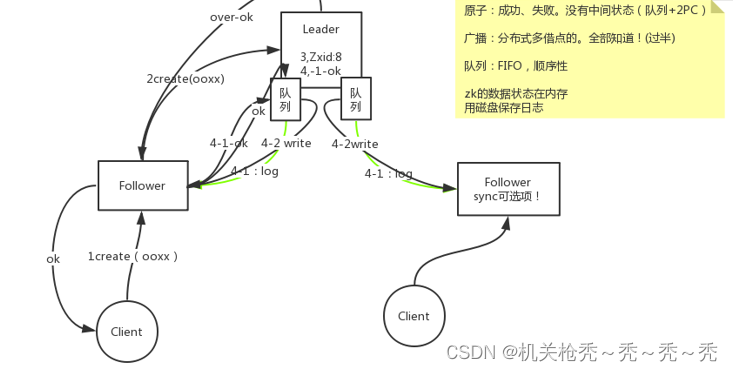
- 客户端连接一个Follower,想创建一个节点ooxx的操作
- Follower把创建节点这个操作转发给Leader,
- Leader创建一个事务ID
- Leader为每一个Follower维护了一个发送队列,4-1.Leader让每一个Follower往磁盘里面写日志 Follower写完之后就回一个OK给leader,leader本身落完之后也有一个OK,这个时候已经过半,就算有的Follower没有同意Leader也会往他的的队列里面发送write操作,最后把队列里面的信息全部消费完达到最终一致性
- Leader完成之后会回一个OK给客户端
如果客户端连接到还没消费完队列里面的信息的Follower,这个时候客户端获取到的数据就是滞后的,ZooKeeper里面提供了一个sync可选项,可以同步也可以不同步,里面使用了一种回调的方式,并不是一直阻塞在哪里,当数据同步完之后就会回调客户端里面的方法
ZooKeeper选举leader
第一次启动zookeeper集群和leader挂掉之后选举leader
选举标准:经验最丰富的Zxid,Zxid大说明他的数据是最全的
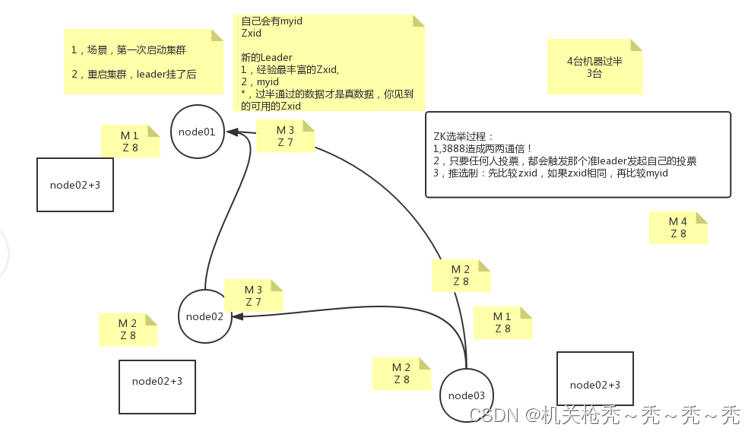
首次启动集群:第一次启动集群的时候Zxid都一样,只要机器数量达到过半,集群之间开始通讯之后会快速的把票投出去选举myid最大的为leader
leader挂掉之后:
- 假如node03先发现leader挂了,他会把自己手中自己的myid、zxid(票)通过socket发送给对方,并给自己投一票(+1)
- node01、node02拿到票之后会把这个票与自己的票相比较若否定node03发过来的票的时候会给node03回一个自己的票,并且给其他node也广播了自己的票并自己投自己一票(在内存里面+1)node03给node01、node02都+1
- node02给node01、node03广播了自己node02这个票,node01拿到票之后看到自己的myid比node02小就给node02在内存里面+1然后把node02的票再广播个node02、node03
- node02是给所有的都广播了自己的票,所以node03也和node01一样广播了node02这个票
- 这样node02就收到了自己手上投给自己的一票、广播之后node01、node03投回来的node02的两票,选举为leader
无论是哪一个follower先发起投票都会触发那个会被选为leader那个follower选自己一票并广播自己的myid、zxid,都会快速的被选举为新leader,这一切可以快速得选举出leader都是靠选举端口两两通信
ZooKeeper分布式协调配置

ZooKeeper分布式锁
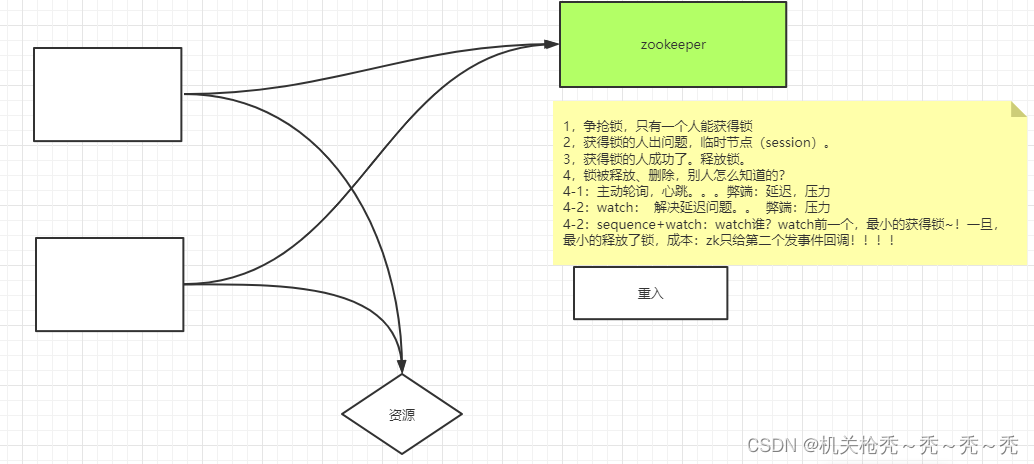
几个客户端争抢锁,但只有一个人可以获得锁,使用临时节点来解决获得锁的人出现问题之后一直拿着锁没有释放的问题,锁被释放之后其他的客户端可以通过watch监控这个临时节点,若发生改变就会触发回调函数,但这样会有一个问题就是Zookeeper要给每一个监控的客户端发事件回调,造成Zookeeper压力大。所以就使用了一个临时顺序节点+watch来实现分布式锁
每一个客户端去父节点那里创建一个同名的子节点(会自己加上序号)
获取父节点下的所有子节点(无序),需要手动排序。返回一个集合,看自己的下标是不是0如果是就可以抢锁干活,干完之后删除节点错发监控他的那个客户端的回调函数,如果不是监控自己下标减1的那个节点
代码略。。。。。















 1812
1812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









