






KNN算法
1. 什么是KNN算法
简单来说,就是根据周围几个邻居的类别来判断自己的类别
1.1 KNN概念
KNN算法全称K Nearest Neighbor
- 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
- 距离公式:两个样本的距离可以通过如下公式计算,⼜叫欧式距离;
n维空间的欧式距离公式:

1.2 KNN算法流程
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最⼩的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最⾼的类别作为当前点的预测分类
1.3 KNN算法优缺点
- 优点
- 简单有效
- 重新训练的代价低
- 适合类域交叉样本
- KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
- 缺点
- 惰性学习
- 懒散学习法(基本不学习),一些积极学习的算法要快得多
- 类别评分不是规格化
- 不像⼀些通过概率评分的分类
- 输出可解释性不强
- 例如决策树的输出可解释性就较强
- 对不均衡的样本不擅长
- 当样本不平衡时,如⼀个类的样本容量很大,而其他类样本容量很小时,有可能导致当输⼊一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某⼀类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
- 计算量较大
- 目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本
- 惰性学习
KNN案例示范
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler # 归一化,标准化(看需求选一即可)
from sklearn.neighbors import KNeighborsClassifier
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
mpl.rcParams['axes.unicode_minus'] = False
# 获取鸢尾花数据
iris = load_iris()
print("鸢尾花数据集的返回值:\n",iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n",iris['data'])
print("鸢尾花的⽬标值:\n",iris.target)
print("鸢尾花特征的名字:\n",iris.feature_names)
print("鸢尾花⽬标值的名字:\n",iris.target_names)
print("鸢尾花的描述:\n",iris.DESCR)
# 查看数据分布情况
# 把数据转换成dataframe的格式
iris_d = pd.DataFrame(iris['data'], columns=[
'Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_d['Species'] = iris.target
def plot_iris(iris, col1, col2):
sns.lmplot(x=col1, y=col2, data=iris, hue="Species", fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('鸢尾花种类分布图')
plt.show()
plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')
# 对鸢尾花数据集进行分割
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=99,test_size=0.2)
# 数据预处理(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train) # fit_transform(x_train)是在x_train自身的基础上标准化
x_test = transfer.transform(x_test) # transform(x_test)是利用fit_transform的结果标准化
# 模型训练
knn_model = KNeighborsClassifier(n_neighbors=5)
knn_model.fit(x_train,y_train)
# 模型评估
# 方法1:比对真实值和预测值
y_pre = knn_model.predict(x_test)
print("预测结果为:\n",y_pre)
print("⽐对真实值和预测值:\n",y_pre==y_test)
# 方法2:计算准确率
score = knn_model.score(x_test,y_test)
print("准确率:\n",score)
算法改进
1. 交叉验证,网格搜索
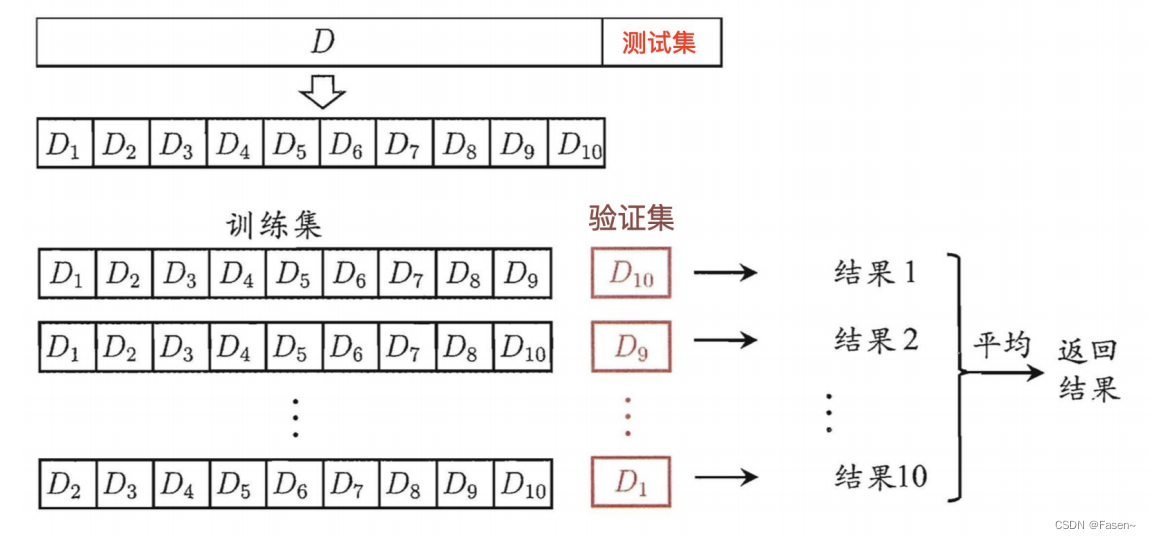
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成10份(k份),其中⼀份作为验证集。然后经过10次 (组)的测试,每次都更换不同的验证集。即得到10组模型的结果,取平均值作为最终结果。又称10折交叉验证(k折)。
网格搜索:搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
2. 目的
- 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
- 还可以从有限的数据中获取尽可能多的有效信息。
同模型改进示范
from sklearn.model_selection import GridSearchCV
# 创建新的模型
knn_model_1 = KNeighborsClassifier()
param_dict = {'n_neighbors':[5,7,9,11]} # 近邻数
knn_model_1 = GridSearchCV(knn_model_1,param_grid=param_dict,cv=3)
# fit数据进行训练
knn_model_1.fit(x_train,y_train)
# 模型评估
# 方法1:比对真实值和预测值
y_pre_1 = knn_model_1.predict(x_test)
print("预测结果为:\n",y_pre_1)
print("⽐对真实值和预测值:\n",y_pre_1==y_test)
# 方法2:计算准确率
score = knn_model_1.score(x_test,y_test)
print("准确率:\n",score)
print("在交叉验证中验证的最好结果:\n", knn_model_1.best_score_)
print("最好的参数模型:\n", knn_model_1.best_estimator_)
print("每次交叉验证后的准确率结果:\n", knn_model_1.cv_results_)














 2739
2739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









