






python 常用模块
os
参考链接 https://www.runoob.com/python3/python3-os-path.html
https://www.runoob.com/python3/python3-os-file-methods.html
os.popen() 执行linux命令 返回一个地址, 用 .read()读取内容
os.system() 执行linux名,返回一个数值,0表示执行成功,非0表示执行linux命令失败
os.path.join()函数:连接两个或更多的路径名组件, 不用考虑系统
os.chdir(path)用于改变当前工作目录到指定的路径。
os.getcwd() 方法用于返回当前工作目录。
os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
os.mkdir() 方法用于以数字权限模式创建目录。
os.rmdir() 方法用于删除指定路径的目录。仅当这文件夹是空的才可以, 否则, 抛出OSError。
os.path.abspath(path) 返回绝对路径
os.path.basename(path) 返回文件名
os.path.dirname(path) 返回文件路径
os.path.exists(path) 路径存在则返回True,路径损坏返回False
os.path.lexists 路径存在则返回True,路径损坏也返回True
os.path.getsize(path) 返回文件大小,如果文件不存在就返回错误
os.path.isabs(path) 判断是否为绝对路径
os.path.isfile(path) 判断路径是否为文件
os.path.isdir(path) 判断路径是否为目录
os.walk(path)列出一个目录下所有的文件名和子文件名
解决vscode导入自定义模块失败
import os, sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # __file__获取执行文件相对路径,整行为取上一级的上一级目录
sys.path.append(BASE_DIR)
sys
参考链接: https://cloud.tencent.com/developer/article/1569291
sys.argv 实现从程序外部向程序内传递参数
(sys.argv[0]:为脚本名称,sys.argv[1]:第一个参数,以此类推)
sys.exit([arg]) 程序中间的退出,arg=0为正常退出
(sys.exit(1) 常用做异常退出)
time
time.tiem() 时间戳
time.ctime() 返回当前时间
time.asctime() 返回一个格式化的时间
random
print( random.randint(1,10) ) # 产生 1 到 10 的一个整数型随机数
print( random.random() ) # 产生 0 到 1 之间的随机浮点数
print( random.uniform(1.1,5.4) ) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数
print( random.choice(‘tomorrow’) ) # 从序列中随机选取一个元素
print( random.randrange(1,100,2) ) # 生成从1到100的间隔为2的随机整数
json

json.dumps() 将python对象转为json对象
json.loads() 将json对象转化为python对象
json.dump() 将接送对象写入文件中
json.load() 读取文件中的json对象
jsonpath

d={
"error_code": 0,
"stu_info": [
{
"id": 2059,
"name": "小红",
"sex": "女",
"age": 21,
"grade": "天蝎座",
"phone": "18378309272",
"gold": 10896,
"info":{
"card":434345432,
"bank_name":'中国银行'
}
},
{
"id": 2067,
"name": "小刚",
"sex": "男",
"age": 22,
"grade": "天蝎座",
"phone": "12345678915",
"gold": 100
}
]
}
res= d["stu_info"][1]['name'] #取某个学生姓名的原始方法:通过查找字典中的key以及list方法中的下标索引
print(res) #输出结果是:小刚
import jsonpath
res1=jsonpath.jsonpath(d,'$..name') #嵌套n层也能取到所有学生姓名信息,$表示最外层的{},..表示模糊匹配
print(res1) #输出结果是list:['小红', '小刚']
res2= jsonpath.jsonpath(d,'$..bank_name')
print(res2) #输出结果是list:['中国银行']
res3=jsonpath.jsonpath(d,'$..name123') #当传入不存在的key(name)时,返回False
print(res3) #输出结果是:False
jmespath
pip install jmespath
通过key 获取值
# 非嵌套字典取值
import jmespath
data = {"a": "apple", "b": "banana", "c": "car"}
print(jmespath.search("c", data))
## 输出结果
# car
# 嵌套字典取值
import jmespath
data = {'a': {'b': {'c': 'car'}}}
print(jmespath.search('a', data))
print(jmespath.search('a.b', data))
print(jmespath.search('a.b.c', data))
## 输出结果
# {'b': {'c': 'car'}}
# {'c': 'car'}
# car
# 非列表取值
import jmespath
data = ['apple', 'banana', 'car', 'dog']
print(jmespath.search('[0]', data))
print(jmespath.search('[1]', data))
print(jmespath.search('[2]', data))
print(jmespath.search('[3]', data))
## 输出结果
# apple
# banana
# car
# dog
# 嵌套列表取值
import jmespath
data = [['apple', 'banana'], ['car', 'dog']]
print(jmespath.search('[0][0]', data))
print(jmespath.search('[0][1]', data))
print(jmespath.search('[1][0]', data))
print(jmespath.search('[1][1]', data))
## 输出结果
# apple
# banana
# car
# dog
# 字典嵌套列表 列表嵌套字典的取值
import jmespath
data = {
'students': [
{
'name': 'zhangsan',
'age': 12,
'hobby': ['eat', 'sleep']
},
{
'name': 'lisi',
'age': 14,
'hobby': ['sing', 'dance']
},
{
'name': 'wangwu',
'age': 17,
'hobby': ['rap', 'basketball']
}
]
}
print(jmespath.search('students[0].name', data))
print(jmespath.search('students[0].age', data))
print(jmespath.search('students[0].hobby[1]', data))
## 输出结果
# zhangsan
# 12
# sleep
# 切片操作
import jmespath
data = [1,2,3,4,5,6,7,8,9]
print(jmespath.search('[0:3]', data))
print(jmespath.search('[4:8]', data))
print(jmespath.search('[:6]', data))
print(jmespath.search('[::3]', data))
#输出结果
# [1, 2, 3]
# [5, 6, 7, 8]
# [1, 2, 3, 4, 5, 6]
# [1, 4, 7]
# 去出所有name的值
import jmespath
data = {
'students': [
{
'name': 'zhangsan',
'age': 14
},
{
'name': 'lisi',
'age': 13
},
{
'name': 'wangwu',
'age': 16
}
]
}
# print(jmespath.search('students[].name', data))
# [] 中加不加 * 结果一样
print(jmespath.search('students[*].name', data))
## 输出结果
# ['zhangsan', 'lisi', 'wangwu']
# 去除列表中前2个
import jmespath
data = {
'students': [
{
'name': 'zhangsan',
'age': 14
},
{
'name': 'lisi',
'age': 13
},
{
'name': 'wangwu',
'age': 16
}
]
}
print(jmespath.search('students[:2].name', data))
## 输出结果
# ['zhangsan', 'lisi']
# 对象取值使用 * 通配符
import jmespath
data = {
'class': {
'class_1' : {
'name_1': 'zhangsan'
},
'class_2' : {
'name_2': 'lisi'
},
'class_3' : {
'name_3': 'wangwu'
},
}
}
print(jmespath.search('class.*.name_1', data))
## 输出结果
# ['zhangsan']
pathlib
from pathlib import Path
print(Path.cwd())
# 获取当前路径
print(Path.home())
# 获取home目录
print(Path.cwd().parent)
# 获取上级父目录
print(Path.cwd().parent.parent)
# 获取上上级父目录
# 可支持多层链式操作
for i in Path.cwd().parents:
print(i)
# 遍历整个父级目录
cur_file_path = os.path.realpath(__file__)
print(Path(cur_file_path).suffix)
# 返回文件的扩展名
print(Path(cur_file_path).stem)
# 返回文件的名称
print(Path(cur_file_path).name)
# 返回路径的文件名
print(Path(Path().cwd()).joinpath('abc.py'))
# 拼接路径
for i in Path(Path.cwd()).iterdir():
print(i)
# Path(Path.cwd()).iterdir() 返回的是一个生产器
# 遍历当前目录下的所有内容并且是绝对路径
for i in Path().iterdir():
print(i)
# 遍历当前目录下的所有内容 没有路径
Path(Path.cwd().joinpath('as1').joinpath('qw')).mkdir(parents=True, exist_ok=True)
# 创建路径
print(Path(Path.cwd().joinpath('qwe')).exists())
# 判断对象是否存在
print(Path(Path.cwd().joinpath('as')).is_dir())
# 判断是否为目录
print(Path(Path.cwd().joinpath('as')).is_file())
# 判断是否为文件
Faker
用来构造假数据
pip install Faker
re
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,
re.search 匹配整个字符串,直到找到一个匹配。
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:re.compile(pattern[, flags])
re.findall()在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
参考 : https://www.nowcoder.com/tutorial/10005/405978e43980483691016271ac34c9f8
dotenv
安装
pip install python-dotenv
需要把 .env文件的内容导入到系统环境变量中,以方便程序调用
.env 文件
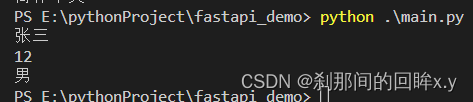
name='张三'
age=12
sex='男'
import os
from dotenv import find_dotenv, load_dotenv
load_dotenv(find_dotenv('.env'))
# find_dotenv默认传入当前路径的.env文件,用户可以自定义其他文件,并把对应的路径传入即可导入到环境变量中
# load_dotenv 加载
env_dist = os.environ
print(env_dist.get('name'))
print(env_dist.get('age'))
print(env_dist.get('sex'))
requests
requests.get(url) # GET请求
requests.post(url) # POST请求
r.encoding #获取当前的编码
r.text #以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。
r.content #以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。
r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.status_code #响应状态码
r.raw #返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read()
r.ok # 查看r.ok的布尔值便可以知道是否登陆成功
#特殊方法#
r.json() #Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常
r.raise_for_status() #失败请求(非200响应)抛出异常
参考:https://www.cnblogs.com/saneri/p/9870901.html
configparser
内置模块,用来读取conf文件
导入模块
import configparser
conf = configparser.ConfigParser() # 获取一个读取conf文件的句柄
conf.read("myconf.conf") # 读取conf文件
sections = conf.sections() # 获取一个配置项内容 返回的是一个list
option = conf.options("logging") # 获取配置项内容中key对应的value
value = conf.get('logging', 'path') # 根据某个sections 下的某个key 获取对应的value
glob
模块提供了一个函数用于从目录通配符搜索中生成文件列表:
# 获取路径列表
# 如果目录存在返回列表,列表中有目录名称
# 如果目录不存在返回空列表
import glob
print(glob.glob('./test_dirname/'))
# 返回 test_dirname 目录下的所有目录和文件
import glob
print(glob.glob('./test_dirname/*'))
# 不递归的获取 test_dirname 目录下的.py文件
import glob
print(glob.glob('./test_dirname/*.py'))
print(glob.glob('./test_dirname/*/*.py'))
# 递归获取test_dirname 目录下的所有目录和文件
import glob
print(glob.glob('./test_dirname/**', recursive=True))
print(glob.glob('./test_dirname/**/*.py', recursive=True))
import glob
for i in glob.iglob('./test_dirname/*'):
print(i)
# glob.iglob() 返回一个生成器
hashlib
ipaddr
安装
pip install ipaddr
# 判断一个地址是否在某个网段内
import ipaddr
ip = ipaddr.IPv4Address("10.10.1.1")
ip_net = ipaddr.IPv4Network("10.10.1.0/23")
if ip in ip_net:
print("True")
else:
print("False")
# True
# 判断一个网段是否属于另一个网段
import ipaddr
ip_net1 = ipaddr.IPv4Network("10.10.1.0/24")
ip_net2 = ipaddr.IPv4Network("10.10.0.0/16")
if ip_net1 in ip_net2:
print("True")
else:
print("False")
# True
# 判断是否属于内网ip
import ipaddr
ip1 = ipaddr.IPv4Address("1.1.2.2")
print(ip1.is_private)
ip2 = ipaddr.IPv4Address("192.168.2.2")
print(ip2.is_private)
# False
# True
# 判断是否属于内网网段
import ipaddr
ip_net1 = ipaddr.IPv4Network("1.1.0.0/24")
print(ip_net1.is_private)
ip_net2 = ipaddr.IPv4Network("192.168.1.1/32")
print(ip_net2.is_private)
# 获取网段中子网的ip个数
import ipaddr
ip_net1 = ipaddr.IPv4Network("1.1.1.0/24")
print(ip_net1.numhosts)
ip_net2 = ipaddr.IPv4Network("192.168.1.1/24")
print(ip_net2.numhosts)
ip_net3 = ipaddr.IPv4Network("192.168.1.1/16")
print(ip_net3.numhosts)
# 256
# 256
# 65536
# 获取某个网段中的所有ip
import ipaddr
ip_net1 = ipaddr.IPv4Network("1.1.1.0/31")
for ip in ip_net1:
print(isinstance(ip, ipaddr.IPv4Address))
print(str(ip)) # 这里遍历时返回的元素是ipaddr.IPv4Address对象,不是一个IP字符串,但可以转换。
# True
# 1.1.1.0
# True
# 1.1.1.1
# 根据索引访问某个网段中的ip
import ipaddr
ip_net = ipaddr.IPv4Network("1.1.1.0/24")
print(ip_net[0], ip_net[5])
# 1.1.1.0 1.1.1.5
python3 中的 urllib
包含以下几个模块:
urllib.request - 打开和读取 URL。
urllib.error - 包含 urllib.request 抛出的异常。
urllib.parse - 解析 URL。
urllib.robotparser - 解析 robots.txt 文件
详情参考:https://www.runoob.com/python3/python-urllib.html
time
根据时间戳获取当前格式化时间
timeStamp = 1381419600
timeArray = time.localtime(timeStamp) # 这里格式后 :(tm_year=2021, tm_mon=11, tm_mday=1, tm_hour=22, tm_min=20, tm_sec=51, tm_wday=0, tm_yday=305, tm_isdst=0)
otherStyleTime = time.strftime(“%Y–%m–%d %H:%M:%S”, timeArray)
print(otherStyleTime) # 2013–10–10 23:40:00
pystache
模板替换工具
先看模板
yaml 文件
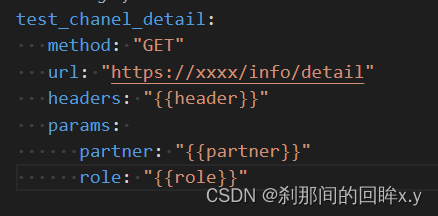
json文件

双花括号中的内容为要替换的变量

pystache.render() 里面添加两个参数,第一个是json字符串模板,第二个是模板对应的值为dict
输出

可以看到yaml或json文件中双花括号中的内容已经替换为具体的值
如果出现匹配数据中的key 不存在模板中,会发生什么呢?


string 中 Template
模板替换工具
json文件模板
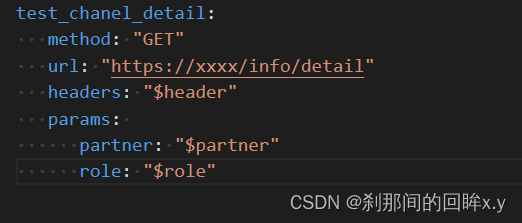
json文件模板

代码
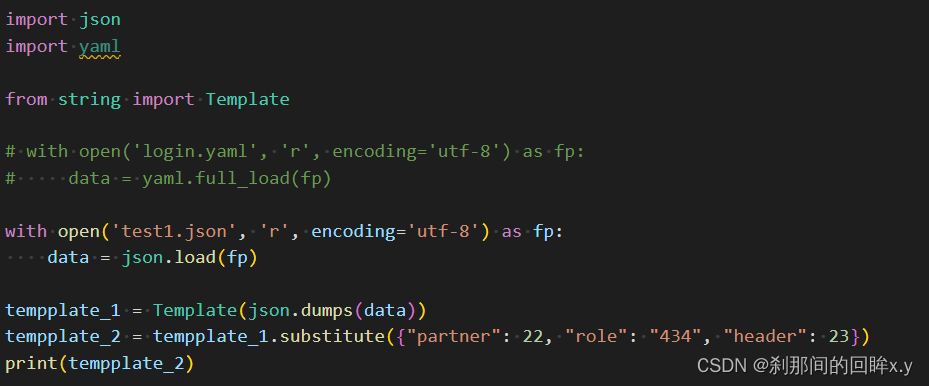
输出

可以看出,模板文件支持两种写法,$var 和 ${var}
如果出现匹配数据中的key 不存在模板中,会发生什么呢?
会触发keyError 指出不存在变量值
如果不希望报错
则需要


datetime
根据时间戳获取当前格式化时间
timeStamp = 1381419600
dateArray = datetime.datetime.fromtimestamp(timeStamp)
otherStyleTime = dateArray.strftime(“%Y–%m–%d %H:%M:%S”)
print(otherStyleTime) # 2013–10–10 23:40:00
python3版本中已经将urllib2、urlparse和robotparser并入了urllib模块中,并且修改urllib模块,其中包含5个子模块,即是help()中看到的那五个名字。如下:
urllib.error:ContentTooShortError、HTTPError、URLError
urllib.parse:parseqs、parseqsl、quote、quotefrombytes、quote_plus、unquote unquoteplus、unquoteto_bytes、urldefrag、 urlencode、urljoin、 urlparse、 urlsplit、 urlunparse、 urlunsplit
urllib.request:AbstractBasicAuthHandler、 AbstractDigestAuthHandler、 BaseHandler、 CatheFTPHandler、 FTPHandler、 FancyURLopener、FileHandler、HTTPBasicAuthHandler、 HTTPCookieProcessor、HTTPDefaultErrorHandler、 HTTPDigestAuthHandler、 HTTPErrorProcessorl、 HTTPHandler、HTTPPasswordMgr、 HTTPPasswordMgrWithDefaultRealm、 HTTPRedirectHandler、HTTPSHandler、OpenerDirector、ProxyBasicAuthHandler ProxyDigestAuthHandler、 ProxyHandler、 Request、URLopener、UnknowHandler、 buildopener、 getproxies、 installopener、 pathname2url、 url2pathname、 urlcleanup、 urlopen、 urlretrieve
urllib.response:addbase、addclosehook、addinfo、addinfourl
urllib.robotparser:RobotFileParser















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









