






1 lxml 解析 html
1.1 安装
pip3 install lxml # 下载慢的找个pip 源
1.2 导入
from lxml import etree
text = f'{html文本}'
# 创建对象
html_obj = etree.HTML(text)
1.3 Xpath 用法
XPath 全称 XML Path Language 即 XML路径语言,他是一门在XML文档中查找信息的语言。最初是用来搜寻XML文档,但是同样使用HTML文档的搜索,所以子啊做爬虫时完全可以使用XPath做相应的信息抽取.。
Xpath 常用规则
1.3.1 选取节点
nodename 选取此节点的所有子节点
/ 从当前节点选取直接子节点
// 从匹配选择的当前节点选取文档中的节点,而不考虑它们的位置
. 选取当前节点
.. 选择当前节点的父节点
@ 选取属性
1.3.1.1 从根节点选取直接子节点
注意:需要从根路径开始写,比较麻烦,可以在复制(在下图位置),获取的结果是一个list,可以指定同级别下的标签位置,索引位置从1开始
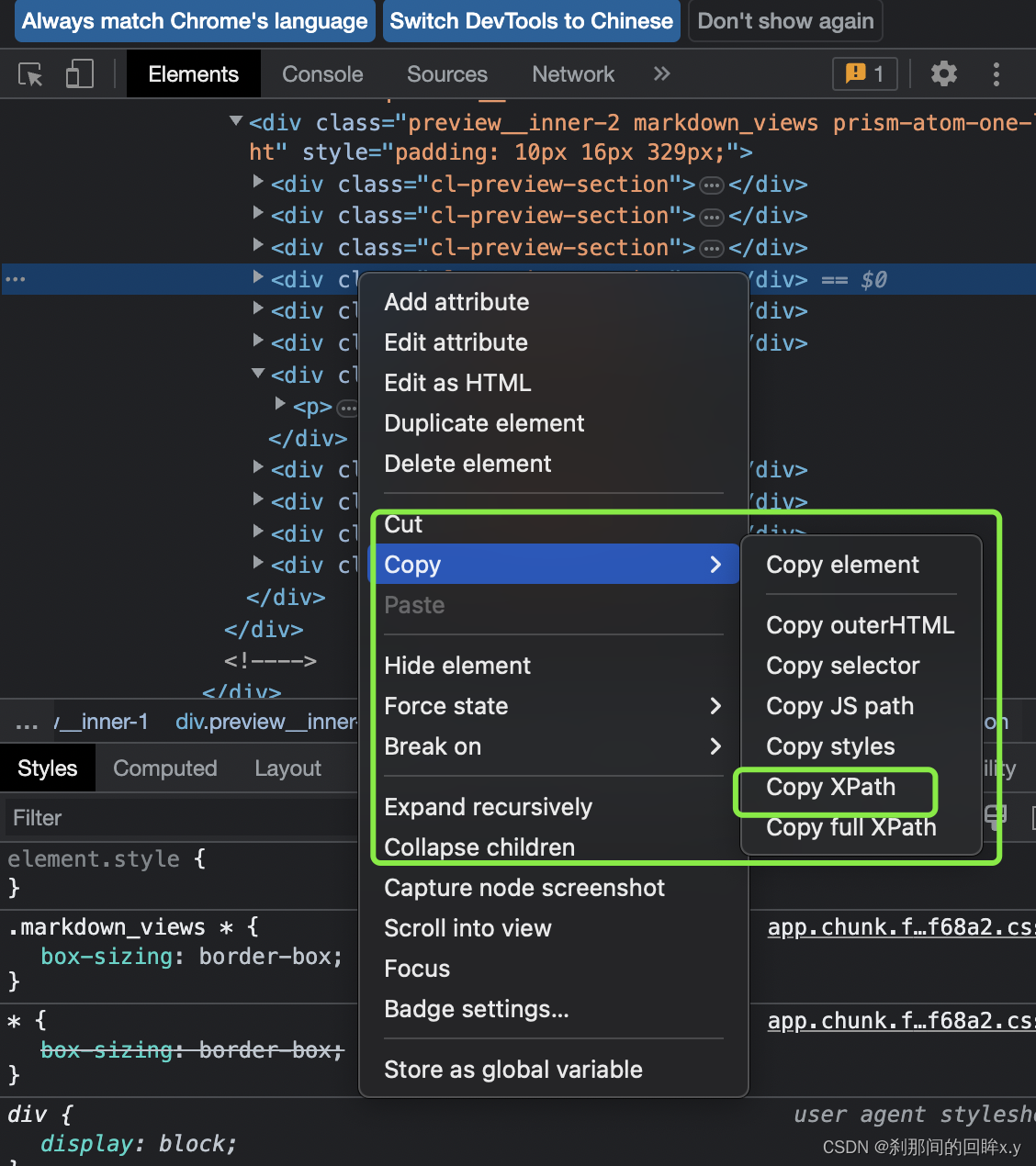
from lxml import etree
text = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>学习园地</title>
</head>
<body>
<ul>
<li><a href="/a/b/c/java/">java工程师</a></li>
<li><a href="/a/b/c/python/">python工程师</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
</ul>
<ul>
<li><a href="/a/b/c/java/">会计师</a></li>
<li><a href="/a/b/c/python/">消防员</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
</ul>
<div>
<p>这是一个段落</p>
</div>
</body>
</html>
'''
# 使用etree 解析html字符串
html = etree.HTML(text)
# print(html)
# # 提取数据
r1 = html.xpath('/html/body/div/p/text()')
print(r1) # ['这是一个段落']
1.3.1.2 从匹配选择的当前节点选取文档中的节点
注意:会匹配指定节点下的所有的内容,返回结果是一个list,可以指定同级别下的标签位置,索引位置从1开始
from lxml import etree
text = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>学习园地</title>
</head>
<body>
<ul>
<li><a href="/a/b/c/java/">java工程师</a></li>
<li><a href="/a/b/c/python/">python工程师</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
</ul>
<ul>
<li><a href="/a/b/c/java/">会计师</a></li>
<li><a href="/a/b/c/python/">消防员</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
</ul>
<div>
<p>这是一个段落</p>
</div>
<div>
<p>这是另外一个段落</p>
</div>
</body>
</html>
'''
# 使用etree 解析html字符串
html = etree.HTML(text)
# print(html)
# # 提取数据
r1 = html.xpath('//p/text()')
print(r1) # ['这是一个段落', '这是另外一个段落']
1.3.1.3 其他节点选取方式
from lxml import etree
text = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>学习园地</title>
</head>
<body>
<ul>
<li><a href="/a/b/c/java/">java工程师</a></li>
<li><a href="/a/b/c/python/">python工程师</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
<p>这是段落1</p>
</ul>
<ul>
<li><a href="/a/b/c/java/">会计师</a></li>
<li><a href="/a/b/c/python/">消防员</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
</ul>
<div>
<p>这是段落2</p>
</div>
<div class="bottom">
<p>这是段落3</p>
<span>这是span标签</span>
</div>
</body>
</html>
'''
# 使用etree 解析html字符串
html = etree.HTML(text)
div_class_bottom = html.xpath("//div[@class='bottom']")[0] # 获取class=bottom的div标签
print(div_class_bottom.xpath('span/text()')) # 在class=bottom的div标签下找到span标签的内容
print(div_class_bottom.xpath('..')) # 找到class=bottom的div标签的父节点对象
print(div_class_bottom.xpath('./p')) # 在class=bottom的div标签下找到p标签对象
1.3.2 xpath 通配符
* 匹配任何元素节点
@* 匹配任何属性节点
node() 匹配任何类型的节点
from lxml import etree
text = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>学习园地</title>
</head>
<body>
<ul>
<li><a href="/a/b/c/java/">java工程师</a></li>
<li><a href="/a/b/c/python/">python工程师</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
<p>这是段落1</p>
</ul>
<ul>
<li><a href="/a/b/c/java/">会计师</a></li>
<li><a href="/a/b/c/python/">消防员</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
</ul>
<div>
<p>这是段落2</p>
</div>
<div class="bottom">
<p>这是段落3</p>
<span>这是span标签</span>
</div>
<div class="33">
<input type="text" name="user"><br>
<input type="text" name="user1"><br>
<input type="text" name="user2"><br>
<input type="text" name="user3"><br>
</div>
<div class='343'>11</div>
<div class='343'>12</div>
</body>
</html>
'''
# 使用etree 解析html字符串
html = etree.HTML(text)
r1 = html.xpath("//*[@class='343']") # 匹配属性class=343的标签
for i in r1:
print(i.xpath('text()'))
1.3.3 获取标签属性和标签内容
① /text() 获取多个节点下第一层节点的所有内容,不包括子节点,且结果是list。
② /@属性名: 获得标签的属性,结果也是 list。
③ string 获得多个节点的第一个节点下所有节点的内容,包括子节点,结果是 str 。
from lxml import etree
text = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>学习园地</title>
</head>
<body>
<ul>
<li><a href="/a/b/c/java/">java工程师</a></li>
<li><a href="/a/b/c/python/">python工程师</a></li>
<li><a href="/a/b/c/ai">AI工程师</a></li>
<p>这是段落1</p>
</ul>
<ul>
<li><a href="/a/b/c/java/">会计师</a></li>
<li><a href="/a/b/c/python/">消防员</a></li>
<li><a href="/a/b/c/ai">警察</a></li>
</ul>
<div>
<p>这是段落2</p>
</div>
<div class="bottom">
<p>这是段落3</p>
<span>这是span标签</span>
</div>
<div class="33">
<input type="text" name="user"><br>
<input type="text" name="user1"><br>
<input type="text" name="user2"><br>
<input type="text" name="user3"><br>
</div>
<div class='343'>11</div>
<div class='345'>12</div>
</body>
</html>
'''
r1 = html.xpath("//div[@class='343' or @class='345']") # (or 或) (and 和)
for i in r1:
print(i.xpath('text()'))
# ['11']
# ['12']
# 使用etree 解析html字符串
html = etree.HTML(text)
r1 = html.xpath("//ul/li[last()-1]/a") # last() 取最后一个
for i in r1:
print('标签内容: ', i.xpath('text()'))
print('链接:', i.xpath('./@href'))
print('字符串格式的内容', i.xpath('string()'))
标签内容: ['python工程师']
链接: ['/a/b/c/python/']
python工程师
标签内容: ['消防员']
链接: ['/a/b/c/python/']
消防员
1.4 从文件获取html信息
html = etree.parse("./test.html", etree.HTMLParser())
r = html.xpath('/html/body/ul/li/a/text()')
print(r)
Tip: lxml 的用法还有很多,这里只写出的常用的一些,
2 BeautifulSoup
2.1 安装
pip install lxml
pip install bs4
2.2 导入
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
2.3 标签选择器
2.3.1 选择元素
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
# <title>The Dormouse's story</title>
print(type(soup.title))
# <class 'bs4.element.Tag'>
print(soup.head)
# <head><title>The Dormouse's story</title></head>
print(soup.p)
# <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
2.3.2 获取名称
这个看着没什么用啊 😄
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title.name)
# title
2.3.3 获取属性
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.attrs['name'])
# dromouse
print(soup.p['name'])
# dromouse
2.3.4 获取内容
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.string)
# The Dormouse's story
2.3.5 嵌套选择
看着没什么用 😄
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div><p><span>hello world</span></p></div>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.div.p.span.string)
# hello world
2.4 标准选择器
2.4.1 find_all()的使用
find_all() 可以根据标签名 属性内容查找文档,返回所有匹配的内容
2.4.1.1 find_all()根据标签名查找
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('ul'))
print(type(soup.find_all('ul')[0]))
[<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>, <ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>]
<class 'bs4.element.Tag'>
for i in soup.find_all('ul'):
print(i.find_all('li'))
[<li class="element">python教程</li>, <li class="element">java教程</li>, <li class="element">php教程</li>]
[<li class="element">Golang教程</li>, <li class="element">C++教程</li>]
2.4.1.2 find_all() 根据属性查找
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(attrs={'id':'list-1'}))
print(soup.find_all(id='list-2'))
print(soup.find_all(class_='element'))
[<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>]
[<ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>]
[<li class="element">python教程</li>, <li class="element">java教程</li>, <li class="element">php教程</li>, <li class="element">Golang教程</li>, <li class="element">C++教程</li>]
2.4.1.3 根据内容查找
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print('-----')
print(soup.find_all(string='Golang教程'))
# ['Golang教程']
2.4.2 find() 的使用
find 返回匹配到的第一个元素
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find('ul'))
<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>
2.4.3 查找所有的父节点及祖父节点
find_parent() 父节点
find_parents() 所有祖先节点
2.4.3 查找所有兄弟节点及下一个兄弟节点
find_next_siblings() 后面 所有兄弟节点
find_next_sibling() 下一个兄弟节点
2.5 css选择器
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">python教程</li>
<li class="element">java教程</li>
<li class="element">php教程</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Golang教程</li>
<li class="element">C++教程</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0]))
print('-'*20)
for i in soup.select('ul li'):
print(i.attrs['class'], end=' ') # 获取指定属性值
print(i.get_text()) # 获取文本内容
[<div class="panel-heading">
<h4>Hello</h4>
</div>]
[<li class="element">python教程</li>, <li class="element">java教程</li>, <li class="element">php教程</li>, <li class="element">Golang教程</li>, <li class="element">C++教程</li>]
[<li class="element">Golang教程</li>, <li class="element">C++教程</li>]
<class 'bs4.element.Tag'>
--------------------
['element'] python教程
['element'] java教程
['element'] php教程
['element'] Golang教程
['element'] C++教程
















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









