




 本文分析了线性表的空间不足、空间浪费和效率低下的问题,并介绍了如何通过使用链表(单链表)来改进,特别关注了单链表的尾部和头部数据添加及删除操作。
本文分析了线性表的空间不足、空间浪费和效率低下的问题,并介绍了如何通过使用链表(单链表)来改进,特别关注了单链表的尾部和头部数据添加及删除操作。
线性表的缺点
上篇博客简单的说明了一下什么是线性表,解释线性表的一些基本运行原理,但会发现线性表存在
着明显的缺点。
1.空间不足后需要增容,但是增容是需要代价的;如果需要增容的空间后面有足够的空间,则
realloc函数会在原地增容;而如果后面没有足够的空间,realloc 函数会另寻一处地址扩容,将原
来数据拷贝过去,再释放原空间。
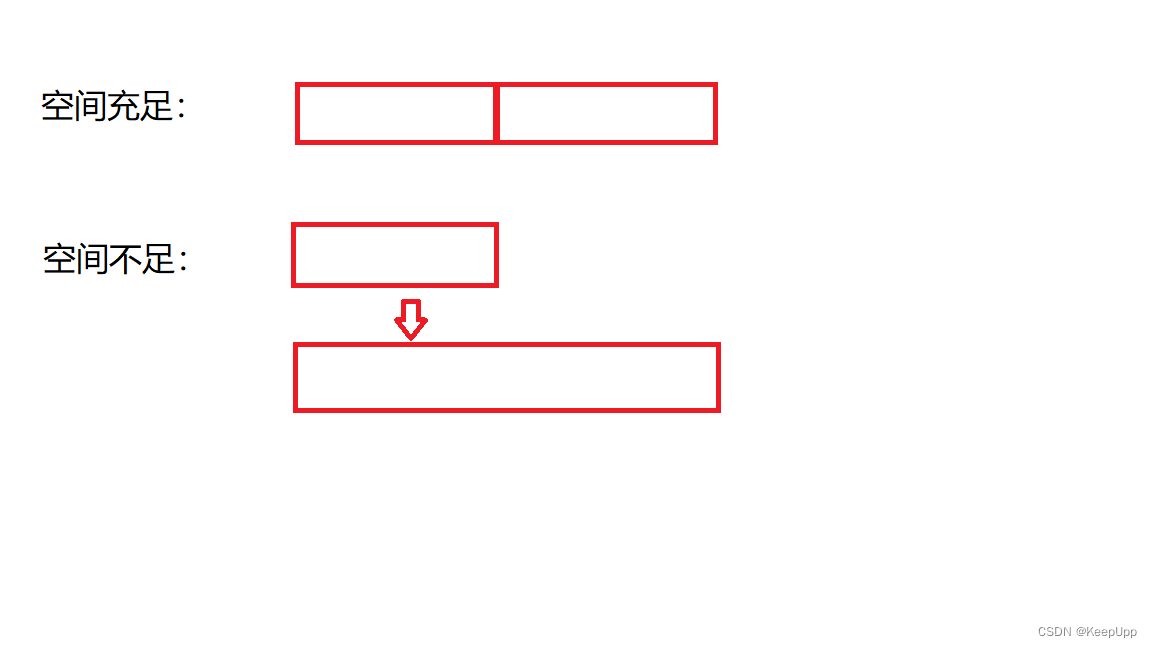
2.线性表一般按照原容量的两倍增加,极容易造成空间的浪费。
3.线性表要求连续储存数据,如在中间增加、删除数据,就需要挪动数据,导致效率不高。
针对上面线性表的缺点,有人就提出了链表!
链表:
单链表
链表与线性表的最大不同是,链表不要求储存空间是连续的,同时需要添加数据,才会分配内存,
不会造成内存的浪费!
单链表的定义:单链表通过一组任意的存储单元来存储线性表中的数据元素,不需要使用地址连续
的存储单元。
逻辑解释如下:

链表由两个组成成分:
1.是需要存储的数据
2.是下一个数据的地址;
通过地址的访问,将所有数据连接起来。
代码实现:
typedef struct SListNode { int data; //当前储存的数据 struct SListNode* next; //指向下一个节点 数据地址 }SLTNode;
尾部添加链表数据
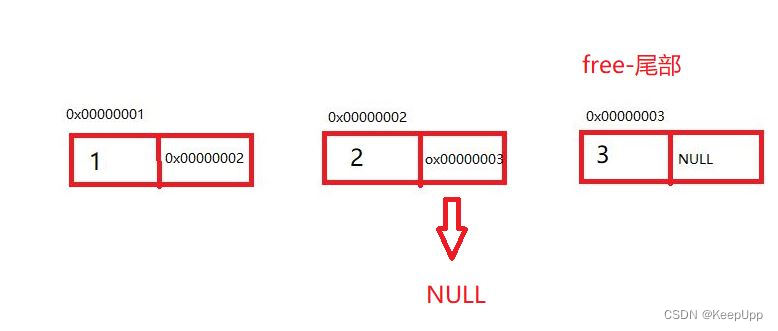
假设链表中已经存有俩个节点,如下图:

链表添加数据的意思是,将第二个节点中NULL,存入一个新的节点。如下图:

上述则是单链表的尾插逻辑示意图。
下面是代码分析,关键是需要找的链表的尾,即找的链表中的NULL部分:
void SListAddData(SLTNode** phead, SLTDataType x) { //新建链表成分 SLTNode* new = (SLTNode*)malloc(sizeof(SLTNode)); //先链表成员赋值 new->data = x; new->next = NULL; //定义链表头 SLTNode* cur = *phead; //寻找链表尾 while (cur->next != NULL) { cur = cur->next; } //连接链表 cur->next = new; }
头部添加链表数据
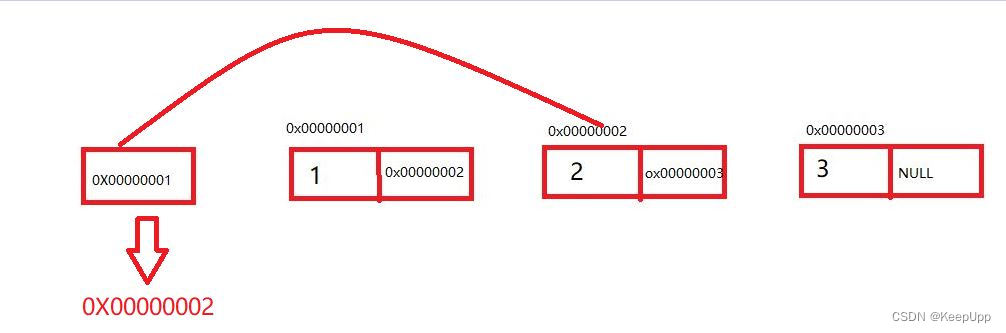
相比尾部的数据添加,链表头部添加就会简单许多。
只需要将原链表的头地址,存入到新的节点地址部分中,再指向新节点,即可完成了数据的头部添
加。下面是头部添加数据的的逻辑示意图:

下面是代码实现:
void SListAddDataFront(SLTNode** phead, int x) { //新建链表成分 SLTNode* new = (SLTNode*)malloc(sizeof(SLTNode)); //先链表成员赋值 new->data = x; //连接上原来链表 new->next = *phead; //新链表成为头元素 *phead = new; }
单链表的尾部数据删除
我们假设该链表已近存有数据,单链表的尾部数据删除就只需要将尾部的节点内存释放,同时将
前一个链表结点地址模块指向NULL,则完成了单链表的尾部数据删除,如下面的逻辑实际图:
代码实现:
void SListPopData(SLTNode** phead) { SLTNode* cur = *phead; //找到次尾结点 while (cur->next->next) { cur = cur->next; } //释放尾结点的内存 free(cur->next); //次尾结点指向NULL cur->next = NULL; }
首先需要找到次尾结点,释放尾结点的内存,将次尾巴结点的内存指向NULL!
单链表的头部数据删除
头部数据删除相比尾巴的数据删除,就会简单很多,只需要跳过当前的结点,指向下一个结点。
代码实现
//头部删除数据
void SListPopDataFront(SLTNode** phead)
{
*phead= (*phead)->next;
}
上述是对单链表的简单描述,当然链表的情况远比上述的要复杂很多,欢迎大家留言讨论~~~

















 3300
3300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









